Python常用功能函数系列总结(六)
本节目录
常用函数一:词云图
常用函数二:关键词清洗
常用函数三:中英文姓名转换
常用函数四:去除文本中的HTML标签和文本清洗
常用函数一:词云图
- wordcloud
# -*- coding: utf-8 -*- """
Datetime: 2020/06/28
Author: Zhang Yafei
Description: 词云图
"""
import os
import random import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from pylab import mpl
from wordcloud import WordCloud
import pandas as pd plt.figure(figsize=(13, 6), dpi=500) # 定义一个函数
def grey_color_func(word, font_size, position, orientation, ranndom_state=None, **kwargs):
return "hsl(0,0%%,%d%%)" % random.randint(60, 100) def plot_wordcloud(cols, rows, num, title, frequence_dict, mask_image='mask1.jpg'):
plt.subplot(rows, cols, num) # 背景图
root = os.path.dirname(__file__)
mask = np.array(Image.open(os.path.join(root, mask_image))) # 设置字体
font = os.path.join(root, 'simsun.ttc')
wordcloud = WordCloud(font_path=font, mask=mask, background_color='white').generate_from_frequencies(frequencies=frequence_dict) # 设置默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 标题
plt.title(title) # 显示我们生成图片
plt.imshow(wordcloud) plt.tight_layout()
# 去掉x,y轴的标签
plt.axis("off") def plot_wordcloud1(frequence_dict, title=None,mask_image='mask.png', bcolor='white'):
# 背景图
root = os.path.dirname(__file__)
mask = np.array(Image.open(os.path.join(root, mask_image))) # 设置字体
font = os.path.join(root, 'simsun.ttc')
wordcloud = WordCloud(scale=6, font_path=font, mask=mask, max_words=60, background_color=bcolor).generate_from_frequencies(frequencies=frequence_dict) # 设置默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 标题
if title: plt.title(title) # 显示我们生成图片
plt.imshow(wordcloud) # 去掉x,y轴的标签
plt.axis("off") if title:
plt.savefig(os.path.join('res', f'{title}.png'))
else:
plt.savefig(os.path.join('res', '词云图.png'))
plt.show() def read_data():
df = pd.read_excel('word_cloud_data.xlsx', index_col=0)
return df['freq'].to_dict() if __name__ == '__main__':
data_dict = read_data()
plot_wordcloud1(frequence_dict=data_dict)
- stylecloud
word.txt
