Spark(一)【spark-3.0安装和入门】
一.Windows安装
1.安装
将spark-3.0.0-bin-hadoop3.2.tgz解压到非中文目录
2.使用
bin/spark-shell.cmd : 提供一个交互式shell
val result: String = sc.textFile("input").flatMap(_.split(" ")).map((_, 1)).reduceByKey( _ + _).collect().mkString(",")
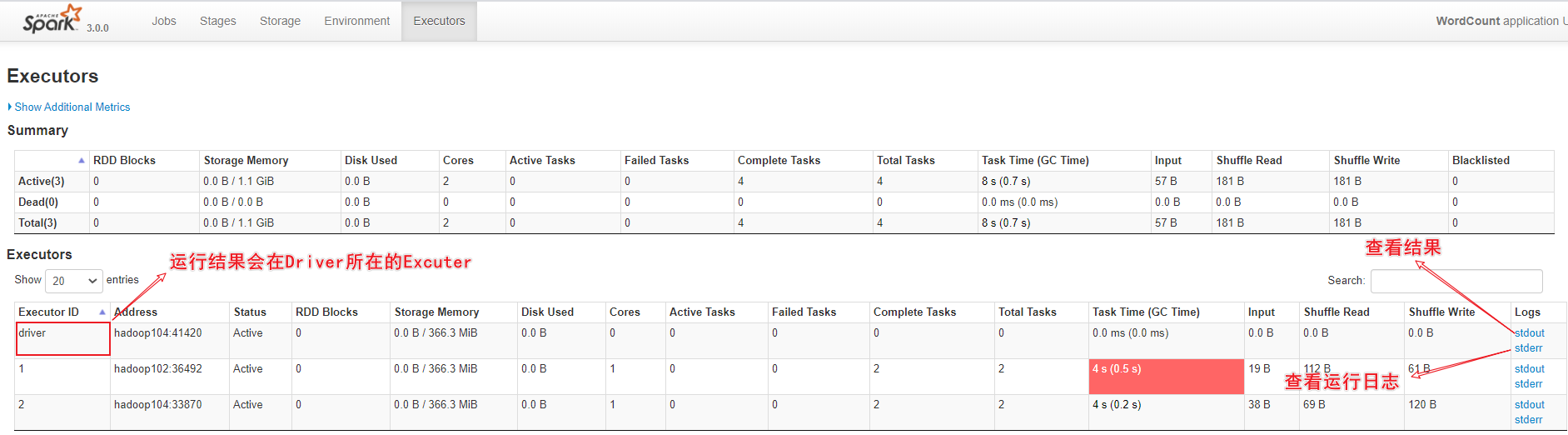
可以打开WEB UI:http://localhost:4040/(每一个spark-shell会初始化一个spark-context,是一个job,关闭窗口后,就没有这个页面了)
bin/spark-submit.cmd: 将程序打包后,提交运行!打包过程参考:idea开发spark程序
1)进入D:\SoftWare\spark\spark-3.0.0-bin-hadoop3.2\bin
2)将jar包上传到bin目录下,和测试的文件
3)在该目录路径输入cmd打开cmd窗口
输入以下命令测试
spark-submit --class com.spark.day01.WcCount 09sparkdemo-1.0-SNAPSHOT.jar 1.txt


二.Linux安装
Local模式
一般可以使用local模式进行测试,学习
1.安装
将spark-3.0.0-bin-hadoop3.2.tgz文件上传到linux并解压缩,放置在指定位置,改包名为spark-local
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2.tgz spark-local
2.使用
进入 /opt/module/spark-local目录下
spark-shell:命令行工具
执行以下命令
[hadoop@hadoop103 spark-local]$ bin/spark-shell
[hadoop@hadoop103 spark-local]$ bin/spark-shell
20/07/29 18:54:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
20/07/29 18:55:06 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://hadoop103:4041
Spark context available as 'sc' (master = local[*], app id = local-1596020106480).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
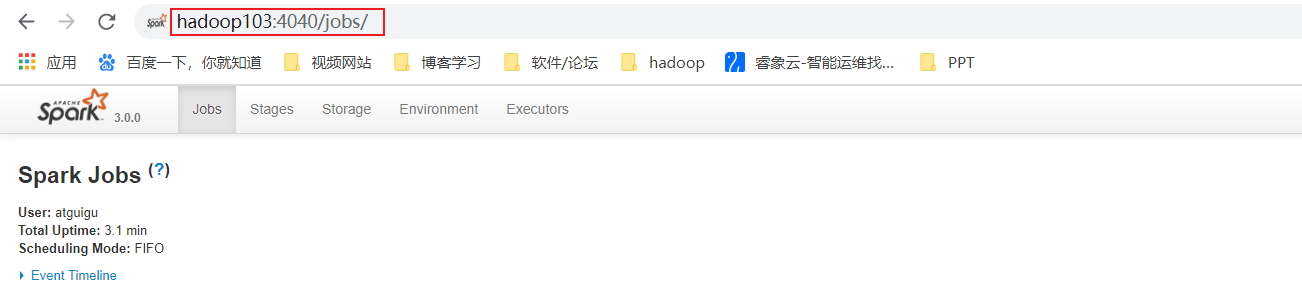
通过WEB UI 界面查看:http://hadoop103:4040/jobs/
执行代码
