(转)Python爬虫--通用框架
转自https://blog.csdn.net/m0_37903789/article/details/74935906
前言:
相信不少写过Python爬虫的小伙伴,都应该有和笔者一样的经历吧只要确定了要爬取的目标,就开始疯狂的写代码,写脚本经过一番努力后,爬取到目标数据;但是回过头来,却发现自己所代码复用性小,一旦网页发生了更改,我们也不得不随之更改自己的代码,而却自己的程序过于脚本化,函数化,没有采用OPP的思维方式;没有系统的框架或结构。
指导老师看了笔者的爬虫作品后,便给出了以下三点建议:
(1)爬虫爬取的数据根据需要存数据库或直接写入.csv文件;
(2)爬虫程序包括控制程序、URL调度器、页面加载器、页面分析器、数据处理器等,尽量用OOP的思想,写成类,便于扩充,而不要直接全写成脚本;
(3)控制程序最好使用一个用户界面,用于设置开始爬取的页面、数据存放位置、显示爬取情况等。
由于笔者知识和能力有限,刚听到这些建议时,很难明白他的意思,而笔者还偏执的认为既然已经成功的爬取到目标数据,也就没什么要做的啦,已经OK啦直到昨天看了这个http://www.imooc.com/learn/563关于Python爬虫的课程后,才彻底的理解了老师教的课程里系统的讲解了爬虫应有的框架和结构,使笔者收益匪浅,故在此总结,反思,希望对大家有帮助。
这里先为它,打个小广告吧~笔者个人认为,不管你是资深的Python爬虫专家,还是才接触爬虫的新手,都应该来看一看,为你以后的Python爬虫工作添砖加瓦,广告语“慕课网—程序员的梦工厂”。
