老Python带你从浅入深探究List
列表
Python中的列表(list)是最常用的数据类型之一。
Python中的列表可以存储任意类型的数据,这与其他语言中的数组(array)不同。
被存入列表中的内容可称之为元素(element)或者数据项(data item)亦或是值(value)。
虽然Python列表支持存储任意类型的数据项,但不建议这么做,事实上这么做的概率也很低。
列表特性
列表的特点:
- 列表属于容器序列
- 列表属于可变类型,即对象本身的属性会根据外部变化而变化,例如长度
- 列表底层由顺序存储组成,而顺序存储是线性结构的一种
基本声明
以下是使用类实例化的形式进行对象声明:
li = list((1, 2, 3, 4, 5))print("值:%r,类型:%r" % (li, type(li)))# 值:[1, 2, 3, 4, 5],类型:<class 'list'>
也可以选择使用更方便的字面量形式进行对象声明,利用[]对数据项进行包裹,并且使用逗号将数据项之间进行分割:
li = [1, 2, 3, 4, 5]print("值:%r,类型:%r" % (li, type(li)))# 值:[1, 2, 3, 4, 5],类型:<class 'list'>
多维列表
当一个列表中嵌套另一个列表,该列表就可以称为多维列表。
如下,定义一个2维列表:
li = [1, 2, ["三","四"]]print("值:%r,类型:%r" % (li, type(li)))值:[1, 2, ['三', '四']],类型:<class 'list'>
续行操作
在Python中,列表中的数据项如果过多,可能会导致整个列表太长,太长的列表是不符合PEP8规范的。
- 每行最大的字符数不可超过79,文档字符或者注释每行不可超过72
Python虽然提供了续行符\,但是在列表中可以忽略续行符,如下所示:
li = [1,2,3,4,5]print("值:%r,类型:%r" % (li, type(li)))# 值:[1, 2, 3, 4, 5],类型:<class 'list'>
类型转换
列表支持与布尔型、字符串、元组、以及集合类型进行类型转换:
li = [1, 2, 3]bLi = bool(li) # 布尔类型strLi = str(li) # 字符串类型tupLi = tuple(li) # 元组类型setLi = set(li) # 集合类型print("值:%r,类型:%r" % (bLi, type(bLi)))print("值:%r,类型:%r" % (strLi, type(strLi)))print("值:%r,类型:%r" % (tupLi, type(tupLi)))print("值:%r,类型:%r" % (setLi, type(setLi)))# 值:True,类型:<class 'bool'># 值:'[1, 2, 3]',类型:<class 'str'># 值:(1, 2, 3),类型:<class 'tuple'># 值:{1, 2, 3},类型:<class 'set'>
如果一个2维列表遵循一定的规律,那么也可以将其转换为字典类型:
li = [["k1", "v1"], ["k2", "v2"], ["k3", "v3"]]dictList = dict(li)print("值:%r,类型:%r" % (dictList, type(dictList)))# 值:{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'},类型:<class 'dict'>
四则运算
列表支持与元组,列表进行加法运算:
+:合并2个列表并生成新列表:
li1 = [1, 2, 3]li2 = [4, 5, 6]newLi = li1 + li2print(newLi)# [1, 2, 3, 4, 5, 6]
+=:扩展已有列表,相当于extend()方法:
oldLi = [1, 2, 3]newLi = [4, 5, 6]oldLi += newLiprint(oldLi)# [1, 2, 3, 4, 5, 6]
列表支持与数字进行乘法运算:
*:生成一个重复旧列表数据项的新列表:
oldLi = [1, 2, 3]newLi = oldLi * 3print(newLi)# [1, 2, 3, 1, 2, 3, 1, 2, 3]
*=:扩展已有列表,将已有列表的数据项进行重复添加:
oldLi = [1, 2, 3]oldLi *= 3print(oldLi)# [1, 2, 3, 1, 2, 3, 1, 2, 3]
索引切片
索引的概念
列表底层是以一种连续的顺序结构存储数据项,故可以使用索引(index)对数据项进行获取、删除、截取、替换等操作。
----------------------------|| A | B | C | D | E | F | G |----------------------------|| 0 | 1 | 2 | 3 | 4 | 5 | 6 ||-7 |-6 |-5 |-4 |-3 |-2 |-1 |
正向索引都是从0开始,负向索引都是从-1开始。
enumerate()
我们以一个内置函数enumerate()来举例,该函数返回一个迭代器,将其转换为list()后可以查看数据项以及正向索引:
li = ["A", "B", "C", "D", "E", "F", "G"]print(list(enumerate(li)))# [(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'), (6, 'G')]
更多的关于enumerate()函数的妙用,将会放在循环章节中进行探讨。
slice()
slice()函数有三个参数:
start:索引开始的位置
stop:索引结束的位置
step:步长间距,默认为1
如果为正数代表正取,如果为负数代表倒取
