oracle 碎片管理和数据文件resize释放表空间和磁盘空间(以及sys.wri$_optstat_histgrm_history过大处理)
因此,只能将数据文件缩小到高水位线,因为高水位线以下有一些空白。
因此,在这种情况下(删除太多),要在数据文件上占用更多空间,首先,重组表,重置高水位线,然后再次缩小数据文件。
这样我们可以在磁盘级别上释放更多的空间。

文档资料和脚本来自support文献编号:
2348230.1,1019709.6,1020182.6,186826.1等。
一.遇到的案例
windows oracle 11.2.0.4空间不太够,然后查看实际表占的空间不足40G,但是数据文件占用了100多G,业务表名空间数据文件用的都是ASSM管理;除了处理碎片之外,还需要收缩数据文件(缩小所占用的空间)。
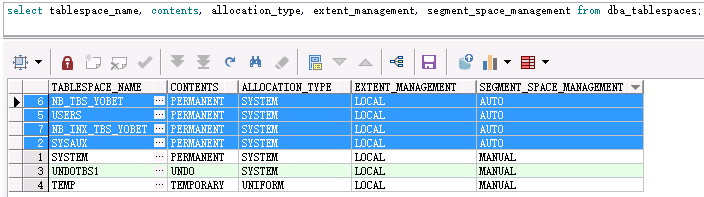
查看表空间数据文件管理方式:
select tablespace_name, contents, allocation_type, extent_management, segment_space_management from dba_tablespaces;
--查看表空间使用和剩余大小:
select a.TABLESPACE_NAME tbs_name,
round(a.BYTES/1024/1024) Total_MB,
round((a.BYTES-nvl(b.BYTES, 0)) /1024/1024) Used_MB,
round((1-((a.BYTES-nvl(b.BYTES,0))/a.BYTES))*100,2) Pct_Free,
nvl(round(b.BYTES/1024/1024), 0) Free_MB ,
auto
from (select TABLESPACE_NAME,
sum(BYTES) BYTES,
max(AUTOEXTENSIBLE) AUTO
from sys.dba_data_files
group by TABLESPACE_NAME) a,
(select TABLESPACE_NAME,
sum(BYTES) BYTES
from sys.dba_free_space
group by TABLESPACE_NAME) b
where a.TABLESPACE_NAME = b.TABLESPACE_NAME (+)
order by ((a.BYTES-b.BYTES)/a.BYTES) desc
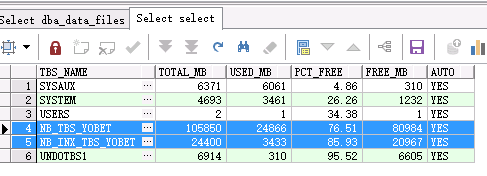
实力上表使用的空间约37GB
select round(sum(bytes/1024/1024/1024),2) G from dba_segments ;
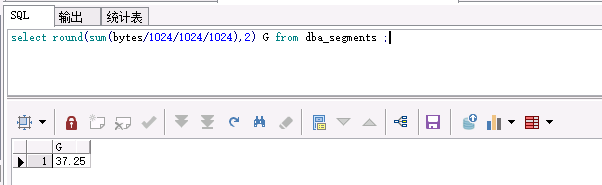
但是数据文件占用的表空间约144GB
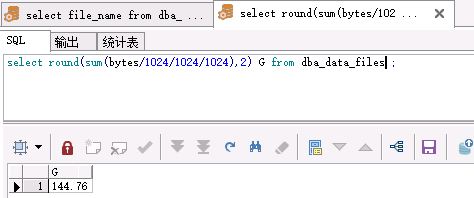
comp sum of nfrags totsiz avasiz on report
break on report col tsname format a16 justify c heading 'Tablespace'
col nfrags format 999,990 justify c heading 'Free|Frags'
col mxfrag format 999,999,990 justify c heading 'Largest|Frag (KB)'
col totsiz format 999,999,990 justify c heading 'Total|(KB)'
col avasiz format 999,999,990 justify c heading 'Available|(KB)'
col pctusd format 990 justify c heading 'Pct|Used' select
total.tablespace_name tsname,
count(free.bytes) nfrags,
nvl(max(free.bytes)/1024,0) mxfrag,
total.bytes/1024 totsiz,
nvl(sum(free.bytes)/1024,0) avasiz,
(1-nvl(sum(free.bytes),0)/total.bytes)*100 pctusd
from
dba_data_files total,
dba_free_space free
where
total.tablespace_name = free.tablespace_name(+)
and total.file_id=free.file_id(+)
group by
total.tablespace_name,
total.bytes
/
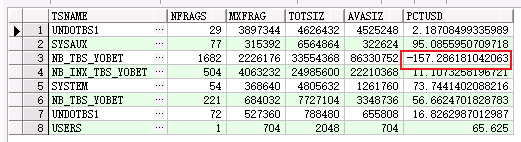
--这个是support脚本,检查表空间碎片数
select substr(a.tablespace_name,1,20) tablespace,
round(sum(a.total1)/1024/1024, 1) Total,
round(sum(a.total1)/1024/1024, 1)-round(sum(a.sum1)/1024/1024, 1)
used,
round(sum(a.sum1)/1024/1024, 1) free,
round(round(sum(a.sum1)/1024/1024, 1)*100/round(sum(a.total1)/1024/1024, 1),1) pct_free,