暮色西去,留下了淡淡的忧伤。半帘落霞里,醉晕星辰、月隐山巅。一柳落背的残影孤独着滑进了山弯,悄悄的沉眠。烟尘朦胧中,岁月匆匆流逝,追逐着一轮远远的梦想。半盏残垣、两堵城池,萤火中幽香夜色。 剪一段经年,写一篇过往,流年里风月缠绵、轻浅如禅。心阅一卷时光,悠然里安静赏花、无语草香。红尘幽幽,行走在尘世的的路上,花间写诗,月下饮酒。一盏琉璃的浮华,云淡风轻中失落。一半的静谧、一半的安祥,遗留着许多错过的情爱、伤过的心灵。生命中太多的笔墨,纸砚一池安然。一扇时光中,悠香着一缕淡淡的芬芳,相伴着一份柔柔的恬淡。一本书写满了人生、一段情温暖了爱恋、一首诗记忆了曾经、一杯茶起落了缘份。握着最美的遇见,写下珍惜。携着最暖的心语,写意温馨。 烟雨下的春绿,伏笔了盛夏的明朗。海棠落月的幽静,缠绵着银色的月光,星光执笔的萧瑟和鸣里,轻笛梵音。花月中秦时幛幔垂垂,风尘里汉疆硝烟漫漫。 岁月咫尺、天涯相望。尘世匆匆,遥遥万里。留一片春风,栽一山桃源,幽静的心灵里,刻下了多少人的风花雪月、悲欢离合。恍恍惚惚的秋梦里,又有多少人发出了长长的的叹息。年年过四季,岁岁是轮回。 人生自己温一壶茶,烫也罢,凉也罢,苦也可,甜也可,自己慢慢品慢慢尝。 回想一世,不记得了誓言,也忘记了当初的承诺。什么时候两鬓斑白、皱纹沟壑,什么时候去过桃源,什么时候带雨梨花,都成了过往一笺无字的纸。 指尖拨动着岁月的年轮,把曾经都碾成了粉末。洒在大海里、洒在山谷中、种在大树下、种在田园里。明年又会长出春绿、长出秋黄、长出冬雪。再执笔展开红尘,一首岁月一首诗,一韵平仄一片情。 烟雨尘世,岁月匆匆……
代码
import jieba
from stylecloud import gen_stylecloud def cloud1(file_name):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) # 分词用 隔开
# 制作中文云词
gen_stylecloud(text=result,
font_path='C:\\Windows\\Fonts\\simhei.ttf',
output_name='t1.png',
) # 必须加中文字体,否则格式错误 def cloud2(file_name):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) # 分词用 隔开
# 制作中文云词
gen_stylecloud(text=result,
font_path='C:\\Windows\\Fonts\\simhei.ttf',
background_color='black',
output_name='t2.png',
) # 必须加中文字体,否则格式错误 def cloud3(file_name):
with open(file_name,'r',encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) #分词用 隔开
#制作中文云词
gen_stylecloud(text=result,
font_path='C:\\Windows\\Fonts\\simhei.ttf',
background_color= 'black',
#palette='cartocolors.diverging.ArmyRose_3',
palette='colorbrewer.diverging.Spectral_11',
output_name='t3.png',
) #必须加中文字体,否则格式错误 def cloud4(file_name):
with open(file_name,'r',encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) #分词用 隔开
#制作中文云词
gen_stylecloud(text=result,
font_path='C:\\Windows\\Fonts\\simhei.ttf',
# background_color= 'black',
palette='cartocolors.diverging.Fall_4',
icon_name='fas fa-plane',
output_name='t4.png',
) #必须加中文字体,否则格式错误 def cloud5(file_name):
with open(file_name,'r',encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) #分词用 隔开
#制作中文云词
gen_stylecloud(text=result,
font_path='C:\\Windows\\Fonts\\simhei.ttf',
# background_color= 'black',
palette='cartocolors.diverging.TealRose_2',
icon_name='fas fa-bell',
gradient='vertical' ,
output_name='t5.png',
) #必须加中文字体,否则格式错误 if __name__ == "__main__":
file_name = 'word.txt'
# cloud1(file_name)
# cloud2(file_name)
# cloud3(file_name)
# cloud4(file_name)
cloud5(file_name)





- pyecharts
示例1:
