基于DNN的残余回声抑制
摘要
由于功率放大器或扬声器的限制,即使在回声路径完全线性的情况下,麦克风捕获的回声信号与远端信号也不是线性关系。线性回声消除器无法成功地消除回声的非线性分量。RES是在AES后对剩余回声进行抑制的一种技术。传统的方法是根据相关信号的估计统计量,使用维纳滤波或谱减法来计算RES增益。在本文中,我们提出了一种基于DNN的RES增益估计方法,该方法基于远端和AES输出信号在各频率点(frequency bins)的增益估计。采用一种适合于建立高维向量间复杂非线性映射模型的DNN结构,作为从这些信号到最优RES增益的回归函数。该方法可以在不使用显式双端会话检测器(double-talk detectors)的情况下抑制残余分量。实验结果表明,该方法在单语音时段的回音往返损耗增强(echo return loss enhancement, ERLE)和双讲时段的语音质量感知评价(PESQ)评分方面都优于传统方法。
关键字:声学回声抑制,残余回声抑制,非线性回声,深度神经网络,最优增益回归
1 引言
回声消除(AEC)或回声抑制(AES)是一种减少扬声器和麦克风之间的声耦合所产生的回声的技术。虽然已经有很多方法成功地抑制了回声,但在这些方法的输出端仍然存在一定的残余回声。AEC或AES造成该现象的原因之一是,即使回声路径是完全线性的,回声信号也不是远端数字信号的线性函数。功率放大器和扩音器,尤其是那些廉价和小型的,可能是这种非线性的来源。
为了克服这个问题,一些残余回声抑制(RES)滤波器已被应用到AEC或AES的输出以抑制残余回声。[5]和[6]的作者提出了RES方法来估计信号-回声比(SER),然后在频域中应用维纳滤波器或谱减法。在[7]中,将基于谱减法的子带滤波与截断的声回声路径泰勒级数展开相结合来估计回声的功率谱密度。在[8]中,基于远端回声信号与回声信号的频间相关性建模,提出了一种基于残差回声幅度回归模型的RES算法。
最近,提出了一种利用人工神经网络(ANN)从远端信号估计残余回声的方法。ANN的输入为给定频率区中的远端信号,该信号的功率以及可能导致谐波失真的频率分量之和,最终的频谱增益为维纳滤波增益。但这些方法没有考虑残差回声与远端信号在各频率区中的非线性特性。
在本文中,我们提出了一种利用DNNs的残余回声抑制方法,该方法根据AES的远端和各频率区的输出信号估计最优RES增益。DNN结构可以学习高维向量之间的复杂映射,已成功应用于自动语音识别和语音增强领域。我们期望这些结构能够适应,从这些信号到基于多条件数据的DNN训练的,最优RES增益的非线性回归函数建模,即使在训练中使用的室内冲激响应(RIRs)与测试中的RIRs不匹配。在匹配和不匹配条件下,针对不同的RIRs、SER、剪切类型和非线性程度,我们采用两种客观指标来评估扬声器的整体性能。这些度量标准是单语音周期的ERLE和双讲音周期的ITU-T建议P.862 PESQ。实验结果表明,与传统的基于ANN的残余回声估计和增益函数的维纳滤波算法相比,该方法提高了语音质量,抑制了回声。
2 带有非线性RES滤波器的回声抑制系统
AES提供了一个有吸引力的替代AEC技术,低复杂度系统中回声抑制的远程通信。
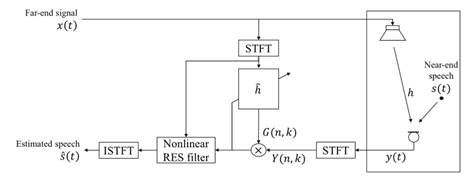
图1 具有非线性RES后滤波器的AES系统示意图
图1描述了一个单通道AES系统。时间指标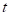 处的远端信号
处的远端信号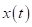 是由源信号在发射室内通过声脉冲响应产生的。设
是由源信号在发射室内通过声脉冲响应产生的。设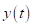 为接收室内包含近端语音
为接收室内包含近端语音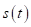 的输入信号,
的输入信号,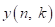 为第
为第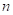 帧第
帧第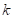 个频率区y(t)的短时傅里叶变换
个频率区y(t)的短时傅里叶变换 系数。通过对每个频率区进行维纳滤波或谱减,得到抑制回声的谱增益函数
系数。通过对每个频率区进行维纳滤波或谱减,得到抑制回声的谱增益函数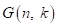 。然而,由于线性回声建模的限制,回声成分可能仍然保留在AES的输出中,包括大量的非线性回声,降低近端语音的质量。为了提高AES的输出性能,可以对剩余信号进行附加的非线性RES滤波。使用RES增益
