zset如何解决内部链表查找效率低下
zset作为有序集合,内部基于跳表或者说索引的方式实现了数据的快速查找。解决了链表查询效率低下的痛点
前言
- 紧接前文我们学习了
Redis中Hash结构。在里面我们梳理了字典这个重要的内部结构并分析了hash结构rehash的流程从而解释了为什么redis单线程还是那么快 - 本章节我们将视角下推,继续学习
Redis五大天王中的zset数据结构 ;zset是有序不重复集合其内部元素唯一且是有序的,他的排序标准是根据其内部score维度进行排序的。
zset结构
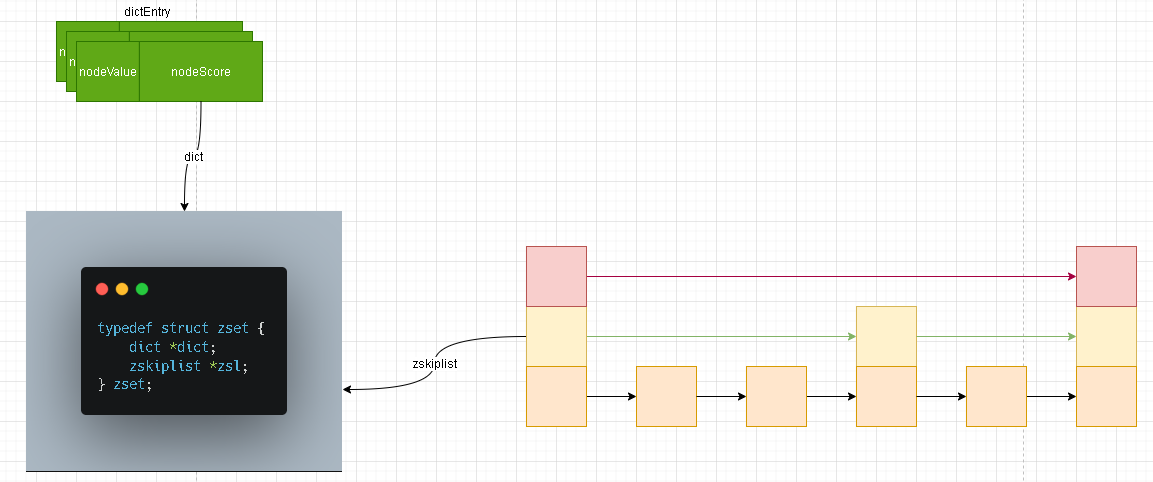
基本单元
- 关于zset结构很简单,一个是我们之前学习的字典结构(简单理解成Hash结构),另外一个是跳跃表结构 ; 关于字典我们上一章节已经详细解说了其内部的构造及其如何进行数据扩容等操作!剩下的且符合今天我们学习主旨的自然就是这个熟悉又陌生的
zskiplist。 - 我们根据上面zset的结构图也能够看出来,zskiplist实际上就是一个链表。
zskiplist
