Spark-寒假-实验1
(1)切换到目录 /usr/bin;
(2)查看目录/usr/local 下所有的文件;

(3)进入/usr 目录,创建一个名为 test 的目录,并查看有多少目录存在;
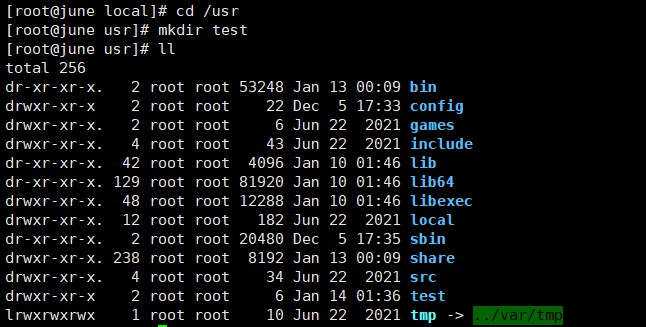
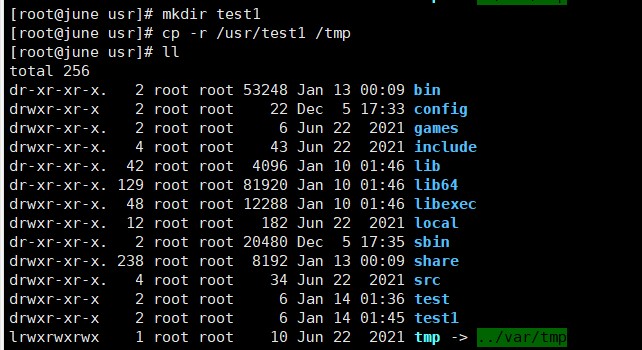
(4)在/usr 下新建目录 test1,再复制这个目录内容到/tmp;
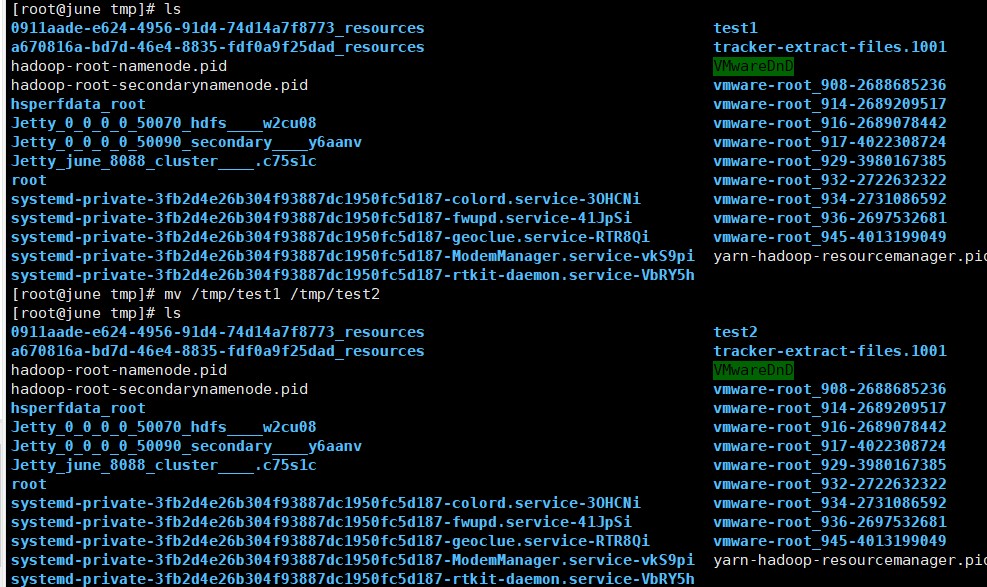
(5)将上面的/tmp/test1 目录重命名为 test2;
(6)在/tmp/test2 目录下新建 word.txt 文件并输入一些字符串保存退出;


(7)查看 word.txt 文件内容;

(8)将 word.txt 文件所有者改为 root 帐号,并查看属性;
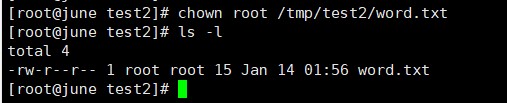
(9)找出/tmp 目录下文件名为 test2 的文件;

