一种简易但设计全面的ID生成器思考
![]()
分布式系统中,全局唯一 ID 的生成是一个老生常谈但是非常重要的话题。随着技术的不断成熟,大家的分布式全局唯一 ID 设计与生成方案趋向于趋势递增的 ID,这篇文章将结合我们系统中的 ID 针对实际业务场景以及性能存储和可读性的考量以及优缺点取舍,进行深入分析。本文并不是为了分析出最好的 ID 生成器,而是分析设计 ID 生成器的时候需要考虑哪些,如何设计出最适合自己业务的 ID 生成器。

首先,先放出我们的全局唯一 ID 结构:
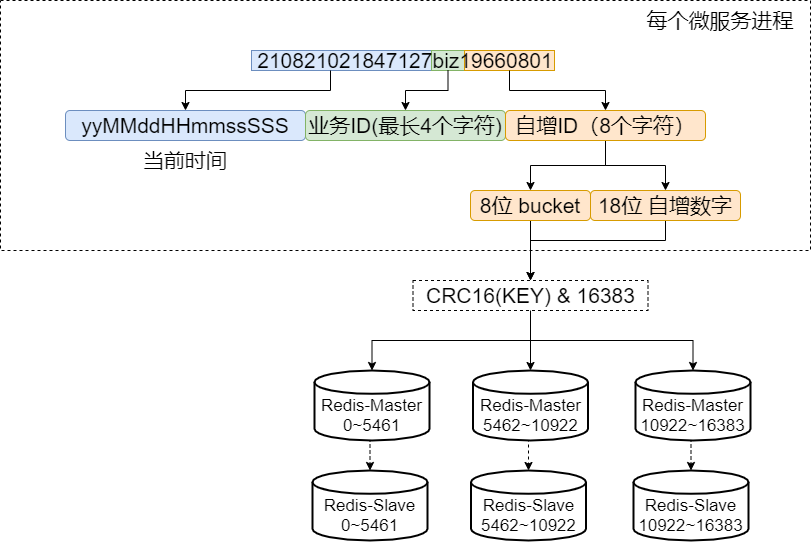
这个唯一 ID 生成器是放在每个微服务进程里面的插件这种架构,不是有那种唯一 ID 生成中心的架构:
- 开头是时间戳格式化之后的字符串,可以直接看出年月日时分秒以及毫秒。由于分散在不同进程里面,需要考虑不同微服务时间戳不同是否会产生相同 ID 的问题。
- 中间业务字段,最多 4 个字符。
- 最后是自增序列。这个自增序列通过 Redis 获取,同时做了分散压力优化以及集群 fallback 优化,后面会详细分析。

序列号的开头是时间戳格式化之后的字符串,由于分散在不同进程里面,不同进程当前时间可能会有差异,这个差异可能是毫秒或者秒级别的。所以,要考虑 ID 中剩下的部分是否会产生相同的序列。
自增序列由两部分组成,第一部分是 Bucket,后面是从 Redis 中获取的对应 Bucket 自增序列,获取自增序列的伪代码是:
1. 获取当前线程 ThreadLocal 的 position,position 初始值为一个随机数。
2. position += 1,之后对最大 Bucket 大小(即 2^8)取余,即对 2^8 - 1 取与运算,获取当前 Bucket。
如果当前 Bucket 没有被断路,则执行做下一步,否则重复 2。
如果所有 Bucket 都失败,则抛异常退出
3. redis 执行: incr sequence_num_key:当前Bucket值,拿到返回值 sequence
4. 如果 sequence 大于最大 Sequence 值,即 2^18, 对这个 Bucket 加锁(sequence_num_lock:当前Bucket值),
更新 sequence_num_key:当前Bucket值 为 0,之后重复第 3 步。否则,返回这个 sequence
-- 如果 3,4 出现 Redis 相关异常,则将当前 Bucket 加入断路器,重复步骤 2
在这种算法下,即使每个实例时间戳可能有差异,只要在最大差异时间内,同一业务不生成超过 Sequence 界限数量的实体,即可保证不会产生重复 ID。
同时,我们设计了 Bucket,这样在使用 Redis 集群的情况下,即使某些节点的 Redis 不可用,也不会影响我们生成 ID。

