Elasticsearch (1) 文档操作
本文介绍如何在Elasticsearch中对文档进行操作。
1、检查Elasticsearch及Kibana运行是否正常
在浏览器输入192.168.6.16:9200,有如下输出则说明Elasticsearch运行正常。
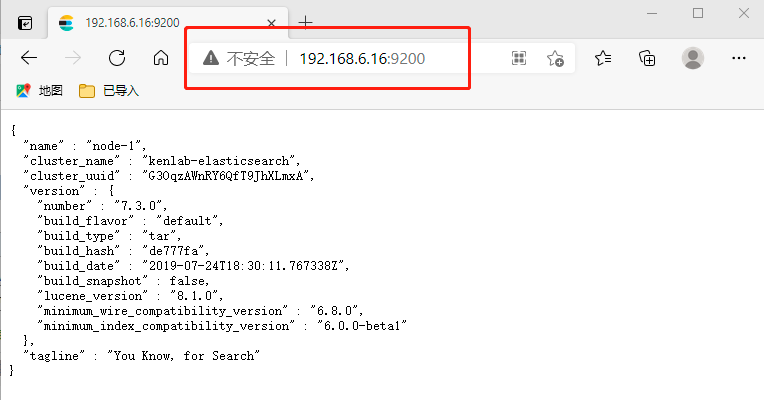
浏览器中输入http://192.168.6.16:5601/,显示如下页面,则说明Kibana运行正常。
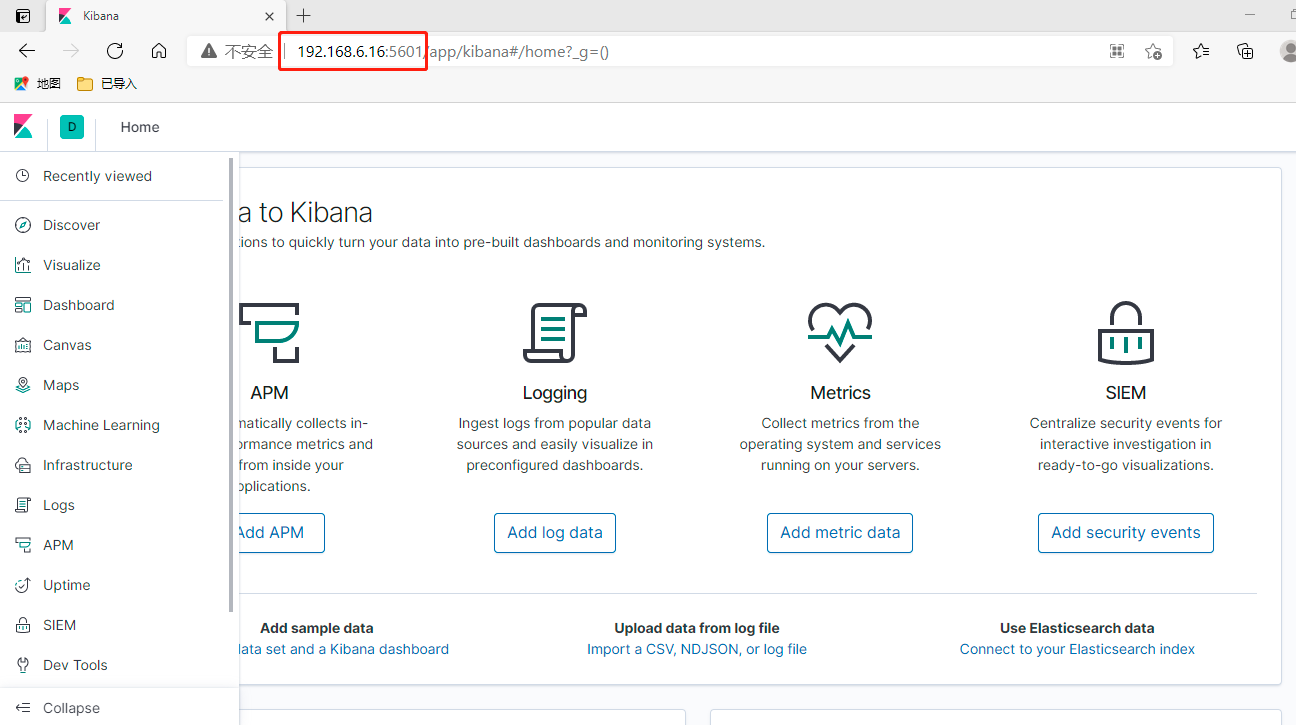
2、查看Elasticsearch信息
在kibana Dev tools中输入GET / 指令,同样可以查看Elasticsearch的版本信息及其cluster名称等:
GET /
如下图所示:

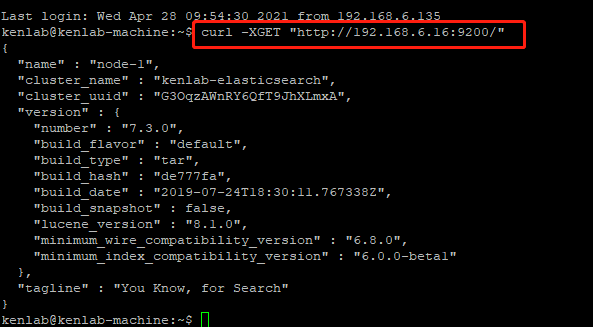
当然也可以在terminal中输入相同的指令来达到相同的效果,不过在Kibana中更加直接:

上面的命令拷贝成为cURL,然后粘贴上terminal上去执行,当然也反过来的操作也成立:
3、创建索引和文档
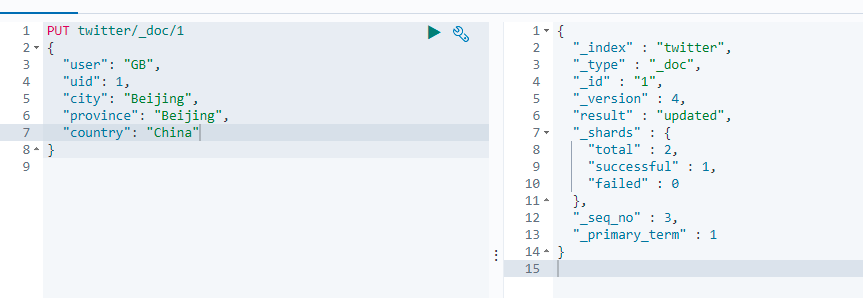
创建一个叫twitter的索引,并插入一个文档。
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
执行结果如下图:
通过上述方法,可以自动创建索引,如果不想用自动创建索引,可以修改设置。
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false"
}
}
通过上述方法写入到Elasticsearch中的文档,默认情况下不会马上可进行搜索,需要refresh操作,使其对搜索可见。通常会有一个refresh timer定时器来完成这个操作,周期周期为1秒,也就是通常说的Elasticsearch可以试系秒级搜索。如果想让结果马上对搜索可见,可以用如下方法:
PUT twitter/_doc/1?refresh=true
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