PS:以下截图,为笔者再听课时截图整理所得,故图片来源该课程的PPT
基于百度百科词条,通用爬虫源码:https://github.com/NO1117/baike_spider
Python交流群:942913325 欢迎大家一起交流学习
总结:
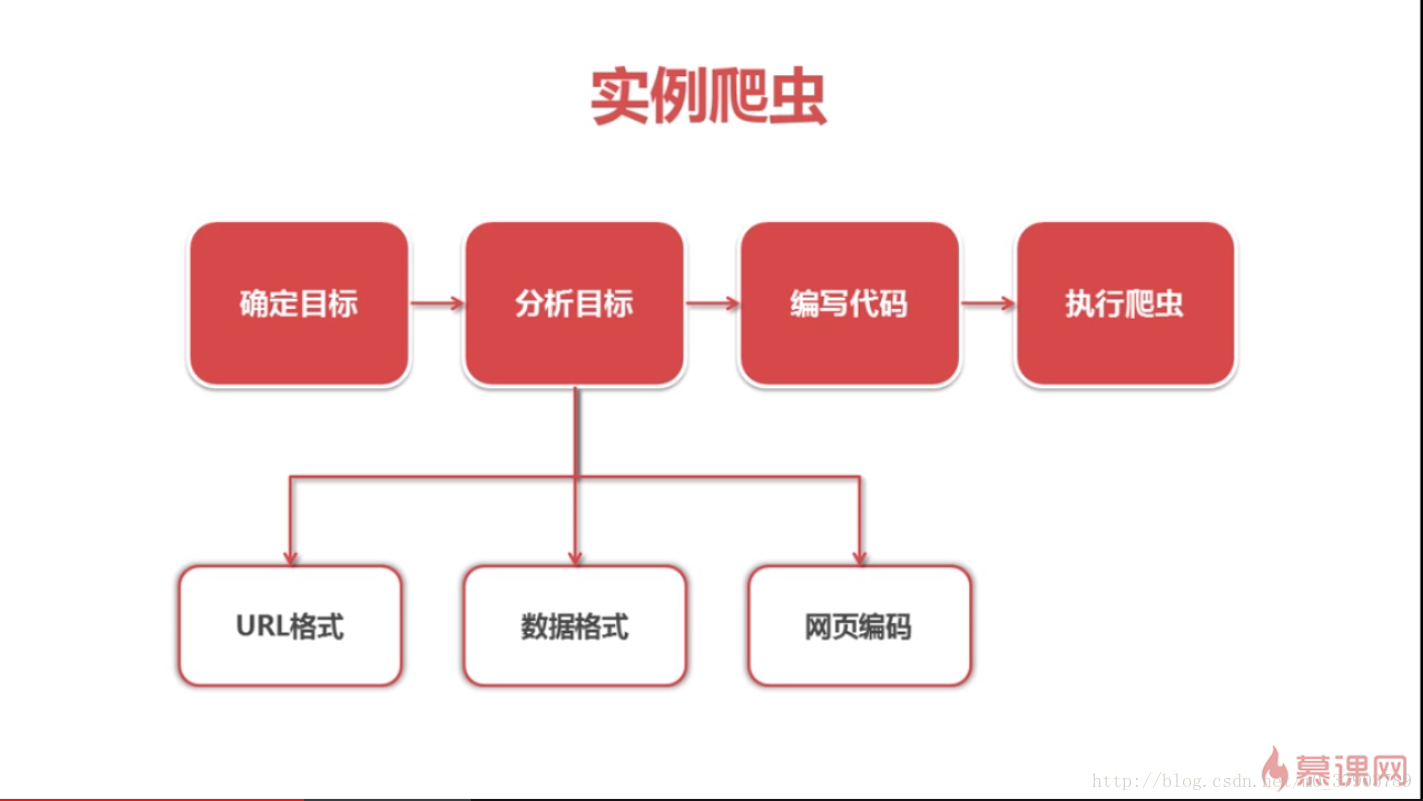
1.爬虫思路
