搭建ELK日志平台(单机)
系统版本:Ubuntu 16.04.7 LTS
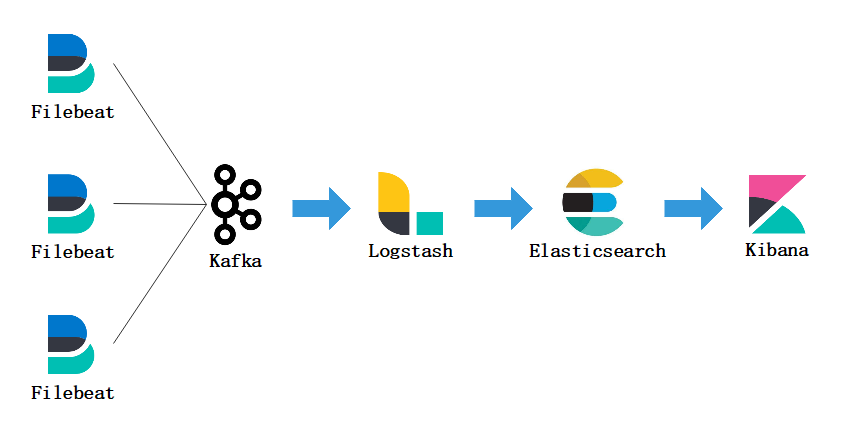
软件架构:Filebeat+Kafka+Logstash+Elasticsearch+Kibana+Nginx
软件版本:Filebeat-7.16.0、Kafka-2.11-1.0.0、Logstash-7.16.0、Elasticsearch-7.16.0、Kibana-1.76.0
主机性能:CPU:4c3.8Ghz、MEM:16GB、DISK:1TB
部署方式:单机
索引规划:按[主机环境]-[项目名称]-[日期]创建索引。
主题规划:按[主机环境]-[项目名称]创建主题。
注意事项:
ELK中所有服务组件建议使用兼容的相同版本。
由于Filebeat和Logstash对Kafka的兼容性,Kafka推荐使用1.0~2.0版本。
1. 在搭建之前的一些操作
1、创建工作目录
root@yw-elk:~# mkdir /data/elk/elasticsearch
root@yw-elk:~# mkdir /data/elk/logstash
root@yw-elk:~# mkdir /data/elk/kafka
root@yw-elk:~# mkdir /data/elk/kibana
2. Elasticsearch(存储日志)
用于数据存储。
通常存储来自于Logstash处理后的日志数据,以及Kibana管理控制台管理ES的交互数据,或者Beats扩展集成的数据。
Elasticsearch一个索引中可存储的文档数量为20亿。
1、解压二进制包
root@yw-elk:~# cd /data/elk/elasticsearch
root@yw-elk:/data/elk/elasticsearch# tar xzvf elasticsearch-7.16.0-linux-x86_64.tar.gz
2、配置Elasticsearch
默认情况下单节点的ES只允许创建999/1000个索引,我们生产+测试环境共有6个项目,每个项目的日志按天存,一天一个索引,则一年的索引总数=365*6=2190。所以我们需要扩大"cluster.max_shards_per_node"该项的值。
root@yw-elk:/data/elk/elasticsearch# cd elasticsearch-7.16.0/
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# vim config/elasticsearch.yml
cluster.name: my-application
node.name: node-1
node.master: true
node.data: true
path.data: /data/elk/elasticsearch/elasticsearch-7.16.0/data
path.logs: /data/elk/elasticsearch/elasticsearch-7.16.0/logs
bootstrap.memory_lock: true
network.host: 127.0.0.1
http.port: 9200
transport.port: 9300
discovery.type: single-node
discovery.seed_hosts: ["127.0.0.1"]
gateway.recover_after_nodes: 1
action.destructive_requires_name: true
cluster.routing.allocation.disk.threshold_enabled: false
cluster.max_shards_per_node: 10000
# 设置集群中节点最大分片数量,即单个节点可创建的最大索引数量。默认为1000。
### x-pack ###
xpack.security.enabled: true
3、设置JVM堆内存大小为4GB
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# vim config/jvm.options
-Xms4g
-Xmx4g
4、创建运行用户
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# useradd -M elk
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# chown -R elk.elk /data/elk/elasticsearch/elasticsearch-7.16.0
5、运行Elasticsearch
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# nohup sudo -u elk bin/elasticsearch &
root@yw-elk:~# netstat -lnupt |grep 9200
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 19021/java
6、创建内置账户的密码
内置账户说明:
- elastic,一个内置的超级用户。关联角色superuser。
- apm_system,用于Elastic APM在Elasticsearch中存储监控信息时使用的用户。关联角色apm_system。
- kibana,用于Kibana连接Elasticsearch并与之通信(已过时的内置用户)。关联角色kibana_system。
- kibana_system,用户Kibana连接Elasticsearch并与之通信。关联角色kibana_system。
- logstash_system,用于Logstash在Elasticsearch中存储监控信息时使用。关联角色logstash_system。
- beats_system,用于Beats在Elasticsearch中存储监控信息时使用。关联角色beats_system。
- remote_monitoring_user ,用于Metricbeat在Elasticsearch中收集和存储监控信息时使用。关联remote_monitoring_agent和remote_monitoring_collector角色 。
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# bin/elasticsearch-setup-passwords interactive
password: xxxxx
7、使用账号访问Elasticsearch(列出所有索引)
无需手动创建索引,索引由Logstash自动创建。
Elasticsearch默认最大索引数量为999,所以在创建索引的时候,建议一个项目对应一个索引。
root@yw-elk:/data/elk/elasticsearch/elasticsearch-7.16.0# curl -X GET -u elastic:xxx http://127.0.0.1:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases TCYNKgxLQCCzztI-5O410Q 1 0 42 0 41.1mb 41.1mb
green open .security-7 XkfwEgRVQcOnl3IpqKNOxg 1 0 7 0 25.7kb 25.7kb
3. Kibana(日志搜索与展示)
Elasticsearch的Web图形化操作管理控制台。
1、解压二进制包
root@yw-elk:~# cd /data/elk/kibana
root@yw-elk:/data/elk/kibana# tar xzvf kibana-7.16.0-linux-x86_64.tar.gz
2、配置Kibana
root@yw-elk:/data/elk/kibana# cd kibana-7.16.0-linux-x86_64
root@yw-elk:/data/elk/kibana/kibana-7.16.0-linux-x86_64# vim config/kibana.yml
server.port: 5601
server.host: "127.0.0.1"
server.publicBaseUrl: "http://elk.xxx.net"
elasticsearch.hosts: ["http://127.0.0.1:9200"]
elasticsearch.username: "kibana_system"
elasticsearch.password: "xxx"
logging.dest: /data/elk/kibana/kibana-7.16.0-linux-x86_64/logs/kibana.log
i18n.locale: "zh-CN"
3、使用elk用户启动Kibana
root@yw-elk:/data/elk/kibana# chown -R elk.elk kibana-7.16.0-linux-x86_64
root@yw-elk:/data/elk/kibana# cd kibana-7.16.0-linux-x86_64/
root@yw-elk:/data/elk/kibana/kibana-7.16.0-linux-x86_64# nohup sudo -u elk bin/kibana &
root@yw-elk:/data/elk/kibana/kibana-7.16.0-linux-x86_64# netstat -lnupt |grep 5601
tcp 0 0 127.0.0.1:5601 0.0.0.0:* LISTEN 13060/node
4、安装并配置Nginx反代Kibana
root@yw-elk:~# apt-get -y install nginx
root@yw-elk:~# vim /etc/nginx/conf.d/elk.conf
server {
listen 80;
server_name elk.xxx.net;
location / {
proxy_pass http://127.0.0.1:5601;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
root@yw-elk:~# systemctl restart nginx
root@yw-elk:~# systemctl enable nginx
5、使用浏览器访问
访问地址:http://elk.xxx.com
使用超级管理员"elastic"账号密码登录
4. Kafka(消息队列)
Kafka是一个消息队列MQ服务,异步传输日志数据。
Kafka减轻了Logstash的压力,Logstash有多少能力处理消息,则就从Kafka中消费消息。
这里为了安全性考虑,增加了SASL基础认证功能。
SASL(Simple Authentication and Security Layer)简单的身份验证和安全层,使用明文用户密码的方式保证Kafka的安全。
1、安装JDK
运行Kafka需要JDK环境的支持。
root@yw-elk:~# mkdir /data/elk/jdk
root@yw-elk:~# cd /data/elk/jdk
root@yw-elk:/data/elk/jdk# tar xzvf Jdk-8u211-linux-x64.tar.gz
root@yw-elk:/data/elk/jdk# vim /etc/profile
# jdk
export JAVA_HOME=/data/elk/jdk/jdk1.8.0_211
export PATH=$JAVA_HOME/bin:$PATH
root@yw-elk:/data/elk/jdk# source /etc/profile
root@yw-elk:/data/elk/jdk# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
2、解压二进制包
root@yw-elk:/data/elk# cd /data/elk/kafka/
root@yw-elk:/data/elk/kafka# tar xzvf kafka_2.11-1.0.0.tgz
3、创建相关数据目录
root@yw-elk:/data/elk/kafka# cd kafka_2.11-1.0.0/
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# mkdir kafka_data
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# mkdir zk_data
4、配置并启动Zookeeper
Kafka二进制包中已经集成Zookeeper了,Zookeeper是Kafka的注册中心,用于实现消费者与代理节点之间的路由和负载平衡等工作,生产者将消息写入到代理节点,由代理节点分发给消费者。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/zookeeper.properties
dataDir=/data/elk/kafka/kafka_2.11-1.0.0/zk_data
# zookeeper的数据目录。
clientPort=2181
# zookeeper监听端口。
maxClientCnxns=0
# 最大客户端并发连接数量。
### SASL ###
# 开启ZookeeperClient支持SASL认证
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
requireClientAuthScheme=sasl
jaasLoginRenew=3600000
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/zookeeper-server-start.sh -daemon /data/elk/kafka/kafka_2.11-1.0.0/config/zookeeper.properties
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 2181
tcp6 0 0 :::2181 :::* LISTEN 1086/java
5、配置Kafka服务端(Broker)
Broker,代理节点,即Kafka服务端。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/server.properties
############################# Server Basics #############################
broker.id=0
# BrokerID,用于Kafka集群中代理节点的全局唯一编号。
message.max.bytes=10000000
# 设置单个消息的最大值,默认为1M。
# delete.topic.enble=true
# 设置允许对Topic进行删除操作,否则无法删除Topic。只有开启此项的时候Topic才会被真正删除,否则Topic仅
# 只是被标记为删除而已。为了安全性考虑的结果。
# auto.create.topics.enable=true
# 设置当生产者要推送消息的Topic不存在时自动创建对应的Topic。默认为true。
### SASL ###
security.inter.broker.protocol=SASL_PLAINTEXT
# Broker之间通信所使用的的协议。
sasl.enabled.mechanisms=PLAIN
# 启用Kafka服务器简单安全认证机列表。这个列表可以包括一个可用的安全提供者的任意机置。只有GSSAPI(通用安全服务应用接口)是默认启用的。
sasl.mechanism.inter.broker.protocol=PLAIN