频繁使用fefresh操作,会使Elasticsearch变得非常慢。所以可以通过另外一种方式refresh=wait_for,相当于同步操作,等待下一个refresh周期发生后才返回。这样可以确保我们在调用上面接口后,马上可以搜索到我们刚才录入的文档。
PUT twitter/_doc/1?refresh=wait_for
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
每次执行post或者put接口时,如果文档已经存在,那么相应的版本会自动加1,之前的版本被抛弃掉。如果不是要更新文档的话,可以使用_create端点接口来实现:
PUT twitter/_create/1
{
"user": "GB",
"uid": 1,
"city": "Shenzhen",
"province": "Guangdong",
"country": "China"
}
此时如果文档已经存在时,系统将返回错误信息。如下图所示:
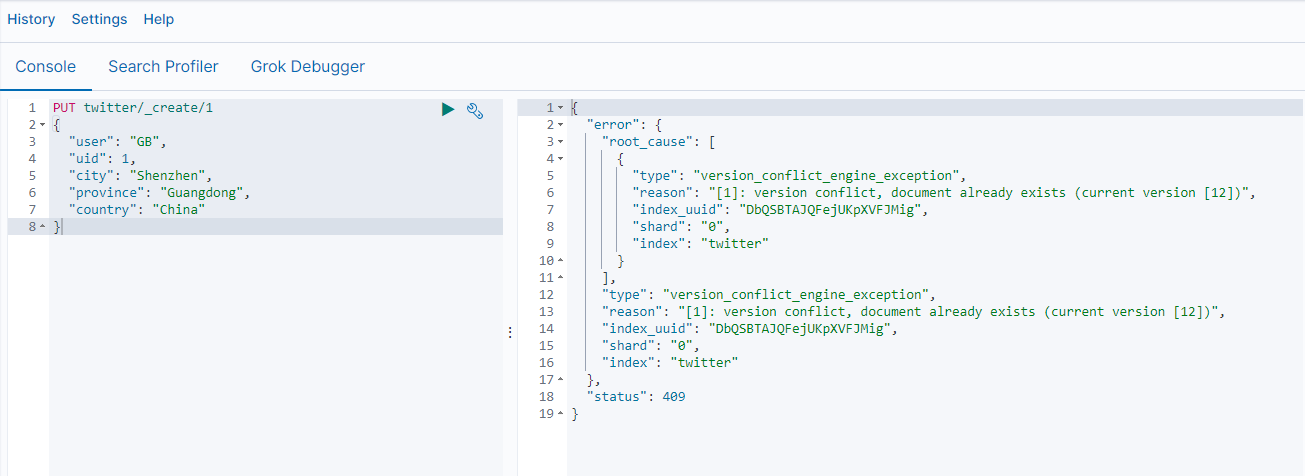
用如下命令也是一样的效果(op_type可以有两种值:index及create):
PUT twitter/_doc/1?op_type=create
{
"user": "张三",
"message": "Hi",
"uid": 2,
"age": 20,
"city": "北京",
"province": "北京",
"country": "中国",
"address": "中国北京市海淀区",
"location": {
"lat": "39.970718",
"lon": "116.325747"
}
}
4、查看被修改的文档
1)根据id查找文档。
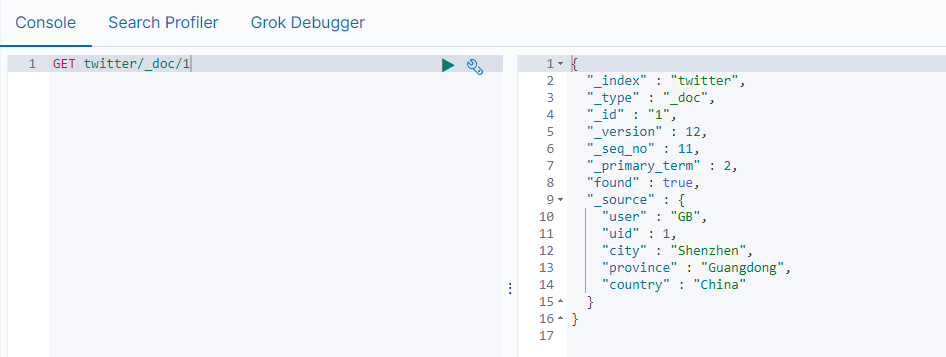
GET twitter/_doc/1
查询结果如下图所示:
可以通过如下命令来获取文档的_source部分:
GET twitter/_doc/1/_source
GET twitter/_source/1 //Elasticsearch 7.0之后建议使用这个命令
2)使用_mget查找多个文档
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1
},
{
"_index": "twitter",
"_id": 2
}
]
}
可以简写为:
GET twitter/_doc/_mget