from pyecharts.charts import WordCloud
from pyecharts import options as opts
from pyecharts.globals import SymbolType
from snapshot_selenium import snapshot
from pyecharts.render import make_snapshot words = [("能天使", 10000), ("拉普兰德", 6181), ("艾雅法拉", 4386), ("银灰", 4055),
("德克萨斯", 2467), ("麦哲伦", 2244), ("伊芙利特", 1868), ("推进之王", 1484),
("煌", 1112), ("黑", 865), ("赫拉格", 847), ("风笛", 582), ("莫斯提玛", 555),
("空", 550), ("豆子龙", 462), ("斯卡蒂", 366), ("陨星", 360), ("白金之星", 282),
("天火", 273), ("塞雷亚", 265), ("星熊", 569), ("闪灵", 3598), ("夜莺", 1889),
] wordcloud = WordCloud(init_opts=opts.InitOpts(width='800px', height='600px'))
wordcloud.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
make_snapshot(snapshot, wordcloud.render('词云图示例.html'), '词云图.png')

常用函数二:关键词清洗
讲一下关键词分隔符统一替换成某一种符号,可扩展到文献数据的任意列,比如作者列


from pandas import read_excel # 关键词列分割标点序列
PUNCS = [';;', '; ', ';', ',']
# 指定关键词列分割标点
DEP = '; '
# 新作者列分割标点
RES_DEP = '; '
# 读取文件名
# FILE = '/Users/wangxiaoqi/Downloads/关键词数据清洗/NTDs数据清洗.xlsx'
FILE = 'NTDs数据清洗.xlsx'
# 表名 只有一张表的话可以不指定
SHEET_NAME = 'Sheet1'
# 作者列名
keywords_columns = 'keywords'
# 新作者列名
NEW_COLUMN = '关键词清洗'
# 结果文件存储路径
OUTPUT_FILE = '结果数据.xlsx' def keyword_clearup_mul_sep(keywords):
# print(keywords)
for punc in PUNCS:
if punc in keywords:
words = keywords.split(punc)
if '' in words:
words.remove('')
break
else:
words = [keywords]
return '; '.join(words) def main(dep_type='multi'):
"""
dep_type 若为multi 表示分割符有多种不统一 用PUNS中的标点分割
若为single 表示分隔符一致 用DEP分割
"""
print('正在读取数据文件---')
data = read_excel(FILE, sheet_name=SHEET_NAME) if SHEET_NAME else read_excel(FILE)
print('数据文件读取完成,开始转换---')
data.dropna(subset=['keywords'], inplace=True)
if dep_type == 'single':
data[NEW_COLUMN] = data[keywords_columns].str.replace(DEP, RES_DEP)
elif dep_type == 'multi':
data[NEW_COLUMN] = data[keywords_columns].apply(keyword_clearup_mul_sep)
data.to_excel(OUTPUT_FILE, index=False)
print(f'数据处理完成,结果文件存储在【{OUTPUT_FILE}】中') if __name__ == '__main__':
main(dep_type='multi')
# main(dep_type='single')
常用函数三:中英文姓名转换
需求:将数据中的中文作者名转换成英文,例如:张三装换成Zhang,San, 王老五 Wang,Laowu
原始数据:NTDs原始数据.xls
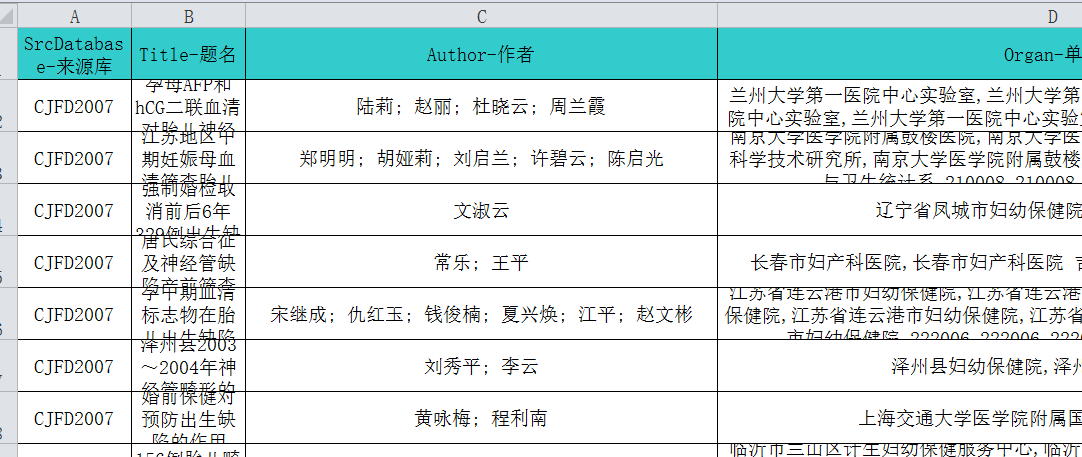
结果文件:结果数据.xlsx
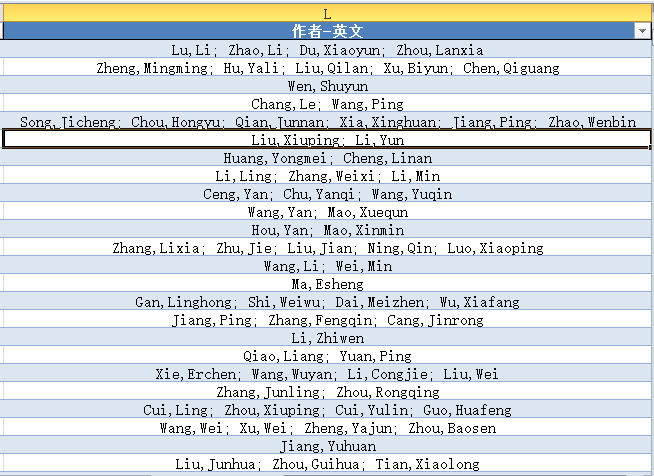
