网络协议之:基于UDP的高速数据传输协议UDT
简介
简单就是美。在网络协议的世界中,TCP和UDP是建立在IP协议基础上的两个非常通用的协议。我们现在经常使用的HTTP协议就是建立在TCP协议的基础上的。相当于TCP的稳定性来说,UDP因为其数据传输的不可靠性,所以用在某些特定的场合,如直播、广播消息、视频音频流处理等不太需要校验数据完整性的场合。
UDP相对TCP协议而言,其特点就是简洁,它删除了在TCP协议中为了保证消息准确性的各种限制性特征。简洁带来的好处就是快!今天给大家讲解一下,基于UDP的高速数据传输协议UDT。
UDT协议
UDP因为其简单的特性,所以可以做到很多TCP做不到的事情,比如进行大数据量的快速传输。这里并不是要将TCP和UDP分个好坏高下,毕竟各个协议的适应场景不同,他们之所以流行,就是因为可以在特定的场景发挥出重要的作用。套用中国的一句谚语就是:不管白猫黑猫,能抓到老鼠的,就是好猫。
用好UDP协议,我们就可以快速的传递大量的数据,这个协议就是UDT协议。
话说,像这些基础协议都是老外发明的,而中国的互联网巨头都在抢着做平台、做流量的生意,真的是无话可说....
UDT项目开始于2001年,是由Yunhong Gu在芝加哥伊利诺伊大学国家数据挖掘中心 (NCDM)读博士期间开发的,并在毕业之后持续的进行维护和升级改进。
UDP的出现是因为那时候,传输更快更便宜的光纤网络出现了,代替了之前的铜缆线和双绞线,从而极大的提升了信息传输的效率。这时候大家就发现之前使用TCP协议来进行大数据的传输会有很大的问题。从而基于UDP的UDT协议出现了。
UDT的第一个版本,也称为SABUL(Simple Available Bandwidth Utility Library),UDT通过支持批量数据传输,从而方便在私有网络中进行数据的传输。
要注意的是UDT的第一个版本SABUL使用UDP协议进行传输数据,同时使用单独的TCP协议连接传输控制消息。
UDT的初始版本是在超高速网络(1 Gbit/s、10 Gbit/s等)上进行开发和测试的,2003年10月,NCDM实现了从美国芝加哥到荷兰阿姆斯特丹的平均每秒6.8G比特的传输。在30分钟内的测试中,他们传输了大约1.4TB的数据。
从2004年发布的2.0版本开始,SABUL改名为UDT,UDT的全称是UDP-based Data Transfer Protocol,也就是基于UDP的数据传输协议。
为什么要改成UDT呢?因为在UDT2.0中,删除了SABUL中的TCP 控制连接,并使用UDP来处理数据和控制信息。 另外,UDT2还引入了一种新的拥塞控制算法,允许协议动态调整UDT和TCP流,实现UDT和TCP流的并发运行。
在2006年,UDT协议升级到了3版本,该协议不仅是在私有网络中运行了,而是扩展到了商业互联网中。同时UDT3中的拥塞控制可以进行调整优化,可以在低带宽的环境中运行,并且允许用户轻松定义和安装自己的拥塞控制算法。另外,UDT3还显着减少了系统资源(CPU和内存)的使用。
2007年,UDT4版本在高并发和防火墙穿透方面进行优化和性能的提升。UDT4允许多个UDT连接绑定到同一个UDP端口,它还支持集合连接设置,以便UDP hole punching。
什么是UDP hole punching呢?
UDP hole punching通常被用在网络地址转换 (NAT)中。用来维护穿越NAT的用户UDP数据包流。它是一种使用网络地址转换器在专用网络中的Internet主机之间建立双向UDP连接的方法。
什么是NAT呢?
大家都知道IPV4地址是有限的,很快IPV4地址就快用完了,那怎么解决这个问题呢?
当然,一个永久解决的办法是IPV6,不过IPV6推出这么多年了,好像还没有真正的普及。
不使用IPV6的话还有什么解决办法呢?