round(sum(a.maxb)/1024/1024, 1) largest,
max(a.cnt) fragments
from
(select tablespace_name, 0 total1, sum(bytes) sum1,
max(bytes) MAXB,
count(bytes) cnt
from dba_free_space
group by tablespace_name
union
select tablespace_name, sum(bytes) total1, 0, 0, 0
from dba_data_files
group by tablespace_name
) a
group by a.tablespace_name;
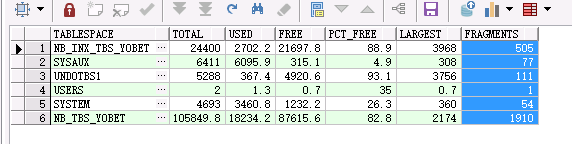
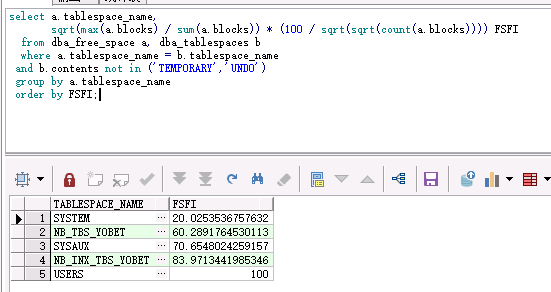
--查看表空间计算FSFI(Free Space Fragmentation Index)值
select a.tablespace_name,
sqrt(max(a.blocks) / sum(a.blocks)) * (100 / sqrt(sqrt(count(a.blocks)))) FSFI
from dba_free_space a, dba_tablespaces b
where a.tablespace_name = b.tablespace_name
and b.contents not in ('TEMPORARY','UNDO')
group by a.tablespace_name
order by FSFI;

这两个表空间是业务表空间,如果FSFI值 < 30%,则该表空间的碎片较多(该数据库每天都有定时任务收集统计信息,不会存在统计信息的偏差);
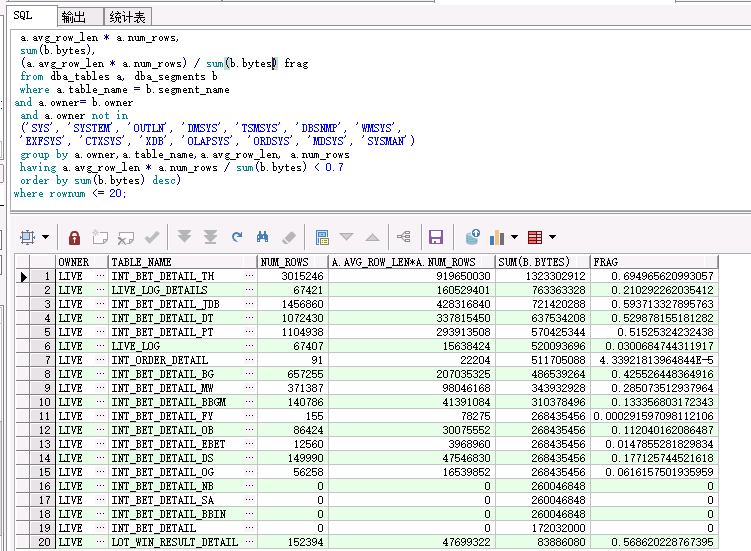
--检查碎片最严重的前100张表,实际我只检查了前20张表就够了
col frag format 999999.99
col owner format a30;
col table_name format a30;
select * from (
select a.owner,
a.table_name,
a.num_rows,
a.avg_row_len * a.num_rows,
sum(b.bytes),
(a.avg_row_len * a.num_rows) / sum(b.bytes) frag
from dba_tables a, dba_segments b
where a.table_name = b.segment_name
and a.owner= b.owner
and a.owner not in
('SYS', 'SYSTEM', 'OUTLN', 'DMSYS', 'TSMSYS', 'DBSNMP', 'WMSYS',
'EXFSYS', 'CTXSYS', 'XDB', 'OLAPSYS', 'ORDSYS', 'MDSYS', 'SYSMAN')
group by a.owner,a.table_name,a.avg_row_len, a.num_rows
having a.avg_row_len * a.num_rows / sum(b.bytes) < 0.7
order by sum(b.bytes) desc)
where rownum <= 100;
--检查Oracle在索引碎片
col tablespace_name format a20;
col owner format a10;
col index_name format a30;
select id.tablespace_name,
id.owner,
id.index_name,
id.blevel,
sum(sg.bytes) / 1024 / 1024,
sg.blocks,
sg.extents
from dba_indexes id, dba_segments sg
where id.owner = sg.owner
and id.index_name = sg.segment_name
and id.tablespace_name = sg.tablespace_name
and id.owner not in
('SYS', 'SYSTEM', 'USER', 'DBSNMP', 'ORDSYS', 'OUTLN')
and sg.extents > 100
and id.blevel >= 3
group by id.tablespace_name,
id.owner,
id.index_name,
id.blevel,
sg.blocks,
sg.extents
having sum(sg.bytes) / 1024 / 1024 > 100;
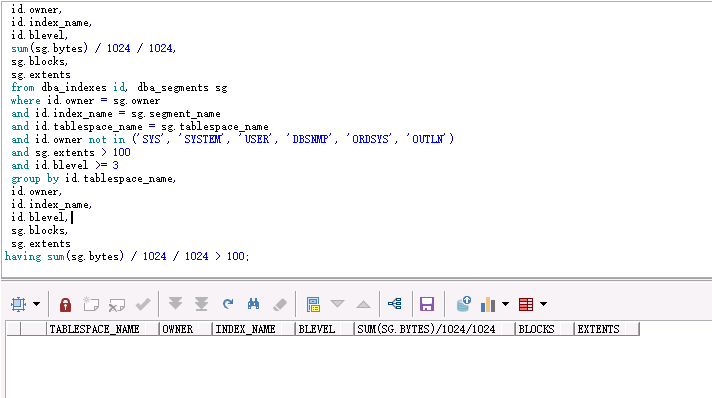
如果有索引层级未Blevel >=3,并且索引大小超过100M的索引。则需要进行Analyze index。
- Analyze index方法
analyze index <Index_name> validate structure;
select DEL_LF_ROWS * 100 / decode(LF_ROWS, 0, 1, LF_ROWS) PCT_DELETED from index_stats;
二.碎片处理方式
2.1.首选shrink
alter table <表名> enable row movement;
alter table <表名> shrink space compact; --- 只压缩数据不下调HWM
