OO_JAVA_表达式求导
OO_JAVA_表达式求导_第一弹
---------------------------------------------------表达式提取部分
词法分析
首先,每一个表达式内部都存在不可分割的字符组,比如一个不止一位的数字,或是一个sin三角函数,这样不能分离的字符组我称之为词法单元,依照其定义,可以将第三次作业的表达式分割成如下词法单元:
- SPACE:即空格和TAB字符的组合
- 纯数字:即纯粹由0-9字符集组成
- 运算符:-、+、*、^,这些都是运算符
- 三角函数:sin或cos内部不可存在空格
- 左括号:(
- 右括号:)
将一串字符解析成词法单元列表的形式,就已经是一层处理了,这一步就可以排查出一些错误,直接抛出异常,然后我们得到了一个由词法单元组成的列表,现在就是采用递归递降的方法线性解析这个列表并生成表达树了。
语法分析
仔细阅读指导书,可以归纳出如下定义:
- Num = [-|+]纯数字
- Factor = Num | x [^ Num] | sin ( Factor) [^ Num] | cos ( Factor) [^ Num] | (Expr)
- Item = [-|+]Factor (*Factor)*
- Expr = [-|+]Item ([-|+]Item)*
** 其中[]表示其中的字符存在或不存在皆可;()*表示可选重复0至任意次;| 表示或 **
除Num单元内部,其它语法单元内部可以任意插入SPACE
写作分析函数的原则有两条:
- 采用分层次的设计思路,从归纳的语法定义就可以看出,需要写一个处理Expr的函数,一个处理Item的函数……需要子结构时调用相应函数即可。
- 只处理本层次需要处理的字符,遇到非法字符,返回上层调用或者抛出异常;
当然,有人会说,这样只是写一堆递归函数(o(╯□╰)o,我就是这么写的),没有实行面对对象,其实,递归递降也是可以面对对象的。
模式匹配
首先需要一个Parser接口,实现如下(不一定)函数(为清晰起见,写的很简单)
public interface Parser {
public Atom toAtom();
public Integer getIndex();
public void addParser(Parser parser);
}
分别是一个转换函数,一个获取新遍历下标的函数,一个添加子Parser的函数。
根据不同层级Parser的需要,完成相应函数的重写(Override)即可,举个栗子:
public class ExprParser implements Parser {
ArrayList<Parser> itemList;
// Integer endIndex; //
private ExprParser() {
itemList = new ArrayList<>();
}
@Override
public Atom toAtom() {
Atom root = new Atom(Atom.Type.PLUS, BigInteger.ZERO);
for (Parser parser:itemList) {
root.addChild(parser.toAtom());
}
return root;
}
@Override
public Integer getIndex() {
return endIndex;
}
public static Parser newParser(String string) {
Parser parser = new ExprParser();
for (int i = 0; i < string.length();) {
if (string.charAt(i) == '-' || string.charAt(i) == '+' ||
string.charAt(i) != ' ' && string.charAt(i) != '\t') {
Parser itemParser = ItemParser.newParser(string.substring(i));
parser.addParser(itemParser);
i = itemParser.getIndex();
} else {
i += 1;
}
}
return parser;
}
@Override
public void addParser(Parser parser) {
itemList.add(parser);
}
}
依旧格式简易,但是只是为了说明怎么重写这样的函数,Atom即最后生成的表达树的节点类或者接口,随个人意。
另外没有显式抛出异常,真正写时需要在返回parser时检查item List是否为空,若为空,则显式抛出异常,进行异常处理。
现在说明一下,这个newParser工厂函数为什么这么写,为了清楚起见,我把Expr的定义重新拉过来:
Expr = [-|+]Item ([-|+]Item)*
这个语法定义告诉我们Expr线性扫描,检查是否有减号或是加号,然后需要获取一个Item,这时调用ItemParser的工厂函数即可,格式异常由不同层级的Parser实现类的工厂函数负责抛出,只要语法分析合理,这样写作是简单无误的。
以此类推,相信读懂了上述抽象的思维方式,写出Item和Factor的Parser对你易如反掌!