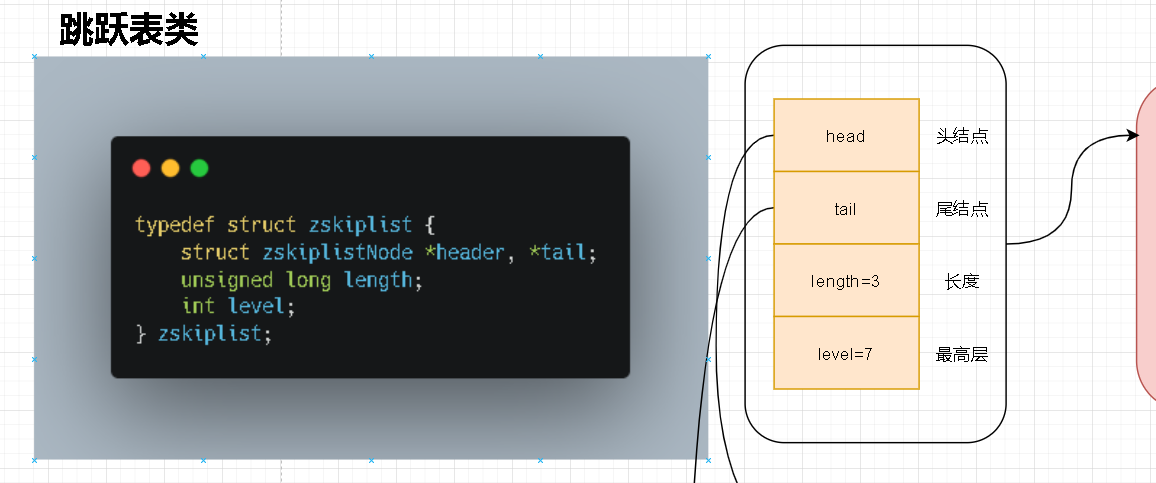
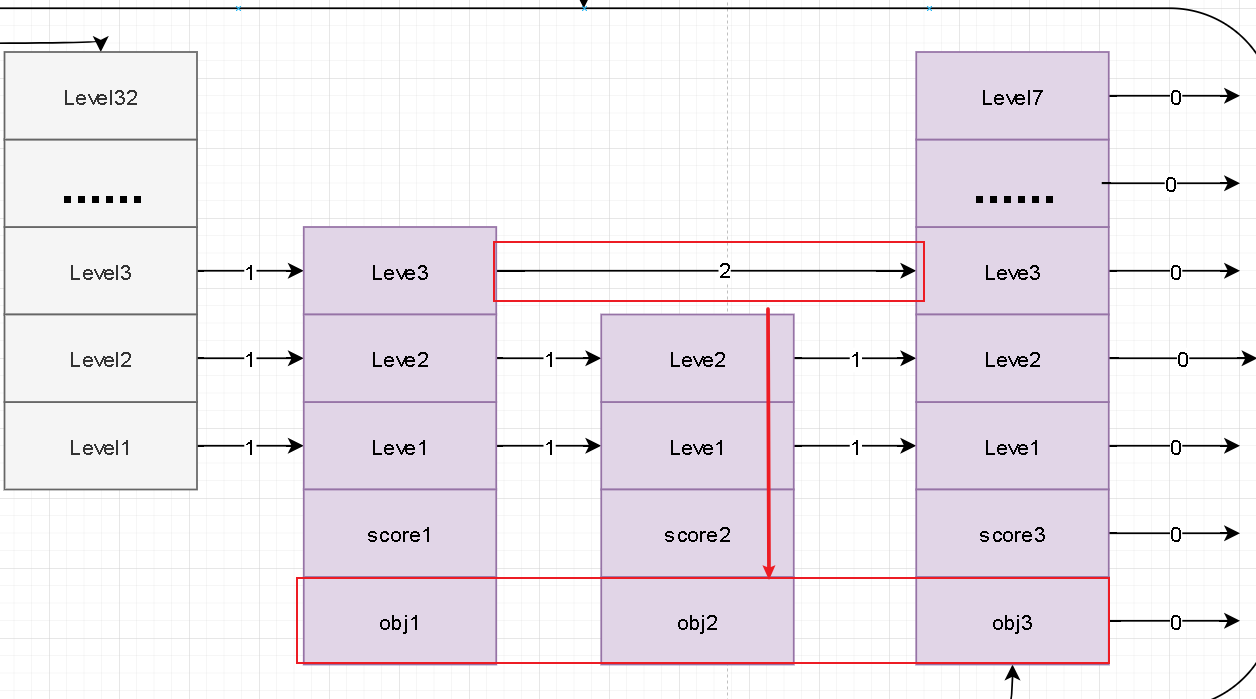
- 我们查看源码不难看出其内部结构是对zset中链表的一个抽象描述。zskiplist首先会对这个链表记录其头结点、尾结点方便通过zskiplist进行遍历操作。剩下的length自然就是对内部的这个链表数量的统计。比较抽象的是这个level的理解。在上面我们也看到了zskiplist那个链表实际上会有分层的概念。笔者这里通过不同的颜色进行表述不同层级的概念。
- 笔者这里针对上述描述的跳跃表内部的zskiplist绘画了一张内部数据图
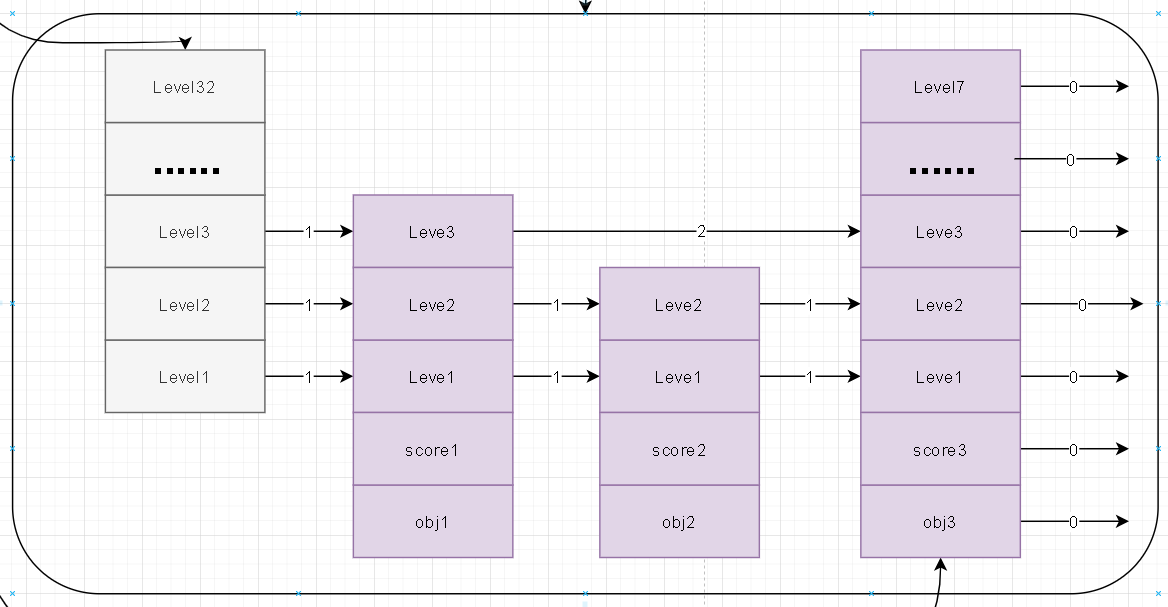
- 在对zskiplist结构描述和数据描述中我将他们拆开理解,觉得这样更容易理解结构关系。下面是整个图示
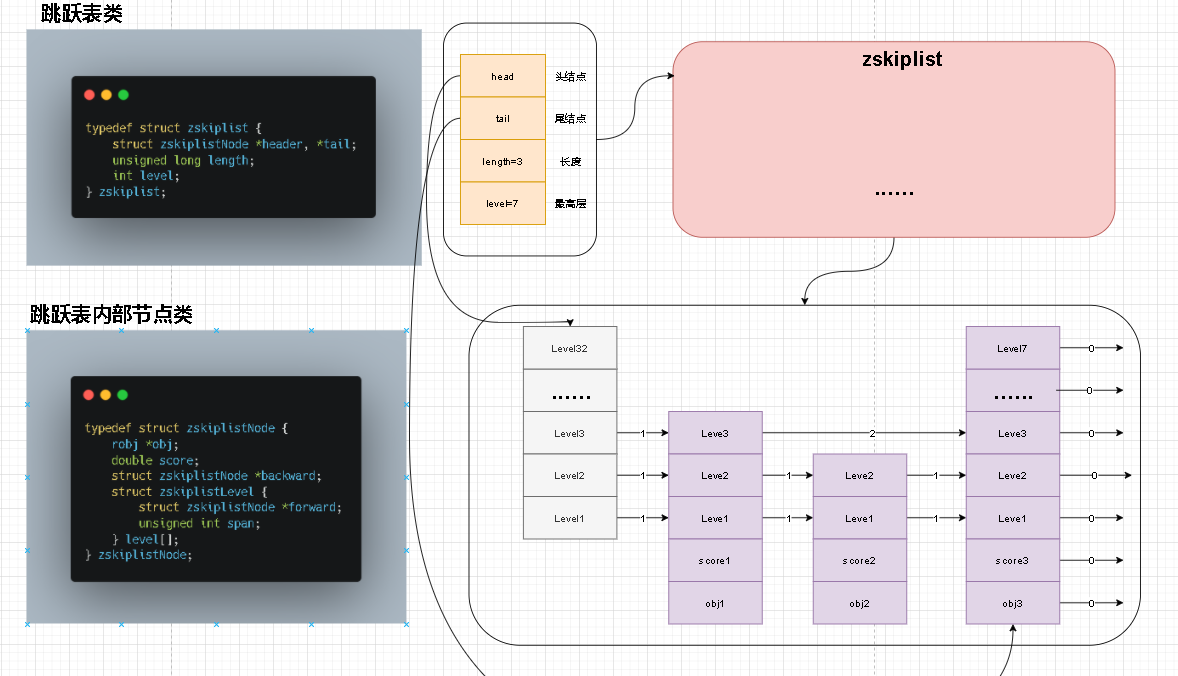
- 细心的读者应该能够发现,我好想漏掉了链表重要组成部分
zskiplistNode这个重要的节点说明。实际上他就是我们右侧那个链表中节点。换句话说链表中每个点就是zskiplistNode 。