如果为1代表连续取,如果为2代表隔一个取一个,以此类推
使用方法如下示例,先使用slice()确定截取数据项的范围,然后再使用列表的[]操作形式取出指定范围的数据项。
注意:所有的切片都是顾头不顾尾:
li = ["A", "B", "C", "D", "E", "F", "G"]# 取出A# 释义:从0开始取,取1个,步长为0s = slice(0, 1, None)print(li[s])# ['A']
[::]形式
使用slice()函数会比较繁琐,直接使用[::]形式进行切片会比较简单。
签名如下:
[start:stop:step]
参数描述和slice()相同,当某一参数不设置时可省略前面的参数。
增删改截操作演示:
>>> # 获取第2个数据项>>> li = ["A", "B", "C", "D", "E", "F", "G"]>>> li[1]'B'>>> # 删除第3个数据项>>> del li[2]>>> li['A', 'B', 'D', 'E', 'F', 'G']>>> # 从第1个数据项开始向后替换2个数据项,替换内容为123>>> li[0:3] = 1,2,3>>> li[1, 2, 3, 'E', 'F', 'G']>>> # 从第1个数据项开始获取2个数据项>>> li[0:3][1, 2, 3]>>> # 试图访问一个超出索引之外的数据项,将引发异常>>> li[100]IndexError: list index out of range
需要注意的是,如果使用[:]则会创建一个新的列表,再将原有列表中的数据项全部引用至新的列表中,类似于浅拷贝的概念。
如下所示:
l1 = ["A", "B", "C", "D", "E", "F", "G"]l2 = l1[:]print("值:%s,地址:%s" % (l1, id(l1)))print("值:%s,地址:%s" % (l2, id(l2)))# 值:['A', 'B', 'C', 'D', 'E', 'F', 'G'],地址:4366350216# 值:['A', 'B', 'C', 'D', 'E', 'F', 'G'],地址:4366660104
正向切片
正向切片即使用正向索引,索引从0开始进行切片。
如下示例:
>>> li = ["A", "B", "C", "D", "E", "F", "G"]>>> li[0:3]['A', 'B', 'C']
反向切片
反向切片即使用反向索引,索引从-1开始进行切片。
如下示例:
>>> li = ["A", "B", "C", "D", "E", "F", "G"]>>> li[-3:]['E', 'F', 'G']
多维切片
列表是支持多维切片的,如下示例,拿出2维列表中的数据项A:
>>> li = [1, 2, ["A", "B"]]>>> li[-1][0]'A'
高级切片
反向和正向切片可以混合使用,下面是一些高级切片的用法:
>>> li = ["A", "B", "C", "D", "E", "F", "G"]>>> li[:] ①['A', 'B', 'C', 'D', 'E', 'F', 'G']>>> li[2:4] ②['C', 'D']>>> li[::2] ③['A', 'C', 'E', 'G']>>> li[::-2]['G', 'E', 'C', 'A'] ④>>> li[::-1] ⑤['G', 'F', 'E', 'D', 'C', 'B', 'A']>>> li[:-5:-2] ⑥['G', 'E']>>> li[0::-1] ⑦['A']>>> li[5::-2] ⑧['F', 'D', 'B']
如何一眼读懂高级切片,通过以下步骤判定:
- 第一步先观察step,是负数还是正数,负数代表倒着取
- 第二步观察start,确定切片的开始位置
- 第三步观察stop,确定切片的结束位置
上述示例演示的说明,带*的是比较重要的方式。
①:列表的[:]操作是创建一个新的列表,再将原有列表中的数据项全部引用一次至新的列表*
②:步长为空,代表正着取,从第2号索引位置的数据项开始,到第4号索引位置的数据项结束,根据顾头不顾尾原则,取2,3号索引的数据项*
③:步长为2,代表正着取,隔一个取一个,即从0号索引位置的数据项开始,每次往后数到2的时候再取*
④:步长为-2,代表倒着取,隔一个取一个,即从-1号索引位置的数据项开始,每次向前数到2的时候再取*
⑤:步长为-1,代表倒着取,即从-1号索引位置的数据项开始,取到索引0号位置结束*
⑥:步长为-2,代表倒着取,隔一个位置取一个,取到-5索引位置结束,根据顾头不顾尾原则,不取-5索引位置的数据项
⑦:步长为-1,代表倒着取,开始位置为0,结束位置未标记,则取1个
⑧:步长为-2,代表倒着取,隔一个取一个,开始位置为5号索引,则从第5号索引开始向前取
解构方法
*语法
使用*语法可对列表进行解构,将列表中的数据项全部提取出来:
li = [1, 2, 3]print(*li)# 1 2 3
我们可以利用*语法的特性,来达到两个列表进行合并产生新列表的效果,类似于+:
l1 = [1, 2, 3]l2 = [4, 5, 6]result = [*l1, *l2]print(result)# [1, 2, 3, 4, 5, 6]
解构赋值
如果一个列表中的数据项需要赋值到变量中,可使用解构赋值,需要注意的是变量接收位置与列表中的数据项位置需要一一对应:
li = ["A", "B"]item1, item2 = liprint(item1, item2)# A B
我们只想取出列表中前2个数据项时,可使用*语法将剩下的数据项全部打包到一个变量中:
li = ["A", "B", "C", "D", "E", "F", "G"]item1, item2, *otherItems = liprint(item1, item2)print(otherItems)# A B# ['C', 'D', 'E', 'F', 'G']
如果只想取第1个后和最后2个,中间的都不想要怎么办?也可以通过*语法:
li = ["A", "B", "C", "D", "E", "F", "G"]itemFirst, *_, itemLast1, itemLast2 = li # ①print(itemFirst, itemLast1, itemLast2)print(_)# A F G# ['B', 'C', 'D', 'E']
①:_为匿名变量,参见变量与常量一章节中的释义
常用方法
方法一览
常用的list方法一览表:
| 方法名 | 返回值 | 描述 |
|---|---|---|
| append() | None | 将数据项添加至列表的末尾 |
| extend() | None | 通过附加来自可迭代对象的数据项来扩展列表 |
| insert() | None | 在索引之前插入对象 |
| pop() | item | 删除并返回索引处的项目(默认为-1)。如果列表为空或索引超出范围,则引发IndexError |
| copy() | list | 返回L的浅拷贝 |
| remove() | None | 删除列表中第一次出现的数据项。如果不存在该数据项,则引发ValueError |
| clear() | None | 从L移除所有项目 |
| count() | integer | 返回数据项在L中出现的次数 |
| index() | integer | 返回第一个数据项在L中出现位置的索引,若值不存在,则抛出ValueError |
| sort() | None | 对列表进行原地排序,可指定参数reverse,若不指定该参数则默认升序排列,指定该参数则为降序排列 |
基础公用函数:
| 函数名 | 返回值 | 描述 |
|---|---|---|
| len() | integer | 返回容器中的项目数 |
| enumerate() | iterator for index, value of iterable | 返回一个可迭代对象,其中以小元组的形式包裹数据项与正向索引的对应关系 |
| reversed() | ... | 详情参见函数章节 |
| sorted() | ... | 详情参见函数章节 |
获取长度
使用len()方法来获取列表的长度。
返回int类型的值。
li = ["A", "B", "C", "D", "E", "F", "G"]print(len(li))# 7
Python在对内置的数据类型使用len()方法时,实际上是会直接的从PyVarObject结构体中获取ob_size属性,这是一种非常高效的策略。
PyVarObject是表示内存中长度可变的内置对象的C语言结构体。
直接读取这个值比调用一个方法要快很多。
追加元素
使用append()方法为当前列表追加一个数据项。
返回None:
li = ["A", "B", "C", "D", "E", "F", "G"]li.append("H")print(li)# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
你也可以使用+=进行操作,但个人并不推荐这样使用。
在某些极端情况下,可能会出现一些难以察觉的Bug:
li = ["A", "B", "C", "D", "E", "F", "G"]li += "H"print(li)# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
列表合并
使用extend()方法来让当前列表与另一个可迭代对象进行合并。
返回None:
l1 = ["A", "B", "C", "D", "E", "F", "G"]l2 = ["H", "J", "K", "L"]l1.extend(l2)print(l1)# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L']
你也可以使用+=进行操作,但个人并不推荐这样使用。
在某些极端情况下,可能会出现一些难以察觉的Bug:
l1 = ["A", "B", "C", "D", "E", "F", "G"]l2 = ["H", "J", "K", "L"]l1 += l2print(l1)# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L']
插入元素
使用insert()方法将数据项插入当前列表中的指定位置。
返回None:
li = ["A", "B", "C", "D", "E", "F", "G"]li.insert(0, "a")print(li)# ['a', 'A', 'B', 'C', 'D', 'E', 'F', 'G']
列表拷贝
使用copy()方法将当前列表进行浅拷贝。
返回当前列表的拷贝对象:
oldLi = ["A", "B", "C", "D", "E", "F", "G"]newLi = oldLi.copy()print(oldLi)print(newLi)print(id(oldLi))print(id(newLi))print(id(oldLi[0]))print(id(oldLi[0]))# ['A', 'B', 'C', 'D', 'E', 'F', 'G']# ['A', 'B', 'C', 'D', 'E', 'F', 'G']# 4329305992# 4329607688# 4328383520# 4328383520
弹出元素
使用pop()方法弹出当前列表中在此索引位置的数据项,列表中该数据项将被删除,并返回被弹出的数据项。
若不指定位置,则默认弹出-1号索引位置的数据项:
li = ["A", "B", "C", "D", "E", "F", "G"]popItem1 = li.pop()popItem2 = li.pop(2)print(li)print(popItem1)print(popItem2)# ['A', 'B', 'D', 'E', 'F']# G# C