这个办法就是NAT(Network Address Translators)。
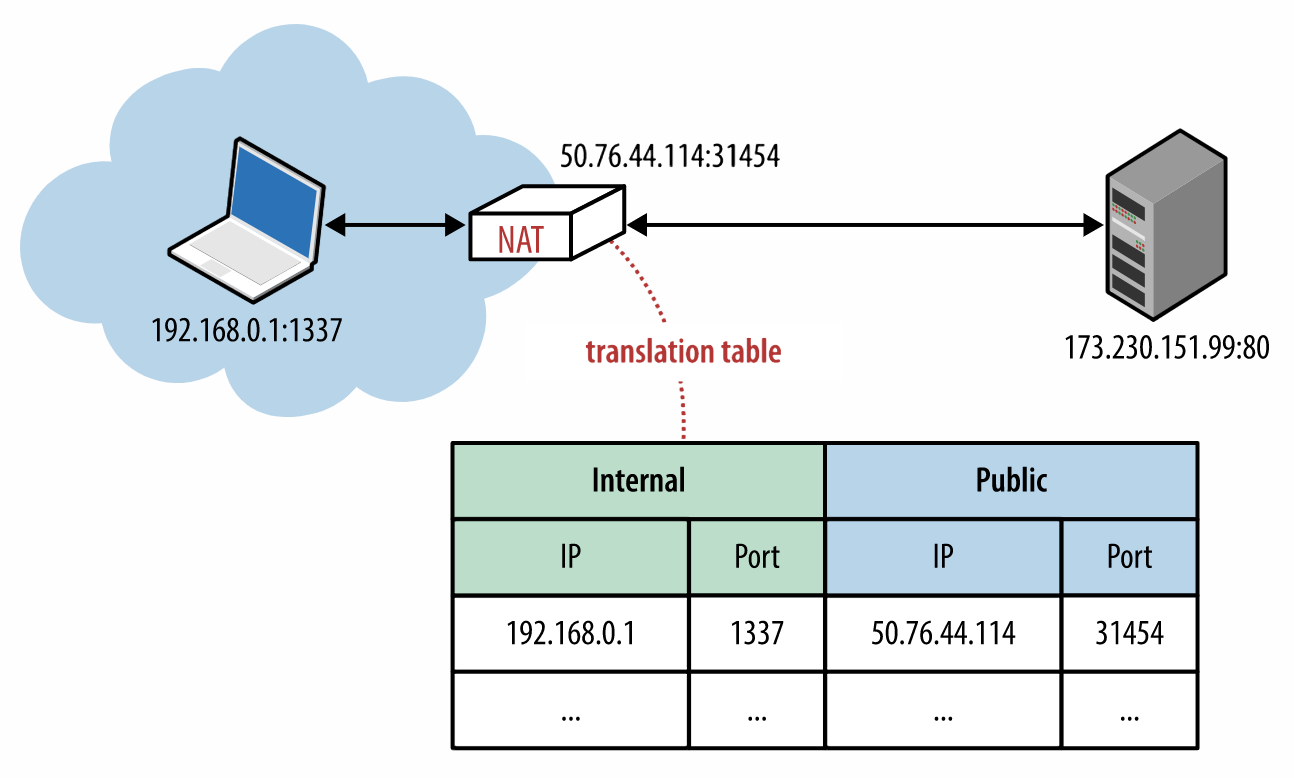
NAT的原理是将局域网的IP和端口和NAT设备的IP和端口做个映射。
NAT内部维护着一张转换表。这样就可以通过一个NAT的IP地址和不同的端口来连接众多的局域网服务器。
那么NAT有什么问题呢?