当前 OLTP 业务离不开传统数据库,目前最流行的数据库是 MySQL,MySQL 中最流行的 OLTP 存储引擎是 InnoDB。考虑业务扩展与分布式数据库设计,InnoDB 的主键 ID 一般不采用自增 ID,而是通过全局 ID 生成器生成。这个 ID 对于 MySQL InnoDB 有哪些性能影响呢?我们通过将 BigInt 类型主键和我们这个字符串类型的主键进行对比分析。
首先,由于 B+ 树的索引特性,主键越是严格递增,插入性能越好。越是混乱无序,插入性能越差。这个原因,主要是 B+ 树设计中,如果值无序程度很高,数据被离散存储,造成 innodb 频繁的页分裂操作,严重降低插入性能。可以通过下面两个图的对比看出:
插入有序:

插入无序:
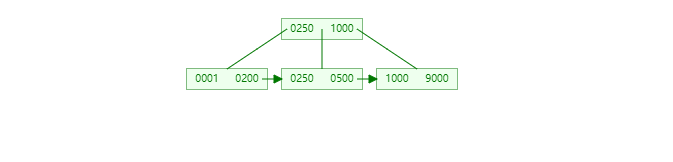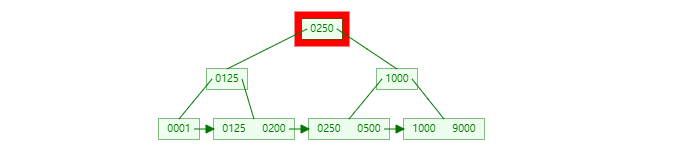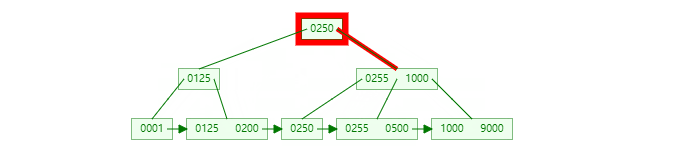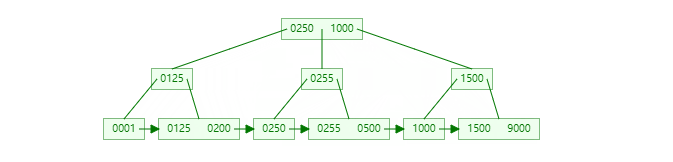
如果插入的主键 ID 是离散无序的,那么每次插入都有可能对于之前的 B+ 树子节点进行裂变修改,那么在任一一段时间内,整个 B+ 树的每一个子分支都有可能被读取并修改,导致内存效率低下。如果主键是有序的(即新插入的 id 比之前的 id 要大),那么只有最新分支的子分支以及节点会被读取修改,这样从整体上提升了插入效率。
我们设计的 ID,由于是当前时间戳开头的,从趋势上是整体递增的。基本上能满足将插入要修改的 B+ 树节点控制在最新的 B+ 树分支上,防止树整体扫描以及修改。

和 SnowFlake 算法生成的 long 类型数字,在数据库中即 bigint 对比:bigint,在 InnoDB 引擎行记录存储中,无论是哪种行格式,都占用 8 字节。我们的 ID,char类型,字符编码采用 latin1(因为只有字母和数字),占用 27 字节,大概是 bigint 的 3 倍多。
- MySQL 的主键 B+ 树,如果主键越大,那么单行占用空间越多,即 B+ 树的分支以及叶子节点都会占用更多空间,造成的后果是:MySQL 是按页加载文件到内存的,也是按页处理的。这样一页内,可以读取与操作的数据将会变少。如果数据表字段只有一个主键,那么 MySQL 单页(不考虑各种头部,例如页头,行头,表头等等)能加载处理的行数, bigint 类型是我们这个主键的 3 倍多。但是数据表一般不会只有主键字段,还会有很多其他字段,其他字段占用空间越多,这个影响越小。
- MySQL 的二级索引,叶子节点的值是主键,那么同样的,单页加载的叶子节点数量,bigint 类型是我们这个主键的 3 倍多。但是目前一般 MySQL 的配置,都是内存资源很大的,造成其实二级索引搜索主要的性能瓶颈并不在于此处,这个 3 倍影响对于大部分查询可能就是小于毫秒级别的优化提升。相对于我们设计的这个主键带来的可读性以及便利性来说,是微不足道的。