alter table <表名> shrink space; --- 下调HWM;
alter table <表名> shrink space cascade; --- 压缩表及相关数据段并下调HWM
alter table <表名> disable row movement;
select * from (
select
a.table_name,
'alter table '||a.table_name||' enable row movement ; ',
'alter table '||a.table_name||' shrink space compact ; ',
'alter table '||a.table_name||' shrink space cascade ; ',
'alter table '||a.table_name||' disable row movement ;',
a.num_rows,
a.avg_row_len * a.num_rows,
round(sum(b.bytes/1024/1024/1024),2) G,
(a.avg_row_len * a.num_rows) / sum(b.bytes) frag
from dba_tables a, dba_segments b
where a.table_name = b.segment_name
and a.owner= b.owner
and a.owner not in
('SYS', 'SYSTEM', 'OUTLN', 'DMSYS', 'TSMSYS', 'DBSNMP', 'WMSYS',
'EXFSYS', 'CTXSYS', 'XDB', 'OLAPSYS', 'ORDSYS', 'MDSYS', 'SYSMAN')
group by a.owner,a.table_name,a.avg_row_len, a.num_rows
having a.avg_row_len * a.num_rows / sum(b.bytes) < 0.7
order by round(sum(b.bytes/1024/1024/1024),2) desc)
where rownum <= 20;
把生产的shrink语句执行一下。

进行shrink之后,进行数据文件的收缩如下。
执行后进行数据文件的收缩:
SELECT a.tablespace_name,
'alter database datafile ''' || a.file_name || ''' resize ' ||
round(ceil(b.resize_to / 1024 / 1024 / 1024), 2) || 'G;' AS "resize_SQL",
round(a.bytes / 1024 / 1024 / 1024, 2) AS "current_bytes(GB)",
round(a.bytes / 1024 / 1024 / 1024 -
b.resize_to / 1024 / 1024 / 1024,
2) AS "shrink_by_bytes(GB)",
round(ceil(b.resize_to / 1024 / 1024 / 1024), 2) AS "resize_to_bytes(GB)"
FROM dba_data_files a,
(SELECT file_id,
MAX((block_id + blocks - 1) *
(select value
from v$parameter
where name = 'db_block_size')) AS resize_to
FROM dba_extents
GROUP by file_id) b
WHERE a.file_id = b.file_id
ORDER BY a.tablespace_name, a.file_name;

可以看到数据文件还是下不去,微乎其微的影响,后面就尝试了move 操作。
2.2进行move到新的表空间操作(全局索引会失效)
create tablespace tbs_move datafile 'F:\APP\ADMINISTRATOR\ORADATA\TTFC\tbd_move.DBF' size 5g autoextend on next 256m;
select b.owner,
b.segment_name,
ROUND(sum(bytes / 1024 / 1024 / 1024), 2) G
from dba_segments b
where segment_type like 'TABLE%' having
sum(b.BYTES / 1024 / 1024 / 1024) >= 1
group by b.owner, b.segment_name;

with d as
( select b.owner,
b.segment_name
from dba_segments b
where b.segment_type like 'TABLE%' having
sum(b.BYTES / 1024 / 1024 / 1024) >= 1
group by b.owner, b.segment_name )
select
a.segment_name,a.owner,a.segment_type,
case when a.segment_type='TABLE' then
'alter table ' || a.owner || '.' || a.segment_name || ' move tablespace tbs_move;'
when segment_type='TABLE PARTITION' then