# 用于内部的broker通信的简单身份验证和安全层机置。默认为通用安全服务应用程序接口。
# authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
# 开启简单的ACL访问控制功能。
# allow.everyone.if.no.acl.found=true
# 在ACL中,如果列表中没找到任何ACL规则,表默认允许所有用户操作。
super.users=User:admin
# 设置Broker的超级管理用户为admin。
############################# Socket Server Settings #############################
listeners=SASL_PLAINTEXT://:9092
# 设置套接字监听器所使用的安全协议和端口。PLAINTEXT是Kafka默认使用的协议。这边将其修改为SASL_PLAINTEXT协议,为了增加基于SASL的身份认证功能。
advertised.listeners=SASL_PLAINTEXT://47.96.96.60:9092
# 设置将Kafka的地址通告给生产者和消费者,如果不设置该项,则默认使用listeners的值。
# 由于我这边是公网环境,想要生产者和消费者与Kafka正常通信,则需要设置该项为公网地址,这才可以正常工
# 作。
num.network.threads=3
# Broker接收网络请求所开启的线程数量。
num.io.threads=8
# Broker用于处理请求的线程数量,其中可能包括磁盘IO。
socket.send.buffer.bytes=102400
# 套接字发送数据的缓冲区大小,单位为字节。
socket.receive.buffer.bytes=102400
# 套接字接受数据的缓冲区大小,单位为字节。
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 套接字接受单个请求的最大大小(防止OOM)。
log.dirs=/data/elk/kafka/kafka_2.11-1.0.0/kafka_data
# Broker日志和数据存储目录路径。
num.partitions=1
# 每个Topic的默认日志分区数量,更多的分区将允许更多的并行度,这也将导致会产生更多的文件,但可以增加每个Topic的并发性能。默认为1
num.recovery.threads.per.data.dir=1
# 在启动和关闭Broker服务器时,每个数据目录(log.dirs)中日志恢复的线程数量。
############################# Internal Topic Settings #############################
# 设置内部元数据Topic组的副本因子数量"__consumer_offsets"和"__transaction_state"。
# 除了开发测试之外,建议设置>1的值,比如3。
# 建议有几个节点就设置为几个副本数量。
offsets.topic.replication.factor=1
# 每个Topic的偏移值记录都在"__consumer_offsets"这个Topic中存储,该项用于设
# 置"__consumer_offsets"这个Topic的副本数量。以增加可靠性。
transaction.state.log.replication.factor=1
# 存储事务状态日志的Topic"__transaction_state"的副本数量。
transaction.state.log.min.isr=1
# 覆盖事务状态日志Topic中的min.insync.replicas配置。
# "min.insync.replicas"用于保证事务写入认为成功的最小副本数量,如果写入操作不能满足该要求,则生产者会引发一个异常"NotEnoughReplicas或NotEnoughReplicasAfterAppend"。
############################# Log Retention Policy #############################
log.retention.hours=168
# 日志(消息)保留时间,单位为小时。
# log.retention.bytes=1073741824
# 一个基于日志(消息)大小的保留策略。每个Topic下每个分区保存数据的最大文件大小。
# 当log.retention.hours和log.retention.bytes都存在时,当满足任何一个策略时都会删除。
# 该项如果设置为-1,则表示不删除。
log.segment.bytes=1073741824
# 日志段文件的最大大小,当达到此大小的时候,将创建一个新的日志段,单位为字节。
log.retention.check.interval.ms=300000
# 日志保留检查间隔时间,单位ms。
############################# Zookeeper #############################
zookeeper.connect=127.0.0.0.1:2181
# zookeeper连接地址。
zookeeper.connection.timeout.ms=18000
# zookeeper连接超时时间。
############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0
# 设置所有成员都加入到消费者组中需要的延迟时间,以避免出现再平衡"rebalance"事件的发生。
6、配置生产者和消费者客户端
配置生产者和消费者客户端,使其支持SASL安全机制。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/producer.properties
### SASL ###
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/consumer.properties
### SASL ###
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
7、为Kafka添加用户和密码
注:在kafka_server_jaas.conf和kafka_client_jaas.conf配置文件中,"username"和"password"创建的用户密码用于Broker之间的SASL身份认证,而user_=""这个用户用户生产者和消费者客户端使用。
# 创建Kafka服务器所使用的的账号密码以用于基于用户密码的身份验证
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/kafka_server_jaas.conf
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="xxx"
user_admin="xxx";
};
# 创建生产者或消费者客户端登录所使用的用户密码文件,用于登录到Kafka服务器(broker)。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/kafka_client_jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="xxx";
};
# 修改启动脚本文件
# 将内容写入到文件的最顶部
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-server-start.sh
export KAFKA_OPTS="-Djava.security.auth.login.config=/data/elk/kafka/kafka_2.11-1.0.0/config/kafka_server_jaas.conf"
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-console-producer.sh
export KAFKA_OPTS="-Djava.security.auth.login.config=/data/elk/kafka/kafka_2.11-1.0.0/config/kafka_client_jaas.conf"
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-console-consumer.sh
export KAFKA_OPTS="-Djava.security.auth.login.config=/data/elk/kafka/kafka_2.11-1.0.0/config/kafka_client_jaas.conf"
8、开启Kafka JMX监控功能(可选的步骤)
创建JMX监控要使用的账号密码文件"jmxremote.password"和权限控制"jmxremote.access"文件:
- jmxremote.password 内容格式:
- jmxremote.access 内容格式: <readonly|readwrite>
注:这两个文件仅能使用600权限,否则服务无法启动。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/jmxremote.password
jmxuser xxx
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/jmxremote.access
jmxuser readonly
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# chmod 600 config/jmxremote.*
指定在的脚本文件中找到以下内容,添加并修改相关内容:
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-run-class.sh
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Djava.rmi.server.hostname="127.0.0.1" -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.password.file=/data/elk/kafka/kafka_2.11-1.0.0/config/jmxremote.password -Dcom.sun.management.jmxremote.access.file=/data/elk/kafka/kafka_2.11-1.0.0/config/jmxremote.access"
fi
# JMX port to use
if [ $JMX_PORT ]; then
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT"
fi
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-server-start.sh
export JMX_PORT="12345"
9、启动Kafka服务器(Broker)
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-server-start.sh -daemon /data/elk/kafka/kafka_2.11-1.0.0/config/server.properties
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 9092
tcp6 0 0 :::9092 :::* LISTEN 28738/java
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 12345
tcp6 0 0 :::12345 :::* LISTEN 24280/java
10、手动创建项目使用的Topic
这里无需手动建立Topic,Logstash会自动创建Topic。
创建Topic:
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --partitions 5 --replication-factor 1 --topic production-xxx
查看Topic列表:
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --list
__consumer_offsets
production-xxx
查看Topic状态信息:
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe --topic production-xxx
Topic:test-th PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test-th Partition: 0 Leader: 0 Replicas: 0 Isr: 0
5、Filebeat(采集日志)
Filebeart是Elastic家族中轻量级的基于文件的采集器,用于从多台主机上采集日志,并传送给Elasticsearch存储或Logstash过滤处理。
安装Filebeat以采集日志,并将其传送到Kafka消息队列中,由Logstash连接到Kafka获取日志消息结构化处理后将其存储到Elasticsearch。
示例日志内容:
这是JAVA程序产生的日志数据,其结构格式都是第一行通常都是以日期时间开头的,当发生异常时后续的无日期开头的行都将会属于上一行日期开头行的内容,这才是一条完整的JAVA日志。
所以这里我们使用Filebeat则需要配置多行日志合并为一条日志进行处理。
2018-12-03 02:15:28.049 c.t.f.w.common.stat.WebappStatUtil [INFO][WebappStatUtil.java:49][93926cbbdeca44f2b3f713b643df959a] - reqId=-8a26-1203021528-570,uri=/train/basic/station_info,code=0,duration=30,uid=-1,ip=139.214.244.179,stack=[TrainQueryService.getStationMap:0:4]
2018-12-03 18:07:36.183 c.t.f.w.c.f.ExceptionAndStatFilter [ERROR][ExceptionAndStatFilter.java:433][93926cbbdeca44f2b3f713b643df959a] - reqId=-8a26-1203180736-18, Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0
org.springframework.web.util.NestedServletException: Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]
1、解压二进制包
root@jxota:~# cd /opt/ota/yw/filebeat
root@jxota:/opt/ota/yw/filebeat# tar xzvf filebeat-7.16.0-linux-x86_64.tar.gz
root@jxota:/opt/ota/yw/filebeat# cd filebeat-7.16.0-linux-x86_64/
2、配置Filebeat
我这边是在测试环境下的一台主机上配置的,可以作为示例配置。
Filebeat应该在多台主机上运行,并所属不同的主机环境和项目。
root@jxota:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# vim filebeat.yml
# ============================== Filebeat inputs ===============================
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/xxx/*/*.log
### 添加字段
# 添加一些字段以识别项目和主机环境
fields:
hostenv: "production" # 主机环境
project: "xxx" # 所属项目
### 多行选项
# 多行选项,期望输出连续的多行日志,比如Java日志。
multiline.type: pattern
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
# 使用正则表达匹配行。
multiline.negate: true
# 定义行是否被否定,若被否定,则执行"multiline.match"。
multiline.match: after
# 设置将匹配行与上一行(before)合并为一个事件输出,还是将匹配行与下一行(after)合并为一个事件输出。
# ================================== Outputs ===================================
# ...
# ------------------------------ Kafka Output -------------------------------
output.kafka:
hosts: ["172.16.31.12:9092"]
# 指定Kafka服务器连接地址,我这边由于网络环境问题,所以使用Kafka服务器的公网主机IP地址。
username: "admin"
# 设置连接Kafka所使用的的用户名
password: "xxx"
# 设置连接Kafka所使用的的用户密码
topic: '%{[fields.hostenv]}-%{[fields.project]}'
# 设置主题名称
partition.round_robin:
group_events: 1
reachable_only: false
# 设置消息写入主题的分区策略:默认使用hash方法。
# random.group_events, 随机写入主题的任意一个分区,并设置写入分区时消息事件的数量,默认为1。
# round_robin.group_events,有序的轮询的写入主题分区,并设置写入分区时消息时间的数量,默认为1。
# hash.hash,通过哈希计算分区中的字段列表,将匹配的字段写入到同一个分区中,如果没有配置字段,则使用事件键值。
# - hash.random,如果无法计算哈希或键值,则随机分发事件。
# reachable_only: 默认分区都尝试向所有分区发布事件,如果一个分区的leader在这个beat下变得不可用,输出可能会阻塞,则开启该项表示允许将事件发送到可用分区。
required_acks: 1
# 设置Kafka代理要求的ACK可靠性级别:
# 0,无响应。
# 1,等待本地提交。
# -1,等待所有副本提交。
# 注:如果设置为0,则Kafka不会返回任何ACK。出现错误时,消息可能会自动丢失。
compression: gzip
# 设置输出压缩编解码器,默认为gzip。支持none、snappy、lz4和zip压缩方式。
compression_level: 4
# 设置压缩级别,默认为4。如果设置为0,则表示不压缩。
max_message_bytes: 10000000
# JSON编码消息最大允许大小。更大的信息将被删除。默认是1M。该值应该小于或等于Kafka代理服务器
# 的"message.max.bytes"。
3、添加Filebeat到系统服务
默认情况下Filebeat无法通过nohup这种方式让其在后台运行,所以需要将其添加到系统服务才可后台运行。
root@jxota:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# vim /lib/systemd/system/filebeat.service
[Unit]
Description=filebeat
Wants=network-online.target
After=network-online.target
[Service]
User=root
ExecStart=/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64/filebeat -c /opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64/filebeat.yml
Restart=always
[Install]
WantedBy=multi-user.target
root@jxota:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# systemctl daemon-reload
4、启动Filebeat
可以先使用"./filebeat -e -c filebeat.yml -d "publist""在前台启动,测试Filebeat(生产者)-> Kafka -> Logstash(消费方)的通信情况。
root@jxota:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# systemctl start filebeat
root@jxota:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# systemctl status filebeat
● filebeat.service - filebeat
Loaded: loaded (/lib/systemd/system/filebeat.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2021-12-16 15:54:47 CST; 4min 30s ago
Main PID: 10525 (filebeat)
CGroup: /system.slice/filebeat.service
└─10525 /opt/th/yw/filebeat-7.16.0-linux-x86_64/filebeat -c /opt/th/yw/filebeat-7.16.0-linux-x86_64/filebeat.yml
5、设置Filebeat开机自启
root@agent:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# systemctl enable filebeat
Synchronizing state of filebeat.service with SysV init with /lib/systemd/systemd-sysv-install...
Executing /lib/systemd/systemd-sysv-install enable filebeat
6. Logstash(处理日志)
Logstash用于读取从Kafka+Filebeat采集来的日志数据,结构化处理后存储到Elasticsearch。
示例日志内容:
2018-12-03 02:15:28.049 c.t.f.w.common.stat.WebappStatUtil [INFO][WebappStatUtil.java:49][93926cbbdeca44f2b3f713b643df959a] - reqId=-8a26-1203021528-570,uri=/train/basic/station_info,code=0,duration=30,uid=-1,ip=139.214.244.179,stack=[TrainQueryService.getStationMap:0:4]
2018-12-03 18:07:36.183 c.t.f.w.c.f.ExceptionAndStatFilter [ERROR][ExceptionAndStatFilter.java:433][93926cbbdeca44f2b3f713b643df959a] - reqId=-8a26-1203180736-18, Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0
org.springframework.web.util.NestedServletException: Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]
1、解压二进制包
root@yw-elk:~# cd /data/elk/logstash/
root@yw-elk:/data/elk/logstash# tar xzvf logstash-7.16.0-linux-x86_64.tar.gz
2、安装常用插件(可选的步骤)
查看已安装插件,如果插件没有安装则需要手动安装相关插件。
Logstash-7.16.0适用的Kafka插件版本是10.8.1。
注:由于默认的插件包地址下载较慢,需要修改为国内源。
root@yw-elk:/data/elk/logstash# cd logstash-7.16.0/
root@yw-elk:/data/elk/logstash/logstash-7.16.0# echo "54.235.82.130 artifacts.elastic.co" >> /etc/hosts
root@yw-elk:/data/elk/logstash/logstash-7.16.0# bin/logstash-plugin list --verbose
root@yw-elk:/data/elk/logstash/logstash-7.16.0# bin/logstash-plugin install <plugin_name>
3、调整JVM堆内存大小
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/jvm.options
-Xms4g
-Xmx4g
4、创建Kafka客户端认证文件
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/kafka_client_jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="xxx";
};
5、调试Logstash
创建用于调试的Logstash管道配置文件,并启动Logstash,查看控制台输出以调试并编写完整的Logstash管道配置。
我们期望将一些重要的关键的字段存入到Elasticsearch中!