代码:
# -*- coding: utf-8 -*- """
Datetime: 2020/08/20
Author: Zhang Yafei
Description: 中英文姓名转换
"""
import time
from functools import wraps from pandas import read_excel
from pypinyin import lazy_pinyin # 作者列分割标点序列
PUNCS = [';;', '; ', ';', ',']
# 指定作者列分割标点
DEP = '; '
# 新作者列分割标点
RES_DEP = '; '
# 读取文件名
FILE = 'NTDs原始数据.xls'
# 表名 只有一张表的话可以不指定
SHEET_NAME = 'Sheet1'
# 作者列名
AUTHOR_COLUMN = 'Author-作者'
# 新作者列名
NEW_COLUMN = '作者-英文'
# 结果文件存储路径
OUTPUT_FILE = '结果数据.xlsx' def timeit(func):
"""
装饰器: 判断函数执行时间
:param func:
:return:
""" @wraps(func)
def inner(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
end = time.time() - start
if end < 60:
print(f'花费时间: {round(end, 2)}秒')
else:
min, sec = divmod(end, 60)
print(f'花费时间 {round(min)}分 {round(sec, 2)}秒')
return ret return inner def names_split(authors):
for punc in PUNCS:
if punc in authors:
names = authors.split(punc)
if '' in names:
names.remove('')
break
else:
names = [authors]
return names def name_ch_en_convert(names):
print(names)
if '' in names:
names.remove('')
en_names = ''
for name in names:
name_list = lazy_pinyin(name)
ming = ''.join(name_list[1:])
en_name = name_list[0] + "," + ming
en_name = en_name.title().strip(' ')
# print(name, en_name)
en_names += f'{en_name}{RES_DEP}'
print(en_names)
en_names = en_names.rstrip(RES_DEP)
return en_names @timeit
def main(dep_type='single'):
print('正在读取数据文件---')
data = read_excel(FILE, sheet_name=SHEET_NAME) if SHEET_NAME else read_excel(FILE)
print('数据文件读取完成,开始转换---')
if dep_type == 'multi':
data[NEW_COLUMN] = data[AUTHOR_COLUMN].apply(names_split).apply(name_ch_en_convert)
elif dep_type == 'single':
data[NEW_COLUMN] = data[AUTHOR_COLUMN].str.split(DEP).apply(name_ch_en_convert)
data.to_excel(OUTPUT_FILE, index=False)
print(f'数据处理完成,结果文件存储在【{OUTPUT_FILE}】中') if __name__ == '__main__':
main(dep_type='multi')
常用函数四:去除文本中的HTML标签及文本清洗
需求
有时我们爬取一些网页文本时,经常见到正文部分含有HTML标签的情况,而我们大部分情况下只是为了获取其中的文本,因此,需要对其中的HTML标签进行过滤。过滤之后,还需要进行文本清洗,即对其中的空格、换行符等字符进行替换和删除。

代码实现
# -*- coding: utf-8 -*- """
DateTime : 2020/12/03 21:25
Author : ZhangYafei
Description: 去除HTML标签和文本清洗
"""
import re
from bs4 import BeautifulSoup
from lxml import etree # html = '<p>你好</p><br/><font>哈哈</font><b>大家好</b>'