'alter table '|| a.owner || '.' || a.segment_name || ' move partition '|| a.PARTITION_NAME ||' tablespace tbs_move;'
when segment_type='TABLE SUBPARTITION' then
'alter table ' || a.owner || '.' || a.segment_name || ' move subpartition '|| a.PARTITION_NAME ||' tablespace tbs_move;'
end
as sqltext
from dba_segments a inner join d on a.segment_name=d.segment_name
and a.owner=d.owner
where a.segment_type like 'TABLE%';
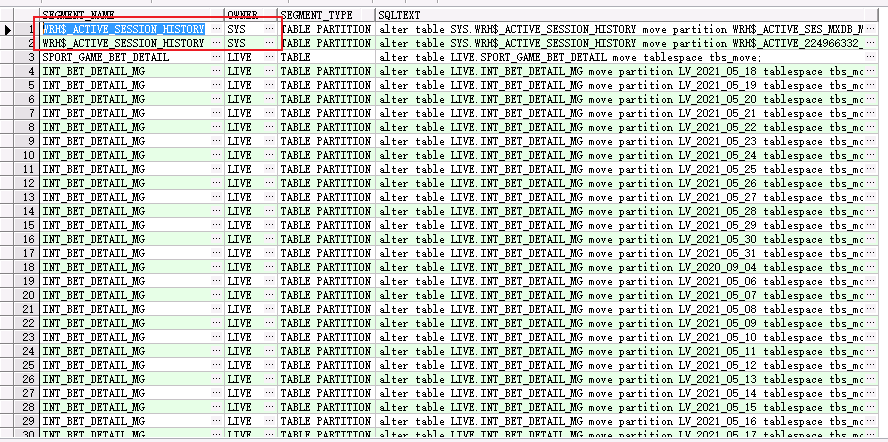
sys用户开头的表后面解决,非SYS得先move,move到tbs_move 表空间。
全局索引move后失效,进行重建:
--所有非分区和全局索引重建
select a.status,
'alter index ' || A.owner || '.' || a.index_name ||
' rebuild tablespace TBS_MOVE online nologging ;' AS REBUILD_SQL
from dba_indexes a
WHERE
--a.STATUS = 'UNUSABLE' and
a.PARTITIONED = 'NO' AND
A.TABLE_NAME IN ('INT_BET_DETAIL_CQ',
'INT_BET_DETAIL_KY',
'INT_BET_DETAIL_HB',
'INT_BET_DETAIL_MG',
'SPORT_GAME_BET_DETAIL',
'INT_BET_DETAIL_AG')
AND A.OWNER = 'LIVE'
alter index LIVE.SPORT_GAME_BET_DETAIL_CODE rebuild tablespace TBS_MOVE online nologging ;
alter index LIVE.SYS_C0011675 rebuild tablespace TBS_MOVE online nologging ;
--一级主分区索引重建
select distinct 'alter index ' || A.INDEX_OWNER || '.' || a.index_name ||
' rebuild PARTITION ' || a.partition_name ||
' tablespace TBS_MOVE online nologging;'
from dba_ind_partitions a
INNER JOIN dba_part_indexes t
ON T.owner = A.INDEX_OWNER
AND a.index_name = T.index_name
where
-- a.STATUS ='UNUSABLE' and
INDEX_OWNER = 'LIVE'
and T.SUBPARTITIONING_TYPE ='NONE'
AND T.TABLE_NAME IN ('INT_BET_DETAIL_CQ',
'INT_BET_DETAIL_KY',
'INT_BET_DETAIL_HB',
'INT_BET_DETAIL_MG',
'SPORT_GAME_BET_DETAIL',
'INT_BET_DETAIL_AG');
--二级分区索引重建
select distinct a.STATUS,
'alter index ' || A.INDEX_OWNER || '.' || a.index_name ||
' rebuild SUBPARTITION ' || a.subpartition_name ||
' tablespace TBS_MOVE online nologging;'
from dba_ind_subpartitions a
INNER JOIN dba_part_indexes t
ON T.owner = A.INDEX_OWNER
AND a.index_name = T.index_name
where
-- a.STATUS ='UNUSABLE' and
INDEX_OWNER = 'LIVE'
AND T.SUBPARTITIONING_TYPE <> 'NONE'
AND T.TABLE_NAME IN ('INT_BET_DETAIL_CQ',
'INT_BET_DETAIL_KY',
'INT_BET_DETAIL_HB',
'INT_BET_DETAIL_MG',
'SPORT_GAME_BET_DETAIL',
'INT_BET_DETAIL_AG');
注意,分区字段的组合索引需要重新删除重建,不能rebuild。
通过上面的move操作。
以及分区表索引重建(move后,分区表本地索引继续有效,但是为了压缩原索引表空间,我重建到新的表空间)

经过一系列操作,发现数据文件回收不了也是微乎其微。

Move会移动高水位,但不会释放申请的空间,是在高水位以下(below HWM)的操作;
而shrink space 同样会移动高水位,但也会释放申请的空间,是在高水位上下(below and above HWM)都有的操作,表段所在表空间的段空间管理(segment space management)必须为auto还要开启行移动。
由于业务占用数据文件较大的是分区表,我查看分区参数,进行调整后,看看是否数据文件可以resize.