{
"ids": ["1", "2"]
}
还可以使用_mget获得部分字段
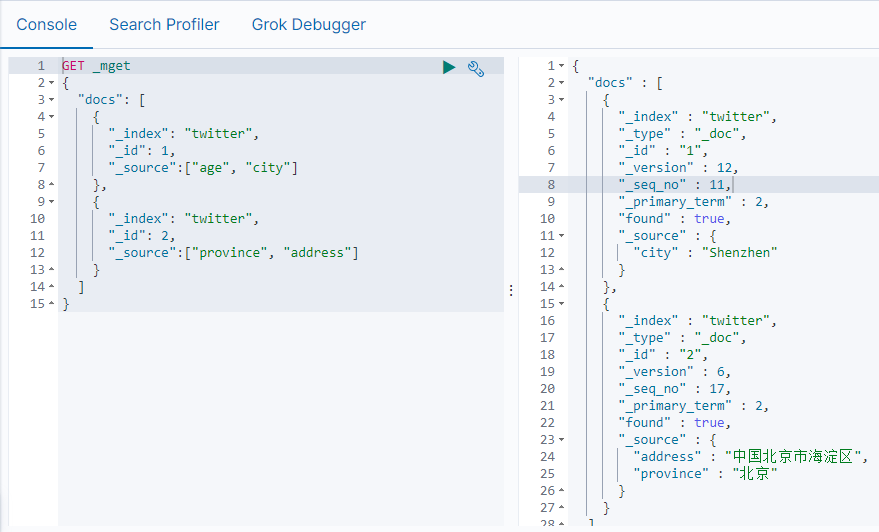
5、自动ID生成
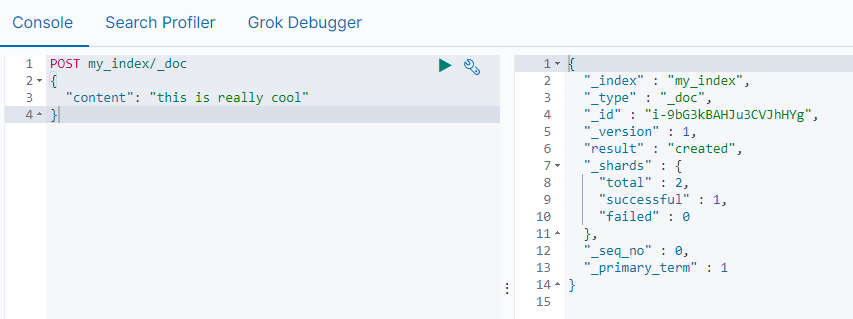
在上面命令中,作者特意给文档分配了一个ID。在实际应用中,并不必要。相反,手动分配一个ID时,在数据导入时会检查这个ID的文档是否存在,如果存在则更新这个版本,如果不存在,则创建一个新的文档。如果我们不指定文档ID,而让Elasticsearch自动帮我们生成ID,这样速度更快,这种情况下,我们必须使用POST,而不是PUT。比如:
POST my_index/_doc
{
"content": "this is really cool"
}
返回结果显示,系统自动分配一个ID:ju9eG3kBAHJu3CVJ0XaV。
并可以是如下命令查询到刚刚建立的文档:
GET /my_index/_doc/ju9eG3kBAHJu3CVJ0XaV/
6、修改文档
使用PUT并指定一个特定的ID来修改文档。
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "北京",
"province": "北京",
"country": "中国",
"location":{
"lat":"29.084661",
"lon":"111.335210"
}
}
使用PUT修改文档时,需要填写文档中的所有项。如要修改单独项时,可以实现如下方法:
POST twitter/_update/1
{
"doc": {
"city": "成都",
"province": "四川"
}
}
使用_update_by_query来协助搜索文档,然后信息修改。
POST twitter/_update_by_query
{
"query": {
"match": {
"user": "GB"
}
},
"script": {
"source": "ctx._source.city = params.city;ctx._source.province = params.province;ctx._source.country = params.country",
"lang": "painless",
"params": {
"city": "成都",