html = '''
<div class="pages_content">
<p style="font-size: 12pt; text-align: center;"><span style="font-family: 宋体; font-weight: bold;"><span style="font-size: 18pt;">财政部办公厅关于2020年抗疫特别国债(二期)</span><br>
</span><span style="font-family: 宋体; font-size: 12pt; text-indent: 2em;"><span style="font-weight: bold; font-size: 18pt;">发行工作有关事宜的通知</span><br>
</span><span style="font-size: 12pt; text-indent: 2em; font-family: 楷体, 楷体_GB2312;">财办库〔2020〕110号</span></p>
<p style="font-family: 宋体; font-size: 12pt;">2018-2020年记账式国债承销团成员,中央国债登记结算有限责任公司、中国证券登记结算有限责任公司、中国外汇交易中心、上海证券交易所、深圳证券交易所:</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">为筹集财政资金,统筹推进疫情防控和经济社会发展,财政部决定发行2020年抗疫特别国债(二期)。现就本期国债发行工作有关事宜通知如下:</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;"><span style="font-weight: bold;">一、发行条件</span></p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(一)品种和数量。本期国债为7年期固定利率附息债,竞争性招标面值总额500亿元,不进行甲类成员追加投标。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(二)日期安排。2020年6月18日招标,6月19日开始计息,招标结束至6月19日进行分销,6月23日起上市交易。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(三)兑付安排。本期国债利息按年支付,每年6月19日(节假日顺延,下同)支付利息,2027年6月19日偿还本金并支付最后一次利息。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(四)竞争性招标时间。2020年6月18日上午10:35至11:35。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(五)发行手续费。承销面值的0.1%。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;"><span style="font-weight: bold;">二、竞争性招标</span></p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(一)招标方式。采用修正的多重价格(即混合式)招标方式,标的为利率。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">(二)标位限定。投标剔除、中标剔除和每一承销团成员投标标位差分别为75个、15个和30个标位。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;"><span style="font-weight: bold;">三、发行款缴纳</span></p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">中标承销团成员于2020年6月19日前(含6月19日),将发行款缴入财政部指定账户。缴款日期以财政部指定账户收到款项为准。</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">收款人名称:中华人民共和国财政部</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">开户银行:国家金库总库</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">账号:270—207702—1</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">汇入行行号:011100099992</p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;"><span style="font-weight: bold;">四、其他</span></p>