OO_JAVA_表达式求导_第二弹
------------------------------------------------表达树的构建
总体来说,按照设计模式上可以分为两类:本次实验还是建议第二种方式(虽然我用了第一种,,::>_<::)
- extends 继承,采取一个父类实现所需方法子类重写方法,但是为了统一填充到ArrayList或者HashMap中,必须采取子类cast回父类的方式,这样子类不能有自己的属性,否则无法cast;
- implements 实现,采取定义共通的接口,所有节点类重写接口中的方法,如求导方法、化简方法、toString方法。
在第三次作业中,我采用了继承的方案实现树形结构节点的构造,Atom父类实现了非常多的函数,现在的视角来看,是很不合理的,因为Atom负担了所有子类的函数,臃肿累赘,层次是分明了,只有父类Atom和子类各种Atom,但是在工程管理和逻辑架构设计上,还是有所问题的。
下面是我的Atom类图关系,其它类都继承自Atom很复杂把。
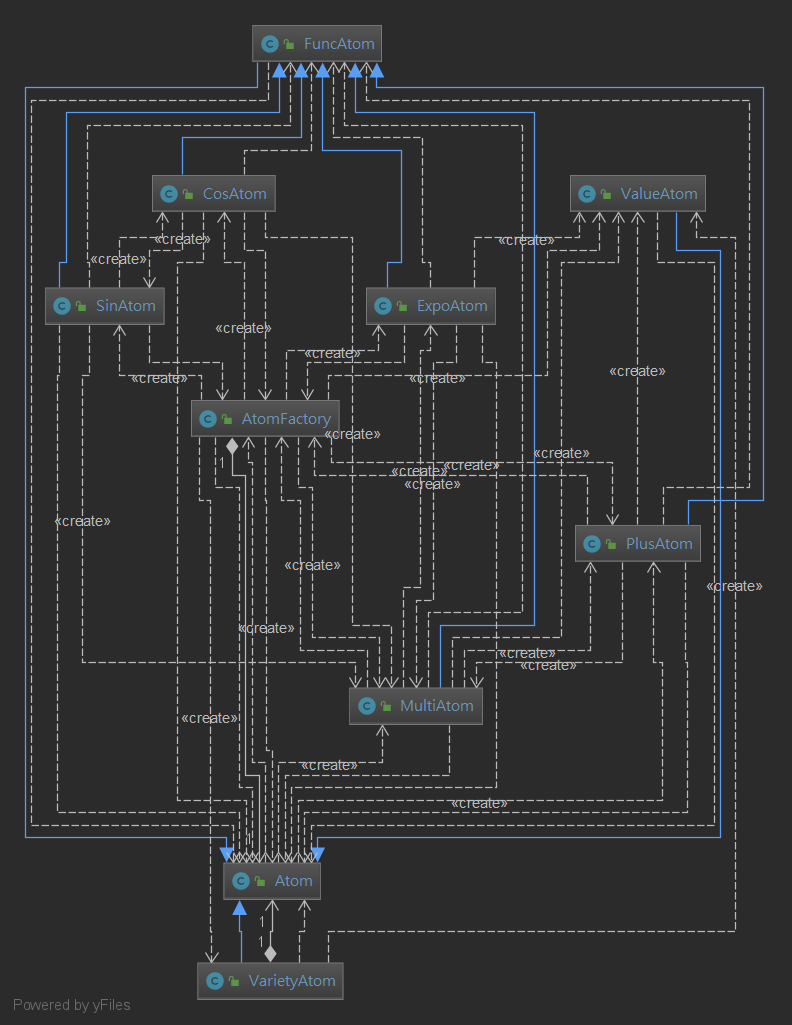
OO_JAVA_表达式求导_第三弹
-----------------------------如何将函数式思维带入化简函数
要实现化简合并,最好先完成两个准备工作(一个可选)
- expand:展开(可选),有时会遇见123*(x+123)这样的情况,*与+没有按照优先级组合,而是需要根据乘法分配率展开这样的项;
- flat Map:平铺,在处理字符串生成表达树以及求导表达树返回新表达树的过程中,会产生很多如1*(1*(1*x))连乘项或连加项嵌套的结果,平铺可以将之展开成为1*1*1*x的形式,利于下一步的分类和合并。
首先从宏观的角度抽象地理解化简,是怎么一回事,一共两步
- classification:分类,将能化简的规整在一起,不能化简的单独存放,最终结果是一个List<List<Atom>>,每一个List<Atom>存放的是可以合并的同类项;
- merge:合并,对不同的可合并List<Atom>进行合并处理,再新建一个父对象,将合并结果依次填回父对象的子节点中,返回父对象。
现在简单说明一下Java8引入的Stream API和lambda表达式(实际上是Functional Interface)
举个栗子,现在我们有一串数字在列表origin中,我们要对他们都平个方,生成一个新列表,正常做法如下:
List<Integer> after = new ArrayList<>();
for (Integer integer: origin) {
after.add(integer * integer);
}
但是有了Stream API和lambda表达式,就可以这么写:
List<Integer> after = origin.stream().map(e -> e * e).collect(toList());
Stream流的主要功能有filter(筛选),map(映射),flatMap(平铺映射),collect(收集返回列表或Map或其它)。
需要填充函数接口的参数的来源有两种:
- 方法引用,比如Integer::add,就是对Integer的加法方法的一个引用,内秉其实是函数接口
- lambda表达式,基本形式为(参数列表)->返回值 或 (参数列表)->{语句; return 返回值;}组成。
现在问题来了,为什么要这么写呢?什么时候要写成哪一种形式呢?