SELECT A.KSPPINM NAME, B.KSPPSTVL VALUE, A.KSPPDESC DESCRIPTION
FROM sys.X$KSPPI A, sys.X$KSPPCV B
WHERE A.INDX = B.INDX
AND A.KSPPINM LIKE '_partition_large_extents';
查看隐含参数,从11.2.0.2开始创建分区表,每个分区默认大小为8M,是由_partition_large_extents参数控制,可以算是11.2.0.2开始的一个新特性,为了减少extent数量,提高分区表性能,而引入的一个参数,默认为true,即分区表的每个extent为8M。
当参数_partition_large_extents等于true时(此时可能不可见),创建分区表默认占用空间大小为每个分区8m,而普通表默认占据空间大小仅0.0625m(64k)。而当_index_partition_large_extents为true时,创建分区索引时,默认分区大小为8m,而创建普通索引默认大小为64k。
alter system set "_partition_large_extents"=false scope=spfile sid='*';
alter system set "_index_partition_large_extents"=false scope=spfile sid='*';
由于我使用的是分区表,进行参数修改后重启数据库。后续发现仍然不能resize 数据文件,resize微乎其微。
2.3 expdp/impdp 导入导出方式
由于上面shrink,move方式都失败,索引进行第三中导入导出方式(按照用户导出),后续删除表空间,然后新建表空间,还好数据量不大,停机时间不久。
expdp system/XXX dumpfile=live0515.dmp logfile=live0515.log directory=BET_DIR schemas=live compression=all
drop tablespace NB_TBS_YOBET including contents and datafiles;
drop tablespace NB_INX_TBS_YOBET including contents and datafiles;
并且手动的删除数据文件后重新建表空间。
create tablespace NB_TBS_YOBET datafile 'F:\APP\ADMINISTRATOR\ORADATA\TTFC\NB_TBS_YOBET01.DBF' size 5g autoextend on next 256M;
create tablespace NB_INX_TBS_YOBET datafile 'F:\APP\ADMINISTRATOR\ORADATA\TTFC\NB_INX_TBS_YOBET01.DBF' size 2g autoextend on next 256M;
alter tablespace NB_TBS_YOBET add datafile 'F:\APP\ADMINISTRATOR\ORADATA\TTFC\NB_TBS_YOBET02.DBF' size 5g autoextend on next 256M;
在进行数据导入。
impdp system/XXX directory=BET_DIR dumpfile=LIVE0515.DMP logfile=imp.log table_exists_action=replace
查看导入后的的表空间计算FSFI
select a.tablespace_name,
sqrt(max(a.blocks) / sum(a.blocks)) * (100 / sqrt(sqrt(count(a.blocks)))) FSFI
from dba_free_space a, dba_tablespaces b
where a.tablespace_name = b.tablespace_name
and b.contents not in ('TEMPORARY','UNDO')
group by a.tablespace_name
order by FSFI;
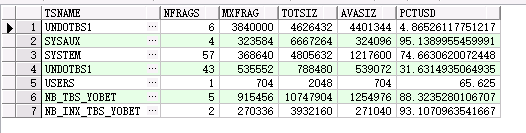
select
total.tablespace_name tsname,
count(free.bytes) nfrags,
nvl(max(free.bytes)/1024,0) mxfrag,
total.bytes/1024 totsiz,
nvl(sum(free.bytes)/1024,0) avasiz,
(1-nvl(sum(free.bytes),0)/total.bytes)*100 pctusd
from
dba_data_files total,
dba_free_space free
where
total.tablespace_name = free.tablespace_name(+)
and total.file_id=free.file_id(+)
group by
total.tablespace_name,
total.bytes
/
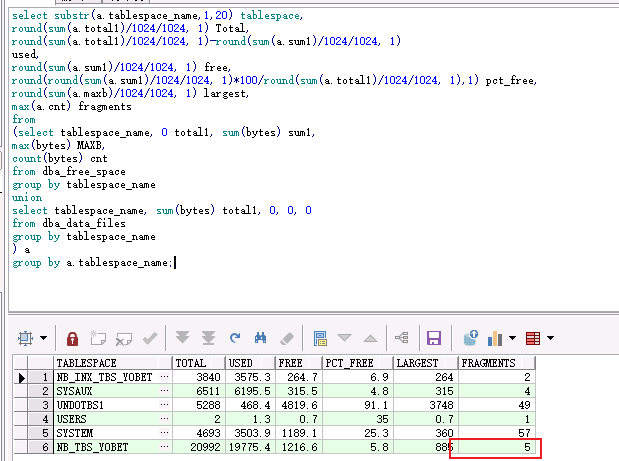
在为进行expdp 和重建表空间,impdp之后,明显碎片数减少,之前是1910.