<p style="text-indent: 2em; font-family: 宋体; font-size: 12pt;">除上述有关规定外,本期国债招标工作按《2020年记账式国债招标发行规则》执行。</p>
<p style="font-family: 宋体; font-size: 12pt; text-align: right;">财政部办公厅</p>
<p style="font-family: 宋体; font-size: 12pt; text-align: right;">2020年6月15日</p>
</div>
''' def remove_html_label(html: str):
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html) def remove_html_label2(html: str):
soup = BeautifulSoup(html, 'html.parser')
return soup.get_text() def remove_html_label3(html: str):
response = etree.HTML(text=html)
return response.xpath('string(.)') def process_text(content, word_list: list = None):
"""
文本清洗:对文本中的空格、换行等无效字符进行删除和替换
:param content:
:param word_list:
:return:
"""
content = content.replace('\n', '').replace(',', ' ').replace('。', ' ').replace('\t', '').replace(' ', '')
if word_list:
for word in word_list:
content = content.replace(word, '')
content = content.strip('\r\n').replace(u'\u3000', u'').replace(u'\xa0', u'')
return content if __name__ == '__main__':
text = remove_html_label(html=html)
text2 = remove_html_label2(html=html)
text3 = remove_html_label3(html=html)
print(text, text2, text3)
print(process_text(text))
打印结果
财政部办公厅关于2020年抗疫特别国债(二期)
发行工作有关事宜的通知
财办库〔2020〕110号
2018-2020年记账式国债承销团成员,中央国债登记结算有限责任公司、中国证券登记结算有限责任公司、中国外汇交易中心、上海证券交易所、深圳证券交易所:
为筹集财政资金,统筹推进疫情防控和经济社会发展,财政部决定发行2020年抗疫特别国债(二期)。现就本期国债发行工作有关事宜通知如下:
一、发行条件
(一)品种和数量。本期国债为7年期固定利率附息债,竞争性招标面值总额500亿元,不进行甲类成员追加投标。
(二)日期安排。2020年6月18日招标,6月19日开始计息,招标结束至6月19日进行分销,6月23日起上市交易。
(三)兑付安排。本期国债利息按年支付,每年6月19日(节假日顺延,下同)支付利息,2027年6月19日偿还本金并支付最后一次利息。
(四)竞争性招标时间。2020年6月18日上午10:35至11:35。
(五)发行手续费。承销面值的print(0.1%。
二、竞争性招标
(一)招标方式。采用修正的多重价格(即混合式)招标方式,标的为利率。
(二)标位限定。投标剔除、中标剔除和每一承销团成员投标标位差分别为75个、15个和30个标位。
三、发行款缴纳
中标承销团成员于2020年6月19日前(含6月19日),将发行款缴入财政部指定账户。缴款日期以财政部指定账户收到款项为准。
收款人名称:中华人民共和国财政部
开户银行:国家金库总库
账号:270—207702—1
汇入行行号:011100099992
四、其他
除上述有关规定外,本期国债招标工作按《2020年记账式国债招标发行规则》执行。
财政部办公厅
2020年6月15日 财政部办公厅关于2020年抗疫特别国债(二期)
发行工作有关事宜的通知
财办库〔2020〕110号
2018-2020年记账式国债承销团成员,中央国债登记结算有限责任公司、中国证券登记结算有限责任公司、中国外汇交易中心、上海证券交易所、深圳证券交易所:
为筹集财政资金,统筹推进疫情防控和经济社会发展,财政部决定发行2020年抗疫特别国债(二期)。现就本期国债发行工作有关事宜通知如下:
一、发行条件