- 这两种写法的主要区别在于逻辑的分离性与可控性:前者循环方式,循环流程完全由你掌控,可操作性极大,同时脑力负担也大一些;后者将循环体隐藏在Stream API的内部,你不需要在控制循环的方方面面,可以一层层地分离逻辑,减轻脑力负担,高效清晰地编写代码。
- 在循环体内部流程非常简单时,比如上述栗子,你选择哪一种都没有什么问题,无非是代码行数和内部执行效率的区别,但是,在具化到我要讲的classification过程时,也就是可以尽量分离循环体内部操作时,选择Stream API可以清晰地简单地生成新列表,下面就对此说明一下吧。
Classification可以分为四步:
- 实现一个函数(满足Predicate接口定义),也就是一个泛化意义上的相等函数,用来判断两项能否合并;
- 根据先前实现的接口,采用Stream的filter过滤器API,对每个元素,过滤出与之相等(可合并)的元素组成列表;
- 依照先前产生的列表,统统插入到Map中,为保证key的唯一,采用每一个列表的toString方法结果作为key;
- 将上述生成的Map的values取出,返回一个列表的列表,实现classification的功能。
上述过程就是一个逻辑不断分离的过程,对应到相加项和相乘项,唯一不同的就是Predicate接口,也是这么思维的意义所在。
这里把后三步的合并加法与合并乘法共通的代码贴出来:
public List<Atom> filter(Atom atom, Predicate<Atom> predicate) {
return this.children.stream()
.filter(predicate)
.collect(Collectors.toList());
}
public ArrayList<List<Atom>> classify(Predicate<Atom> predicate) {
Map<String, List<Atom>> map = new HashMap<>();
for (Atom atom : children) {
ArrayList<Atom> list = (ArrayList<Atom>) this.filter(atom, predicate);
map.put(list.toString(), list);
}
return new ArrayList<>(map.values());
}
与上述思维类似,Merge也可分步进行:
- 先merge所有子节点重新填充到新root节点中;
- 使用classification,获取新root节点分类后的子节点列表的列表;
- 创建新root节点,迭代前一步获取的列表,使用合并同类项函数(同类项列表=>合并后的项),将节点依次插入新的root节点中,返回。
继续拆分,上述第三步采用Stream的思路还可以拆分:
- 产生Stream<List<Atom>>流;
- map映射List<Atom>到Atom,这里交由另一个函数接口负责;
- filter筛选需要添加至最终列表的项,这里依然可以分离出去交由另一个函数接口负责;
- 最后collect函数收集流中的元素,返回List<Atom>,若为空,返回特定值。
这里举个例子就把合并相加项的filter调用的函数接口写一下吧:
Predicate<Atom> addPredicate = e -> !(
e.getType().equals(Atom.Type.CONSTANT) && e.getValue().equals(BigInteger.ZERO)
);
上述函数接口表明,如果元素e是一个常数0了话,返回false否则返回true。
综上所述,如果你理解了分离逻辑的操作后,写出清晰简洁的代码应该是易如反掌把!
OO_JAVA_表达式求导的更多相关文章
- OO_JAVA_表达式求导_单元总结
OO_JAVA_表达式求导_单元总结 这里引用个链接,是我写的另一份博客,讲的是设计层面的问题,下面主要是对自己代码的单元总结. 程序分析 (1)基于度量来分析自己的程序结构 第一次作业 程序结构大致 ...
- OO Unit 1 表达式求导
OO Unit 1 表达式求导 面向对象学习小结 前言 本博主要内容目录: 基于度量来分析⾃己的程序结构 缺点反思 重构想法 关于BUG 自己程序出现过的BUG 分析⾃己发现别人程序bug所采⽤的策略 ...
- BUAA-OO-第一单元表达式求导作业总结
figure:first-child { margin-top: -20px; } #write ol, #write ul { position: relative; } img { max-wid ...