由于从Filebeat传送过来的数据为JSON数据,所以需要将input中的编解码器设置为JSON。
调试并创建Logstash管道配置文件:
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/logstash.conf
# -- 输入
input {
kafka {
bootstrap_servers => "127.0.0.1:9092"
topics => ["production-xxx"]
consumer_threads => 1
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
jaas_path => "/data/elk/logstash/logstash-7.16.0/config/kafka_client_jaas.conf"
codec => "json"
}
}
# -- 处理
filter {
}
# -- 输出
output {
stdout { codec => rubydebug }
}
前台启动Logstash:
root@yw-elk:/data/elk/logstash/logstash-7.16.0# bin/logstash -f config/logstash.conf
未处理前的数据:
{
"ecs" => {
"version" => "1.12.0"
},
"@version" => "1",
"host" => {
"architecture" => "x86_64",
"mac" => [
[0] "00:16:3e:12:0c:77"
],
"containerized" => false,
"hostname" => "xxx",
"os" => {
"name" => "Ubuntu",
"kernel" => "4.4.0-184-generic",
"platform" => "ubuntu",
"type" => "linux",
"version" => "16.04.6 LTS (Xenial Xerus)",
"codename" => "xenial",
"family" => "debian"
},
"id" => "92b8629fdc1ea4d3c82bfcad5eeac938",
"ip" => [
[0] "172.17.0.16",
[1] "fe80::216:3eff:fe12:c77"
],
"name" => "xxx"
},
"message" => "2018-12-03 18:07:36.183 c.t.f.w.c.f.ExceptionAndStatFilter [ERROR][ExceptionAndStatFilter.java:433][93926cbbdeca44f2b3f713b643df959a] - reqId=-8a26-1203180736-18, Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0\norg.springframework.web.util.NestedServletException: Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0\n at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]\n at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]\n",
"log" => {
"file" => {
"path" => "/var/log/xxx/apache-tomcat-api/test.2021-10-12.log"
},
"flags" => [
[0] "multiline"
],
"offset" => 11557
},
"@timestamp" => 2021-12-13T09:55:42.278Z,
"fields" => {
"hostenv" => "production",
"project" => "xxx"
},
"agent" => {
"ephemeral_id" => "34bb5503-74c1-4885-9189-3ac0db6e8e2e",
"hostname" => "xxx",
"type" => "filebeat",
"id" => "8fda7277-3c33-4c05-8607-09b86bee8936",
"version" => "7.16.0",
"name" => "xxx"
},
"input" => {
"type" => "log"
}
}
6、使用Grok文本处理插件处理数据
使用Grok插件对"message"和"path"进行一些处理。
期望从"message"中得到以下字段:
- logDateTime,当前日志的时间戳
- logClassFilePath,类文件路径
- logLevel,日志级别
- logClassFileLine,类文件的第几行报出来的日志,用于问题定位
- logReqId,请求链ID
- logContent,日志内容,具体的描述信息
期望从"[log][file][path]"中获取到日志文件的名称作为索引的名称。 - logFileName,日志文件名称
自定义文本模式:可以使用Kibana中的开发工具中的GrokDebugger工具进行调试。
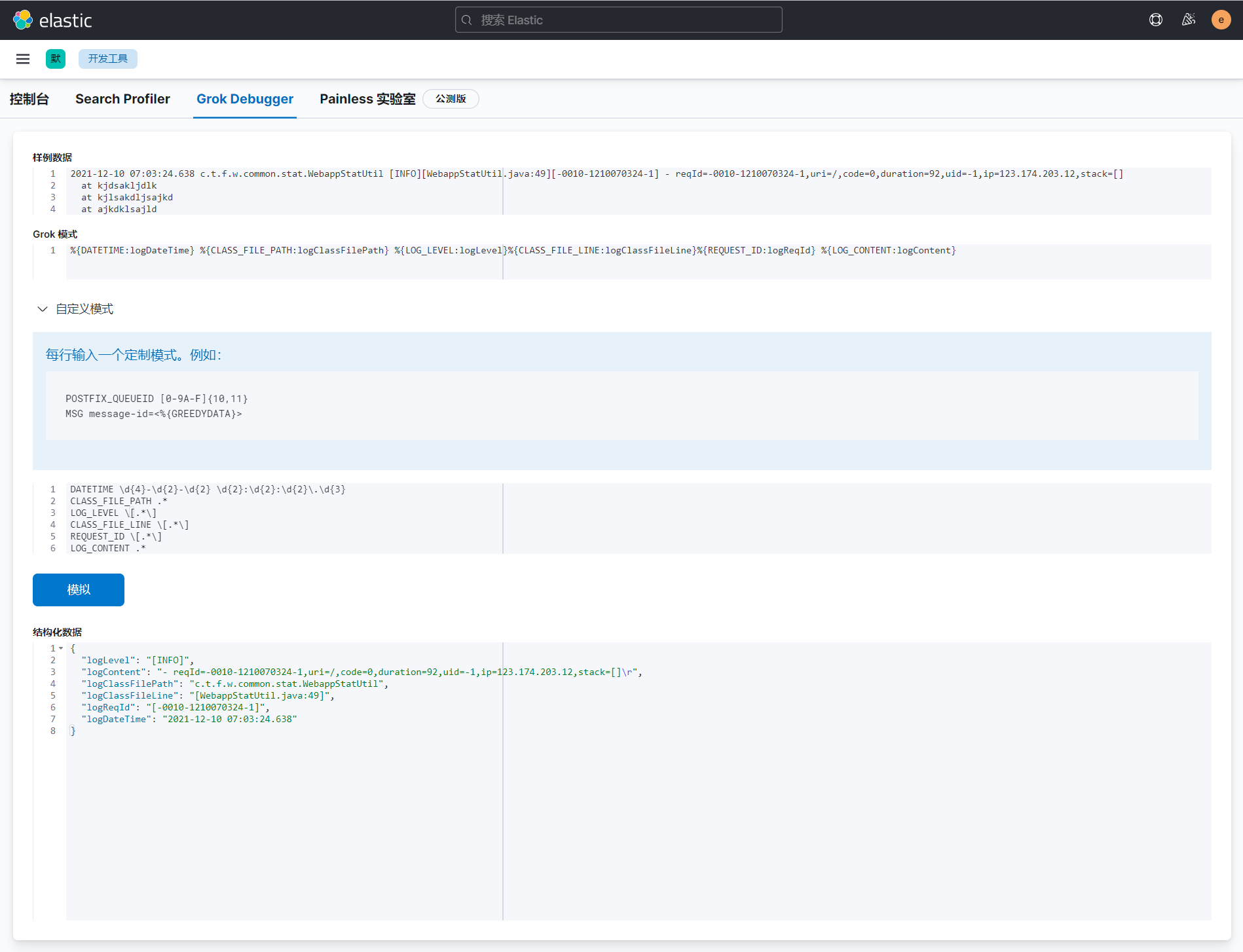
创建自定义文本模式文件:
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/patterns/patterns
# message
DATETIME \d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}
CLASS_FILE_PATH .*
LOG_LEVEL \[.*\]
CLASS_FILE_LINE \[.*\]
REQUEST_ID \[.*\]
LOG_CONTENT .*
Logstash管道配置:
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/logstash.conf
# -- 输入
input {
kafka {
bootstrap_servers => "127.0.0.1:9092"
topics => ["production-xxx"]
consumer_threads => 1
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
jaas_path => "/data/elk/logstash/logstash-7.16.0/config/kafka_client_jaas.conf"
codec => "json"
}
}
# -- 处理
filter {
# 使用Grok插件处理
# 从"message"中提取:
# - logDateTime,当前日志的时间戳
# - logClassFilePath,类文件路径
# - logLevel,日志级别
# - logClassFileLine,类文件的第几行报出来的日志,用于问题定位
# - logReqId,请求链ID
grok {
patterns_dir => ["/data/elk/logstash/logstash-7.16.0/config/patterns"]
match => {
"message" => "%{DATETIME:logDateTime} %{CLASS_FILE_PATH:logClassFilePath} %{LOG_LEVEL:logLevel}%{CLASS_FILE_LINE:logClassFileLine}%{REQUEST_ID:logReqId} %{LOG_CONTENT:logContent}"
}
}
# 使用Mutate插件处理
# 从"[log][file][path]"中提取:
# - logFileName,日志文件名称
# 并删除一些不重要的字段"logContent"
mutate {
split => ["[log][file][path]", "/"]
add_field => { "logFileName" => "%{[log][file][path][-1]}" }
remove_field => ["logContent"]
}
mutate {
join => ["[log][file][path]", "/"]
}
# 使用Mutate插件处理
# 从"logDateTime"中提取:
# - logDate,日志记录中的日期
mutate {
split => ["logDateTime", " "]
add_field => { "logDate" => "%{[logDateTime][0]}" }
}
mutate {
join => ["logDateTime", " "]
}
# 使用Date插件处理
# 使用日志的时间作为记录的时间戳"@timestamp",保证日志时序
date {
match => ["logDateTime", "ISO8601"]
target => "@timestamp"
}
}
# -- 输出
output {
stdout { codec => rubydebug }
}
结构化处理后结果:
{
"logReqId" => "[93926cbbdeca44f2b3f713b643df959a]",
"agent" => {
"name" => "xxx",