level
- 跳跃表的重要特性类型与树结构可以避免逐个遍历的苦恼。那么他是如何实现这种跳跃性质的访问的呢?还有一点为什么redis会这么设计。首先我们先回答下为什么这么设计。在链表中插入、删除等操作是很快速的只需要改变指针指向就可以完成。但是对于查询来说他需要遍历整个链表才能完成操作。针对链表的这个弊端redis设计了跳表的数据结构。
- 下面就是针对如何实现来简单梳理下。上述zskiplistNode节点对象结构中我们也可以看到有个level属性。redis就是通过这个属性来实现跳跃的特性。在每个节点生成的时候回随机生成这个level值。他就表示这个节点所在层的范围。
- 关于这个level为什么说是随机。这有牵涉到其内部的幂等性算法。这个算法保证数字越大生成的概览越小。在redis内部level最大值32.
- 比如说level随机生成5 。 表示当前节点node在level1~level5这五层中。上面的图示中所示的三个节点生成的level值分别是level3、level2、level7。注意在实际存储中level索引时从0开始。
forward
- 在level中还有两个属性分别是前进指针、跨越长度。根据字面意思我们能够理解前进指针是想链表后端方向推进的指针。其跨度就是表示当前节点距离前进指针处节点的距离。这个距离的是参考最底层的距离的。
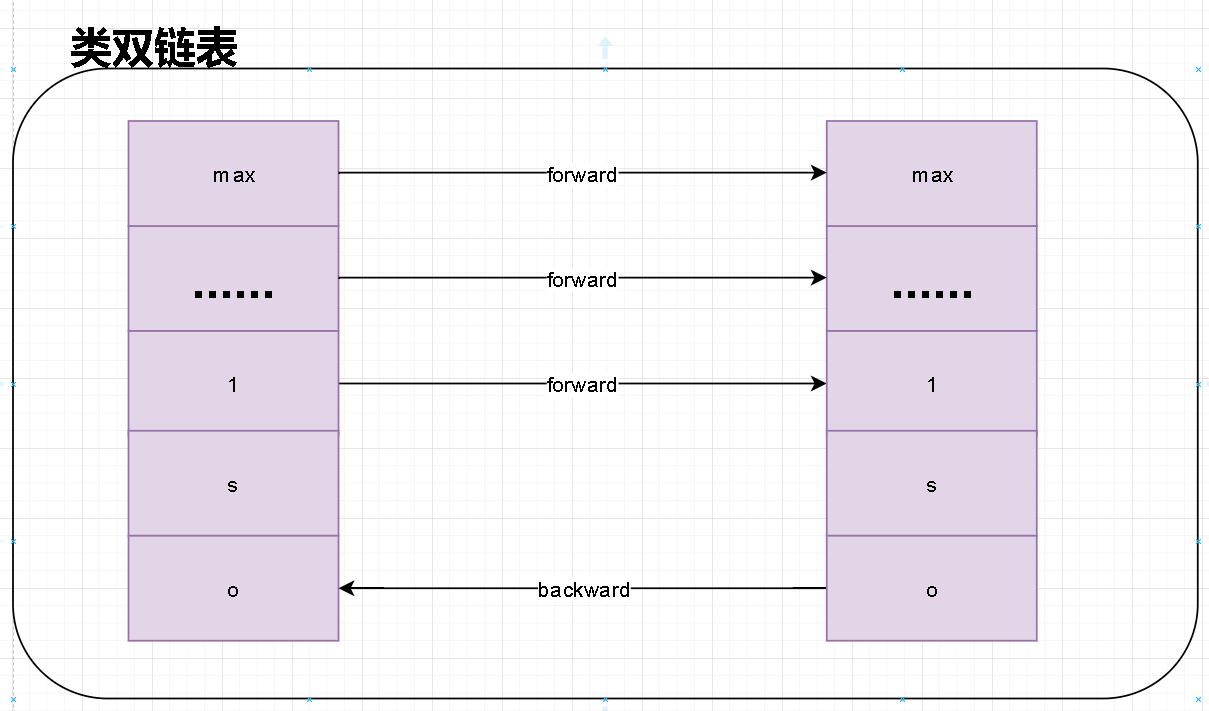
双链表
- 在zskiplist中每一层都是一个单向链表。在level中通过forwar指针指向我们表尾。那么为什么我说是双链表呢?这里的双链表不是严格意义的双链表。但是我们可以借助这些层级的单链表实现我们双向自由路由。
随机层
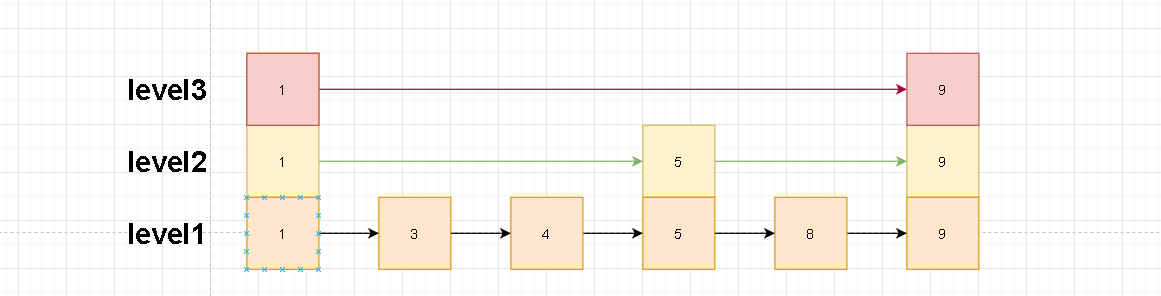
上面我们已经解释过level的定义了。那么为什么这里还有再提一遍呢?因为上面我们简单提到了幂等性算法。这里我们就详细解释下什么是幂等性。
首先根据level的定义我们可以总结如下几点关于level的特性。
①、一个节点如果在level[i]中,那么他一定在level[i]以下的层中
②、越高层元素跨度越大,这个跨度是不定的。取决于生成节点时的随机算法
③、每一层都是一个链表