删除元素
使用remove()方法删除当前列表中的数据项,根据数据项的名字进行删除。
如果具有多个同名的数据项,则只会删除第一个。
返回None:
li = ["A", "A", "B", "C", "D", "E", "F", "G"]li.remove("A")print(li)# ['A', 'B', 'C', 'D', 'E', 'F', 'G']
我们也可以使用del li[index]进行数据项的删除:
li = ["A", "A", "B", "C", "D", "E", "F", "G"]del li[0]print(li)# ['A', 'B', 'C', 'D', 'E', 'F', 'G']
这种方式还可以删除多个:
li = ["A", "A", "B", "C", "D", "E", "F", "G"]del li[0:3]print(li)# ['C', 'D', 'E', 'F', 'G']
清空元素
使用clear()方法将当前列表进行清空,即删除所有数据项。
返回None:
li = ["A", "B", "C", "D", "E", "F", "G"]li.clear()print(li)# []
我们也可以使用del li[:]进行列表的清空:
li = ["A", "B", "C", "D", "E", "F", "G"]del li[:]print(li)# []
统计次数
使用count()方法统计数据项在该列表中出现的次数。
返回int:
li = ["A", "B", "C", "D", "E", "F", "G", "A"]aInLiCount = li.count("A")print(aInLiCount)# 2
查找位置
使用index()方法找到数据项在当前列表中首次出现的位置索引值,如数据项不存在则抛出异常。
返回int。
li = ["A", "B", "C", "D", "E", "F", "G", "A"]aInLiIndex = li.index("A")print(aInLiIndex)# 0
顺序排列
使用sort(li)将当前列表中的数据项按照ASCII码顺序进行排列,默认从小到大。
可指定参数resverse,用于是否翻转列表,如翻转列表则代表从大到小。
返回None:
li = ["A", "B", "C", "D", "E", "F", "G", "A"]li.sort(reverse=True)print(li)# 'G', 'F', 'E', 'D', 'C', 'B', 'A', 'A']
sort()方法内部采用timsort算法,这是一种非常优秀的算法,速度快且稳定。
底层探究
容器序列
这里引出一个新的概念,容器序列:
- 容器中能存放不同类型的数据项,如list就是标准的一个容器
- 序列是指具有长度的对象,且该对象能使用[]进行内部数据项的操作
容器序列存放的是它们所包含的任意类型的对象的引用,如下定义了一个列表:
x = [“A”, “B”, “C”]
它的内部存储结构如下图所示:
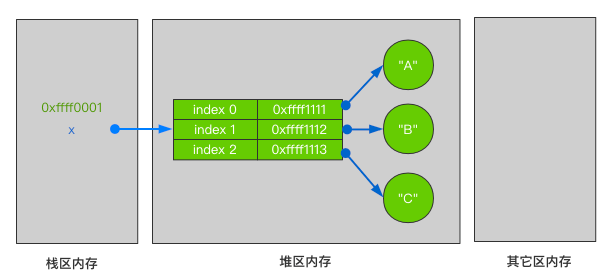
在CPython源码中,列表数据项的引用为PyObject **ob_item属性,即指针的指针。
元素调整
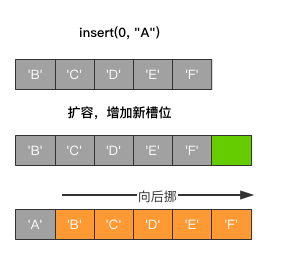
列表中,pop()和insert()方法都具有指定索引值的功能。
如果使用pop(0),或者insert(0)则都会引起整个列表中数据项的调整。
- pop(0)会将队首的数据项弹出并删除,后面的所有数据项都要向前挪一个位置。1变成0,2变成1,以此类推
- insert(0)会将新的数据项插入至队首,后面的所有数据项都要向后挪一个位置。0变成1,1变成2,以此类推
而单纯的使用pop()或者append()则不会发生元素调整,因为它们总是在队尾做操作。
总而言之,任何一个方法只要不是操作的队尾数据项,都会引起该列表中其他所有数据项的调整。
图示如下:
扩容机制
在对列表进行添加数据项时,如果列表内部的容量已满则会触发扩容机制。
我们要理解2个概念:
- 容量:容量指的是列表底层在开辟内存时,开辟了多大的内存空间,能够容纳多少数据项,可以理解为一共有多少个槽位
- 大小:大小指的是当前列表中,数据项已占据的容量,可以理解为已用了多少个槽位
在CPython源码中,列表容量的属性为Py_ssize_t allocated,而列表大小的属性为Py_ssize_t ob_size
在初始化列表时,容量和大小总是等于数据项的总个数,如:
- 一个空列表,容量和大小都为0
- 有8个槽位的列表,容量和大小都为8
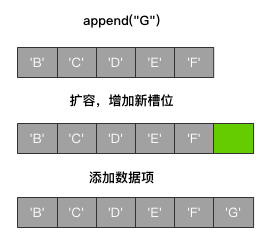
如果对一个已有的列表进行增加数据项的操作时会有以下2条判断,判定当前列表是否需要扩容:
当前列表容量 > 已有数据项个数+1 and 已有数据项个数 >= 当前列表容量的一半
则直接添加数据项,不进行扩容
并且新增数据项个数 Py_ssize_t ob_size + 1
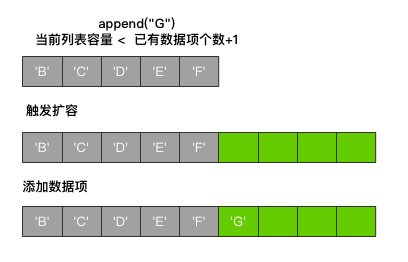
当前列表容量 < 已有数据项个数+1
则先进行扩容后再添加数据项
扩容是一种线性增长,增长规律为:0、4、8、16、24、32、40、52、64、76 …,总是为4的倍数
在扩容时不必担心发生内存溢出,因为内部已经设置了最大值
为:PY_SSIZE_T_MAX *(9/8)+ 6
缩容机制
缩容机制建立在列表有空余空间的情况下。
我们如果使用pop()方法删除了最后一个数据项,其实并不会将最后一个列表槽位所占用的内存空间给释放掉而是进行保留,内部仅进行一次Py_ssize_t ob_size - 1的操作。
这样做的好处是,后面再添加数据项时,其实就不用再次进行扩容了。
但是在添加数据项之前,会判断整个列表的容量是否过大,如果过大即代表还有很多空的位置,此时要进行缩容机制:
如果数据项个数 + 1 < 当前列表容量的一半
则进行缩容,删除空的列表槽位
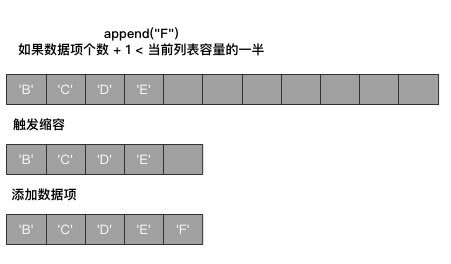
如果是clear()清空元素,则直接非常干脆的将容量以及大小都重置为0,并且将该列表所有槽位占据的内存空间进行释放。
迁徙机制
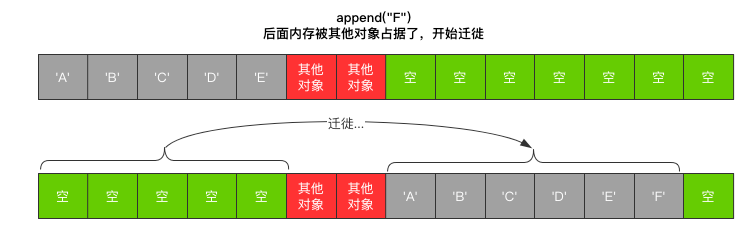
因为列表底层是顺序存储,必须占用一个连续的内存空间。
如果在进行扩容时,发现后面连续的内存空间被其他对象所占据,则会将整个列表进行一次拷贝。
然后迁徙到新的位置开辟内存,确保所有的列表槽位都是连续的。
列表缓存
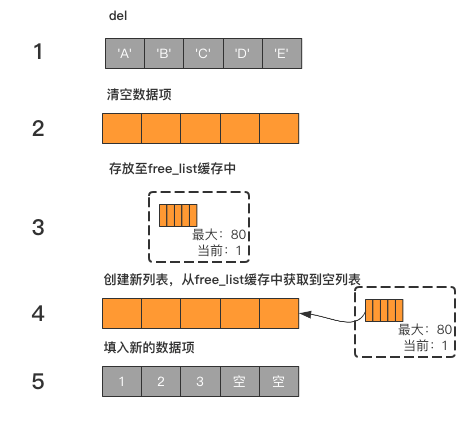
当删除一个列表之后,会将该列表中槽位引用的数据项地址全部清空。
并且将该列表的引用存放至一个叫做free_list的缓存中,下次如果再需要创建列表,则直接从free_list缓存中获取。
- free_list最多可以缓存80个列表
示例,旧列表被删除后将空列表的引用存放至free_list缓存中,当再次创建一个新列表时,会直接从free_list缓存中获取旧列表,并且填入数据项:
li1 = [1, 2, 3]print(id(li1))del li1li2 = [4, 5, 6, 7]print(id(li2))# 4405732936# 4405732936
PyObjectList.c源码
官网参考:点我跳转
源码一览:点我跳转
以下是截取了一些关键性源代码,并且做上了中文注释,方便查阅。
每一个列表都有几个关键性的属性:
Py_ssize_t ob_refcnt; // 引用计数器PyObject **ob_item; // 列表内部槽位的数据项指针,即指针的指针Py_ssize_t ob_size; // 列表大小Py_ssize_t allocated; // 列表容量
创建列表
PyObject *PyList_New(Py_ssize_t size){// 空列表if (size < 0) {PyErr_BadInternalCall();return NULL;}struct _Py_list_state *state = get_list_state();PyListObject *op;#ifdef Py_DEBUG// PyList_New() must not be called after _PyList_Fini()assert(state->numfree != -1);#endif// 判断是否有free_list中是否有缓存if (state->numfree) {// 有缓存,free_list缓存的列表个数减1state->numfree--;op = state->free_list[state->numfree];// 建立新的引用关系_Py_NewReference((PyObject *)op);}else {// 无缓存,创建新列表,先开辟内存op = PyObject_GC_New(PyListObject, &PyList_Type);if (op == NULL) {return NULL;}}if (size <= 0) {// 如果列表是空的,则将ob_item设置为NULL,即不引用任何数据项op->ob_item = NULL;}else {// 如果列表不是空的,则将每个槽位的数据项地址进行引用op->ob_item = (PyObject **) PyMem_Calloc(size, sizeof(PyObject *));if (op->ob_item == NULL) {Py_DECREF(op);return PyErr_NoMemory();}}// 设置列表中数据项占据的容量大小Py_SET_SIZE(op, size);// 设置列表的整体容量op->allocated = size;// 将列表放入双向链表中以进行内存管理_PyObject_GC_TRACK(op);// 返回列表的结构体指针return (PyObject *) op;}
添加元素
static intapp1(PyListObject *self, PyObject *v){// 获取列表的大小(已占用容量)Py_ssize_t n = PyList_GET_SIZE(self);assert (v != NULL);assert((size_t)n + 1 < PY_SSIZE_T_MAX);// 调用 list_resize()对容量进行计算// 扩容、或者缩容if (list_resize(self, n+1) < 0)return -1;// 增加数据项的引用计数器Py_INCREF(v);// 将数据项添加至列表的 ob_item 中PyList_SET_ITEM(self, n, v);return 0;}intPyList_Append(PyObject *op, PyObject *newitem){// 传入列表的引用, 还有新的数据项引用,并且验证列表和数据项if (PyList_Check(op) && (newitem != NULL))// 进行添加return app1((PyListObject *)op, newitem);PyErr_BadInternalCall();return -1;}