scala> sc.textFile("/opt/module/spark_testdata/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((hello,2), (world,2), (spark,1), (hi,2))
spark-submit :提交应用
将写好的spark打包上传至linux,然后执行以下命令
[hadoop@hadoop103 spark-local]$bin/spark-submit --class com.spark.day01.WcCount /opt/module/spark_testdata/09sparkdemo-1.0-SNAPSHOT.jar /opt/module/spark_testdata/1.txt
bin/spark-submit \ --提交应用
--class com.spark.day01.WcCount \ --主类名字
/opt/module/spark_testdata/09sparkdemo-1.0-SNAPSHOT.jar \ --应用类所在的jar包
/opt/module/spark_testdata/1.txt --程序的入口参数
yarn模式
前提,环境中已经安装好hadoop
spark只是类似一个客户端(选择任意一台可以连接上YARN的机器安装即可),YARN是服务端!
1.安装
将spark-3.0.0-bin-hadoop3.2.tgz文件上传到linux并解压缩,放置在指定位置,改包名为spark-yarn
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-examples_2.12-3.0.0 spark-yarn
配置
①修改hadoop的/hadoop/etc/hadoop/yarn-site.xml配置文件,然后分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--允许第三方程序,例如spark将Job的日志,提交给Hadoop的历史服务 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
②修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
改名 : mv spark-env.sh.template spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
#环境变量中有可以不配
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.使用
① 启动HDFS和yarn集群
jps验证下
[hadoop@hadoop103 spark-local]$ myjps
================ hadoop102 JPS =====================
1809 NameNode
2434 Jps
1939 DataNode
2281 NodeManager
================ hadoop103 JPS =====================