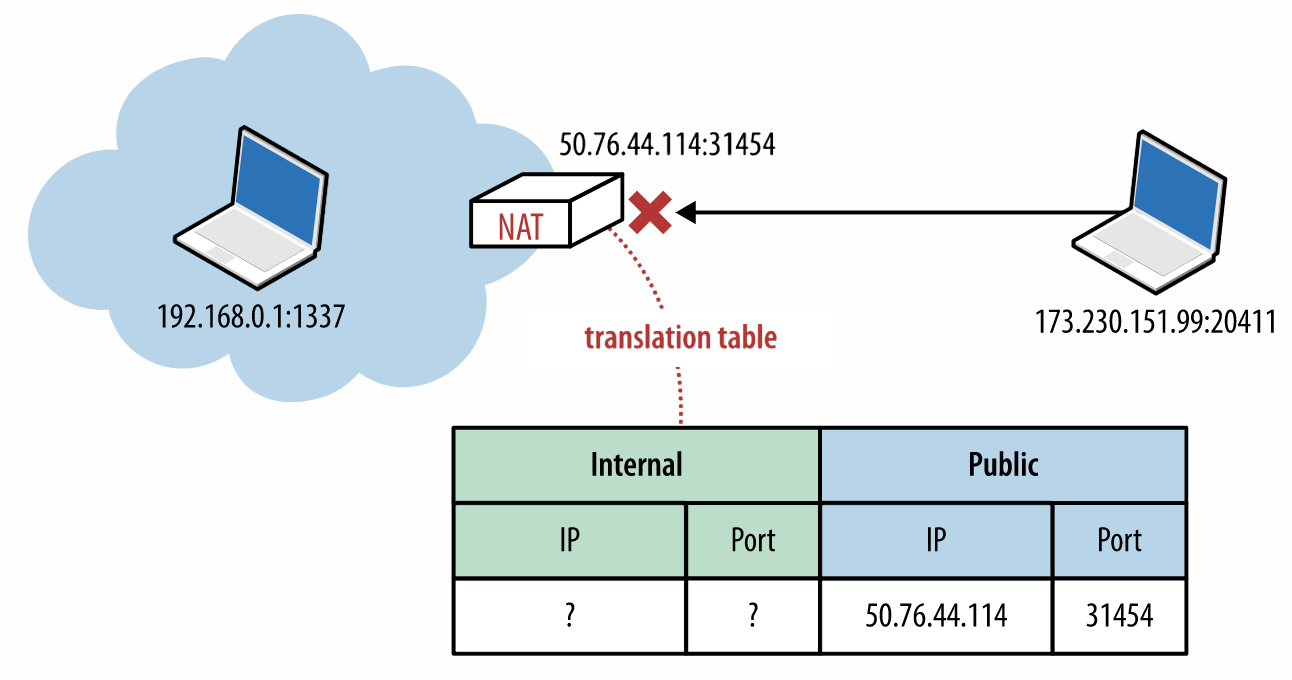
NAT的问题在于,内部客户端不知道自己外网IP地址,只知道内网IP地址。
如果是在UDP协议中,因为UDP是无状态的,所以需要NAT来重写每个UDP分组中的源端口、地址,以及IP分组中的源IP地址。
如果客户端是在应用程序内部将自己的IP地址告诉服务器,并想跟服务器建立连接,那么肯定是建立不了的。因为找不到客户端的公网IP。
即使找到了公网IP,任何到达NAT设备外网IP的分组还必须有一个目标端口,而且NAT转换表中也要有一个条目可以将其转换为内部主机的IP地址和端口号。否则就可能出现下图的连接失败的问题。
怎么解决呢?