。然而,由于线性回声建模的限制,回声成分可能仍然保留在AES的输出中,包括大量的非线性回声,降低近端语音的质量。为了提高AES的输出性能,可以对剩余信号进行附加的非线性RES滤波。使用RES增益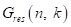 ,最后在频域估计语音,
,最后在频域估计语音, 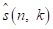 计算如下所示:
计算如下所示:
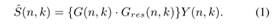
当功率放大器和扬声器引入严重的非线性时, 根据残余回声的非线性特性计算是极其重要的。
3****使用DNN的RES
各种各样的RES方法被发展来有效地抑制残余回声。然而,由于构造高度复杂的函数的困难,这些可能不能准确地描述残余回声信号的非线性特性。近年来,在语音识别和增强领域,DNN结构被用作寻找复杂映射或函数的强大工具,表现出比其他传统方法更好的性能。其主要原因可能是利用叠加受限玻尔兹曼机(RBMs)和贪婪的分层无监督学习初始化DNN参数在DNN方面取得了突破。在无监督的预训练阶段结束后,采用有监督的学习算法,利用反向传播和随机梯度下降法对DNN的权值进行微调。关于预训练和微调过程的详细程序在[12,13]中描述。[9]中,ANN是利用从远端信号估计残留回声, 但由于人工神经网络的输入特征是根据谐波失真的知识构造的,而最终的增益函数是维纳滤波器增益,因此该方法的结构不够灵活。
本文提出了一种基于DNN的最优增益回归算法,利用DNN结构成功地表示了RES过程中最优增益的复杂非线性回归函数。定义增益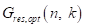 为:
为:

其中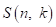 和
和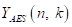 是干净近端语音和AES输出信号的STFT系数,
是干净近端语音和AES输出信号的STFT系数,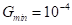 是为了减少计算量。
是为了减少计算量。
输入端采用远端回声谱和残差回声谱。残余回声与RES增益之间的关系可能比输入传声器信号与增益之间的关系更依赖于回声路径。因此,DNN可以通过多条件训练来识别残差回声、远端信号和RES增益之间的非线性关系,尽管这一过程中的DB是通过使用少量回声路径得到的。
图2展示了用于该方法的DNN系统。
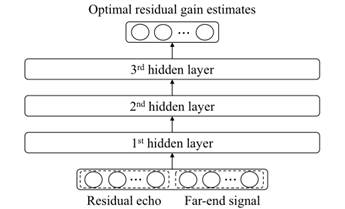
图2 提出的RES的DNN结构
该结构由一个高斯伯努利RBM和两个伯努利-伯努利RBM组成。DNN中各隐含层节点和输出层节点采用sigmoid函数建模。该模型的输入端为短时傅立叶变换域内的残差回声和以幅度谱表示的远端信号对。在取N点的STFT时,考虑T个连续帧的残差回声和远端信号的输入特征向量维数为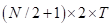 ,而DNN的输出为
,而DNN的输出为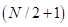 维的RES增益向量。这些标准化后,均值和单位方差都为零。由于相位信息对人的听觉系统不是至关重要的,因此估计的语音相位与AES输出的相位保持一致。
维的RES增益向量。这些标准化后,均值和单位方差都为零。由于相位信息对人的听觉系统不是至关重要的,因此估计的语音相位与AES输出的相位保持一致。
在DNN训练中,我们首先尝试学习残差回声和远端信号光谱的深度生成模型,作为训练前的一个阶段。利用对比散度(CD),以无监督贪婪的方式逐层训练RBMs。在此过程中更新每个RBM的参数。然后在微调阶段,利用RES估计增益与最优增益之间的最小均方误差(MMSE)函数的反向传播算法对DNN进行训练。利用AES输出和近端语音信号,通过式(2)计算出RES的最优增益。
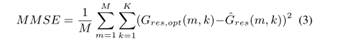
其中M和K分别为小批量大小和总频率点数。然后,对权值和偏差的估计值进行迭代更新。一些传统的方法是基于每个频率点之间的独立性假设或只有几个相邻区的依赖性。相比之下,建议的工作可以考虑从AES输出中提取的最优RES增益和特征,与远端信号在整个频率范围内的非线性映射。此外,由于训练信号中包含近端语音和回声信号,因此该方法不需要任何双讲音检测器。因此,我们认为,与其他传统方法相比,该方法可以提高回声估计。
4 实验结果
为了评估提出的基于DNN的RES的性能,我们在不同的条件下进行了几次仿真。从TIMIT数据库中,我们为每个RIR创建了450个(4036秒)的麦克风信号文件,从扬声器的位置到如图3所示的麦克风,以构建残余回声DB。这些文件以16kHz采样。