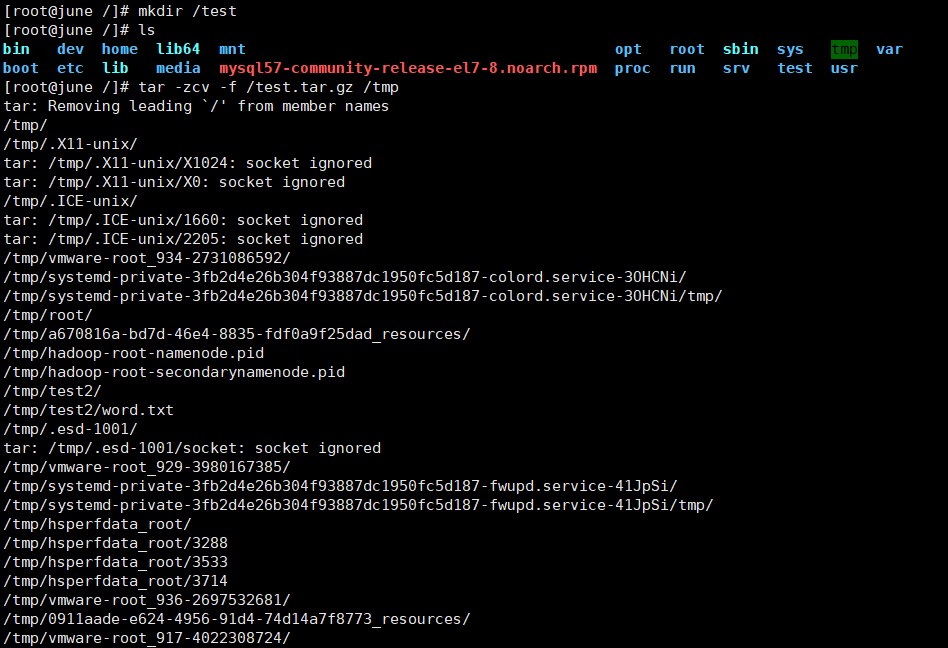
(10)在/目录下新建文件夹 test,然后在/目录下打包成 test.tar.gz;
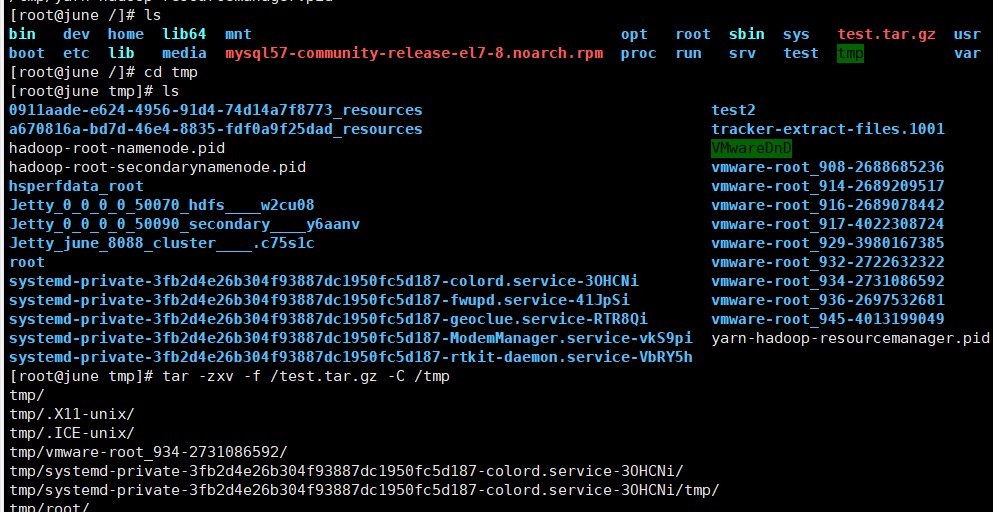
(11)将 test.tar.gz 解压缩到/tmp 目录。
Spark-寒假-实验1的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- spark学习及环境配置
http://dblab.xmu.edu.cn/blog/spark/ 厦大数据库实验室博客 总结.分享.收获 实验室主页 首页 大数据 数据库 数据挖掘 其他 子雨大数据之Spark入门教程 林子 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展.它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理.它直接支持多种数据源:Kafka, Flu ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- 2019寒假训练营第三次作业part2 - 实验题
热身题 服务器正在运转着,也不知道这个技术可不可用,万一服务器被弄崩了,那损失可不小. 所以, 决定在虚拟机上试验一下,不小心弄坏了也没关系.需要在的电脑上装上虚拟机和linux系统 安装虚拟机(可参 ...
- 1.Spark Streaming另类实验与 Spark Streaming本质解析
1 Spark源码定制选择从Spark Streaming入手 我们从第一课就选择Spark子框架中的SparkStreaming. 那么,我们为什么要选择从SparkStreaming入手开始我们 ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
随机推荐
- 使用react搭建组件库:react+typescript+storybook
前期准备 1. 初始化项目 npx create-react-app react-components --template typescript 2. 安装依赖 使用哪种打包方案:webpack/r ...
- SpringBoot使用Aspect切面拦截打印请求参数
引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>sp ...
- Sum Of Gcd(hdu 4676)
Sum Of Gcd Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Total ...
- CNN、RNN
卷积神经网络有三个结构上的特性:局部连接,权重共享以及空间或时间上的次采样.这些特性使得卷积神经网络具有一定程度上的平移.缩放和扭曲不变性. CNN由可学习权重和偏置的神经元组成.每个神经元接收多个输 ...
- Trial-faster-rcnn
目录 motivation 实验设置 实验结果 motivation 试一下faster rcnn的代码, 主要想看看backbone训练一部分好呢还是全部都训练好呢? 实验设置 Attribute ...
- matplotlib 进阶之Constrained Layout Guide
目录 简单的例子 Colorbars Suptitle Legends Padding and Spacing spacing with colobars rcParams Use with Grid ...
- vue基于Blob.js和 Export2Excel.js做前端导出
1安装三个依赖包 npm install -S file-saver@2.0.2 npm install -S xlsx@0.15.6 npm install -D script-loader@0.7 ...
- C++模拟python风格的print函数--打印vector,map,list等结构
// 最基本实现 template<typename T> static void print(T t) { std::cout << t; } // 处理 std::pair ...
- FP增长算法
Apriori原理:如果某个项集是频繁的,那么它的所有子集都是频繁的. Apriori算法: 1 输入支持度阈值t和数据集 2 生成含有K个元素的项集的候选集(K初始为1) 3 对候选集每个项集,判断 ...
- Spring企业级程序设计 • 【目录】
章节 内容 实践练习 Spring企业级程序设计目录(作业笔记) 第1章 Spring企业级程序设计 • [第1章 Spring之旅] 第2章 Spring企业级程序设计 • [第2章 Spring ...