"hostname" => "xxx",
"ephemeral_id" => "34bb5503-74c1-4885-9189-3ac0db6e8e2e",
"version" => "7.16.0",
"type" => "filebeat",
"id" => "8fda7277-3c33-4c05-8607-09b86bee8936"
},
"ecs" => {
"version" => "1.12.0"
},
"@timestamp" => 2021-12-13T09:51:02.255Z,
"fields" => {
"project" => "xxx",
"hostenv" => "production"
},
"log" => {
"flags" => [
[0] "multiline"
],
"file" => {
"path" => "/var/log/xxx/apache-tomcat-api/test.2021-10-12.log"
},
"offset" => 10784
},
"logDateTime" => "2018-12-03 18:07:36.183",
"logDate" => "2018-12-03",
"logLevel" => "[ERROR]",
"input" => {
"type" => "log"
},
"host" => {
"name" => "xxx",
"ip" => [
[0] "172.17.0.16",
[1] "fe80::216:3eff:fe12:c77"
],
"mac" => [
[0] "00:16:3e:12:0c:77"
],
"hostname" => "xxx",
"containerized" => false,
"os" => {
"name" => "Ubuntu",
"kernel" => "4.4.0-184-generic",
"codename" => "xenial",
"platform" => "ubuntu",
"family" => "debian",
"version" => "16.04.6 LTS (Xenial Xerus)",
"type" => "linux"
},
"architecture" => "x86_64",
"id" => "92b8629fdc1ea4d3c82bfcad5eeac938"
},
"message" => "2018-12-03 18:07:36.183 c.t.f.w.c.f.ExceptionAndStatFilter [ERROR][ExceptionAndStatFilter.java:433][93926cbbdeca44f2b3f713b643df959a] - reqId=-8a26-1203180736-18, Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0\norg.springframework.web.util.NestedServletException: Request processing failed; nested exception is com.alibaba.fastjson.JSONException: syntax error, expect {, actual false, pos 0\n at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]\n at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:981) ~[spring-webmvc-4.2.4.RELEASE.jar:4.2.4.RELEASE]\n",
"@version" => "1",
"logClassFilePath" => "c.t.f.w.c.f.ExceptionAndStatFilter",
"logFileName" => "test.2021-10-12.log",
"logClassFileLine" => "[ExceptionAndStatFilter.java:433]"
}
7、将处理完成后的结果存储到Elasticsearch中(最后完整的管道配置)
期望将日志数据写入到项目关联的的索引中"%{[fields][hostenv]}-%{[fields][project]}"。
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/logstash.conf
# -- 输入
input {
kafka {
bootstrap_servers => "127.0.0.1:9092"
topics => ["production-xxx"]
consumer_threads => 5
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
jaas_path => "/data/elk/logstash/logstash-7.16.0/config/kafka_client_jaas.conf"
codec => "json"
}
}
# -- 处理
filter {
# 使用Grok插件处理
# 从"message"中提取:
# - logDateTime,当前日志的时间戳
# - logClassFilePath,类文件路径
# - logLevel,日志级别
# - logClassFileLine,类文件的第几行报出来的日志,用于问题定位
# - logReqId,请求链ID
grok {
patterns_dir => ["/data/elk/logstash/logstash-7.16.0/config/patterns"]
match => {
"message" => "%{DATETIME:logDateTime} %{CLASS_FILE_PATH:logClassFilePath} %{LOG_LEVEL:logLevel}%{CLASS_FILE_LINE:logClassFileLine}%{REQUEST_ID:logReqId} %{LOG_CONTENT:logContent}"
}
}
# 使用Mutate插件处理
# 从"[log][file][path]"中提取:
# - logFileName,日志文件名称
# 并删除一些不重要的字段"logContent"
mutate {
split => ["[log][file][path]", "/"]
add_field => { "logFileName" => "%{[log][file][path][-1]}" }
remove_field => ["logContent"]
}
mutate {
join => ["[log][file][path]", "/"]
}
# 使用Mutate插件处理
# 从"logDateTime"中提取:
# - logDate,日志记录中的日期
mutate {
split => ["logDateTime", " "]
add_field => { "logDate" => "%{[logDateTime][0]}" }
}
mutate {
join => ["logDateTime", " "]
}
# 使用Date插件处理
# 使用日志的时间作为记录的时间戳"@timestamp",保证日志时序
date {
match => ["logDateTime", "ISO8601"]
target => "@timestamp"
}
}
# -- 输出
output {
# stdout { codec => rubydebug }
# 如果"logDate"中的值不是日期,则将其存到指定的索引里面
if [logDate] =~ "^\d{4}-\d{2}-\d{2}" {
elasticsearch {
hosts => "127.0.0.1:9200"
user => "elastic"
password => "lgWZDNRmTaXwkO4s"
manage_template => false
index => "%{[fields][hostenv]}-%{[fields][project]}-%{[logDate]}"
document_type => "%{[@metadata][type]}"
}
} else {
elasticsearch {
hosts => "127.0.0.1:9200"
user => "elastic"
password => "xxx"
manage_template => false
index => "%{[fields][hostenv]}-%{[fields][project]}-unkown"
document_type => "%{[@metadata][type]}"
}
}
}
8、设置服务配置
修改Logstash的API监听端口配置,避免默认的端口范围随机一个端口,端口可用于监控服务是否工作正常。
root@yw-elk:/data/elk/logstash/logstash-7.16.0# vim config/logstash.yml
api.http.port: 9600
9、启动Logstash
root@yw-elk:/data/elk/logstash/logstash-7.16.0# nohup bin/logstash -f config/logstash.conf --config.reload.automatic &
root@yw-elk:/data/elk/logstash/logstash-7.16.0# netstat -lnupt |grep 9600