2867 NodeManager
2552 DataNode
2744 ResourceManager
3263 Jps
================ hadoop104 JPS =====================
1587 DataNode
1797 NodeManager
1676 SecondaryNameNode
1951 Jps
web界面验证下:
② 提交应用
官方案例
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
自定义的WordCount程序
bin/spark-submit \
--class com.spark.day01.WcCount \
--master yarn \
--deploy-mode cluster \
/opt/module/spark_testdata/09sparkdemo-1.0-SNAPSHOT.jar \
hdfs://hadoop102:8020/input
注意:
读取的文件最好放在hdfs路径,注意端口号别写错,core-site.xml中配置。
放在本地路径可能出现文件找不到的异常。
3.spark的历史服务器集成yarn
① 修改spark-defaults.conf.template文件名为spark-defaults.conf
spark.eventLog.enabled true
#HDFS的节点和端口和目录
spark.eventLog.dir hdfs://hadoop102:8020/spark-logs
#spark的历史服务器,在spark所在节点,端口18080
spark.yarn.historyServer.address=hadoop03:18080
spark.history.ui.port=18080
注意:HDFS上的目录需要提前存在。
② 修改spark-env.sh文件,配置日志存储路径
#spark的历史服务器
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/spark-logs
-Dspark.history.retainedApplications=30"
③ 启动spark的历史服务器
sbin/start-history-server.sh
④ 提交应用程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
⑤ 观察web界面
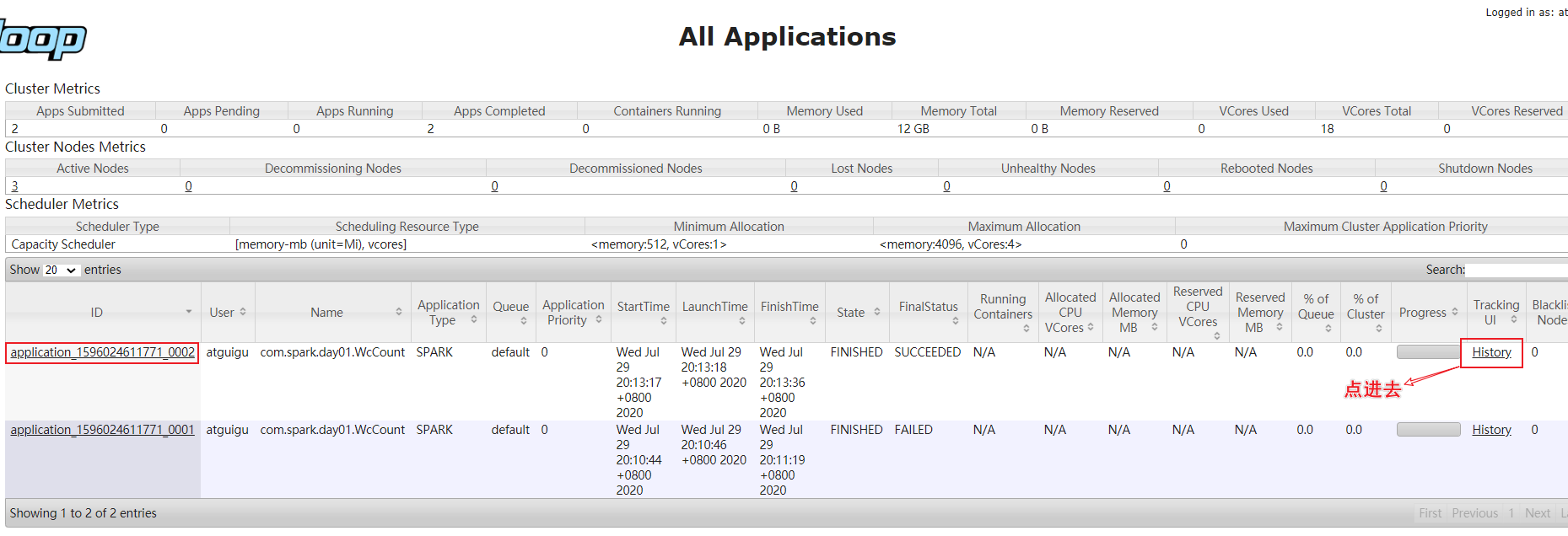
spark的历史服务器
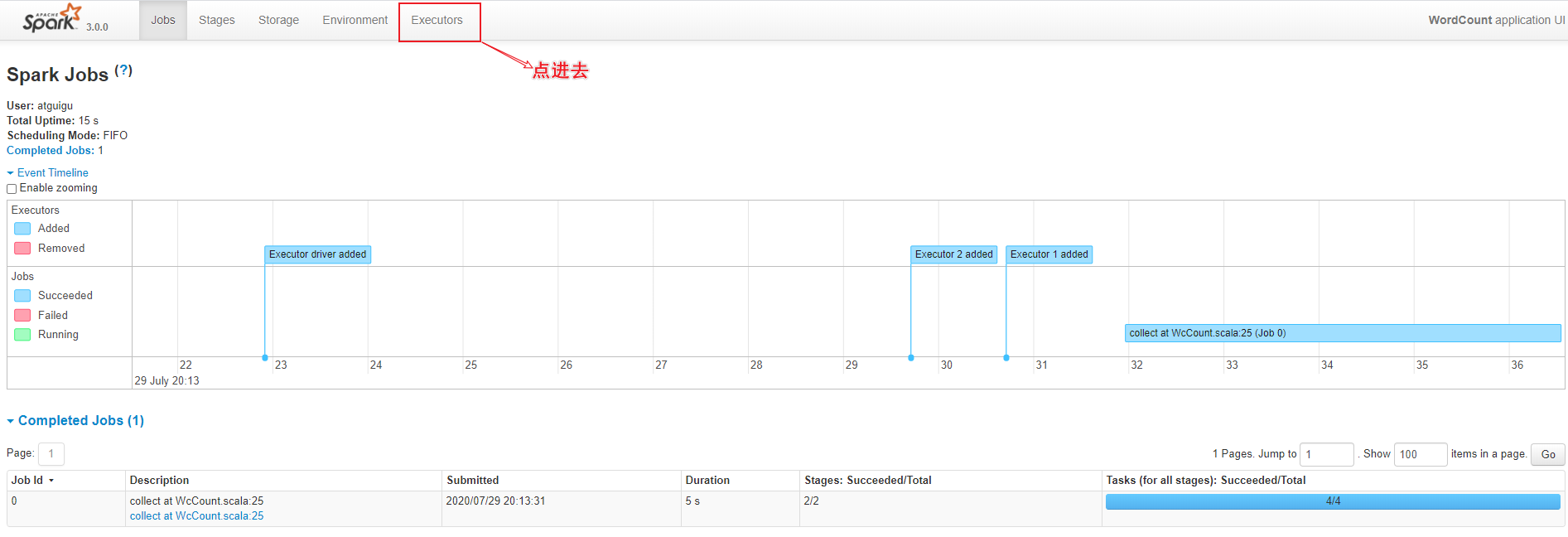
hadoop的历史服务器
Spark(一)【spark-3.0安装和入门】的更多相关文章
- Zabbix4.0安装与入门及常见配置
1.安装zabbix-server 环境: 10.0.0.50 zabbix-server 10.0.0.51 zabbix-web 10.0.0.52 zabbix-agent yum -y ins ...