static intlist_resize(PyListObject *self, Py_ssize_t newsize){PyObject **items;size_t new_allocated, num_allocated_bytes;Py_ssize_t allocated = self->allocated;/* Bypass realloc() when a previous overallocation is large enoughto accommodate the newsize. If the newsize falls lower than halfthe allocated size, then proceed with the realloc() to shrink the list.*/// 扩容、缩容机制调用realloc()函数// allocated = 容量// newsize代表已存在的数据项个数 + 1// 当前列表容量 > 已有数据项个数+1 and 已有数据项个数 >= 当前列表容量的一半if (allocated >= newsize && newsize >= (allocated >> 1)) {assert(self->ob_item != NULL || newsize == 0);// 则直接添加数据项,不进行扩容// 并新增数据项个数 Py_ssize_t ob_size + 1Py_SET_SIZE(self, newsize);return 0;}/* This over-allocates proportional to the list size, making room* for additional growth. The over-allocation is mild, but is* enough to give linear-time amortized behavior over a long* sequence of appends() in the presence of a poorly-performing* system realloc().* Add padding to make the allocated size multiple of 4.* The growth pattern is: 0, 4, 8, 16, 24, 32, 40, 52, 64, 76, ...* Note: new_allocated won't overflow because the largest possible value* is PY_SSIZE_T_MAX * (9 / 8) + 6 which always fits in a size_t.*/new_allocated = ((size_t)newsize + (newsize >> 3) + 6) & ~(size_t)3;/* Do not overallocate if the new size is closer to overallocated size* than to the old size.*/// 如果数据项个数 + 1 < 当前列表容量的一半,则进行缩容,删除空的列表槽位// 当前列表容量 < 已有数据项个数+1,则先进行扩容后再添加数据项// 下面这句话是获取新的容量值if (newsize - Py_SIZE(self) > (Py_ssize_t)(new_allocated - newsize))new_allocated = ((size_t)newsize + 3) & ~(size_t)3;// 全是空的if (newsize == 0)new_allocated = 0;num_allocated_bytes = new_allocated * sizeof(PyObject *);// 基于realloc()进行扩容或者缩容,内部会包含数据项的位置调整items = (PyObject **)PyMem_Realloc(self->ob_item, num_allocated_bytes);if (items == NULL) {PyErr_NoMemory();return -1;}// 重新设置列表的 ob_item、obsize、allocatedself->ob_item = items;Py_SET_SIZE(self, newsize);self->allocated = new_allocated;return 0;}
插入元素
static intins1(PyListObject *self, Py_ssize_t where, PyObject *v){// 获取数据项个数Py_ssize_t i, n = Py_SIZE(self);PyObject **items;// 插入数据项确保不是NULLif (v == NULL) {PyErr_BadInternalCall();return -1;}assert((size_t)n + 1 < PY_SSIZE_T_MAX);// 重新计算容量是否可容纳新数据项的加入,从而进行扩容或缩容if (list_resize(self, n+1) < 0)return -1;// 如果where小于0,代表通过倒序索引进行插入if (where < 0) {where += n;if (where < 0)where = 0;}// 如果where大于列表的大小(已占据容量),则where = 已占据容量// 即插入到最后的一个位置if (where > n)where = n;// 拿到列表中所有数据项的引用items = self->ob_item;// 让插入位置之后的所有数据项开始向后挪动1个位置,腾出位置来插入新的数据项for (i = n; --i >= where; )// i + 1指的是数据项指针地址,每次 - 1items[i+1] = items[i];// 新增数据项的引用计数 + 1Py_INCREF(v);// 新的数据项索引位置和值做绑定items[where] = v;return 0;}intPyList_Insert(PyObject *op, Py_ssize_t where, PyObject *newitem){// 传入列表的引用, 插入的位置,还有新的数据项引用,并且验证列表和数据项if (!PyList_Check(op)) {PyErr_BadInternalCall();return -1;}// 进行插入return ins1((PyListObject *)op, where, newitem);}