tcp6 0 0 127.0.0.1:9600 :::* LISTEN 27192/java
7、搭建完成
1、查看Elasticsearch
可以看到Elasticsearch中已经自动创建了索引,并且日志已经存进去了。
root@yw-elk:~# curl -X GET -u elastic:xxxx http://127.0.0.1:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open production-xxx-2021-12-12 NBrMgp9wS3-K_WsP9iUh-g 1 1 12 0 67.2kb 67.2kb
...
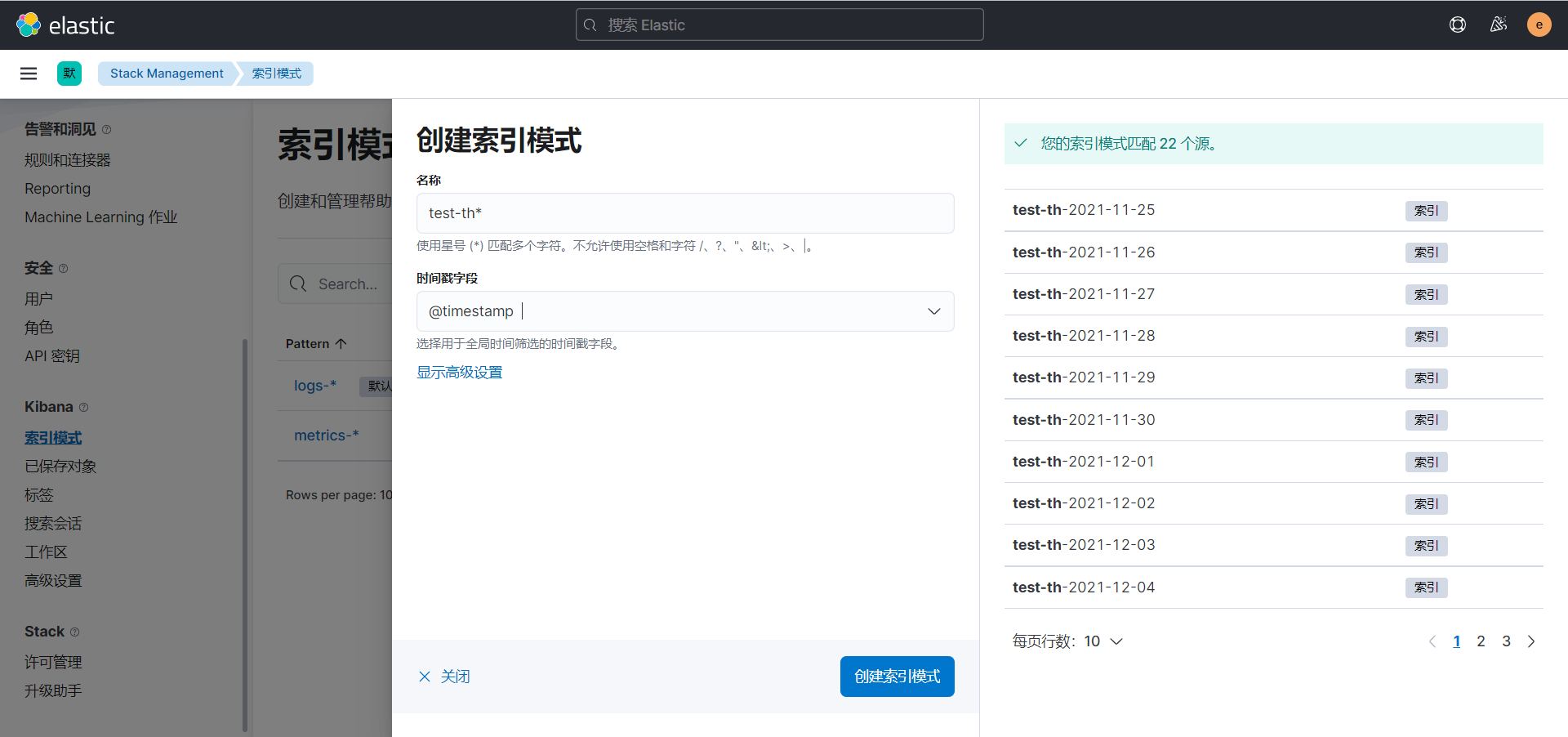
2、在Kibana上创建索引模式检索日志
索引模式是通过通配符表达式关联的多个索引的集合。
操作步骤:Stack Management -> 索引模式 -> 创建索引模式
附录-官方文档
参考官方文档:https://www.elastic.co/guide/index.html
附录-工作组件关系图
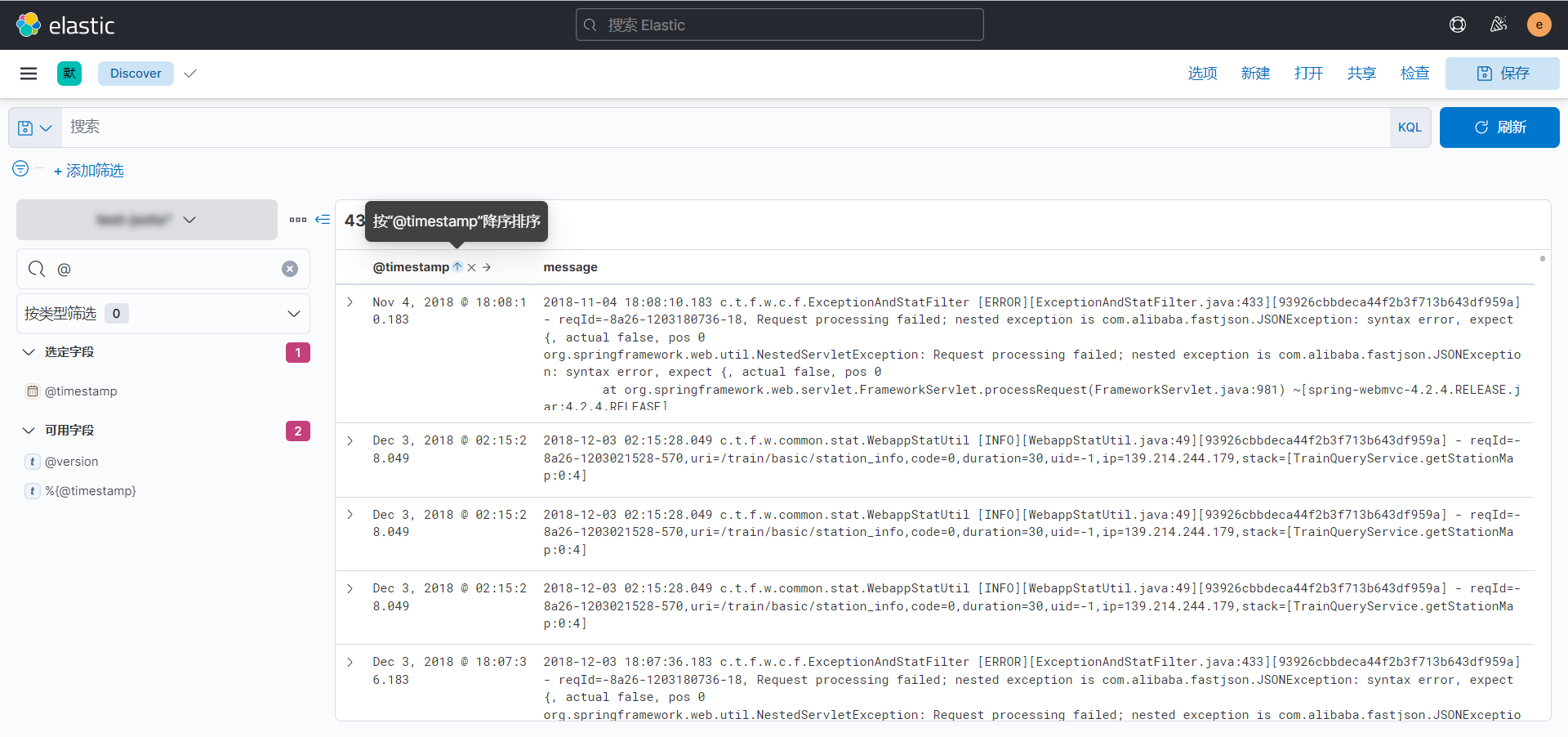
附录-Kibana排序查看日志(使用Logstash修改@timestamp)
由于多个应用的日志异步向ES中写入,对于写入的记录是无序的,Kibana仅提供一个@timestamp可操作排序。
由于默认记录的时间戳是使用的当前系统时间,对采用系统时间戳记录进行排序意义不大。
这个时候如果想要使用@timestamp排序后查看得到的日志是有序的话,则只需要截取日志中的时间戳将其转换为内置字段@timestamp所使用的即可,即日志时间=@timestamp。
Logstash管道配置如下:
# -- 输入
input {
kafka {
bootstrap_servers => "127.0.0.1:9092"
topics => ["production-xxx"]
consumer_threads => 1
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
jaas_path => "/data/elk/logstash/logstash-7.16.0/config/kafka_client_jaas.conf"
codec => "json"
}
}
# -- 处理
filter {
# 使用Grok插件处理
# 从"message"中提取:
# - logDateTime,当前日志的时间戳
# - logClassFilePath,类文件路径
# - logLevel,日志级别
# - logClassFileLine,类文件的第几行报出来的日志,用于问题定位
# - logReqId,请求链ID
grok {
patterns_dir => ["/data/elk/logstash/logstash-7.16.0/config/patterns"]
match => {
"message" => "%{DATETIME:logDateTime} %{CLASS_FILE_PATH:logClassFilePath} %{LOG_LEVEL:logLevel}%{CLASS_FILE_LINE:logClassFileLine}%{REQUEST_ID:logReqId} %{LOG_CONTENT:logContent}"
}
}
# 使用Mutate插件处理
# 从"[log][file][path]"中提取:
# - logFileName,日志文件名称
# 并删除一些不重要的字段
mutate {
split => ["[log][file][path]", "/"]
add_field => { "logFileName" => "%{[log][file][path][-1]}" }
remove_field => ["logContent"]
}
mutate {
join => ["[log][file][path]", "/"]
}
# 使用Date插件处理
# 使用日志的时间作为记录的时间戳"@timestamp",保证日志时序
date {
match => ["logDateTime", "ISO8601"]
target => "@timestamp"
}
}
# -- 输出
output {
elasticsearch {
hosts => "127.0.0.1:9200"
user => "elastic"
password => "xxx"
manage_template => false
index => "%{[fields][hostenv]}-%{[fields][project]}-%{logFileName}"
document_type => "%{[@metadata][type]}"
}
}
Kibana中排序操作:
附录-Filebeat重新收集之前的日志
在Filebeat的工作目录下的"data"目录中记录了filebeat收集日志的偏移值记录。
只需要清除"data"目录下的所有文件,重启Filebeat即可。
root@agent:/opt/ota/yw/filebeat/filebeat-7.16.0-linux-x86_64# rm -rf data/*
附录-Kafka如何合理的设置Topic的分区数量
分区越多,则表示数据库目录下会存放更多的目录和文件,并行的分区数也代表着在系统中会打开更多的句柄数量。
在生产者端的配置中有个batch.size大小,默认为16KB,它会为每个分区缓冲消息,当消息满了以后再打包批量发送到Borker,分区数量越多也意味着会存在更多的缓冲区,即占用更多的内存大小。
在消费者端会创建对应分区数量的线程去消费消息,则表示并行的线程,线程之间上下文切换也会造成系统资源的开销。
所以合理的设置Topic的分区数量是非常重要的。
Kafka默认集成了性能测试的工具"kafka-producer-perf-test.sh"和"kafka-consumer-perf-test.sh"可以测试Topic的每秒可处理消息的吞吐量、延迟。可以根据测试结果合理的创建分区数量。
示例:
假定一条日志消息的数据大小为2000字节,业务系统一个节点每秒产生1000条日志,则你期望在1秒钟就可以存储到Kafka中,则期望的吞吐量是20001000节点数量=目标吞吐量,我这边有10个节点,则我期望的目标吞吐量为20MB/s。
下面我创建了一个分区的Topic,并使用生产端和消费端性能压测工具进行压力测试。
可以看到经过以下测试的结果,一个分区的Topic的处理消息的吞吐量是2.8MB/s,则分区数量=目标吞吐量/性能压测的吞吐量。
1、创建测试用的Topic
root@yw-elk:~# cd /data/elk/kafka/kafka_2.11-1.0.0/
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --partitions 1 --replication-factor 1 --topic test
Created topic "test".
2、使用生产者性能测试工具"kafka-producer-perf-test.sh"进行压测
注:由于这边使用SASL认证,所以需要修改下脚本。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-producer-perf-test.sh
export KAFKA_OPTS="-Djava.security.auth.login.config=/data/elk/kafka/kafka_2.11-1.0.0/config/kafka_client_jaas.conf"
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-producer-perf-test.sh --producer.config config/producer.properties --topic test --num-records 10000 --throughput -1 --print-metrics --record-size 2000 --producer-props acks=1
# 选项:
# --topic TOPIC 指定要生产消息所使用的的Topic
# --num-records NUM-RECORDS 要生产的消息的总数量
# --throughput THROUGHPUT 设置最大消息吞吐量:总消息数量/秒。-1表示不设置。
# --producer.config CONFIG-FILE 指定生产者配置文件
# --producer-props 手动指定配置,acks=1表示不允许丢消息
# --print-metrics 在测试结束后打印指标
# --record-size RECORD-SIZE 每条消息的大小,单位为字节
7713 records sent, 1542.3 records/sec (2.94 MB/sec), 2059.4 ms avg latency, 4814.0 max latency.
10000 records sent, 1489.646954 records/sec (2.84 MB/sec), 2882.56 ms avg latency, 6501.00 ms max latency, 2814 ms 50th, 6132 ms 95th, 6430 ms 99th, 6497 ms 99.9th.
