安装hadoop2.9.2单机版本 jdk1.8 centos7
安装JDK1.8
查看JDK1.8的安装
https://www.cnblogs.com/TJ21/p/13715749.html
安装hadoop
上传hadoop
下载hadoop 地址http://mirrors.hust.edu.cn/apache/hadoop/common/
放到mkdir /usr/local/src/hadoop目录下
解压 tar -zxvf hadoop-2.9.2.tar.gz
配置环境变量
vi /etc/profile 添加如下配置 export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$PATH 重新刷新配置 source /etc/profile 查看版本 hadoop version
修改配置文件
vi core-site.xml
路径是 cd /usr/local/src/hadoop/hadoop-2.9.2/etc/hadoop
vi core-site.xml 添加如下配置
<property>
<name>fs.defaultFS</name>
<!-- 这里填的是你自己的ip,端口默认-->
<value>hdfs://192.168.0.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 这里填的是你自定义的hadoop工作的目录,端口默认-->
<value>/usr/local/src/hadoop/hadoop-2.9.2/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>Should native hadoop libraries, if present, be used.
</description>
</property>
vi hadoop-env.sh 配置成你自己的jdk安装路径
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.secondary.http.address</name> <!--这里是你自己的ip,端口默认-->
<value>192.168.0.130:50090</value>
</property>
vi mapred-site.xml
复制默认的cp mapred-site.xml.template ./mapred-site.xml 配置命名为mapred-site.xml
vi mapred-site.xml 添加如下配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 自己的ip端口默认 -->
<value>192.168.0.130</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置完成启动
配置好之后切换到sbin目录下
cd /usr/local/src/hadoop/hadoop-2.9.2/sbin/ 查看命令 ll
格式化hadoop文件格式,执行命令 hadoop namenode -format,成功之后启动
执行启动所有命令
./start-all.sh
没启动一个进程需要输入密码,可以通过配置ssh来解决,就不需要输入了,暂时配置
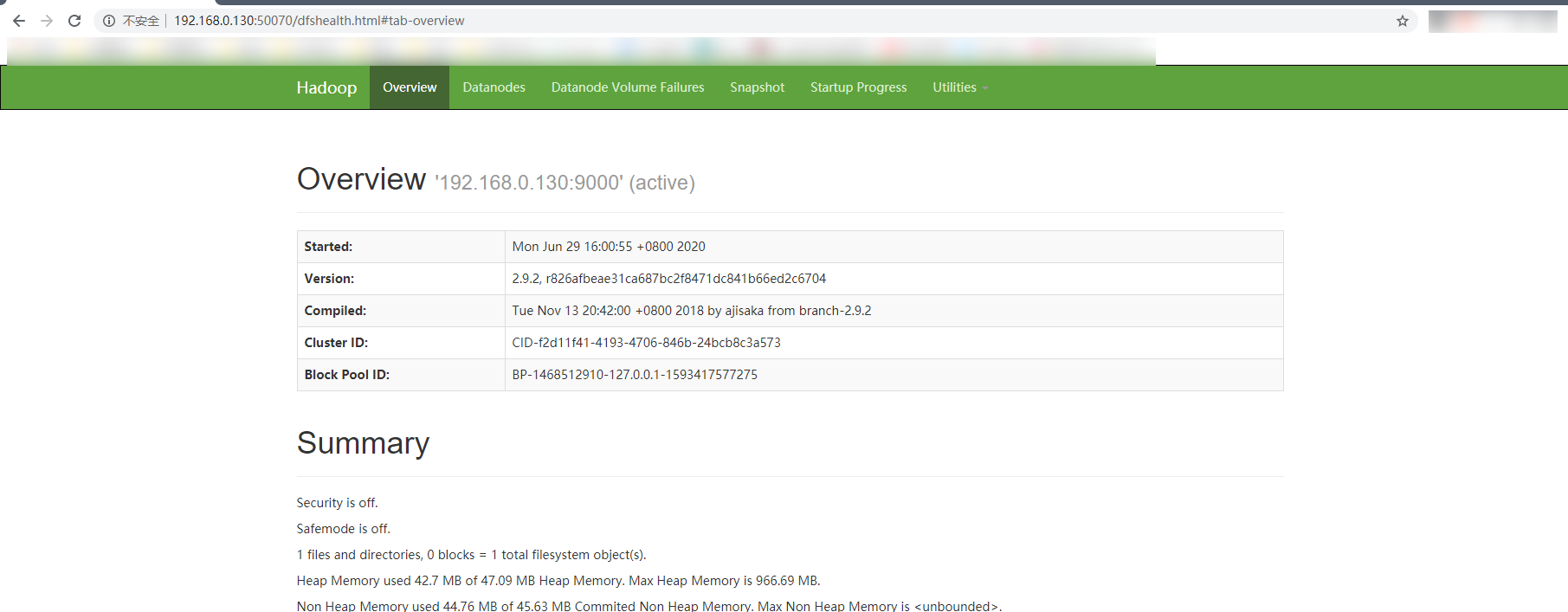
使用 jps 查看进程,能看到这些进程证明启动成功了,
也可以通过网页来查看 192.168.0.130:50070 此处的ip是自己的虚拟机IP
关闭防火墙的方法为:
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动
安装hadoop2.9.2单机版本 jdk1.8 centos7的更多相关文章
- Windows 2016 安装单机版本Oracle ASM 的简单说明
发现这样弄完 启动之后 就挂了 真蛋疼. 改天再研究一下. 1. 需要给磁盘处理一下 建议使用压缩卷的模式进行处理 如图示 需要新建简单卷 注意设置 然后不进行格式化 2. 然后安装oracle的g ...