- 2019年北航OO第1单元(表达式求导)总结
2019年北航OO第1单元(表达式求导)总结 1 基于度量的程序结构分析 量化指标及分析 以下是三次作业的量化指标统计: 关于图中指标在这里简要介绍一下: ev(G):基本复杂度,用来衡量程序非结构化 ...
- 2020 OO 第一单元总结 表达式求导
title: BUAA-OO 第一单元总结 date: 2020-03-19 20:53:41 tags: OO categories: 学习 OO第一单元通过三次递进式的作业让我们实现表达式求导,在 ...
- OO_Unit1_表达式求导总结
OO_Unit1_表达式求导总结 OO的第一单元主要是围绕表达式求导这一问题布置了3个子任务,并在程序的鲁棒性与模型的复杂度上逐渐升级,从而帮助我们更好地提升面向对象的编程能力.事实也证明,通过这 ...
- 面向对象第一单元总结:Java实现表达式求导
面向对象第一单元总结:Java实现表达式求导 题目要求 输入一个表达式:包含x,x**2,sin(),cos(),等形式,对x求导并输出结果 例:\(x+x**2+-2*x**2*(sin(x**2+ ...
- oo第一次博客-三次表达式求导的总结与反思
一.问题回顾与基本设计思路 三次作业依次是多项式表达式求导,多项式.三角函数混合求导,基于三角函数和多项式的嵌套表达式求导. 第一次作业想法很简单,根据指导书,我们可以发现表达式是由各个项与项之间的运 ...
- OO_BLOG1_简单表达式求导问题总结
作业1-1 包含简单幂函数的多项式导函数的求解 I. 基于度量的程序结构分析 1)程序结构与基本度量统计图 2)分析 本人的第一次作业的程序实现逻辑十分简单,但是OOP的色彩并不强烈,程序耦合度过 ...
随机推荐
- Robot Framework 面试题
什么是 RF 基于可扩展关键字驱动的自动化测试框架 什么是可扩展关键字驱动 可扩展意味着可以自己开发,也可以调用第三方的关键字库 关键字驱动意味着测试用例都是围绕着关键字运行的 RF 的原理(框架?) ...
- IPsec 9个包分析(主模式+快速模式)
第一阶段:ISAKMP协商阶段 1.1 第一包 包1:发起端协商SA,使用的是UDP协议,端口号是500,上层协议是ISAKMP,该协议提供的是一个框架,里面的负载Next payload类似模块,可 ...
- AspectJ基于xml和基于注解
一.基于xml 执行的切入点中具体方法有返回值,则方法结束会立即执行后置通知,然后再执行环绕通知的放行之后的代码: 2.连接点即所有可能的方法,切入点是正真被切的方法,连接点方法名: 其中,只有环绕通 ...
- Vue组件传值(三)之 深层嵌套组件传值 - $attrs 和 $listeners
$attrs 包含了父作用域中不作为 prop 被识别 (且获取) 的特性绑定 (class 和 style 除外).当一个组件没有声明任何 prop 时,这里会包含所有父作用域的绑定 (class和 ...
- Devexpress gridcontrol设置列样式
<dxg:GridControl.Columns><dxg:GridColumn Header="排名" FieldName="UserRank&quo ...
- python中时间处理标准库DateTime加强版库:pendulum
DateTime 的时区问题 Python的datetime可以处理2种类型的时间,分别为offset-naive和offset-aware.前者是指没有包含时区信息的时间,后者是指包含时区信息的时间 ...
- MySQL中的查询事务问题
之前帮同学做个app的后台,使用了MySQL+MyBatis,遇到了一个查询提交的问题,卡了很久,现在有时间了来复盘下 环境情况 假设有学生表: USE test; CREATE TABLE `stu ...
- composer 包 slim使用案例,一个简单的路由解决方案
nginx配置文件修改 location / { try_files $uri /index.php$is_args$args; } 设置好nginx伪静态,把所有的请求方式都转向到index.php ...
- PHP中针对区域语言标记信息的操作
相信大家对 zh_CN 这个东西绝对不会陌生,不管是 PHP 中,还是在我们的网页上,都会见到它的身影.其实这就是指定我们的显示编码是什么国家或者地区的,使用何种语言.对于这种区域语言的标记来说,PH ...
- session入库
#存储session的数据表示列结构,可作为参考#创建数据库(可选)CREATE DATABASE session;#使用创建的数据库(可选)USE session;#创建存储session的数据表( ...