3、使用消费端性能测试工具"kafka-producer-perf-test.sh"进行压测
注:由于这边使用SASL认证,所以需要修改下脚本。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-consumer-perf-test.sh
export KAFKA_OPTS="-Djava.security.auth.login.config=/data/elk/kafka/kafka_2.11-1.0.0/config/kafka_client_jaas.conf"
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-consumer-perf-test.sh --broker-list 127.0.0.1:9092 --consumer.config config/consumer.properties --threads 1 --topic test --messages 10000
# 选项:
# --broker-list Kafka服务器列表
# --consumer.config 消费者配置文件
# --threads 线程数量
# --topic 测试使用的主题
# --messages 要处理的消息总数
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2021-12-15 10:31:43:790, 2021-12-15 10:31:49:541, 16.5634, 2.8801, 10484, 1822.9873, 34, 5717, 2.8972, 1833.8289
附录-开启Kafka JMX监控功能
1、创建JMX监控要使用的账号密码文件
创建JMX监控要使用的账号密码文件"jmxremote.password"和权限控制"jmxremote.access"文件:
- jmxremote.password 内容格式:
- jmxremote.access 内容格式: <readonly|readwrite>
注:这两个文件仅能使用600权限,否则服务无法启动。
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# cd /data/elk/kafka/kafka_2.11-1.0.0/
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/jmxremote.password
jmxuser xxx
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim config/jmxremote.access
jmxuser readonly
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# chmod 600 config/jmxremote.*
2、修改相关脚本
在指定的脚本文件中找到以下内容,添加并修改相关内容。
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-run-class.sh
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Djava.rmi.server.hostname="127.0.0.1" -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.password.file=/data/elk/kafka/kafka_2.11-1.0.0/config/jmxremote.password -Dcom.sun.management.jmxremote.access.file=/data/elk/kafka/kafka_2.11-1.0.0/config/jmxremote.access"
fi
# JMX port to use
if [ $JMX_PORT ]; then
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT"
fi
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# vim bin/kafka-server-start.sh
export JMX_PORT="12345"
3、重启Kafka
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 9092
tcp6 0 0 :::9092 :::* LISTEN 12324/java
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# kill -15 12324
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/kafka-server-start.sh -daemon /data/elk/kafka/kafka_2.11-1.0.0/config/server.properties
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 9092
tcp6 0 0 :::9092 :::* LISTEN 24280/java
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 12345
tcp6 0 0 :::12345 :::* LISTEN 24280/java
附录-Kafka Manger(Kafka可视化监控管理工具)
Kafka Manger是一个由雅虎开源的Kafka可视化监控管理工具,由于商标的问题,与Apache产生了商业纠纷,现今阶段已经更名为CMAK了。
1、安装JDK11
CMAK-3.0.0.5需要JDK11的支持。
root@yw-elk:~# cd /data/elk/jdk/
root@yw-elk:/data/elk/jdk# tar xzvf jdk-11.0.13_linux-x64_bin.tar.gz
2、解压CMAK二进制包
root@yw-elk:/data/elk/jdk/jdk-11.0.13# cd /data/elk/kafka/
root@yw-elk:/data/elk/kafka# unzip cmak-3.0.0.5.zip
3、配置CMAK
root@yw-elk:/data/elk/kafka# cd cmak-3.0.0.5
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# vim conf/application.conf
kafka-manager.zkhosts="127.0.0.1:2181"
# kafka-manager连接zookeeper的连接地址。
cmak.zkhosts="127.0.0.1:2181"
# cmak连接zookeeper的连接地址。
basicAuthentication.enabled=true
# 开启基本认证功能。访问CMAK时需要输入账号密码。
basicAuthentication.username="admin"
# 设置基本认证时要使用的账号
basicAuthentication.password="xxx"
# 设置基本认证时要使用的账号密码
4、配置消费者属性
开启消费者支持SASL认证。
Kafka没有配置SASL认证,可以不用执行此步骤。
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# vim conf/consumer.properties
### SASL ###
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
5、启动CMAK服务
启动CMAK服务可能需要会儿时间,请耐心等待。
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# nohup bin/cmak -Dconfig.file=/data/elk/kafka/cmak-3.0.0.5/conf/application.conf -Dhttp.port=8080 -java-home /data/elk/jdk/jdk-11.0.13 &
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# netstat -lnupt |grep 8080
tcp6 0 0 :::8080 :::* LISTEN 22868/java
6、配置Nginx反向代理
配置完成后,需要配置域名解析。
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# vim /etc/nginx/conf.d/elk.conf
# kafka-manager
server {
listen 80;
server_name kafka-manager.xxx.net;
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# nginx -s reload
7、访问到CMAK
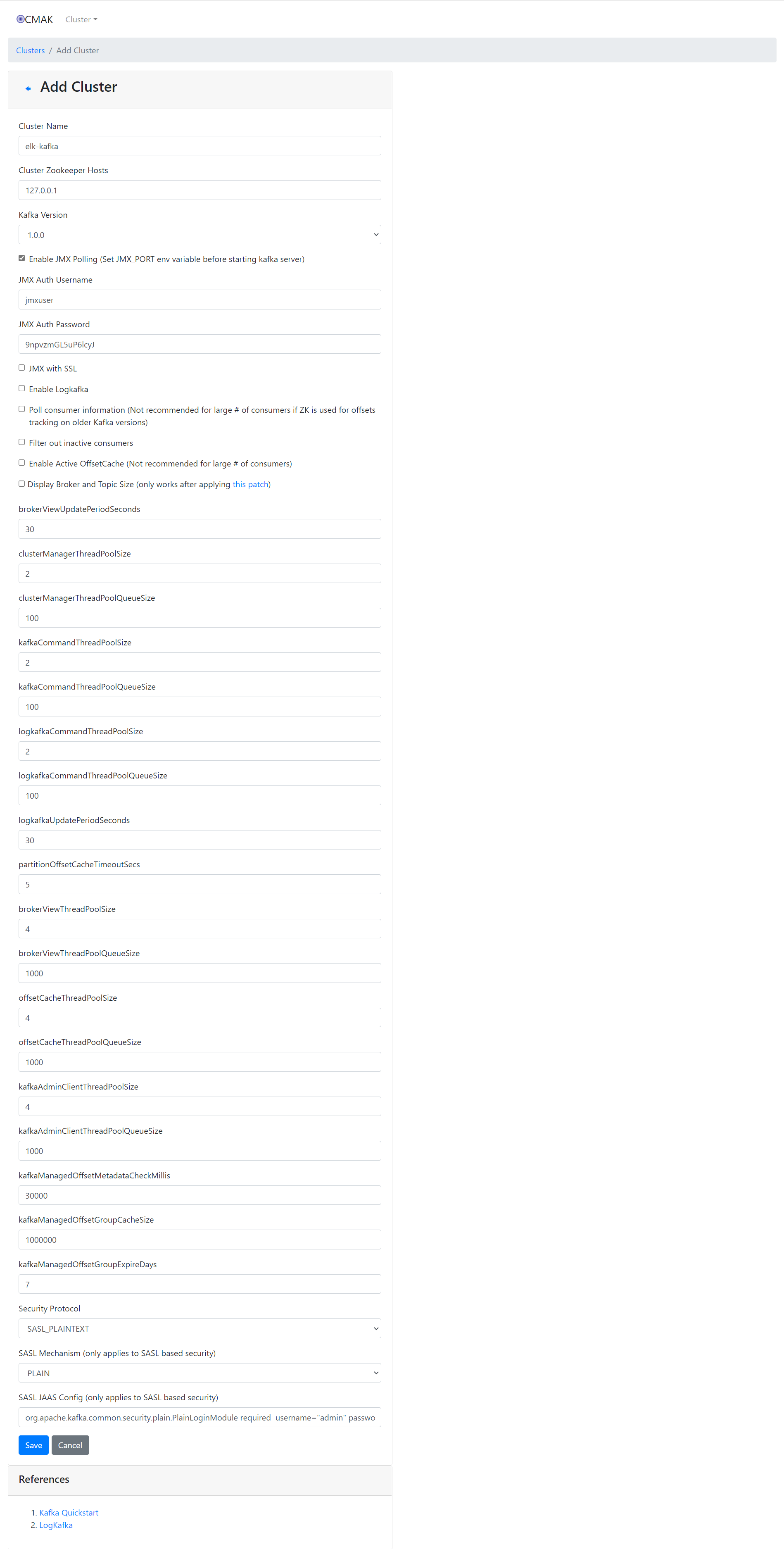
8、添加Kafka集群
这里一定要注意,填写SASL配置的时候必须填写内容,而不是指定配置文件
9、解决在CMAK添加Kafka集群的时候报以下错误问题
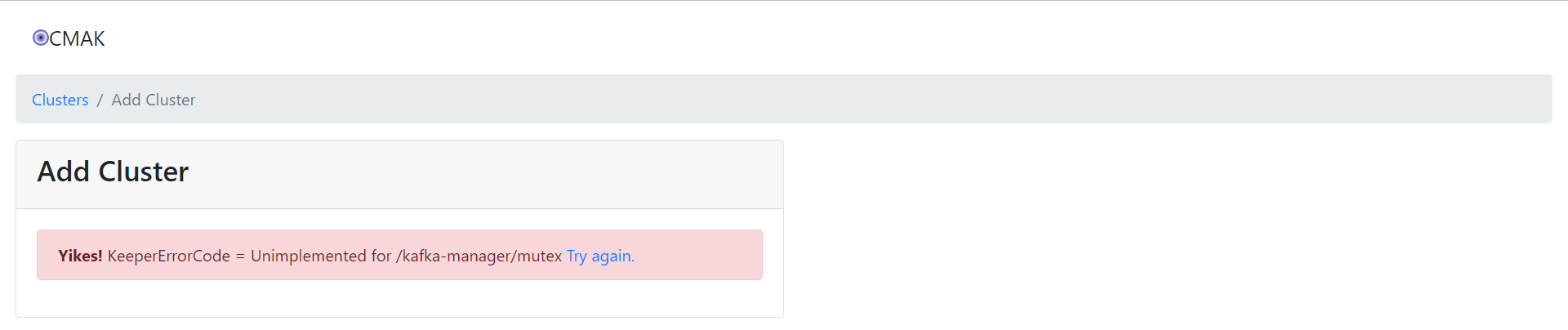
root@yw-elk:/data/elk/kafka/cmak-3.0.0.5# cd /data/elk/kafka/kafka_2.11-1.0.0/
root@yw-elk:/data/elk/kafka/kafka_2.11-1.0.0# bin/zookeeper-shell.sh 127.0.0.1:2181
Connecting to 127.0.0.1:2181
Welcome to ZooKeeper!