业务上,其实有很多需要按创建时间排序的场景。比如说查询一个用户今天的订单,并且按照创建时间倒序,那么 SQL 一般是:
## 查询数量,为了分页
select count(1) from t_order where user_id = "userid" and create_time > date(now());
## 之后查询具体信息
select * from t_order where user_id = "userid" and create_time > date(now()) order by create_time limit 0, 10;
订单表肯定会有 user_id 索引,但是随着业务增长,下单量越来越多导致这两个 SQL 越来越慢,这时我们就可以有两种选择:
- 创建 user_id 和 create_time 的联合索引来减少扫描,但是大表额外增加索引会导致占用更多空间并且和现有索引重合有时候会导致 SQL 优化有误。
- 直接使用我们的主键索引进行筛选:
select count(1) from t_order where user_id = "userid" and id > "210821";
select * from t_order where user_id = "userid" and id > "210821" order by id desc limit 0, 10;
但是需要注意的是,第二个 SQL 执行会比创建 user_id 和 create_time 的联合索引执行原来的 SQL 多一步 Creating sort index 即将命中的数据在内存中排序,如果命中量比较小,即大部分用户在当天的订单量都是几十几百这个级别的,那么基本没问题,这一步不会消耗很大。否则还是需要创建 user_id 和 create_time 的联合索引来减少扫描。
如果不涉及排序,仅仅筛选的话,这样做基本是没问题的。

我们不希望用户通过 ID 得知我们的业务体量,例如我现在下一单拿到 ID,之后再过一段时间再下一单拿到 ID,对比这两个 ID 就能得出这段时间内有多少单。
我们设计的这个 ID 完全没有这个问题,因为最后的序列号:
- 所有业务共用同一套序列号,每种业务有 ID 产生的时候,就会造成 Bucket 里面的序列递增。
- 序列号同一时刻可能不同线程使用的不同的 Bucket,并且结果是位操作,很难看出来那部分是序列号,那部分是 Bucket。

从我们设计的 ID 上,可以直观的看出这个业务的实体,是在什么时刻创建出来的:
- 一般客服受理问题的时候,拿到 ID 就能看出来时间,直接去后台系统对应时间段调取用户相关操作记录即可。简化操作。
- 一般的业务有报警系统,一般报警信息中会包含 ID,从我们设计的 ID 上就能看出来创建时间,以及属于哪个业务。
- 日志一般会被采集到一起,所有微服务系统的日志都会汇入例如 ELK 这样的系统中,从搜索引擎中搜索出来的信息,从 ID 就能直观看出业务以及创建时间。

在给出的项目源码地址中的单元测试中,我们测试了通过 embedded-redis 启动一个本地 redis 的单线程,200 线程获取 ID 的性能,并且对比了只操作 redis,只获取序列以及获取 ID 的性能,我的破电脑结果如下:
单线程
BaseLine(only redis): 200000 in: 28018ms
Sequence generate: 200000 in: 28459ms
ID generate: 200000 in: 29055ms
200线程
BaseLine(only redis): 200000 in: 3450ms
Sequence generate: 200000 in: 3562ms
ID generate: 200000 in: 3610ms
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