"province": "四川",
"country": "中国"
}
}
}
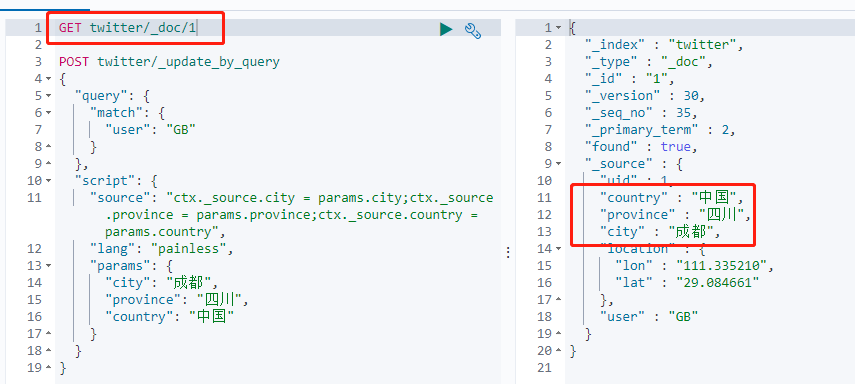
修改结果:
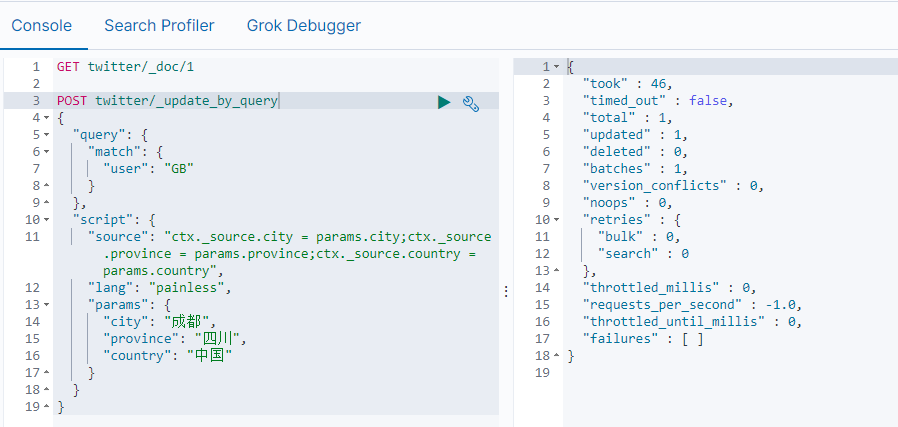
执行GET twitter/_doc/1 后,显示数据已修改成功。
对于那些名字是中文字段的文档来说,在 painless 语言中,直接打入中文字段名字,并不能被认可。我们可以使用如下的方式来操作:
POST edd/_update_by_query
{
"query": {
"match": {
"姓名": "张彬"
}
},
"script": {
"source": "ctx._source[\"签到状态\"] = params[\"签到状态\"]",
"lang": "painless",
"params" : {
"签到状态":"已签到"
}
}
}
在update接口中,也可以使用script方法来修改。
POST twitter/_update/1
{
"script" : {
"source": "ctx._source.city=params.city",
"lang": "painless",
"params": {
"city": "长沙"
}
}
}
可以使用 _update 接口使用 ctx['_op'] 来达到删除一个文档的目的,当检测文档的 uid 是否为 1,如果为 1 的话,那么该文档将被删除,否则将不做任何事情。:
POST twitter/_update/1
{
"script": {
"source": """
if(ctx._source.uid == 1) {
ctx.op = 'delete'
} else {
ctx.op = "none"
}
}
}
7、UPSERT
doc_as_upsert 参数检查具有给定ID的文档是否已经存在,并将提供的 doc 与现有文档合并。 如果不存在具有给定 ID 的文档,则会插入具有给定文档内容的新文档。
POST /catalog/_update/3
{
"doc": {
"author": "Albert Paro",
"title": "Elasticsearch 5.0 Cookbook",
"description": "Elasticsearch 5.0 Cookbook Third Edition",