第一种方式是使用STUN服务器。
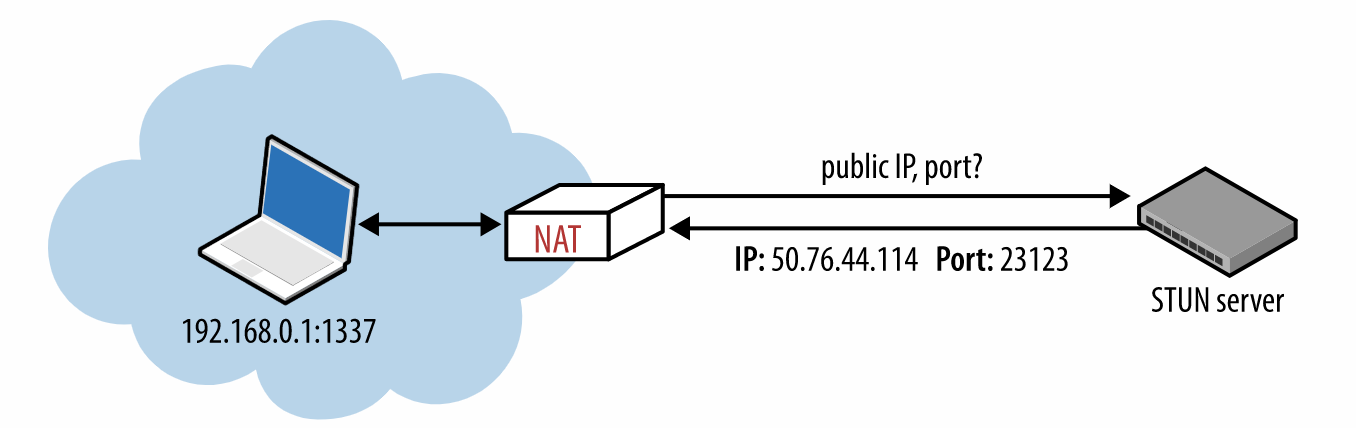
STUN服务器是IP地址已知的服务器,客户端要通信之前,先去STUN服务器上面查询一下自己的外网IP和端口,然后再使用这个外网IP和端口进行通信。
但有时UDP包会被防火墙或者其他的应用程序所阻挡。这个时候就可以使用中继器技术Traversal Using Relays around NAT (TURN) 。
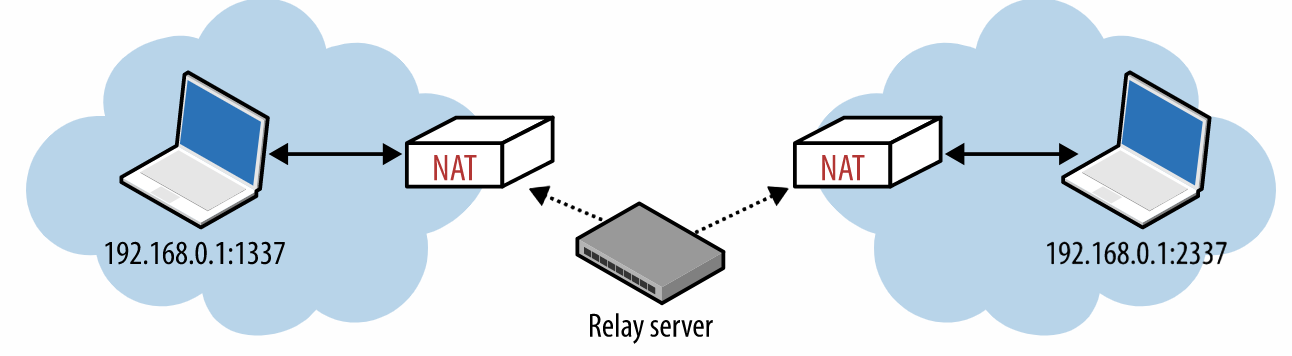
双方都将数据发送到中继器server,由中继器server来负责转发数据。注意,这里已经不是P2P了。
最后,我们有一个集大成者的协议叫做ICE(Interactive Connectivity Establishment ):
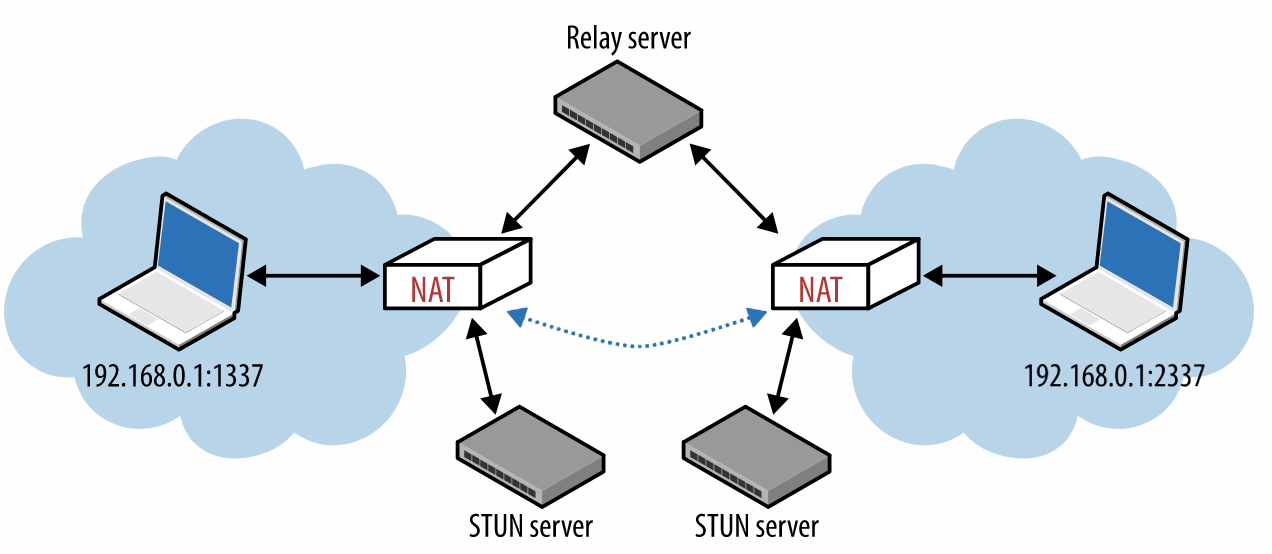
它实际上就是直连,STUN和TURN的综合体,能直连的时候就直连,不能直连就用STUN,不能用STUN就用TURN。
在使用STUN和ICE的过程中,我们会有一台网络主机用来建立端口映射和保持其他UDP端口状态,但是UDP的状态通常在几十秒到几分钟的短时间后过期,为了保证NAT中UDP的状态和生命周期,于是有了UDP hole punching的技术。通过定时传输keep-alive数据包,对NAT中的UDP状态进行更新。
UDT的缺点
因为UDT是基于UDP协议的,但是UDP协议因为其简洁的特性,所以并不具备安全性的特征。所以基于其上的UDT协议因为缺乏安全特性,所以在商业环境中应用会受到一定的限制。
不过UDT的新版本已经在开发中,大家可以期待一下。
总结
UDT被广泛用于高性能计算,比如光纤网络上的高速数据传输。我们后续会在netty中告诉大家怎么使用UDT协议。