一种简易但设计全面的ID生成器思考的更多相关文章
- [置顶]
echarts x轴文字显示不全(xAxis文字倾斜比较全面的3种做法值得推荐)
echarts x轴标签文字过多导致显示不全 如图: 解决办法1:xAxis.axisLabel 属性 axisLabel的类型是object ,主要作用是:坐标轴刻度标签的相关设置.(当然yAxis ...
- 超全面的.NET GDI+图形图像编程教程
本篇主题内容是.NET GDI+图形图像编程系列的教程,不要被这个滚动条吓到,为了查找方便,我没有分开写,上面加了目录了,而且很多都是源码和图片~ (*^_^*) 本人也为了学习深刻,另一方面也是为了 ...
- Winform开发框架之简易工作流设计(转自 伍华聪博客)
Winform开发框架之简易工作流设计 一讲到工作流,很多人第一反应就是这个东西很深奥,有时候又觉得离我们较为遥远,确实完善的工作流设计很多方面,而正是由于需要兼顾很多方面,一般通用的工作流都难做到尽 ...
- [转]超全面的.NET GDI+图形图像编程教程
本篇主题内容是.NET GDI+图形图像编程系列的教程,不要被这个滚动条吓到,为了查找方便,我没有分开写,上面加了目录了,而且很多都是源码和图片~ GDI+绘图基础 编写图形程序时需要使用GDI(Gr ...
- 最全面的iOS和Mac开源项目和第三方库汇总
标签: UI 下拉刷新 EGOTableViewPullRefresh – 最早的下拉刷新控件. SVPullToRefresh – 下拉刷新控件. MJRefresh – 仅需一行代码就可以为UIT ...
- 【Linux开发】全面的framebuffer详解
全面的framebuffer详解 一.FrameBuffer的原理 FrameBuffer 是出现在 2.2.xx 内核当中的一种驱动程序接口. Linux是工作在保护模式下,所以用户态进程是无法象D ...
- 最全面的 C++ 资源、框架大全
转载自 http://www.codeceo.com/article/cpp-resource-framework.html#0-tsina-1-99850-397232819ff9a47a7b7 ...
- 大数据-将MP3保存到数据库并读取出来《黑马程序员_超全面的JavaWeb视频教程vedio》day17
黑马程序员_超全面的JavaWeb视频教程vedio\黑马程序员_超全面的JavaWeb教程-源码笔记\JavaWeb视频教程_day17-资料源码\day17_code\day17_1\ 大数据 目 ...
- 最全面的 Android 编码规范指南
最全面的 Android 编码规范指南 本文word文档下载地址:http://pan.baidu.com/s/1bXT75O 1. 前言 这份文档参考了 Google Java 编程风格规范和 Go ...
随机推荐
- 单选按钮(radio)的取值和点击事件
笔记走一波:获取单选按钮(radio)的选中值,以及它的点击事件的实现 首先要引入Jquery <script type="text/javascript" src=&quo ...
- Java实验项目三——递归实现字符串查找和替换操作
Program:按照下面要求实现字符串的操作: (1)设计一个提供下面字符串操作的类 1)编写一个方法,查找在一个字符串中指定字符串出现的次数. 2)编写一个方法,参数(母字符串,目标字符串,替换字符 ...
- linux学习之路第四天
用户和用户组的配置文件
- STM32中的通信协议
按照数据传送方式分: 串行通信(一条数据线.适合远距离传输)并行通信(多条数据线.成本高.抗干扰性差) 按照通信的数据同步方式分: 异步通信(以1个字符为1帧.发送与接收时钟不一致)同步通信(位同步. ...
- idea本地调式tomcat源码
前言 上篇文章中一直没搞定的tomcat源码调试终于搞明白了,p神的代码审计星球里竟然有,真的好b( ̄▽ ̄)d ,写一下过程,还有p神没提到的小坑 准备阶段 1.去官网下东西:https://tomc ...
- C语言:按相反顺序输出字符
#include <stdio.h> void pailie(int n) { char next; if (n<=1) { next=getchar(); putchar(next ...
- 【LeetCode】137. 只出现一次的数字 II(剑指offer 56-II)
137. 只出现一次的数字 II(剑指offer 56-II) 知识点:哈希表:位运算 题目描述 给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 .请你找出并返回 ...
- JavaScript学习笔记:你必须要懂的原生JS(二)
11.如何正确地判断this?箭头函数的this是什么? this是 JavaScript 语言的一个关键字.它是函数运行时,在函数体内部自动生成的一个对象,只能在函数体内部使用. this的绑定规则 ...
- FiddlerEverywhere 的配置和基本应用
一.下载大家自行在官网下载即可,这个可以当做是fiddler的升级版本,里面加了postman的功能,个人感觉界面比较清晰简约,比较喜欢. 二.下载完成之后大家可以自行注册登录,主页面的基本使用如下: ...
- P5350 序列
P5350 序列 题意 维护一个序列,支持区间求和.赋值.加值.复制.交换.翻转操作,其中交换和复制操作保证两段区间长度相等且不交.答案对 \(1e9+7\) 取模. 思路 对于区间求和.赋值.加值. ...