"price": "54.99"
},
"doc_as_upsert": true
}
8、检查一个文档是否存在
返回200 - OK则说明文档存在。
HEAD twitter/_doc/1
9、删除文档
DELETE twitter/_doc/1
也可以通过查询方式来进行删除,如下语法功能把twitter索引中所有city是上海的文档都删除:
POST twitter/_delete_by_query
{
"query": {
"match": {
"city": "上海"
}
}
}
10、检查索引是否存在
HEAD twitter
11、删除索引
DELETE twitter
12、批处理_bulk
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}
使用_search命令查询所有输入的文档
POST twitter/_search
使用_count命令查询有多少条数据:
GET twitter/_count
也可以是create命令创建文档:
POST _bulk
{ "create" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}
index 和 create 的区别:
- index 总是可以成功,它可以覆盖之前的已经创建的文档。
- create 如果已经有以那个 id 为名义的文档,就不会成功。
使用delete删除一个已经创建好的文档:
POST _bulk
{ "delete" : { "_index" : "twitter", "_id": 1 }}
使用update来更新一个文档:
POST _bulk
{ "update" : { "_index" : "twitter", "_id": 2 }}
{"doc": { "city": "长沙"}}
Elasticsearch (1) 文档操作的更多相关文章
- ElasticSearch 基本概念 and 索引操作 and 文档操作 and 批量操作 and 结构化查询 and 过滤查询
基本概念 索引: 类似于MySQL的表.索引的结构为全文搜索作准备,不存储原始的数据. 索引可以做分布式.每一个索引有一个或者多个分片 shard.每一个分片可以有多个副本 replica. 文档: ...