本文已收录于 http://www.flydean.com/11-udt/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
网络协议之:基于UDP的高速数据传输协议UDT的更多相关文章
- python 之 网络编程(基于UDP协议的套接字通信)
8.5 基于UDP协议的套接字通信 UDP协议:数据报协议 特点:无连接,一发对应一收,先启动哪一端都不会报错 优点:发送效率高,但有效传输的数据量最多为500bytes 缺点:不可靠:发送数据,无需 ...
- 网络编程之基于UDP协议的套接字编程、基于socketserver实现并发的socket
目录 基于UDP协议的套接字编程 UDP套接字简单示例 服务端 客户端 基于socketserver实现并发的socket 基于TCP协议 server类 request类 继承关系 服务端 客户端1 ...
- TCP/IP网络编程之基于UDP的服务端/客户端
理解UDP 在之前学习TCP的过程中,我们还了解了TCP/IP协议栈.在四层TCP/IP模型中,传输层分为TCP和UDP这两种.数据交换过程可以分为通过TCP套接字完成的TCP方式和通过UDP套接字完 ...
- Java网络编程二--基于UDP的编程
DatagramSocket对象为基于UDP协议的Socket 构造器提供可以选择性绑定到指定端口和ip 创建完对象后调用:receive(DatagramPacket p) send(Dategra ...
- Python中的端口协议之基于UDP协议的通信传输
UDP协议: 1.python中基于udp协议的客户端与服务端通信简单过程实现 2.udp协议的一些特点(与tcp协议的比较) 3.利用socketserver模块实现udp传输协议的并 ...