三.WRH$_ACTIVE_SESSION_HISTORY 过大
SYS.WRH$_ACTIVE_SESSION_HISTORY 达到了2G,Oracle根据保留策略决定需要清除哪些行。在AWR表的情况下,有一种特殊的机制可以将快照数据存储在分区中。从这些表中清除数据的一种方法是通过删除仅包含超出保留条件的行的分区。在夜间清除任务期间,仅当分区中的所有数据均已到期时才删除分区。如果分区包含至少一行,根据保留策略,不应删除该行,则不会删除该分区,因此该表将包含旧数据。
如果没有发生分区拆分(出于某种原因),那么我们最终将不得不等待最新的条目到期,然后才能删除它们所在的分区。这可能意味着一些较旧的条目可以在其到期日期之后保留很长时间。结果是数据没有按预期清除。
清除参照support Doc ID 387914.1,Doc ID 1965061.1
@F:\app\Administrator\product\11.2.0.4\dbhome\RDBMS\ADMIN\awrinfo.sql

可以查看awr 占了大部分内容。
select systimestamp - min(savtime) from sys.wri$_optstat_histgrm_history;

exec dbms_stats.purge_stats(sysdate - 1);

删除昨天前的awr的保留的信息。
set lines 150
col SEGMENT_NAME for a30
col PARTITION_NAME for a50
SELECT owner, segment_name, partition_name, segment_type, bytes/1024/1024/1024 Size_GB FROM dba_segments WHERE segment_name='WRH$_ACTIVE_SESSION_HISTORY';
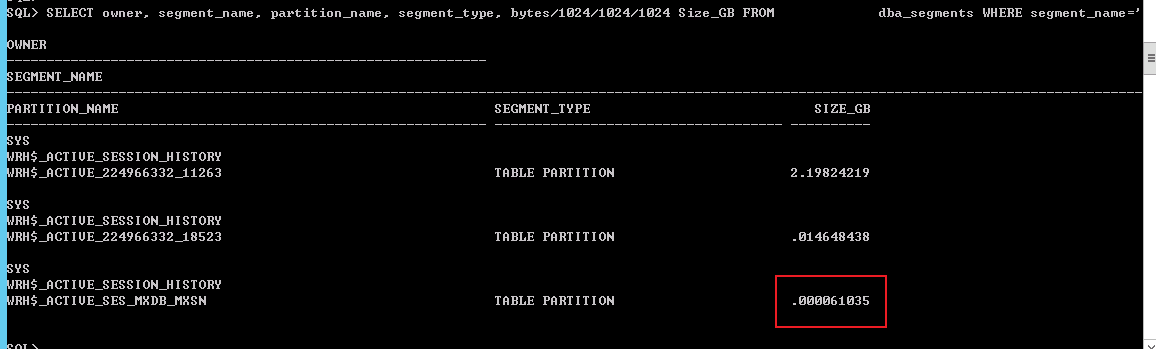
把awr分区分割成更小的分区。
alter session set "_swrf_test_action" = 72;
set lines 150
col SEGMENT_NAME for a30
col PARTITION_NAME for a50
SELECT owner, segment_name, partition_name, segment_type, bytes/1024/1024/1024 Size_GB FROM dba_segments WHERE segment_name='WRH$_ACTIVE_SESSION_HISTORY';

set serveroutput on
declare
CURSOR cur_part IS
SELECT partition_name from dba_tab_partitions
WHERE table_name = 'WRH$_ACTIVE_SESSION_HISTORY'; query1 varchar2(200);
query2 varchar2(200); TYPE partrec IS RECORD (snapid number, dbid number);
TYPE partlist IS TABLE OF partrec; Outlist partlist;
begin
dbms_output.put_line('PARTITION NAME SNAP_ID DBID');
dbms_output.put_line('--------------------------- ------- ----------'); for part in cur_part loop
query1 := 'select min(snap_id), dbid from sys.WRH$_ACTIVE_SESSION_HISTORY partition ('||part.partition_name||')
group by dbid';
execute immediate query1 bulk collect into OutList; if OutList.count > 0 then
for i in OutList.first..OutList.last loop
dbms_output.put_line(part.partition_name||' Min '||OutList(i).snapid||' '||OutList(i).dbid);