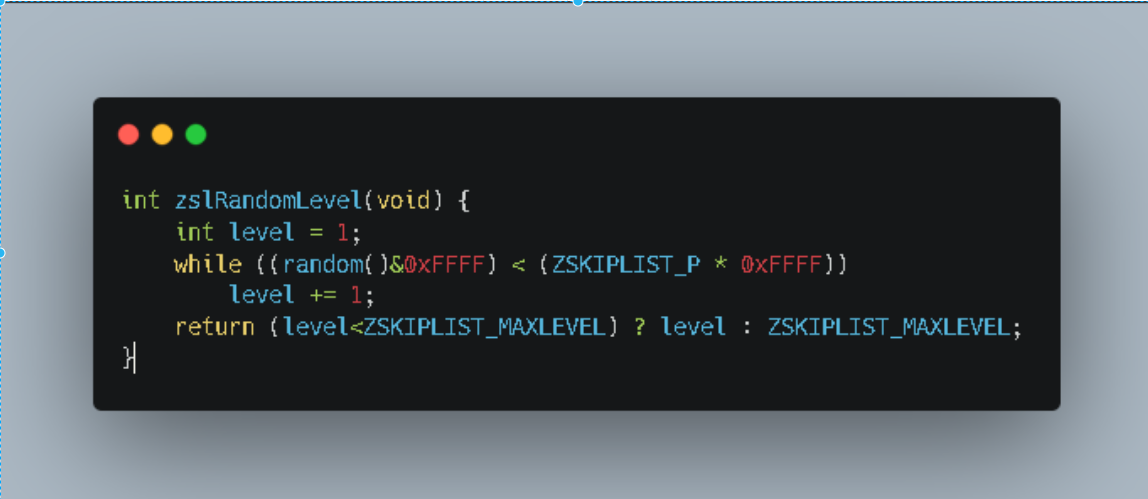
- 这是redis中源码部分。关于这个随机level的算法其实不是很难理解。笔者这里将上述代码进行流程化梳理
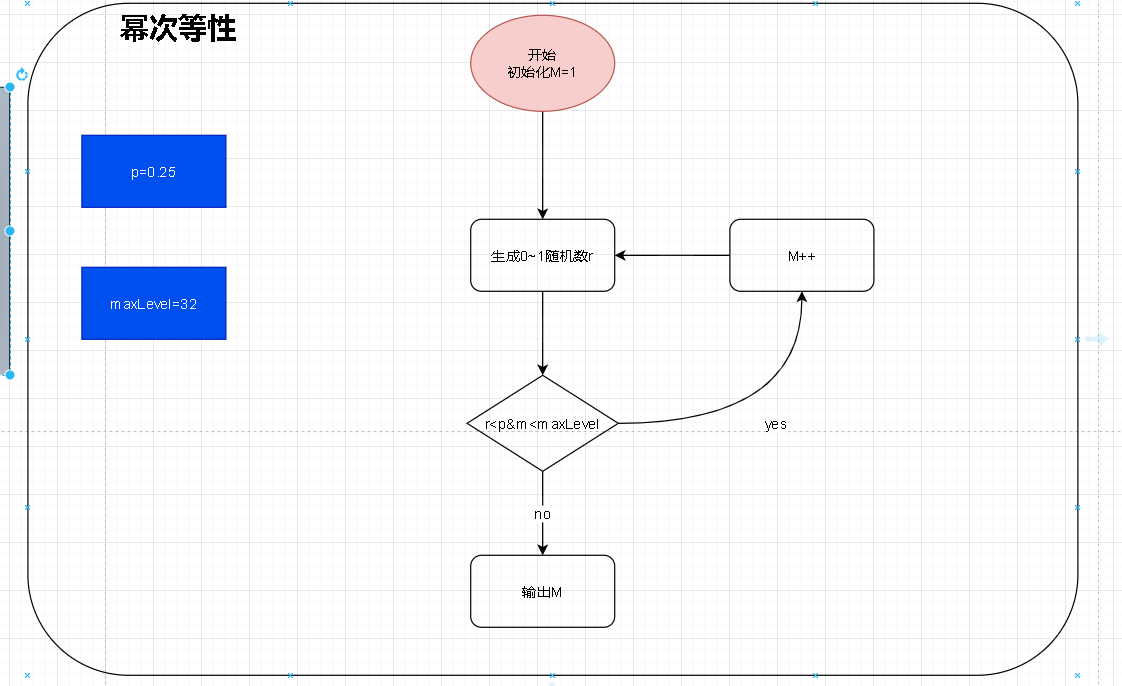
- 就是一个不断重试的机制。其中p和maxLevel都是代码中的固定值。在这个算法机制下我们就可以尽可能的保证在数据量小的情况下保证level不会特别的高。
- 换句话说我们的level就不会显得特别的突兀。如果是纯粹的随机生成的话就有可能有的节点level很低,有的level很高。这样会造成资源不必要的浪费。
查找
- 好了,同学们到了这里我们已经学习了关于zset的基本结构。 简单回顾下内部就是字典+跳表的结合。下面我们针对这两种数据结构来简单梳理下关于zset的常用的一些操作!
- 首先就是我们的查找。上面说了那么多内部结构。纸上谈兵终觉浅,我们还需要实战操作一下。
分数定位
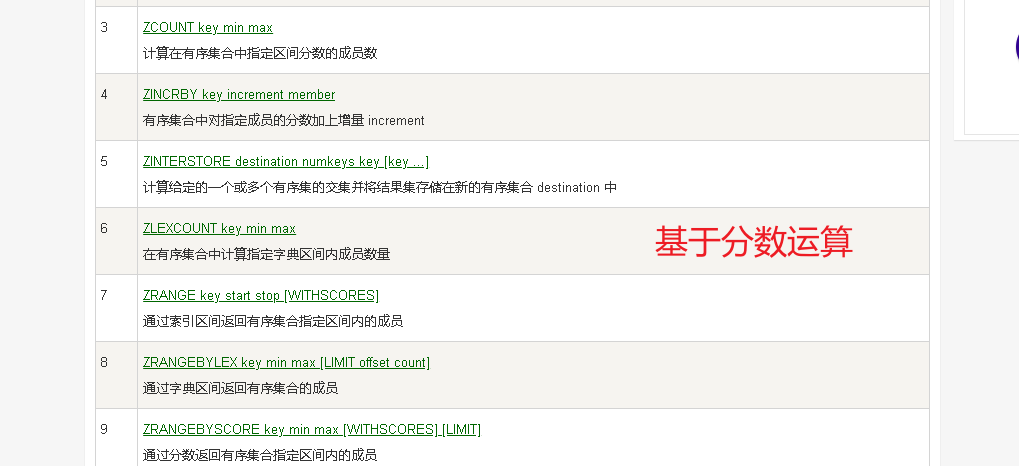
- 上述的命令基本都是通过分数定位然后在做自己的业务处理。