移除元素
static PyObject *list_pop_impl(PyListObject *self, Py_ssize_t index)// 传入列表的引用,列表的弹出数据项索引位置{PyObject *v;int status;// 如果是一个空列表,则抛出异常if (Py_SIZE(self) == 0) {/* Special-case most common failure cause */PyErr_SetString(PyExc_IndexError, "pop from empty list");return NULL;}if (index < 0)index += Py_SIZE(self);// 如果索引值不存在,则抛出异常if (!valid_index(index, Py_SIZE(self))) {PyErr_SetString(PyExc_IndexError, "pop index out of range");return NULL;}// 找到准备弹出的数据项位置v = self->ob_item[index];// 如果弹出的数据项是列表中的最后一个if (index == Py_SIZE(self) - 1) {// list_resize()内部只会做size - 1,而不会回收内存进行缩容status = list_resize(self, Py_SIZE(self) - 1);if (status >= 0)return v; /* and v now owns the reference the list had */elsereturn NULL;}// 增加一次引用计数器Py_INCREF(v);// 如果弹出的数据项不是列表中的最后一个,则需要进行位置调整status = list_ass_slice(self, index, index+1, (PyObject *)NULL);if (status < 0) {Py_DECREF(v);return NULL;}// 返回被弹出的数据项return v;}
清空元素
static int_list_clear(PyListObject *a){Py_ssize_t i;PyObject **item = a->ob_item;if (item != NULL) {/* Because XDECREF can recursively invoke operations onthis list, we make it empty first. */i = Py_SIZE(a);// 重新设置大小为0Py_SET_SIZE(a, 0);// 将列表中插槽引用的对象全部设置为Nonea->ob_item = NULL;// 重新设置容量为0a->allocated = 0;// 循环列表中的数据项,令所有数据项的引用计数-1while (--i >= 0) {Py_XDECREF(item[i]);}PyMem_Free(item);}/* Never fails; the return value can be ignored.Note that there is no guarantee that the list is actually emptyat this point, because XDECREF may have populated it again! */return 0;}
删除列表
static voidlist_dealloc(PyListObject *op){Py_ssize_t i;// 内部会判断这个列表是否还有其他标识符引用,如果为0则代表没有其他标识符引用// 可以通过内部GC机制将该列表所占据的内存空间进行释放PyObject_GC_UnTrack(op);Py_TRASHCAN_BEGIN(op, list_dealloc)if (op->ob_item != NULL) {/* Do it backwards, for Christian Tismer.There's a simple test case where somehow this reducesthrashing when a *very* large list is created andimmediately deleted. */// 获取列表中已有数据项的个数(即大小)i = Py_SIZE(op);// 循环列表中的数据项,令所有数据项的引用计数-1while (--i >= 0) {Py_XDECREF(op->ob_item[i]);}PyMem_Free(op->ob_item);}struct _Py_list_state *state = get_list_state();#ifdef Py_DEBUG// list_dealloc() must not be called after _PyList_Fini()assert(state->numfree != -1);#endif// 判断free_list中的已缓存列表个数是否大于80,这里是没满// 在free_list中添加空列表的引用即可if (state->numfree < PyList_MAXFREELIST && PyList_CheckExact(op)) {state->free_list[state->numfree++] = op;}else {// 如果free_list的大小已达到容量限制// 则直接在内存中销毁列表的结构体对象Py_TYPE(op)->tp_free((PyObject *)op);}Py_TRASHCAN_END}
老Python带你从浅入深探究List的更多相关文章
- 老Python带你从浅入深探究Tuple
元组 Python中的元组容器序列(tuple)与列表容器序列(list)具有极大的相似之处,因此也常被称为不可变的列表. 但是两者之间也有很多的差距,元组侧重于数据的展示,而列表侧重于数据的存储与操 ...