] create /kafka-manager/mutex ""
] create /kafka-manager/mutex/locks ""
] create /kafka-manager/mutex/leases ""
] ls /
[cluster, controller, brokers, zookeeper, kafka-acl, kafka-acl-changes, admin, isr_change_notification, log_dir_event_notification, controller_epoch, kafka-manager, consumers, latest_producer_id_block, config]
] quit
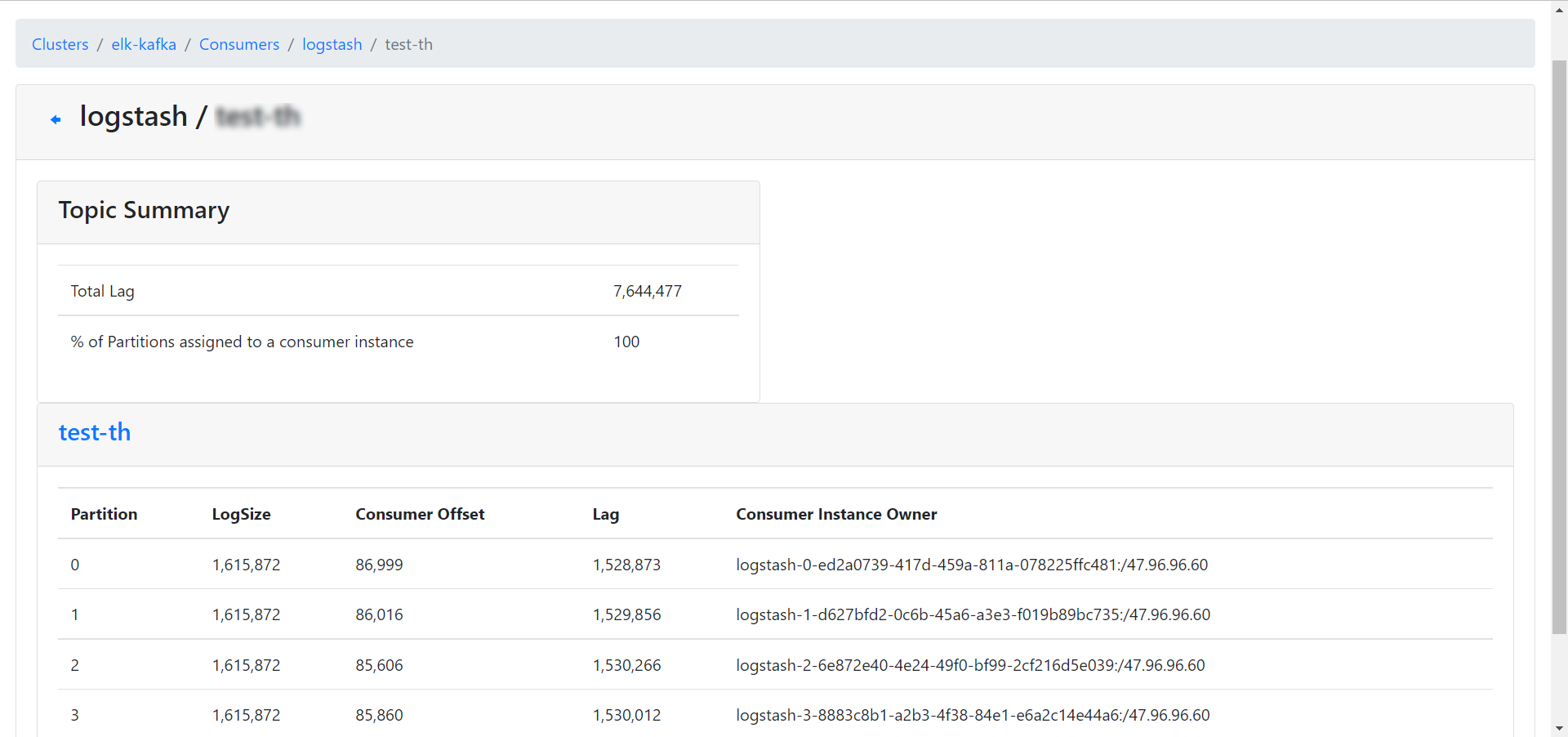
10、查看消费组中的消息堆积情况
- LogSize,当前队列大小偏移值。
- Consumer Offset,当前消费消息的偏移值。
- Lag,滞后的消息数量。
搭建ELK日志平台(单机)的更多相关文章
- elk日志平台搭建小记
最近抽出点时间,搭建了新版本的elk日志平台 elastaicsearch 和logstash,kibana和filebeat都是5.6版本的 中间使用redis做缓存,版本为3.2 使用的系统为ce ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- Springboot项目使用aop切面保存详细日志到ELK日志平台
上一篇讲过了将Springboot项目中logback日志插入到ELK日志平台,它只是个示例.这一篇来看一下实际使用中,我们应该怎样通过aop切面,拦截所有请求日志插入到ELK日志系统.同时,由于往往 ...
- ELK 日志平台构建
elastic中文社区 https://elasticsearch.cn/ 完整参考 ELK实时日志分析平台环境部署--完整记录 https://www.cnblogs.com/kevingrace/ ...
- Springboot项目搭配ELK日志平台
上一篇讲过了elasticsearch和kibana的可视化组合查询,这一篇就来看看大名鼎鼎的ELK日志平台是如何搞定的. elasticsearch负责数据的存储和检索,kibana提供图形界面便于 ...
- 基于Kafka+ELK搭建海量日志平台
早在传统的单体应用时代,查看日志大都通过SSH客户端登服务器去看,使用较多的命令就是 less 或者 tail.如果服务部署了好几台,就要分别登录到这几台机器上看,等到了分布式和微服务架构流行时代,一 ...
- 搭建ELK日志分析平台
(上)—— ELK介绍及搭建 Elasticsearch 分布式集群 http://blog.51cto.com/zero01/2079879 (下)—— 搭建kibana和logstash服务器 h ...
- 从头开始搭建分布式日志平台的docker环境
上篇(spring mvc+ELK从头开始搭建日志平台)分享了从头开始搭建基于spring mvc+redis+logback+logstash+elasticsearch+kibana的分布式日志平 ...
- 亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统.日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」 废话不多说,老司机们座好了, ...
随机推荐
- 【HTML】标签
HTML标签 2020-09-08 15:37:37 by冲冲 1. 标签 <!DOCTYPE html> <html> <head> <meta cha ...
- ThinkPad笔记本外放没声音解决办法(不是驱动的原因)
本人的本子是T480,自从装完Ubuntu系统之后W10系统就没有外放声音了,卸载Ubuntu之后还是没有声音,重装声卡驱动.重装系统之后依然无效. 我的解决办法是升级主板Bois,具体如下: 进入官 ...
- DirectX12 3D 游戏开发与实战第八章内容(上)
8.光照 学习目标 对光照和材质的交互有基本的了解 了解局部光照和全局光照的区别 探究如何用数学来描述位于物体表面上某一点的"朝向",以此来确定入射光照射到表面的角度 学习如何正确 ...
- git添加新账号
1,在linux上添加账号 useradd test passwd test usermod -G gitgroup test 将test账号的组改为和git一样的组gitgroup git所在 ...
- PHP socket Workerman实用的php框架
PHP socket Workerman是一款开源高性能异步PHP socket即时通讯框架. 非常好用的一款框架,可以支持在线聊天,长连接等 用法 官方 https://www.workerman. ...
- APP工程师接入Telink Mesh流程 -3
加密是为了使网络更加的安全.健壮,若由于login.加密等流程 严重影响了 开发进程,也可以通过 修改SDK 固件 将login.加密 环节取消 1.发送数据.接受数据加密,解密去掉 mesh_sec ...
- 【Linux】CentOS下升级Python和Pip版本全自动化py脚本
[Linux]CentOS下升级Python和Pip版本全自动化py脚本 CentOS7.6自带py2.7和py3.6 想要安装其它版本的话就要自己重新下载和编译py其它版本并且配置环境,主要是软链接 ...
- 生产调优3 HDFS-多目录配置
目录 HDFS-多目录配置 NameNode多目录配置 1.修改hdfs-site.xml 2.格式化NameNode DataNode多目录配置(重要) 1.修改hdfs-site.xml 2.测试 ...
- A Child's History of England.23
King William, fearing he might lose his conquest, came back, and tried to pacify the London people b ...
- day16 循环导入、模块搜索路径、软件开发、包的使用
day16 循环导入.模块搜索路径.软件开发.包的使用 1.循环导入 循环导入:循环导入问题指的是在一个模块加载/导入的过程中导入另外一个模块,而在另外一个模块中又返回来导入第一个模块中的名字,由于第 ...