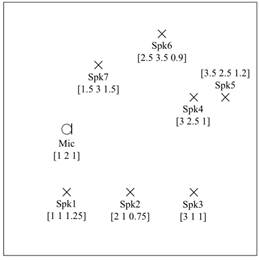
图3 1个麦克风和7个扬声器在4m4m3m的模拟接收房间的位置,
用于构建回声DB
为了模拟麦克风捕捉到的回声信号,依次经过功率放大器、扬声器和声波传输,我们对远端信号进行三种处理:裁剪、应用非线性扬声器仿真模型和与RIRs卷积。人工剪裁是由
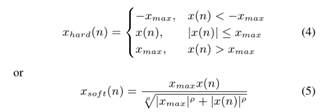
其中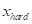 和
和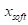 分别为硬裁剪和软裁剪的输出,
分别为硬裁剪和软裁剪的输出,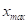 为输出信号的最大值。对于软剪,将
为输出信号的最大值。对于软剪,将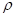 值设为2。为模拟非线性扬声器特性,采用无记忆sigmoidal函数。
值设为2。为模拟非线性扬声器特性,采用无记忆sigmoidal函数。
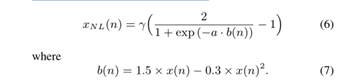
参数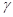 为sigmoid函数增益,设
为sigmoid函数增益,设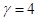 。sigmoid函数斜率值
。sigmoid函数斜率值 取为:如果
取为:如果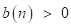 ,则取
,则取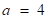 ,否则取
,否则取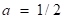 。接收室设计为
。接收室设计为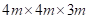 的小型办公空间。采用图像方法[17],生成图3所示接收室7个扬声器位置到麦克风的RIRs,混响时间为
的小型办公空间。采用图像方法[17],生成图3所示接收室7个扬声器位置到麦克风的RIRs,混响时间为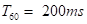 。RIRs的长度设置为512。麦克风测得的回声电平比近端语音平均低
。RIRs的长度设置为512。麦克风测得的回声电平比近端语音平均低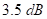 。在性能评价方面,采用ERLE和PESQ作为客观测度。ERLE度量被定义为:
。在性能评价方面,采用ERLE和PESQ作为客观测度。ERLE度量被定义为:

首先,我们将传统的AES应用于整个数据集,对[4]中的回声进行了轻微的修改,消除了第二通道回声估计,使其成为单通道声回声。AES的参数设置为[4]中所示的值。虽然在[4]中提出的AES被证明有效地减少了线性回声,由于严重的非线性失真,测试数据的平均ERLE约为 。
。
为了与传统的RES技术进行比较,我们利用光谱特征实现了基于ANN的RES。采用均匀的128点STFT分析-合成滤波器组,重叠率为75%。RES的离线估计器是一个具有两个log-sigmoid隐藏节点的网络。远端信号的幅度谱和所有子频带的平均值直到当前频带的一半被用作输入。将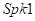 、
、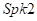 、
、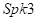 位置的RIRs应用到图3中
位置的RIRs应用到图3中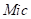 位置的30个文件(267s)上进行训练。参数设置如下:对于双话检测,我们在该方法中应用了人工标记信息。我们也尝试过训练更大的DB或采取256点STFT,但都不能带来性能的改善。
位置的30个文件(267s)上进行训练。参数设置如下:对于双话检测,我们在该方法中应用了人工标记信息。我们也尝试过训练更大的DB或采取256点STFT,但都不能带来性能的改善。
为了训练所提出的技术,在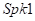 、和位置建立的总共1200个文件(10774s)用于训练DNN。帧长设置为256个样本,重叠度50%。对每一帧应用一个256点的STFT。每个隐藏层和输出层分别有2048和129个节点。最后的输入向量由当前帧和前两个帧组成,因此成为774维的向量。RBM预训练每层epoch为20个。训练前学习率为0.0005。在微调中,前10个epoch的学习率被设置为0.1,然后在每个epoch后降低10%。总迭代次数为50,小批量大小M设置为256。对于每个位置的测试,我们分别为单对话和双对话测试使用两组50个文件(445s)。
