Python实现各种排序算法的代码示例总结
在Python实践中,我们往往遇到排序问题,比如在对搜索结果打分的排序(没有排序就没有Google等搜索引擎的存在),当然,这样的例子数不胜数。《数据结构》也会花大量篇幅讲解排序。之前一段时间,由于需要,我复习了一下排序算法,并用Python实现了各种排序算法,放在这里作为参考。
最简单的排序有三种:插入排序,选择排序和冒泡排序。这三种排序比较简单,它们的平均时间复杂度均为O(n^2),在这里对原理就不加赘述了。贴出来源代码。
插入排序:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def insertion_sort(sort_list): iter_len = len(sort_list) if iter_len < 2: return sort_list for i in range(1, iter_len): key = sort_list[i] j = i - 1 while j >= 0 and sort_list[j] > key: sort_list[j+1] = sort_list[j] j -= 1 sort_list[j+1] = key return sort_list |
冒泡排序:
|
1
2
3
4
5
6
7
8
9
|
def bubble_sort(sort_list): iter_len = len(sort_list) if iter_len < 2: return sort_list for i in range(iter_len-1): for j in range(iter_len-i-1): if sort_list[j] > sort_list[j+1]: sort_list[j], sort_list[j+1] = sort_list[j+1], sort_list[j] return sort_list |
选择排序:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def selection_sort(sort_list): iter_len = len(sort_list) if iter_len < 2: return sort_list for i in range(iter_len-1): smallest = sort_list[i] location = i for j in range(i, iter_len): if sort_list[j] < smallest: smallest = sort_list[j] location = j if i != location: sort_list[i], sort_list[location] = sort_list[location], sort_list[i] return sort_list |
这里我们可以看到这样的句子:
sort_list[i], sort_list[location] = sort_list[location], sort_list[i]
不了解Python的同学可能会觉得奇怪,没错,这是交换两个数的做法,通常在其他语言中如果要交换a与b的值,常常需要一个中间变量temp,首先把a赋给temp,然后把b赋给a,最后再把temp赋给b。但是在python中你就可以这么写:a,
b = b, a,其实这是因为赋值符号的左右两边都是元组(这里需要强调的是,在python中,元组其实是由逗号“,”来界定的,而不是括号)。
平均时间复杂度为O(nlogn)的算法有:归并排序,堆排序和快速排序。
归并排序。对于一个子序列,分成两份,比较两份的第一个元素,小者弹出,然后重复这个过程。对于待排序列,以中间值分成左右两个序列,然后对于各子序列再递归调用。源代码如下,由于有工具函数,所以写成了callable的类:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class merge_sort(object): def _merge(self, alist, p, q, r): left = alist[p:q+1] right = alist[q+1:r+1] for i in range(p, r+1): if len(left) > 0 and len(right) > 0: if left[0] <= right[0]: alist[i] = left.pop(0) else: alist[i] = right.pop(0) elif len(right) == 0: alist[i] = left.pop(0) elif len(left) == 0: alist[i] = right.pop(0) def _merge_sort(self, alist, p, r): if p<r: q = int((p+r)/2) self._merge_sort(alist, p, q) self._merge_sort(alist, q+1, r) self._merge(alist, p, q, r) def __call__(self, sort_list): self._merge_sort(sort_list, 0, len(sort_list)-1) return sort_list |
堆排序,是建立在数据结构——堆上的。关于堆的基本概念、以及堆的存储方式这里不作介绍。这里用一个列表来存储堆(和用数组存储类似),对于处在i位置的元素,2i+1位置上的是其左孩子,2i+2是其右孩子,类似得可以得出该元素的父元素。
首先我们写一个函数,对于某个子树,从根节点开始,如果其值小于子节点的值,就交换其值。用此方法来递归其子树。接着,我们对于堆的所有非叶节点,自下而上调用先前所述的函数,得到一个树,对于每个节点(非叶节点),它都大于其子节点。(其实这是建立最大堆的过程)在完成之后,将列表的头元素和尾元素调换顺序,这样列表的最后一位就是最大的数,接着在对列表的0到n-1部分再调用以上建立最大堆的过程。最后得到堆排序完成的列表。以下是源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