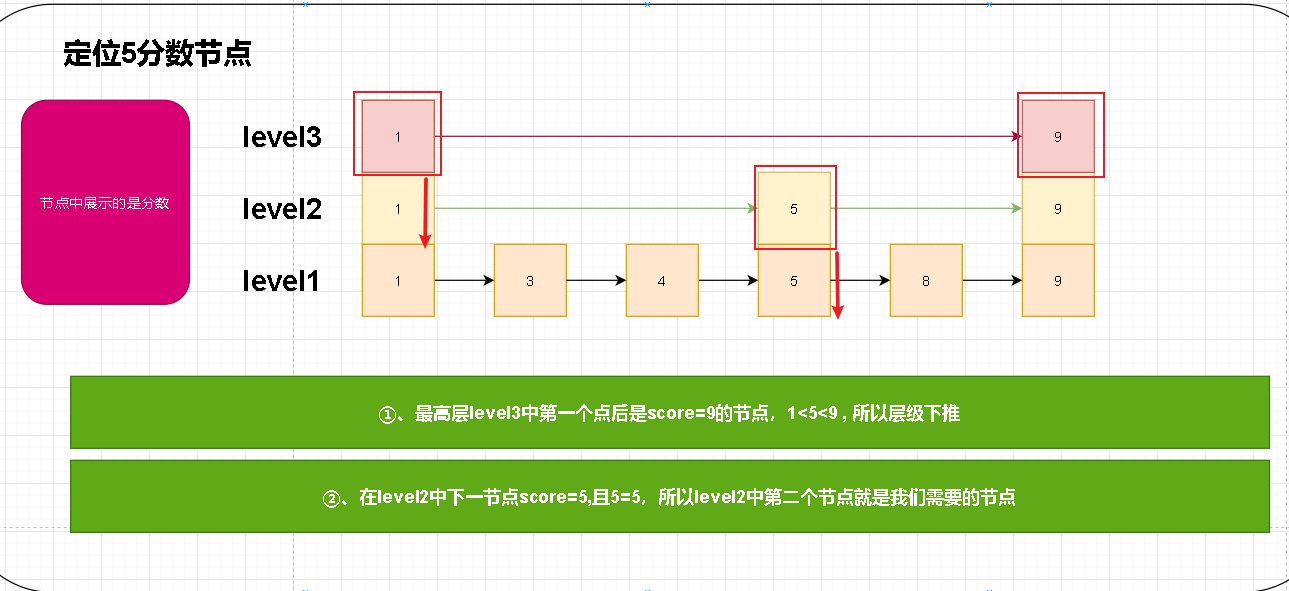
- 图示中已经说明了我们过程。首先是在最高层中寻找因为高层最稀疏。当高层没有发现时我们就会下推层级。此时我们来到level中的节点1.然后在通过forwar指针进行前移。最终定位节点5。
- 还有一点补充说明:节点中通过obj指针指向实际内容,score存储分支;笔者这里为什么演示方便直接在节点中标注了分数。其他部分并未进行标注!!!
成员定位
- 笔者在整理相关逻辑的时候也是经过百度、视频、书籍等方式翻阅后作出的结论。原谅我的能力无法直接阅读源码!但是在查阅资料的过程中。发现很少有说明是如何进行成员定位的。因为zset中除了分数的相关命令以外还有不少是基于成员定位的。
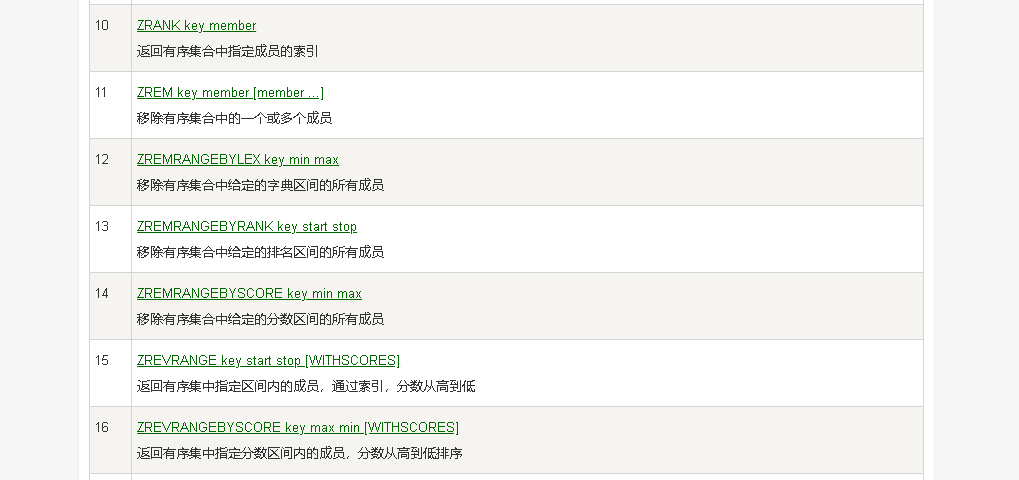
- 上述命令部分是基于成员进行定位的。在zset结构中实际节点是有基于score进行排序的。在obj中没有顺序可言。我们无法按照我们上述通过分数进行逐层定位元素!这就牵扯到我们另外一个重要的角色【字典(hash)】了。
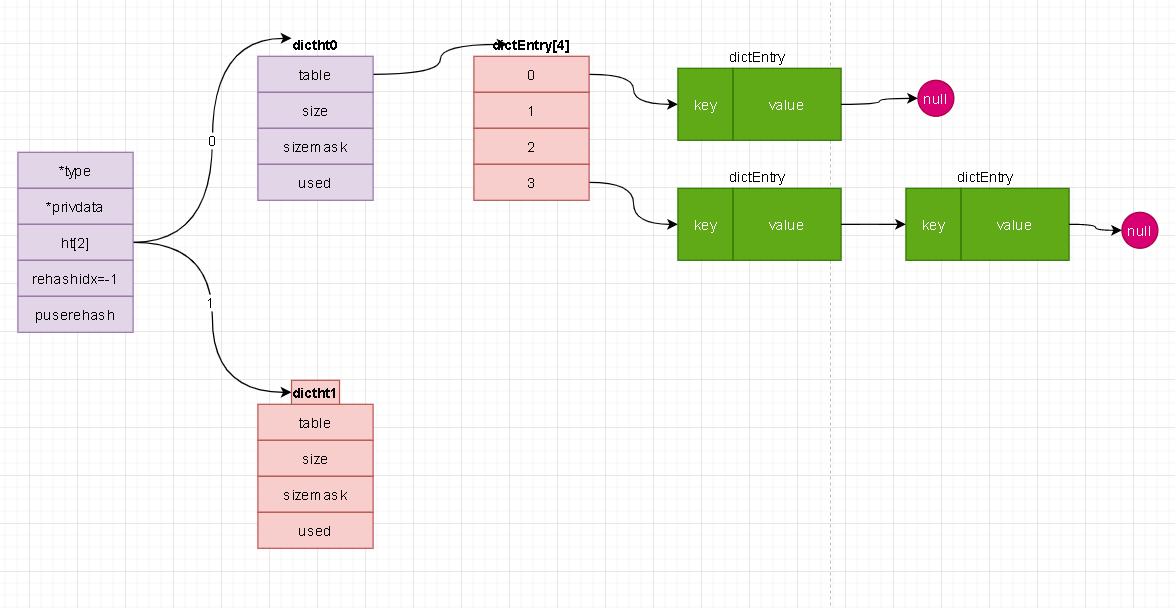