如上图所示,一般在开始爬虫时,都会经历这样的思考过程,其中最为主要和关键的分析目标,只有经过准确的分析和前期的充分准备,才能顺顺利利的爬取到目标数据。
2.爬虫任务:

3.爬虫的框架及运行流程图
接下来,就一起学习一下Python爬虫的框架吧~
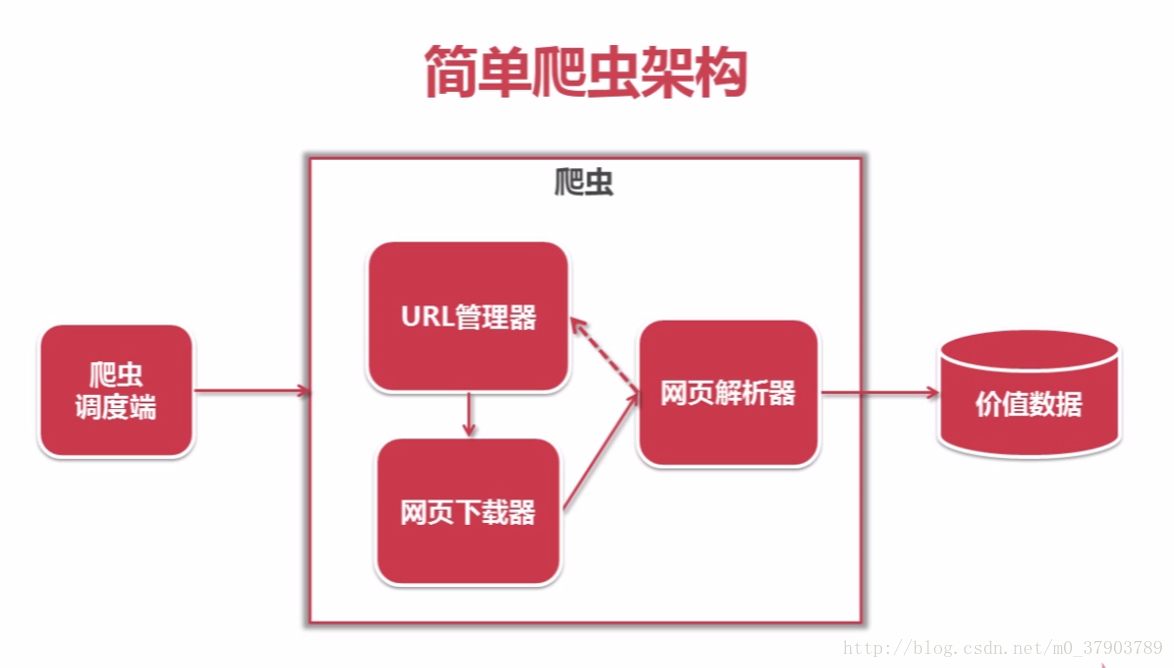
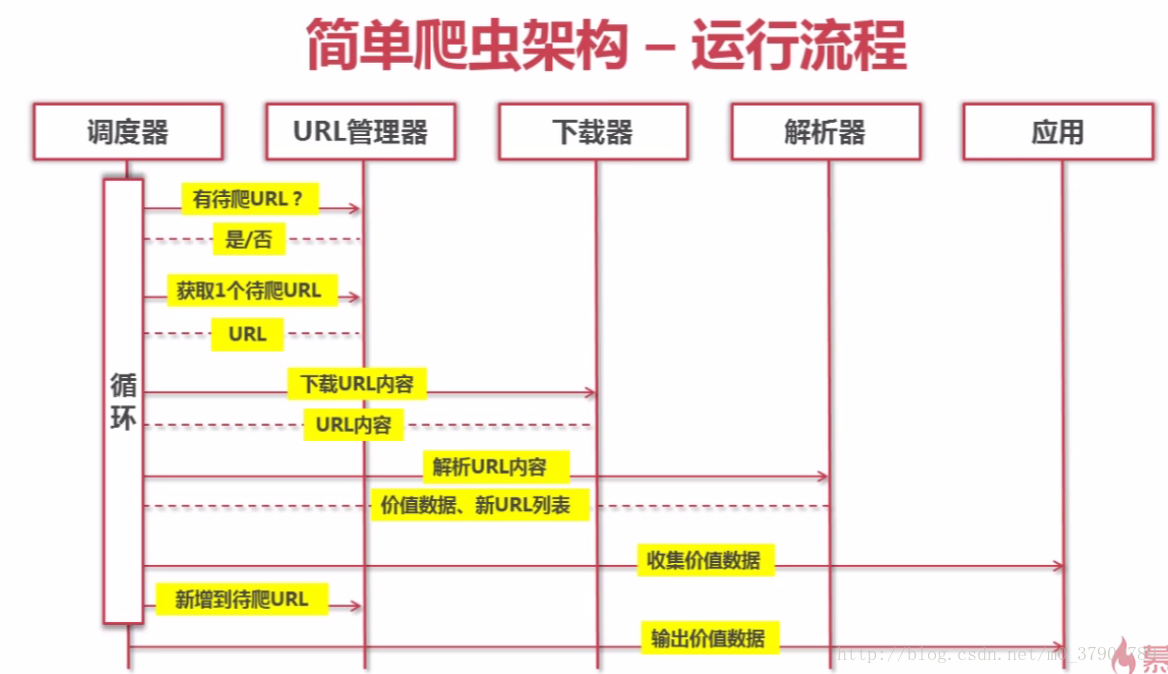
爬虫的大致运行过程如下:
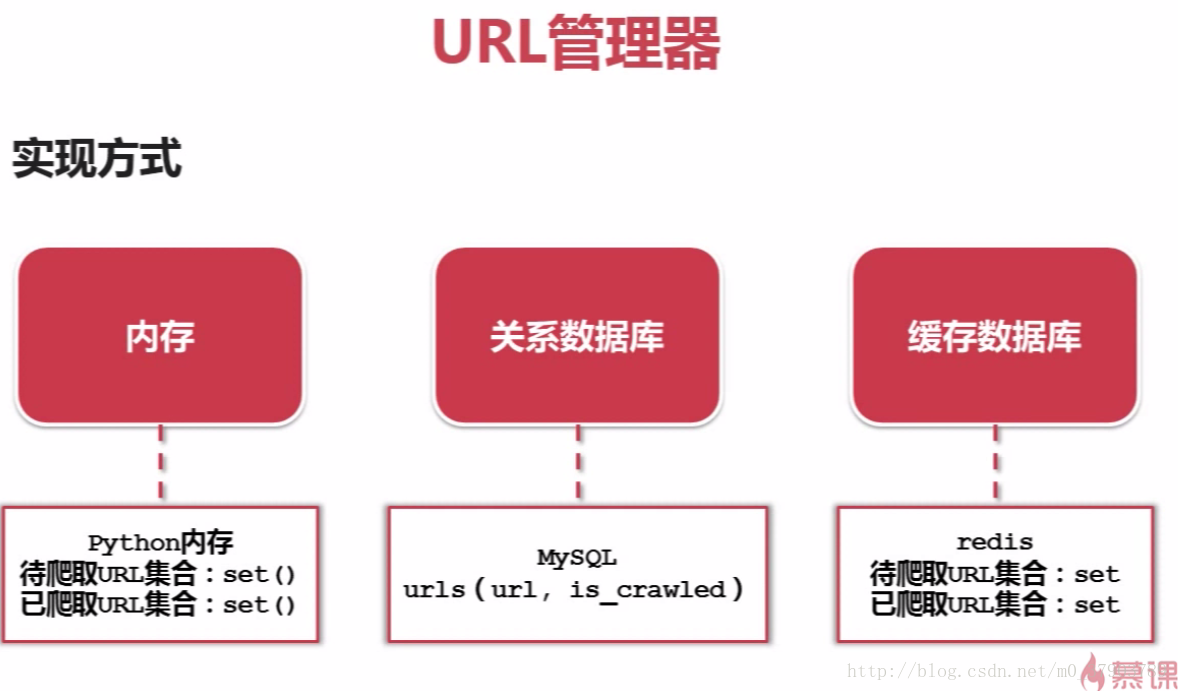
4.URL管理器
所谓的URL管理器,主要是由两个集合构成(待抓取URL集合和已抓取URL集合),其目的是为了防止重复抓取,循环抓取;
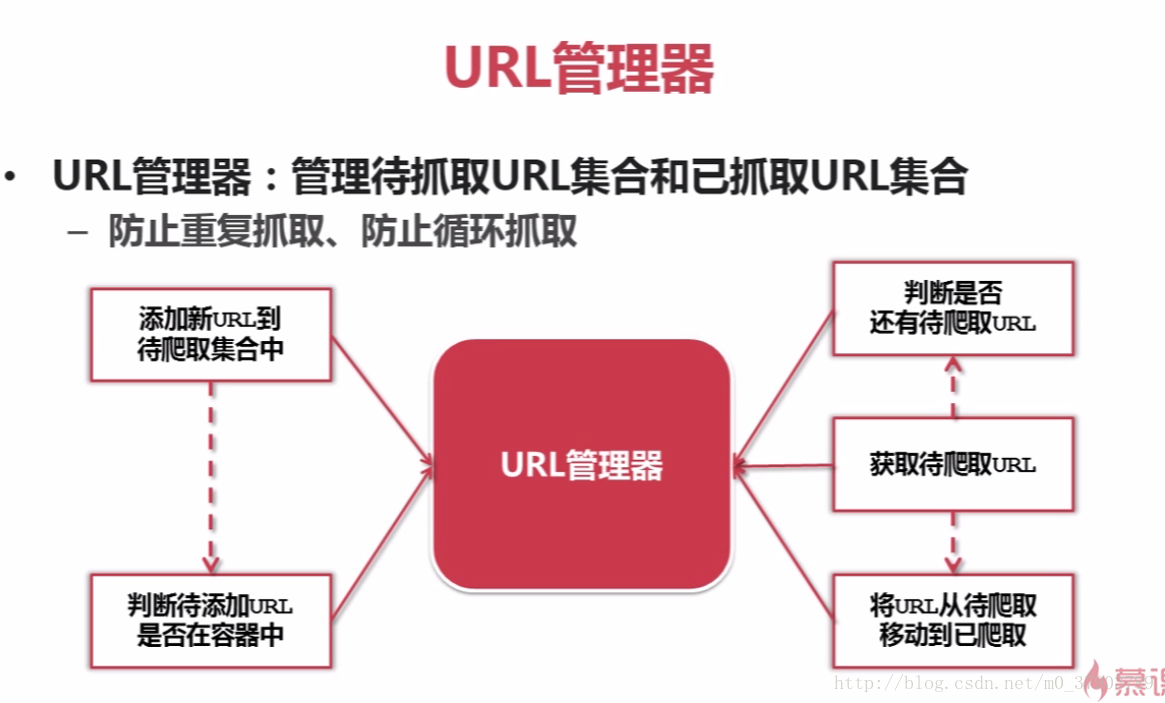
URL管理器的实现方式,分三种:a,Python内存(即集合);b,数据库(如MySQL,MongoDB等);c,缓存数据库
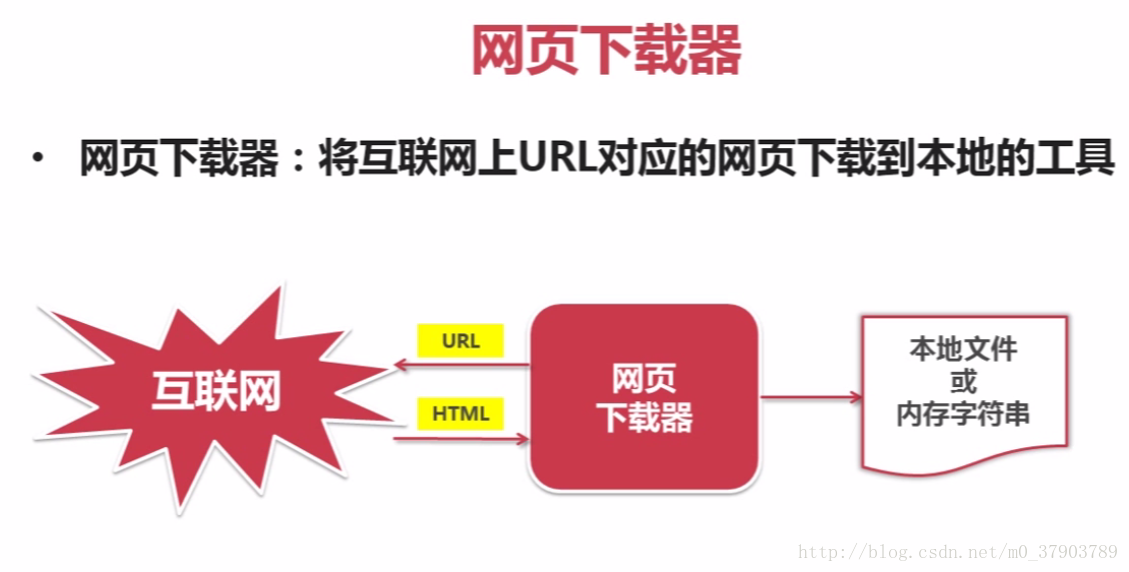