(一)品种和数量。本期国债为7年期固定利率附息债,竞争性招标面值总额500亿元,不进行甲类成员追加投标。
(二)日期安排。2020年6月18日招标,6月19日开始计息,招标结束至6月19日进行分销,6月23日起上市交易。
(三)兑付安排。本期国债利息按年支付,每年6月19日(节假日顺延,下同)支付利息,2027年6月19日偿还本金并支付最后一次利息。
(四)竞争性招标时间。2020年6月18日上午10:35至11:35。
(五)发行手续费。承销面值的0.1%。
二、竞争性招标
(一)招标方式。采用修正的多重价格(即混合式)招标方式,标的为利率。
(二)标位限定。投标剔除、中标剔除和每一承销团成员投标标位差分别为75个、15个和30个标位。
三、发行款缴纳
中标承销团成员于2020年6月19日前(含6月19日),将发行款缴入财政部指定账户。缴款日期以财政部指定账户收到款项为准。
收款人名称:中华人民共和国财政部
开户银行:国家金库总库
账号:270—207702—1
汇入行行号:011100099992
四、其他
除上述有关规定外,本期国债招标工作按《2020年记账式国债招标发行规则》执行。
财政部办公厅
2020年6月15日 财政部办公厅关于2020年抗疫特别国债(二期)
发行工作有关事宜的通知
财办库〔2020〕110号
2018-2020年记账式国债承销团成员,中央国债登记结算有限责任公司、中国证券登记结算有限责任公司、中国外汇交易中心、上海证券交易所、深圳证券交易所:
为筹集财政资金,统筹推进疫情防控和经济社会发展,财政部决定发行2020年抗疫特别国债(二期)。现就本期国债发行工作有关事宜通知如下:
一、发行条件
(一)品种和数量。本期国债为7年期固定利率附息债,竞争性招标面值总额500亿元,不进行甲类成员追加投标。
(二)日期安排。2020年6月18日招标,6月19日开始计息,招标结束至6月19日进行分销,6月23日起上市交易。
(三)兑付安排。本期国债利息按年支付,每年6月19日(节假日顺延,下同)支付利息,2027年6月19日偿还本金并支付最后一次利息。
(四)竞争性招标时间。2020年6月18日上午10:35至11:35。
(五)发行手续费。承销面值的0.1%。
二、竞争性招标
(一)招标方式。采用修正的多重价格(即混合式)招标方式,标的为利率。
(二)标位限定。投标剔除、中标剔除和每一承销团成员投标标位差分别为75个、15个和30个标位。
三、发行款缴纳
中标承销团成员于2020年6月19日前(含6月19日),将发行款缴入财政部指定账户。缴款日期以财政部指定账户收到款项为准。
收款人名称:中华人民共和国财政部
开户银行:国家金库总库
账号:270—207702—1
汇入行行号:011100099992
四、其他
除上述有关规定外,本期国债招标工作按《2020年记账式国债招标发行规则》执行。
财政部办公厅
2020年6月15日 财政部办公厅关于2020年抗疫特别国债(二期)发行工作有关事宜的通知财办库〔2020〕110号2018-2020年记账式国债承销团成员中央国债登记结算有限责任公司、中国证券登记结算有限责任公司、中国外汇交易中心、上海证券交易所、深圳证券交易所:为筹集财政资金统筹推进疫情防控和经济社会发展财政部决定发行2020年抗疫特别国债(二期)现就本期国债发行工作有关事宜通知如下:一、发行条件(一)品种和数量本期国债为7年期固定利率附息债竞争性招标面值总额500亿元不进行甲类成员追加投标(二)日期安排2020年6月18日招标6月19日开始计息招标结束至6月19日进行分销6月23日起上市交易(三)兑付安排本期国债利息按年支付每年6月19日(节假日顺延下同)支付利息2027年6月19日偿还本金并支付最后一次利息(四)竞争性招标时间2020年6月18日上午10:35至11:35(五)发行手续费承销面值的0.1%二、竞争性招标(一)招标方式采用修正的多重价格(即混合式)招标方式标的为利率(二)标位限定投标剔除、中标剔除和每一承销团成员投标标位差分别为75个、15个和30个标位三、发行款缴纳中标承销团成员于2020年6月19日前(含6月19日)将发行款缴入财政部指定账户缴款日期以财政部指定账户收到款项为准收款人名称:中华人民共和国财政部开户银行:国家金库总库账号:270—207702—1汇入行行号:011100099992四、其他除上述有关规定外本期国债招标工作按《2020年记账式国债招标发行规则》执行财政部办公厅2020年6月15日
Python常用功能函数系列总结(六)的更多相关文章
- Python常用功能函数系列总结(一)
本节目录 常用函数一:获取指定文件夹内所有文件 常用函数二:文件合并 常用函数三:将文件按时间划分 常用函数四:数据去重 写在前面 写代码也有很长时间了,总觉得应该做点什么有价值的事情,写代码初始阶段 ...
- Python常用功能函数系列总结(二)
本节目录 常用函数一:sel文件转换 常用函数二:refwork文件转换 常用函数三:xml文档解析 常用函数四:文本分词 常用函数一:sel文件转换 sel是种特殊的文件格式,具体应用场景的话可以 ...