- 上图是我们上一章节的关于字典的说明。在通过成员定位的时候我们就是多了一步先从字典中定位到分数,然后在重复上面的步骤进行定位!
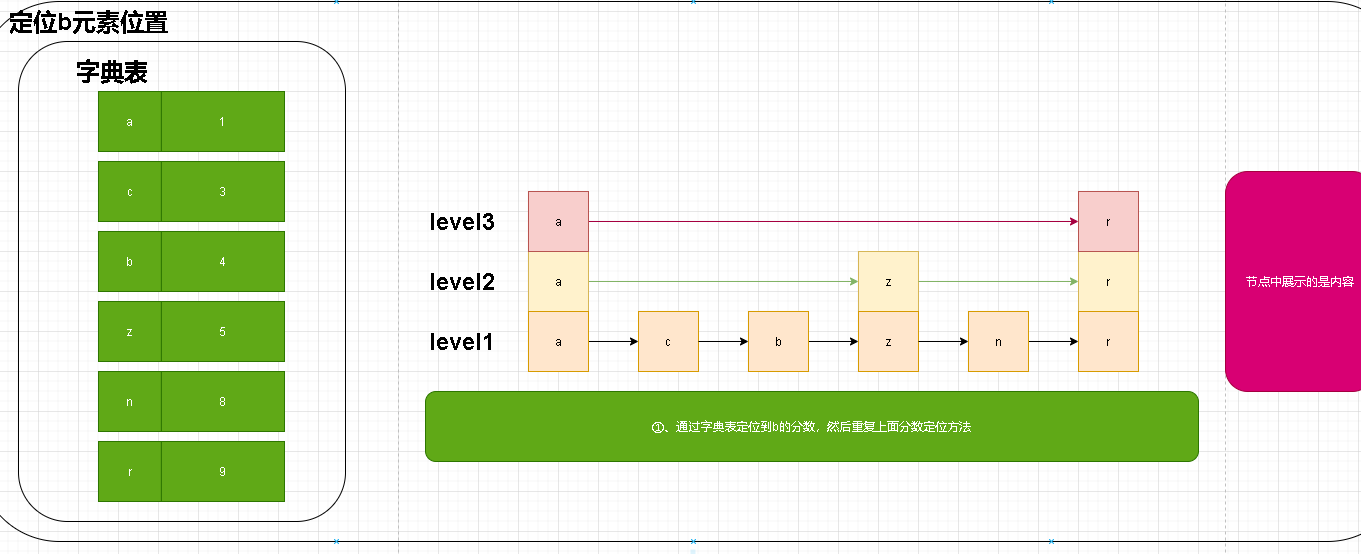
- 了解结构自然就能很容易理解相关的操作。站在巨人的肩膀我们虽然不需要在重复的造轮子了。但是我们得知道当初前辈们造轮子的过程!吃水不忘挖井人!
命令内部理解
- 了解结构就能快速掌握命令,否则就算死记硬背命令过一阵子又会忘记了。但是牢记结构后我们就会知道有命令可以实现我们的需求然后根据手册就可以得心应手。下面我们看看一下四个命令是如何实现的吧。
zcard
- 通过zskiplist中length属性
zcount
- 通过分数定位边界,然后遍历底层链表最终得到统计数量
zlecount
- 通过字典定位分数,在执行zcount操作
zrank
- 返回有序集合中指定成员的索引 , 先定位成员,定位过程中通过span可以确定排名
总结
- zset是一种有序链表。为了解决链表查询低下从而redis构建了跳表的数据结构。大大提高了效率!