5.网页下载器
所谓网页下载器,即是将互联网上URL对应的网页下载到本地的工具
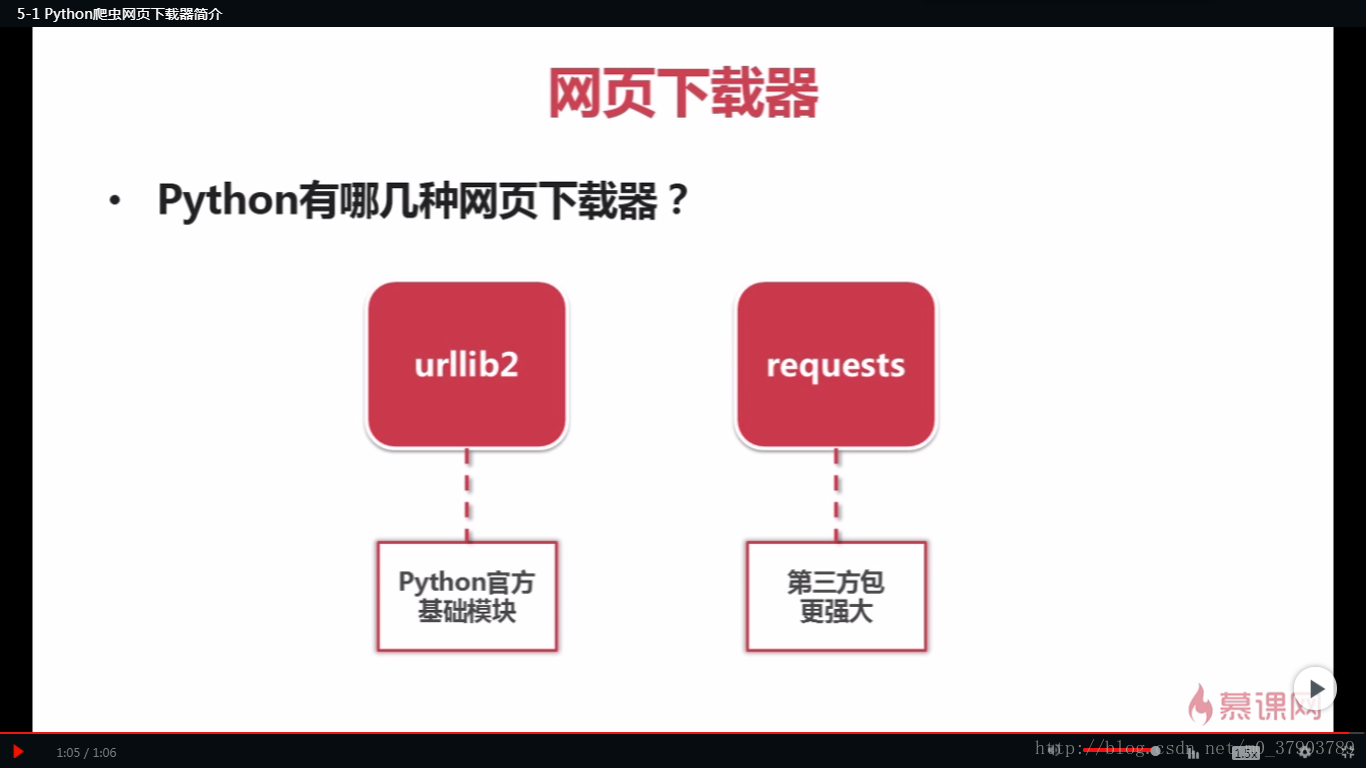
网页下载器,大致为request和urllib2两种;
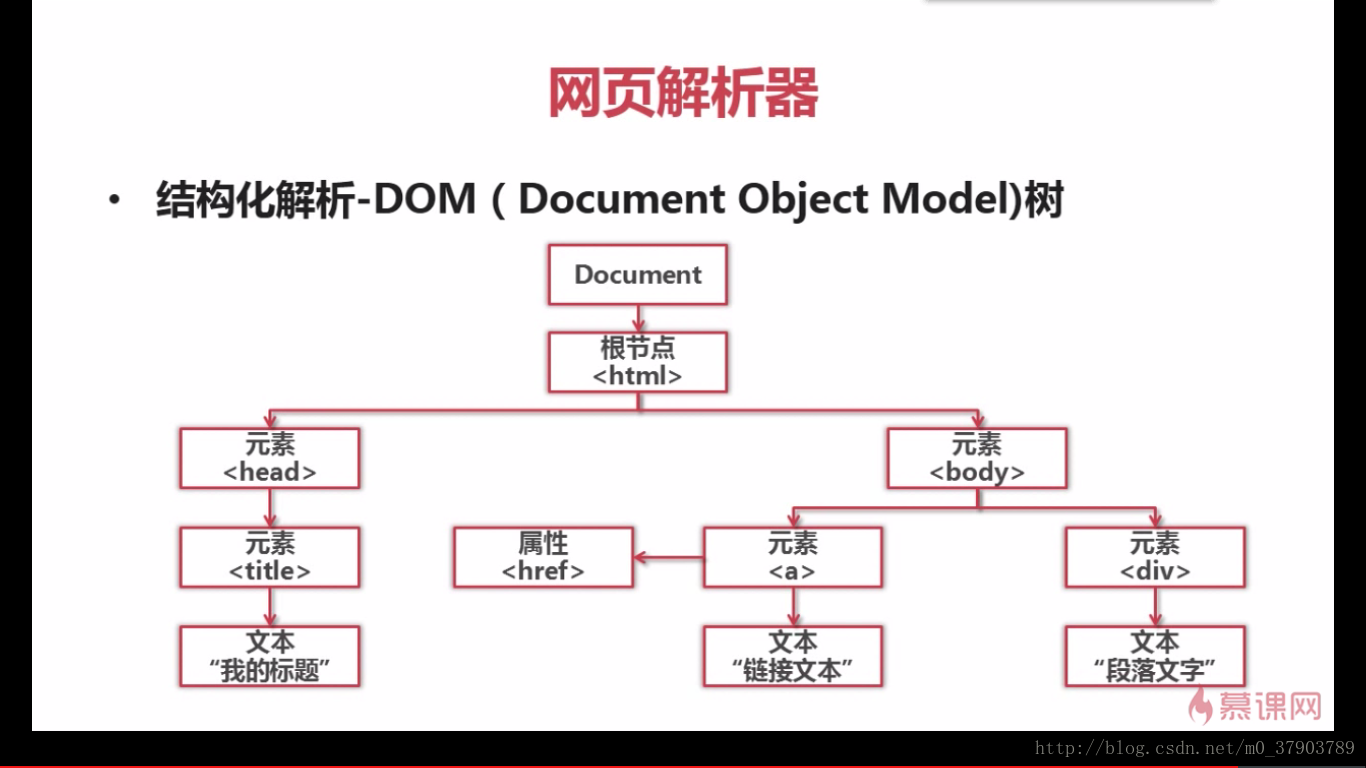
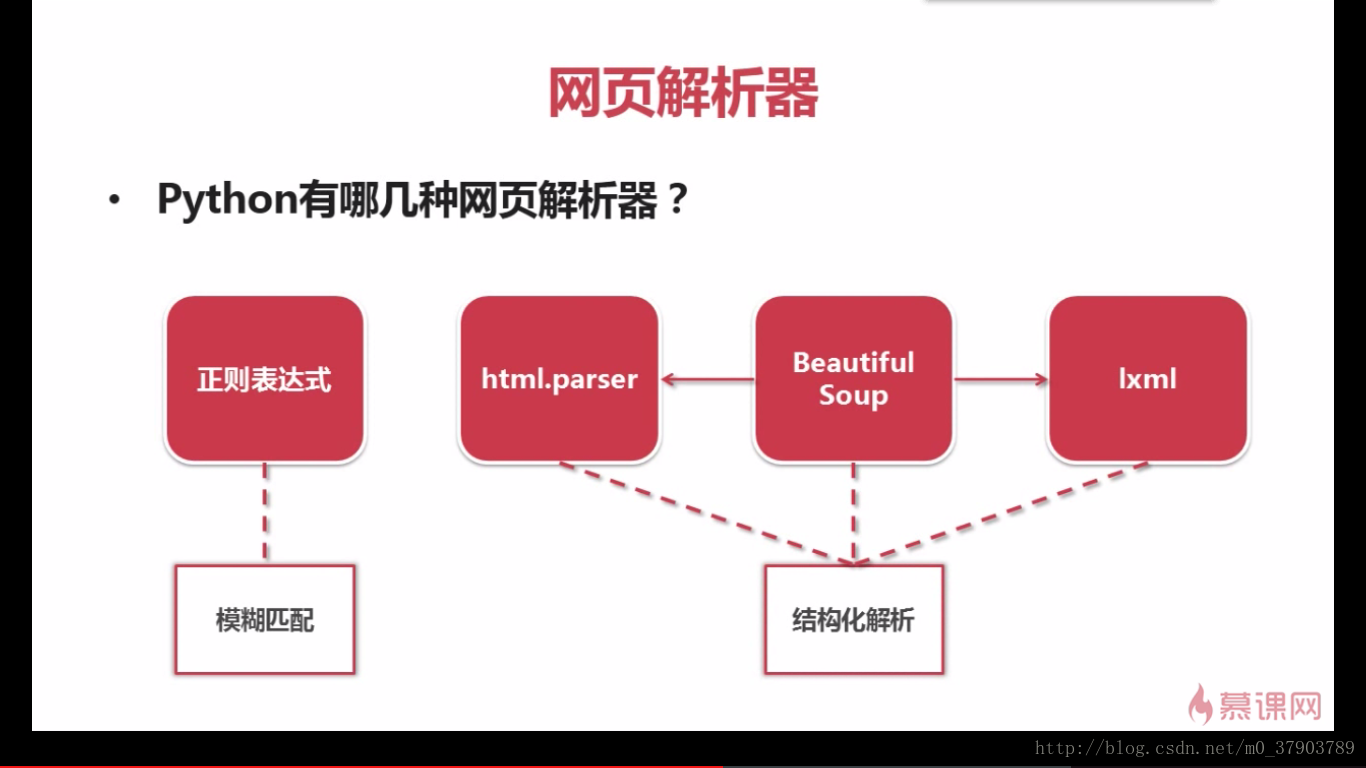
6.网页解析器
什么是网页解析器?