end loop;
end if; query2 := 'select max(snap_id), dbid from sys.WRH$_ACTIVE_SESSION_HISTORY partition ('||part.partition_name||')
group by dbid';
execute immediate query2 bulk collect into OutList; if OutList.count > 0 then
for i in OutList.first..OutList.last loop
dbms_output.put_line(part.partition_name||' Max '||OutList(i).snapid||' '||OutList(i).dbid);
dbms_output.put_line('---');
end loop;
end if; end loop;
end;
/

exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE( low_snap_id IN NUMBER,high_snap_id IN NUMBER, dbid IN NUMBER DEFAULT NULL);
exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE( 18523,18591,224966332);
exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE( 18501,18522,224966332);
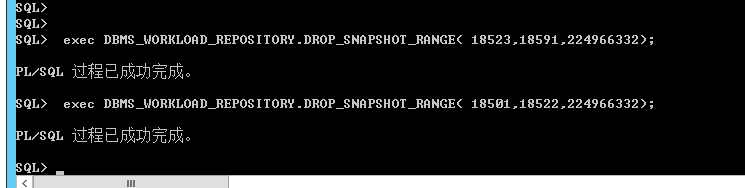
set lines 150
col SEGMENT_NAME for a30
col PARTITION_NAME for a50
SELECT owner, segment_name, partition_name, segment_type, bytes/1024/1024/1024 Size_GB FROM dba_segments WHERE segment_name='WRH$_ACTIVE_SESSION_HISTORY';
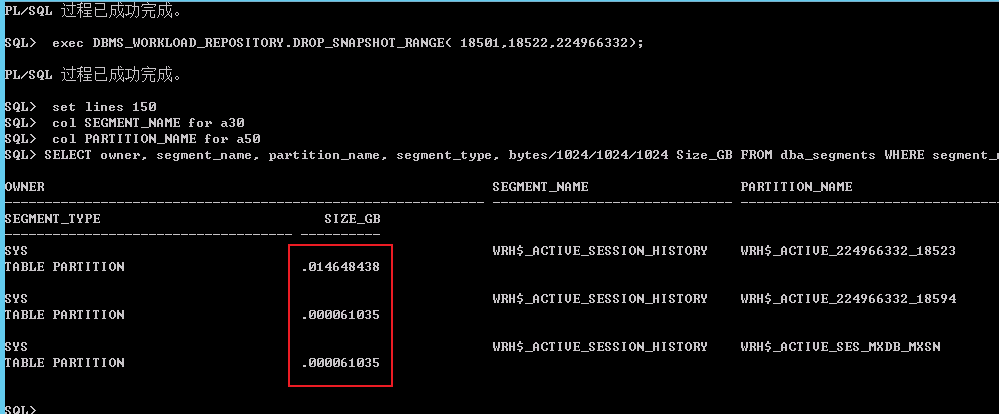
进行awrinfo 再次查看:
@F:\app\Administrator\product\11.2.0.4\dbhome\RDBMS\ADMIN\awrinfo.sql

明显的看到下降了。
四.总结
表空间碎片大多数数据库都会存在,可以定时的监控,在业务范围允许的情况下,进行处理,达到节约空间的目的。
以下是经常用的方法总结。
表级别碎片整理方法:
1.首选shrink
2.导入导出 exp/imp expdp/impdp
3.CATS
4.table move tablespace
5.Online Redefinition
其中注意的是:
1.Move会移动高水位,但不会释放申请的空间,是在高水位以下(below HWM)的操作,同时分区表的全局索引需要重建,且有分区字段的组合索引也要删除后重建(组合索引不能rebuild);
2.shrink space 同样会移动高水位,但也会释放申请的空间,是在高水位上下(below and above HWM)都有的操作,表段所在表空间的段空间管理(segment space management)必须为auto还要开启行移动。
3.导入导出对业务的影响程度较大,24*7的话比较难使用该方法;但是这个方法也有优点,就是表段没有占用那么多数据文件时,导入表空间数据文件只会站表段的大小,我就是采取的这种方法缩小数据文件,而move,和shrink 并不能让我resize数据文件,释放磁盘空间。
4.cast 只适合单个表,多表的话操作比较麻烦。
5.在线重定义这个方法已经落后,不推荐了。
oracle 碎片管理和数据文件resize释放表空间和磁盘空间(以及sys.wri$_optstat_histgrm_history过大处理)的更多相关文章
- 数据文件resize回收空间
场景说明: 客户 ASM磁盘组,data磁盘组空闲空间90G,空间不足,因此强烈建议回收空间 空间回收方案: 1.数据文件resize,回收部分可用性空间(好处就是能够将ASM磁盘组free大小增加) ...