、和位置建立的总共1200个文件(10774s)用于训练DNN。帧长设置为256个样本,重叠度50%。对每一帧应用一个256点的STFT。每个隐藏层和输出层分别有2048和129个节点。最后的输入向量由当前帧和前两个帧组成,因此成为774维的向量。RBM预训练每层epoch为20个。训练前学习率为0.0005。在微调中,前10个epoch的学习率被设置为0.1,然后在每个epoch后降低10%。总迭代次数为50,小批量大小M设置为256。对于每个位置的测试,我们分别为单对话和双对话测试使用两组50个文件(445s)。
接近结尾的语音也是从TIMIT数据库中选择的。
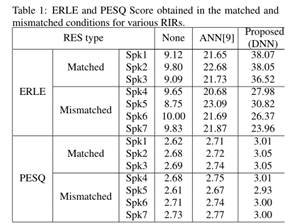
表1显示了单话时段的ERLEs和双话时段的PESQ评分的总体结果,其中测试数据是在输入信号最大音量的80%下,采用硬剪切法在扬声器的所有7个位置获得的。从整体结果来看,基于DNN的方法在匹配和不匹配条件下都比传统的RES有更好的性能。
特别是,从PESQ评分的比较可以看出,本文提出的RES对近端语音的保存效果要好得多。这些结果是在少数的RIR情况下通过训练得到的,这可以支持我们的假设,即从远端信号和残余回声到RES增益的映射不受声环境的显著影响。
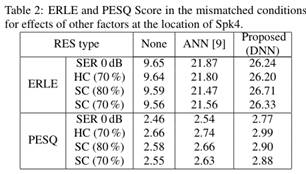
为了研究扩音器的信号-回声比、剪切类型和非线性量等其他因素对RES算法的影响,我们在 位置上另外测试了对应于其他不匹配条件的几种情况。在这次测试中,我们使用了与上次测试相同的模型,这些模型在
位置上另外测试了对应于其他不匹配条件的几种情况。在这次测试中,我们使用了与上次测试相同的模型,这些模型在 、
、 和
和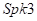 位置用DB进行训练,每种方法都80%的硬剪切。表2比较了建议的RES和常规RES的性能。
位置用DB进行训练,每种方法都80%的硬剪切。表2比较了建议的RES和常规RES的性能。 的SER意味着近端语音回声比水平平均为
的SER意味着近端语音回声比水平平均为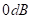 。
。 和
和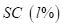 分别以输入信号最大振幅的
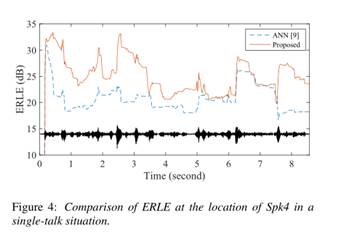
分别以输入信号最大振幅的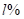 表示硬剪切和软剪切。将我们方法的输出与未处理的信号进行比较,发现PESQ得分至少提高了0.3个点。在4种情况下,该方法均优于常规RES,且不受各种不匹配因素的影响。图4中给出了一个ERLE随时间变化的例子,并给出了相应的未处理回声波形。
表示硬剪切和软剪切。将我们方法的输出与未处理的信号进行比较,发现PESQ得分至少提高了0.3个点。在4种情况下,该方法均优于常规RES,且不受各种不匹配因素的影响。图4中给出了一个ERLE随时间变化的例子,并给出了相应的未处理回声波形。
该算法对残余回声分量的衰减比传统的RES更有效。
5 结论
在本文中,我们提出了一种最优增益回归方法来抑制短时傅立叶变换域内的非线性残余回声。结果表明,基于DNN的回归可以代表整个频率区中最优增益、残余回声和远端信号之间的复杂映射。此外,该方法可以在不使用显式双端会话检测器的情况下抑制残余分量。在单话情况下的ERLE和双话情况下的PESQ评分方面,提出的RES优于传统的RES。
基于DNN的残余回声抑制的更多相关文章
- tensorflow下基于DNN实现实时分辨人脸微表情
参加学校的国创比赛的时候,我们小组的项目有一部分内容需要用到利用摄像头实现实时检测人脸的表情,因为最近都在看深度学习方面的相关知识,所以就自己动手实现了一下这个小Demo.参考网上的资料,发现大部分是 ...
- 基于深度学习的回声消除系统与Pytorch实现
文章作者:凌逆战 文章代码(pytorch实现):https://github.com/LXP-Never/AEC_DeepModel 文章地址(转载请指明出处):https://www.cnblog ...
- 知物由学 | 基于DNN的人脸识别中的反欺骗机制
"知物由学"是网易云易盾打造的一个品牌栏目,词语出自汉·王充<论衡·实知>.人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道."知物 ...