- 浅入深出Vue:第一个页面
今天正式开始入门篇,也就是实战了~ 首先我们是要做一个博客网站,UI 框架采用江湖传闻中的 ElementUI,今天我们就来利用它确定我们博客网站的基本布局吧. 准备工作 新建一个vue项目(可以参考 ...
- Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码
在文章:Mybatis源码解析,一步一步从浅入深(一):创建准备工程,中我们为了解析mybatis源码创建了一个mybatis的简单工程(源码已上传github,链接在文章末尾),并实现了一个查询功能 ...
- Mybatis源码解析,一步一步从浅入深(六):映射代理类的获取
在文章:Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码中我们提到了两个问题: 1,为什么在以前的代码流程中从来没有addMapper,而这里却有getMapper? 2,UserDao ...
- 浅入深出之Java集合框架(上)
Java中的集合框架(上) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入深出之Java集合框架(中)
Java中的集合框架(中) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入深出之Java集合框架(下)
Java中的集合框架(下) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,哈哈这篇其实也还是基础,惊不惊喜意不意外 ̄▽ ̄ 写文真的好累,懒得写了.. ...
- 浅入深出Vue:环境搭建
浅入深出Vue:环境搭建 工欲善其事必先利其器,该搭建我们的环境了. 安装NPM 所有工具的下载地址都可以在导航篇中找到,这里我们下载的是最新版本的NodeJS Windows安装程序 下载下来后,直 ...
- 浅入深出Vue:工具准备之PostMan安装配置及Mock服务配置
浅入深出Vue之工具准备(二):PostMan安装配置 由于家中有事,文章没顾得上.在此说声抱歉,这是工具准备的最后一章. 接下来就是开始环境搭建了~尽情期待 工欲善其事必先利其器,让我们先做好准备工 ...
随机推荐
- IntelliJ IDEA安装lombok
1. 搜索Plugins 点击下方的Browse repositories.. 2.点击安装,重新启动
- HDFS设置配额的命令
1 文件个数限额 #查看配额信息 hdfs dfs -count -q -h /user/root/dir1 #设置N个限额数量,只能存放N-1个文件 hdfs dfsadmin -setQuota ...
- 设置beeline连接hive的数据展示格式
问题描述:beeline -u 方式导出数据,结果文件中含有"|"(竖杠). 执行的sql为:beeline -u jdbc:hive2://hadoop1:10000/defau ...
- C# 通过ServiceStack 操作Redis——ZSet类型的使用及示例
Sorted Sets是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列 /// <summary> /// Sorted Sets是将 ...
- P1739_表达式括号匹配(JAVA语言)
思路:刚开始想用stack,遇到'('就push,遇到')'就pop,后来发现其实我们只需要用到栈里'('的个数,所以我们用一个变量统计'('的个数就好啦~ 题目描述 假设一个表达式有英文字母(小写) ...
- windows平台 cloin +rust 开发环境搭建
rust 安装请看上一篇 clion 下载地址 破解 教程 1.先执行reset_jetbrains_eval_windows.vbs 2.打开软件选择免费使用 将ide-eval-resetter- ...
- [递推]D. 【例题4】传球游戏
D . [ 例 题 4 ] 传 球 游 戏 D. [例题4]传球游戏 D.[例题4]传球游戏 题目解析 设 t ( i , j ) t(i,j) t(i,j)为过了 j j j轮,轮到 i i i手上 ...
- Python的flask接收前台的ajax的post数据和get数据
ajax向后台发送数据: ①post方式 ajax: @app.route("/find_worldByName",methods=['POST']) type:'post', d ...
- [Fundamental of Power Electronics]-PART II-9. 控制器设计-9.2 负反馈对网络传递函数的影响
9.2 负反馈对网络传递函数的影响 我们已经知道了如何推导开关变换器的交流小信号传递函数.例如,buck变换器的等效电路模型可以表示为图9.3所示.这个等效电路包含三个独立输入:控制输入变量\(\ha ...
- 痞子衡嵌入式:在i.MXRT启动头FDCB里使能串行NOR Flash的DTR模式
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是在FDCB里使能串行NOR Flash的DTR模式. 前两篇文章 <IS25WP系列Dummy Cycle设置> 与 < ...