- Ubuntu14.04下安装Hadoop2.5.1 (单机模式)
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-standalone-mode.html,转载请注明源地址. 欢迎关注我的个人博客:www.wuyudo ...
- hadoop2.7.2单机与伪分布式安装
环境相关 系统:CentOS 6.8 64位 jdk:1.7.0_79 hadoop:hadoop 2.7.2 安装java环境 详见:linux中搭建java开发环境 创建hadoop用户 # 以r ...
- Hadoop2.6 安装布置问题总结(单机、分布式)
在debian7虚拟机上安装hadoop2.6,期间遇到一些问题在此记录一下. 安装参考: Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04 Hadoop集群安 ...
- centos单机安装Hadoop2.6
一,安装环境 硬件:虚拟机 操作系统:Centos 6.4 64位 IP:10.51.121.10 主机名:datanode-4 安装用户:root 二,安装JDK 安装JDK1.6或者以上版本.这里 ...
- 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- Redis单机版本的安装
我的是centos-6.5的环境,安装redis的单机版本 1.下载redis源文件redis-3.0.0.tar.gz到一个目录,我的下载目录是/software 2.编译安装源文件的先觉条件是安装 ...
- Ubuntu 14.04下安装Hadoop2.4.0 (单机模式)
转自 http://www.linuxidc.com/Linux/2015-01/112370.htm 一.在Ubuntu下创建Hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增 ...
- JDK1.6 1.7 1.8 多版本windows安装 执行命令java -version 版本不变的问题
现在Windows的java安装已经没有解压版本,Oracle官方也不会再提供了,只有安装程序 所以每当安装一次JDK,都会将 java.exe.javaw.exe.javaws.exe三个可执行文件 ...
随机推荐
- Istio在Rainbond Service Mesh体系下的落地实践
两年前Service Mesh(服务网格)一出来就受到追捧,很多人认为它是微服务架构的最终形态,因为它可以让业务代码和微服务架构解耦,也就是说业务代码不需要修改就能实现微服务架构,但解耦还不够彻底,使 ...
- 【Web】BUUCTF-warmup(CVE-2018-12613)
BUUCTF 的第一题,上来就给搞懵了.. .这要是我自己做出来的,岂不是相当于挖了一个 CVE ?(菜鸡这样安慰自己) 问题在 index.php 的 55~63 行 // If we have ...
- Sql 查询语句优化
sql查询很慢,很多时候并不是数据量大,而是sql语法使用不正确,本文讲述了基础语法使用,避免一些不必要的坑. explain select * from user;--查询执行时间 目录 Sql 优 ...
- CF946B Weird Subtraction Process 题解
Content 有两个数 \(a,b\),执行如下操作: 如果 \(a,b\) 中有一个数是 \(0\),结束操作,否则跳到操作 \(2\). 如果 \(a\geqslant 2b\),那么 \(a\ ...
- .NET 6 优先队列 PriorityQueue 实现分析
在最近发布的 .NET 6 中,包含了一个新的数据结构,优先队列 PriorityQueue, 实际上这个数据结构在隔壁 Java中已经存在了很多年了, 那优先队列是怎么实现的呢? 让我们来一探究竟吧 ...
- 网络路径排查工具使用/原理浅析(MTR、traceroute、tracepath、windows下besttrace)
在请求网络资源获取缓慢或者有丢包过程中.经常会使用到网络路径探测工具.linux 下最常用的有mtr.traceroute.tracepath 等. 你是否有一点疑惑,路径探测的原理到底是如何完成的, ...
- 当页面是本地页面时,通过ajax访问tomcat里的action,传递的参数在action里并不能识别
当页面是本地页面时,通过ajax访问tomcat里的action,传递的参数在action里并不能识别,这个问题困扰了我不少时间. 在测试时发现此问题
- [源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程
[源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程 目录 [源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程 0x00 摘要 0x01 ...
- JAVA字符串去掉html代码,获取内容
有时候我们需要在html代码中获取到文本内容,需要把html代码中的标签过滤掉 String htmlStr="html代码"; htmlStr = htmlStr.replace ...
- hdu-1593 find a way to escape(贪心,数学)
思路:两个人都要选取最优的策略. 先求外层那个人的角速度,因为他的角速度是确定的,再求内层人的当角速度和外层人一样时的对应的圆的半径r1.外层圆的半径为d; 那么如果r1>=外围圆的半径,那么肯 ...