- 基于DNN的推荐算法总结
1.早期的算法 深度学习在CTR预估应用的常见算法有Wide&Deep,DeepFM等. 这些方法一般的思路是:通过Embedding层,将高维离散特征转换为固定长度的连续特征,然后通过多个全 ...
- 论文翻译:2018_Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios
论文地址:深度学习用于噪音和双语场景下的回声消除 博客地址:https://www.cnblogs.com/LXP-Never/p/14210359.html 摘要 传统的声学回声消除(AEC)通过使 ...
- 论文翻译:2020_Attention Wave-U-Net for Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-10.pdf Attention Wave-U-Net 的回声消除 摘要 提出了 ...
- 论文翻译:2021_ICASSP 2021 ACOUSTIC ECHO CANCELLATION CHALLENGE: INTEGRATED ADAPTIVE ECHO CANCELLATION WITH TIME ALIGNMENT AND DEEP LEARNING-BASED RESIDUAL ECHO PLUS NOISE SUPPRESSION
论文地址:https://ieeexplore.ieee.org/abstract/document/9414462 ICASSP 2021声学回声消除挑战:结合时间对准的自适应回声消除和基于深度学习 ...
- 论文翻译:2021_AEC IN A NETSHELL: ON TARGET AND TOPOLOGY CHOICES FOR FCRN ACOUSTIC ECHO CANCELLATION
论文地址:https://ieeexploreieee.53yu.com/abstract/document/9414715 Netshell 中的 AEC:关于 FCRN 声学回声消除的目标和拓扑选 ...
- 论文翻译:2020_RESIDUAL ACOUSTIC ECHO SUPPRESSION BASED ON EFFICIENT MULTI-TASK CONVOLUTIONAL NEURAL NETWORK
论文翻译:https://arxiv.53yu.com/abs/2009.13931 基于高效多任务卷积神经网络的残余回声抑制 摘要 在语音通信系统中,回声会降低用户体验,需要对其进行彻底抑制.提出了 ...
随机推荐
- 洛谷 P3600 - 随机数生成器(期望 dp)
题面传送门 我竟然独立搞出了这道黑题!incredible! u1s1 这题是我做题时间跨度最大的题之一-- 首先讲下我四个月前想出来的 \(n^2\log n\) 的做法吧. 记 \(f(a)=\m ...
- Excel-统一小括号格式(中文小括号,英文小括号)
1.统一小括号格式(中文小括号,英文小括号) 公式=ASC("(") #"(" 解释函数: ASC(A1)#对于双字节字符集(DBCS)语言,将全角英文字符(即 ...
- adjust, administer
adjust to just, exact. In measurement technology and metrology [度量衡学], calibration [校准] is the compa ...
- day07 Nginx入门
day07 Nginx入门 Nginx简介 Nginx是一个开源且高性能.可靠的http web服务.代理服务 开源:直接获取源代码 高性能:支持海量开发 可靠:服务稳定 特点: 1.高性能.高并发: ...
- day32 HTML
day32 HTML 什么是前端 只要是跟用户打交道的界面都可以称之为前端 # eg:电脑界面, 手机界面,平板界面, 什么是后端? eg:python, java,php,go, 不跟用户直接打交道 ...
- Learning Spark中文版--第六章--Spark高级编程(2)
Working on a Per-Partition Basis(基于分区的操作) 以每个分区为基础处理数据使我们可以避免为每个数据项重做配置工作.如打开数据库连接或者创建随机数生成器这样的操作,我们 ...
- 零基础学习java------30---------wordCount案例(涉及到第三种多线程callable)
知识补充:多线程的第三种方式 来源:http://www.threadworld.cn/archives/39.html 创建线程的两种方式,一种是直接继承Thread,另外一种就是实现Runnabl ...
- ssh : connect to host XXX.XXX.XXX.XXX port : 22 connect refused
初学者 写博客 如有不对之处请多多指教 我是要在俩个主机的俩个虚拟机上 用scp (security copy)进行文件远程复制. 但是 终端 提示 ssh : connect to host XXX ...
- oracle加密encrypt,解密decrypt
目录 oracle加密encrypt,解密decrypt 加密 解密 oracle加密encrypt,解密decrypt 有的oracle版本没有加解密函数,以下操作可以手动添加 oracle数据使用 ...
- 编译安装nginx 1.16
准备源码包,并解压,创建nginx用户 [root@slave-master ~]# tar xf nginx-1.16.0.tar.gz [root@slave-master ~]# useradd ...