- Linux网络编程:基于UDP的程序开发回顾篇
基于无连接的UDP程序设计 同样,在开发基于UDP的应用程序时,其主要流程如下: 对于面向无连接的UDP应用程序在开发过程中服务端和客户端的操作流程基本差不多.对比面向连接的TCP程序,服务端少了 ...
- 【Java网络编程】基于 UDP 的聊天通信
使用 udp 协议,写一个基于命令行的聊天软件:客户端跟服务端分别在命令行启动之后,客户端和服务器端可以互相发送数据. 代码实现如下: 一.创建线程 sendThread 和 receiveThrea ...
- 常用传输层协议(tcp/ip+udp)与常用应用层协议简述(http)
一.计算机网络体系结构 二.TCP与UDP差异 1.TCP是面向连接的可靠传输,UDP是面向无连接的不可靠传输 面向连接表现在3次握手,4次挥手:可靠传输表现在未进行4次挥手时的差错重传,超时重传: ...
- 网络协议-网络分层、TCP/UDP、TCP三次握手和四次挥手
网络的五层划分是什么? 应用层,常见协议:HTTP.FTP 传输层,常见协议:TCP.UDP 网络层,常见协议:IP 链路层 物理层 TCP 和 UDP 的区别是什么 TCP/UDP 都属于传输层的协 ...
随机推荐
- vuex基础(vuex基本结构与调用)
import Vue from 'vue'; import Vuex from 'vuex'; Vue.use(Vuex); const modulesA = { state:{//状态 count: ...
- Python 函数 参数传递
参数传递 在 python 中,类型属于对象,变量是没有类型的: a=[1,2,3] a="Runoob" 以上代码中,[1,2,3] 是 ...
- OWASP-Top5-(Security Misconfiguration 安全配置错误)
概述 从上一版的第 6 位开始,90% 的应用程序都经过了某种形式的错误配置测试.随着更多转向高度可配置的软件,看到这一类别上升也就不足为奇了.值得注意的CWE包括CWE-16 Configurati ...
- [bzoj1107]驾驶考试
转化题意,如果一个点k符合条件,当且仅当k能到达1和n考虑如果l和r($l<r$)符合条件,容易证明那么[l,r]的所有点都将会符合条件,因此答案是一个区间枚举答案区间[l,r],考虑如何判定答 ...
- JOI 2020 Final 题解
T1. 只不过是长的领带 大水题,把 \(a_i,b_i\) 从小到大排序. 发现最优方案只可能是大的 \(a_i\) 跟大的 \(b_i\) 匹配,小的 \(a_i\) 与小的 \(b_i\) 匹配 ...
- Codeforces 750E - New Year and Old Subsequence(线段树维护矩阵乘法,板子题)
Codeforces 题目传送门 & 洛谷题目传送门 u1s1 我做这道 *2600 的动力是 wjz 出了道这个套路的题,而我连起码的思路都没有,wtcl/kk 首先考虑怎样对某个固定的串计 ...
- Perl语言入门10-13
----------第十章 其他控制结构---------------- unless结构 unless($fred =~ /\A[A-Z_\w*\z]/i){print "yes" ...
- [Linux] 非root安装Lefse软件及其数据分析
说明 Lefse软件是宏组学物种研究常用软件,一般大家用在线版本即可.但要搭建在Linux集群环境中有点烦,记录一下折腾过程. 安装 这个软件是python2写的,因此假设我已经安装好了较高版本的py ...
- 毕业设计之zabbix=[web检测
网站对一个公司来说非常重要,里边包含了公司的业务,介绍和订单等相关信息,网站的宕掉了对公司的影响非常重大,所以要很好的对网站的页面进行监控 创建web场景 各部分介绍: Name:唯一的scenari ...
- STM32 BootLoader升级固件
一.知识点 1.BootLoader就是单片机启动时候运行的一段小程序,这段程序负责单片机固件的更新,也就是单片机选择性的自己给自己下程序.可以更新,也可以不更新,更新的话,BootLoader更新完 ...