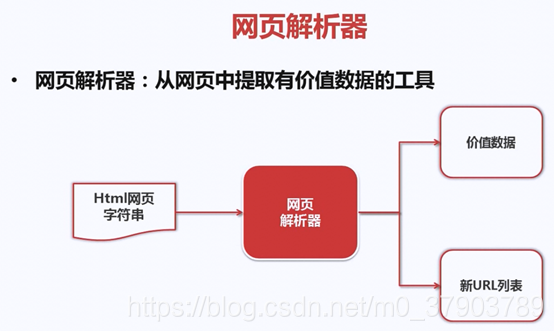
下面,我们来看看,如何解析一个网页文件
解析器种类: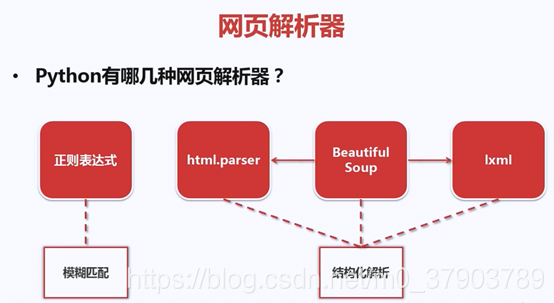
好了,通过以上的学习,我们掌握了Python爬虫的简单框架。那么怎样才能写一个好的python爬虫呢?又该如何去编写代码,实现我们的爬虫功能呢?下一步又该如何优化我们的爬虫代码呢?
(转)Python爬虫--通用框架的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- Python爬虫-pyspider框架的使用
pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优 ...
- Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50 一.Scrapy爬虫的基本命令 Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行. Scrapy命令行格式 Scrapy常用命令 采用 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
随机推荐
- 1.3.6、通过Path匹配
server: port: 8080 spring: application: name: gateway cloud: gateway: routes: - id: guo-system4 uri: ...
- linux学习之路第七天(时间日期类指令详解)
时间日期类 1.date指令 date指令 - 显示当前日期 基本语法 1)date (功能描述:显示当前时间): 2) date + %Y (功能描述:显示当前年份) 3)date+%m( 功能描述 ...
- 【重学Java】多线程基础(三种创建方式,线程安全,生产者消费者)
实现多线程 简单了解多线程[理解] 是指从软件或者硬件上实现多个线程并发执行的技术. 具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,提升性能. 并发和并行[理解] 并行:在同一时刻, ...
- 「AGC029C」Lexicographic constraints
「AGC029C」Lexicographic constraints 传送门 好像这个题非常 easy. 首先这个答案显然具有可二分性,所以问题转化为如何判定给定的 \(k\) 是否可行. 如果 \( ...
- python使用笔记10--os,sy模块
os操作文件,可以输入绝对路径,也可以输入相对路径 windows使用路径用\连接 Linux使用路径用/连接 但是我的电脑是windows 用/也没问题 1.os常用方法 1 import os 2 ...
- CentOS 7 文件权限之访问控制列表(ACL)
Linux的ACL是文件权限访问的一种手段.当拥有者所属组其他人(own,group,other)不能满足给一个单独的用户设置单独的权限时,ACL的出现就很好的解决了该问题. 比如其他用户own,不属 ...
- C语言:位运算符
异或 ^ 两个二进制位相同结果为0:不相同结果为1 1^1=0 1^0=1 0^1=1 0^0=1 按位或 | 两个二进制位 ...
- 用EXCEL打开CSV文件
1.打开EXCEL 2.数据--自文本--选择对应的CSV文件 3.设置表头所在的行(例如17行为表头)则输入17 4.确定分隔符 5.单击"确定"即可
- Function.identity()
Java 8允许在接口中加入具体方法.接口中的具体方法有两种,default方法和static方法,identity()就是Function接口的一个静态方法.Function.identity()返 ...
- 12. Mysql基础入门
课程大纲 • 数据库概述 • MySQL基本操作 • MySQL索引基础 • MySQL高级特性