- 关于zset的数据结构我们实际好多案例可以通过它来实现;延时队列、内部LRU、热点数据等等
点赞、关注不迷路哦
zset如何解决内部链表查找效率低下的更多相关文章
- 何在mysql查找效率慢的SQL语句?
如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow-queries[=file_name]选项启 ...
- List和Dictionary泛型类查找效率浅析
List和Dictionary泛型类查找效率存在巨大差异,前段时间亲历了一次.事情的背景是开发一个匹配程序,将书籍(BookID)推荐给网友(UserID),生成今日推荐数据时,有条规则是同一书籍七日 ...
- python 字典有序无序及查找效率,hash表
刚学python的时候认为字典是无序,通过多次插入,如di = {}, 多次di['testkey']='testvalue' 这样测试来证明无序的.后来接触到了字典查找效率这个东西,查了一下,原来字 ...
- easyui-datagrid加载时的效率低下,解决方案
在360浏览器中 使用easyui datagrid 加载数据是效率低下,有时候会出现卡机. 可以修改easyui源码进行解决.
- SqlBulkCopy效率低下原因分析
看到标题 应该会奇怪 SqlBulkCopy 为什么会效率低下 场景:接手项目 数据库SQLSERVER2008R2, 目前有一张流水表单表数据超过4亿,表中建有索引,有其他模块对这个表进行查询操作 ...
- 【疑难杂症02】ResultSet.next() 效率低下问题解决
今天帮同事解决了一个问题,记录一下,帮助有需要的人. 一.问题解决经过 事情的经过是这样的,下午我在敲代码的时候,一个同事悄悄走到我身边,问我有没有用没用过Oracle,这下我蒙了,难道我在他们眼中这 ...
- MySql in子句 效率低下优化
MySql in子句 效率低下优化 背景: 更新一张表中的某些记录值,更新条件来自另一张含有200多万记录的表,效率极其低下,耗时高达几分钟. where resid in ( ); 耗时 365s ...
- 我是怎么发现并解决项目页面渲染效率问题的(IE调试工具探查器的使用)
#我是怎么发现并解决项目页面渲染效率问题的(IE调试工具探查器的使用) ##背景 之前的项目中,有很多的登记页面,一般都有100-200甚至更加多的字段,而且还涉及到字典.日期及其他效果的显示,载入时 ...
- MySQL数据库中的字段类型varchar和char的主要区别是什么?哪种字段查找效率要高?
1,varchar与char的区别?(1)区别一,定长和变长,char表示定长,长度固定:varchar表示变长,长度可变.当插入字符串超出长度时,视情况来处理,如果是严格模式,则会拒绝插入并提示错误 ...
随机推荐
- 微服务架构(Microservices) ——Martin Flower
不知不觉到达了Sring Boot的学习中了,在学习之前,了解微服务架构是很有必要的,对于自己提升今后面试的软实力有很大帮助,在此写下. 让我们接下来看下Martin Flower 如何解释微服务架构 ...
- Python+Selenium - js操作
js操作:日期框 本部分涉及两个知识点:DOM树和js DOM树教程链接: https://www.w3school.com.cn/htmldom/index.asp js教程链接 https://w ...
- SQL SERVER常用语法记录
用于记录SQL SERVER常用语法,以及内置函数. 以下语句包含: WITH 临时表语法 ROW_NUMBER()内置函数,我一般主要是用来分页.针对于查出来的所有数据做一个数字排序 分页的BETW ...
- nologin用户执行命令
使用su su -s 是指定shell,这里www用户是nologin用户,是没有默认的shell的,这里指定使用/bin/bash, -c 后面接需要运行的命令, 后面www是用www用户来运行 s ...
- C++ 扩展 Op
C++ 扩展 Op 本文将介绍如何使用 C++ 扩展 Op,与用 Python 扩展 Op 相比,使用 C++ 扩展 Op,更加灵活.可配置的选项更多,且支持使用 GPU 作为计算设备.一般可使用 P ...
- VTA:深度学习加速器堆栈
VTA:深度学习加速器堆栈 多功能Tensor加速器(VTA)是一个开放的,通用的,可定制的深度学习加速器,具有完整的基于TVM的编译器堆栈.设计VTA来展示主流深度学习加速器的最显着和共同的特征.T ...
- Turing渲染着色器网格技术分析
Turing渲染着色器网格技术分析 图灵体系结构通过使用 网格着色器 引入了一种新的可编程几何着色管道.新的着色器将计算编程模型引入到图形管道中,因为协同使用线程在芯片上直接生成紧凑网格( meshl ...
- 在 CUDA C/C++ kernel中使用内存
在 CUDA C/C++ kernel中使用内存 如何在主机和设备之间高效地移动数据.本文将讨论如何有效地从内核中访问设备存储器,特别是 全局内存 . 在 CUDA 设备上有几种内存,每种内存的作用域 ...
- 编译器架构Compiler Architecture(上)
编译器架构Compiler Architecture(上) 编译器是程序,通常是非常大的程序.它们几乎都有一个基于翻译分析综合模型的结构. CONTENTS Overview • Compiler C ...
- Java中List和Map的区别
一.List和Map 1.特点 (1).List 1.可以允许重复的对象. 2.可以插入多个null元素. 3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序. 4.常用的实现类有 ...