- Elasticsearch索引和文档操作
列出所有索引 现在来看看我们的索引 GET /_cat/indices?v 响应 health status index uuid pri rep docs.count docs.deleted st ...
- elasticsearch——海量文档高性能索引系统
elasticsearch elasticsearch是一个高性能高扩展性的索引系统,底层基于apache lucene. 可结合kibana工具进行可视化. 概念: index 索引: 类似SQL中 ...
- 008-elasticsearch5.4.3【二】ES使用、ES客户端、索引操作【增加、删除】、文档操作【crud】
一.ES使用,以及客户端 1.pom引用 <dependency> <groupId>org.elasticsearch.client</groupId> < ...
- 007-elasticsearch5.4.3【一】概述、Elasticsearch 访问方式、Elasticsearch 面向文档、常用概念
一.概述 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Elasticsearch 也是使用 Java 编写的,它的内部使用 L ...
- .Net Api 之如何使用Elasticsearch存储文档
.Net Api 之如何使用Elasticsearch存储文档 什么是Elasticsearch? Elasticsearch 是一个分布式.高扩展.高实时的搜索与数据分析引擎.它能很方便的使大量数据 ...
- ES入门三部曲:索引操作,映射操作,文档操作
ES入门三部曲:索引操作,映射操作,文档操作 一.索引操作 1.创建索引库 #语法 PUT /索引名称 { "settings": { "属性名": " ...
- 一款开源免费的.NET文档操作组件DocX(.NET组件介绍之一)
在目前的软件项目中,都会较多的使用到对文档的操作,用于记录和统计相关业务信息.由于系统自身提供了对文档的相关操作,所以在一定程度上极大的简化了软件使用者的工作量. 在.NET项目中如果用户提出了相关文 ...
- jQuery 核心 - noConflict() 方法,jQuery 文档操作 - detach() 方法
原文地址:http://www.w3school.com.cn/jquery/manipulation_detach.asp 实例 使用 noConflict() 方法为 jQuery 变量规定新 ...
随机推荐
- C. The Meaningless Game
C. The Meaningless Game 题目链接 题意 给你两个数,开始都为1,然后每轮可以任选一个k,一边可以乘以\(k\),另一边乘以\(k^2\),然后问你最终是否可以得到所给的两个数a ...
- 【LeetCode】559. Maximum Depth of N-ary Tree 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 DFS BFS 日期 题目地址:https://le ...
- 【LeetCode】704. Binary Search 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 线性查找 二分查找 日期 题目地址:https:// ...
- 广告投放效果难判断?集成华为DTM为您轻松实现!
在进行广告投放时,你是否遇到这样的困扰: 花了一大笔预算去投放推广,不知道实际效果如何? 用户看到投放的广告,产生了哪些有价值的行为? 当前广告投放的渠道和类型等投放策略,是否需要调整? 此时我们就需 ...
- Handing Incomplete Heterogeneous Data using VAEs
目录 概 主要内容 ELBO 网络结构 不同的数据 HI-VAE 代码 Nazabal A., Olmos P., Ghahramani Z. and Valera I. Handing incomp ...
- Vue.js高效前端开发 • 【Ant Design of Vue框架进阶】
全部章节 >>>> 文章目录 一.栅格组件 1.栅格组件介绍 2.栅格组件使用 3.实践练习 二.输入组件 1.输入框组件使用 2.选择器组件使用 3.单选框组件使用 4.实践 ...
- 论文翻译:2020_Generative Adversarial Network based Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-5.pdf 基于GAN的回声消除 摘要 生成对抗网络(GANs)已成为语音增强( ...
- 【已开源】Flutter 穿山甲广告插件的集成-FlutterAds
前言 上篇文章我们聊了国内各大广告平台对 Flutter 的支持程度和我为什么创建 FlutterAds 来构建优质的 Flutter 广告插件,帮助开发者获利.本篇我们来看看Flutter 穿山甲广 ...
- Zookeeper基础教程(四):C#连接使用Zookeeper
Zookeeper作为分布式的服务框架,虽然是java写的,但是强大的C#也可以连接使用. C#要连接使用Zookeeper,需要借助第三方插件,而现在主要有两个插件可供使用,分别是ZooKeeper ...
- CSS基础 精灵图的使用
使用步骤1.创建盒子 <div class="one"></div> 2.使用PxCook量取图标大小,将图标的宽高设置成为盒子的宽高 ...