- win10,vs2017+mpi v10.0 安装与入门 (详细)
一.安装visual studio 2017 下载 地址:https://visualstudio.microsoft.com/zh-hans/vs/ 安装 我们再选择自己想要安装的东西,确认好后点 ...
- spark 1.6.0 安装与配置(spark1.6.0、Ubuntu14.04、hadoop2.6.0、scala2.10.6、jdk1.7)
前几天刚着实研究spark,spark安装与配置是入门的关键,本人也是根据网上各位大神的教程,尝试配置,发现版本对应最为关键.现将自己的安装与配置过程介绍如下,如有兴趣的同学可以尝试安装.所谓工欲善其 ...
- Spark新手入门——3.Spark集群(standalone模式)安装
主要包括以下三部分,本文为第三部分: 一. Scala环境准备 查看二. Hadoop集群(伪分布模式)安装 查看三. Spark集群(standalone模式)安装 Spark集群(standalo ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- spark在不同环境下的搭建|安装|local|standalone|yarn|HA|
spark的集群环境安装搭建 1.spark local模式运行环境搭建 常用于本地开发测试,本地还分为local单线程和local-cluster多线程; 该模式被称为Local[N]模式,是用单机 ...
- 平易近人、兼容并蓄——Spark SQL 1.3.0概览
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件.除了接过Shark的接力棒,继续为Spark用户提供高性能的SQL on Hadoop解决方案之外, ...
- 【转载】Spark SQL 1.3.0 DataFrame介绍、使用
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12358&page=1 1.DataFrame是什么?2.如何创建DataF ...
随机推荐
- hdu 5183 Negative and Positive (NP)(STL-集合【HASH】)
题意: When given an array (a0,a1,a2,⋯an−1) and an integer K, you are expected to judge whether there i ...
- c++ IO库
1:为了支持使用宽字符的语言,标准库定义了一组类型和对象来操作wchar_t类型的数据.宽字符版本的类型和函数的名字以w开头.宽字符版本和普通的char版本定义在同一个头文件中,例如头文件fstrea ...
- 力扣 - 剑指 Offer 59 - I. 滑动窗口的最大值
题目 剑指 Offer 59 - I. 滑动窗口的最大值 思路1(单调队列) 使用单调(递减)队列,保持队列中的元素是递减顺序,队列头保存的是当前窗口中最大的元素 首先先模拟建立第一个窗口,同时获取第 ...
- LeetCode刷题 树专题
树专题 关于树的几个基本概念 1 树的节点定义 2 关于二叉树的遍历方法 2.1 前序遍历 2.2 中序遍历 2.3 后序遍历 2.4 层序遍历 3 几种常见的树介绍 3.1 完全二叉树 3.2 二叉 ...
- python Max retries exceeded with URL in requests
使用requests进行重试 import requests from requests.adapters import HTTPAdapter from requests.packages.urll ...
- 《Python语言程序设计》【第2周】Python基本图形绘制
实例2:Python蟒蛇绘制 #PythonDraw.py import turtle #import 引入了一个绘图库 turtle 海龟库--最小单位像素 turtle.setup(650, 35 ...
- Java核心技术--Java程序设计
Java术语 术语名 缩写 解释 Java Development Kit(Java开发工具包) JDK 编写Java程序的程序员使用的软件 Java Runtime Environment(Java ...
- scrapy获取当当网多页的获取
结合上节,网多页的获取只需要修改 dang.py import scrapy from scrapy_dangdang.items import ScrapyDangdang095Item class ...
- Hadoop集群 增加节点/增加磁盘
在虚拟机中新建一个机器. 设置静态IP 将修改/etc/hosts 192.168.102.10 master 192.168.102.11 slave-1 192.168.102.12 slave- ...
- C#长程序(留着看)
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...