- Python常用功能函数系列总结(三)
本节目录 常用函数一:词频统计 常用函数二:word2vec 常用函数三:doc2vec 常用函数四:LDA主题分析 常用函数一:词频统计 # -*- coding: utf-8 -*- " ...
- Python常用功能函数系列总结(七)
本节目录 常用函数一:批量文件重命名 常用函数一:批量文件重命名 # -*- coding: utf-8 -*- """ DateTime : 2021/02/08 10 ...
- Python常用功能函数系列总结(五)
本节目录 常用函数一:向量距离和相似度计算 常用函数二:pagerank 常用函数三:TF-IDF 常用函数四:关键词提取 常用函数一:向量距离和相似度计算 KL距离.JS距离.余弦距离 # -*- ...
- Python常用功能函数系列总结(四)之数据库操作
本节目录 常用函数一:redis操作 常用函数二:mongodb操作 常用函数三:数据库连接池操作 常用函数四:pandas连接数据库 常用函数五:异步连接数据库 常用函数一:redis操作 # -* ...
- Python常用功能函数总结系列
Python常用功能函数系列总结(一) 常用函数一:获取指定文件夹内所有文件 常用函数二:文件合并 常用函数三:将文件按时间划分 常用函数四:数据去重 Python常用功能函数系列总结(二) 常用函数 ...
- Python常用功能函数
Python常用功能函数汇总 1.按行写字符串到文件中 import sys, os, time, json def saveContext(filename,*name): format = '^' ...
- Python 常用string函数
Python 常用string函数 字符串中字符大小写的变换 1. str.lower() //小写>>> 'SkatE'.lower()'skate' 2. str.upper ...
随机推荐
- 令无数程序员加班的 Log4j2 远程执行漏洞复现
前情提要 Apache 存在 Log4j 远程代码执行漏洞,将给相关企业带来哪些影响?还有哪些信息值得关注? 构建maven项目引入Log4j2 编写 pom 文件 <?xml version= ...
- cmd窗口连接mongodb服务端
1----->配置环境变量,将mongodb\bin目录配置到path 2----->打开cmd窗口,进入到bin目录,测试mongodb服务端是否在运行:net start mongod ...
- picoctf_2018_rop chain
拿到题目就知道要用rop来做 老样子日常检查一下 32位的程序开启了nx和relro保护 将程序放入ida中 一眼就看到了程序中的后门程序 我们逐一分析一下 main vuln get没有对输入字符进 ...
- [HarekazeCTF2019]baby_rop
看到名字就想到了用rop来做这道题 老样子chescksec和file一下 可以看到是64位的程序开启了nx保护,把程序放到idax64里 可以看到有system和/bin/sh,/bin/sh无法跟 ...
- C#汉字转汉语拼音
一.使用PinYinConverterCore获取汉语拼音 最新在做一个搜索组件,需要使用汉语拼音的首字母查询出符合条件的物品名称,由于汉字存在多音字,所以自己写查询组件不太现实,因此,我们使用微软提 ...
- CF415A Mashmokh and Lights 题解
Content 有 \(n\) 个灯,一开始都是亮着的. 有 \(m\) 次操作,每次操作按下开关 \(x\),按下之后所有编号 \(\geqslant x\) 的灯全部熄灭.问你所有的灯第一次被熄灭 ...
- CF152A Marks 题解
Content 有 \(n\) 名学生考了 \(m\) 门科目,各得到了自己的成绩单.如果第 \(i\) 个学生的第 \(j\) 个科目的分数 \(a_{i,j}\) 在所有学生中是最高的,那么我们就 ...
- 常用DBhelper封装方法
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threa ...
- ligerui有时候竖直的线没对齐,是因为某一列的内容太长,此刻可以调整一下此列的宽度为适当的值便可消除此现象
ligerui有时候竖直的线没对齐,是因为某一列的内容太长,此刻可以调整一下此列的宽度为适当的值便可消除此现象
- python 豆瓣top250
豆瓣电影 import re import requests headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; ...