- ORACLE体系结构一 (物理结构)- 数据文件、日志文件、控制文件和参数文件
一.物理结构Oracle物理结构包含了数据文件.日志文件.控制文件和参数文件 1.数据文件每一个ORACLE数据库有一个或多个物理的数据文件(data file).一个数据库的数据文件包含全部数据库数 ...
- oracle之 RAC本地数据文件迁移至ASM
系统环境:CentOS release 6.7 (Final)Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit 操作过 ...
- oracle rm -fr datafile 数据文件被误删的场景恢复(没有rman备份)
环境: Linux release 7.5 oracle19c (无pdb,从11.2.0.4升级上去的) 一:单个非系统表空间的数据文件被删除 我先备份一下,虽然是测试环境. [oracle@19c ...
- 编写Java程序,在一个文件夹内,查找占用磁盘空间最大的 jpg 文件,并输出文件大小
查看本章节 查看作业目录 需求说明: 在一个文件夹内,查找占用磁盘空间最大的 jpg 文件,并输出文件大小 实现思路: 创建ImageFileFilter类实现FilenameFilter接口,且重写 ...
- Oracle逻辑体系:数据文件黑盒的内在洞天
select username,session_num,tablespace from v$sort_usage; Block: 块的组成 Header:包含数据块的概要信息:块地址,块属于哪个段,还 ...
- Oracle与SQLSERVER修改数据文件的路径
1. SQLSERVER ALTER DATABASE CWBASEMSS modify file (name = cwbasemss_dat ,filename = 'c:\cwdata\mss\C ...
- 【Oracle】重命名数据文件
1)查看当前数据文件位置 SQL> select file_id,file_name,tablespace_name from dba_data_files; FILE_ID FILE_NAME ...
- Oracle数据库表空间 数据文件 用户 以及表创建的SQL代码
--create the tablespace CREATE SMALLFILE TABLESPACE "TABLE_CONTAINER" --创建表空间 DATAFILE 'E: ...
随机推荐
- vue实现拖拽排序
基于vue实现列表拖拽排序的效果 在日常开发中,特别是管理端,经常会遇到要实现拖拽排序的效果:这里提供一种简单的实现方案. 此例子基于vuecli3 首先,我们先了解一下js原生拖动事件: 在拖动目标 ...
- jenkins构建go及java项目
jenkins构建go及java项目 转载请注明出处https://www.cnblogs.com/funnyzpc/p/14554017.html 写在前面 jenkins作为java的好基友,经历 ...
- Unity 背包系统的完整实现(基于MVC框架思想)
前言: 项目源码上传GitHub:Unity-knapsack 背包系统: 背包系统是游戏中非常重要的元素,几乎每一款游戏都有背包系统,我们使用背包系统可以完成装备栏的数据管理,商店物体的数据管理等等 ...
- 在Vue中使用sass和less,并解决报错问题(this.getOptions is not a function)
使用 Less 下载依赖:npm install less less-loader 在mian.js 中添加: import less from "less"; Vue.use(l ...
- zk都有哪些使用场景?
(1)分布式协调:这个其实是zk很经典的一个用法,简单来说,就好比,你A系统发送个请求到mq,然后B消息消费之后处理了.那A系统如何知道B系统的处理结果?用zk就可以实现分布式系统之间的协调工作.A系 ...
- linux-shell 判断当前用户是否是root用户
环境变量UID中保存的是用户ID. root用户的UID是0. #! /bin/bash if [ $UID -ne 0 ]; then echo Non root user. Please run ...
- 简单的介绍一下Java设计模式:解释器模式
目录 定义 意图 主要解决问题 优缺点 结构 示例 适用情况 定义 解释器模式是类的行为型模式,给定一个语言之后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器,客户端可以使用这个解释器来 ...
- 熟知Mysql基本操作
本文是学习 Mysql必知必会 后的笔记 学习之前需要创建一个数据库,然后导入下面两个mysql脚本 create database db1 charset utf8; ############### ...
- 10- JMeter5.1.1 工具快速入门
什么是JMeter JMeter是Apache组织开发的开源软件,由Java语言实现. 主要用于软件系统性能测试,他最初被设计用于web测试,后来被扩展到其他领域. Jmeter特点 http://w ...
- android添加账户源码浅析
上篇粗略的分析android添加账号的流程,本篇深入的解析下执行步骤.先来看图片,取自深入理解android卷2: 上图详细的分析了addAccount的流程,下面我们结合源码来理解它 1.addAc ...