class heap_sort(object): def _left(self, i): return 2*i+1 def _right(self, i): return 2*i+2 def _parent(self, i): if i%2==1: return int(i/2) else: return i/2-1 def _max_heapify(self, alist, i, heap_size=None): length = len(alist) if heap_size is None: heap_size = length l = self._left(i) r = self._right(i) if l < heap_size and alist[l] > alist[i]: largest = l else: largest = i if r < heap_size and alist[r] > alist[largest]: largest = r if largest!=i: alist[i], alist[largest] = alist[largest], alist[i] self._max_heapify(alist, largest, heap_size) def _build_max_heap(self, alist): roop_end = int(len(alist)/2) for i in range(0, roop_end)[::-1]: self._max_heapify(alist, i) def __call__(self, sort_list): self._build_max_heap(sort_list) heap_size = len(sort_list) for i in range(1, len(sort_list))[::-1]: sort_list[0], sort_list[i] = sort_list[i], sort_list[0] heap_size -= 1 self._max_heapify(sort_list, 0, heap_size) return sort_list |
最后一种要说明的交换排序算法(以上所有算法都为交换排序,原因是都需要通过两两比较交换顺序)自然就是经典的快速排序。
先来讲解一下原理。首先要用到的是分区工具函数(partition),对于给定的列表(数组),我们首先选择基准元素(这里我选择最后一个元素),通过比较,最后使得该元素的位置,使得这个运行结束的新列表(就地运行)所有在基准元素左边的数都小于基准元素,而右边的数都大于它。然后我们对于待排的列表,用分区函数求得位置,将列表分为左右两个列表(理想情况下),然后对其递归调用分区函数,直到子序列的长度小于等于1。
下面是快速排序的源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class quick_sort(object): def _partition(self, alist, p, r): i = p-1 x = alist[r] for j in range(p, r): if alist[j] <= x: i += 1 alist[i], alist[j] = alist[j], alist[i] alist[i+1], alist[r] = alist[r], alist[i+1] return i+1 def _quicksort(self, alist, p, r): if p < r: q = self._partition(alist, p, r) self._quicksort(alist, p, q-1) self._quicksort(alist, q+1, r) def __call__(self, sort_list): self._quicksort(sort_list, 0, len(sort_list)-1) return sort_list |
细心的朋友在这里可能会发现一个问题,如果待排序列正好是顺序的时候,整个的递归将会达到最大递归深度(序列的长度)。而实际上在操作的时候,当列表长度大于1000(理论值)的时候,程序会中断,报超出最大递归深度的错误(maximum
recursion depth
exceeded)。在查过资料后我们知道,Python在默认情况下,最大递归深度为1000(理论值,其实真实情况下,只有995左右,各个系统这个值的大小也不同)。这个问题有两种解决方案,1)重新设置最大递归深度,采用以下方法设置:
|
1
2
|
import sys sys.setrecursionlimit(99999) |
2)第二种方法就是采用另外一个版本的分区函数,称为随机化分区函数。由于之前我们的选择都是子序列的最后一个数,因此对于特殊情况的健壮性就差了许多。现在我们随机从子序列选择基准元素,这样可以减少对特殊情况的差错率。新的randomize
partition函数如下:
|
1
2
3
4
|
def _randomized_partition(self, alist, p, r): i = random.randint(p, r) alist[i], alist[r] = alist[r], alist[i] return self._partition(alist, p, r) |
完整的randomize_quick_sort的代码如下(这里我直接继承之前的quick_sort类):
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import random class randomized_quick_sort(quick_sort): def _randomized_partition(self, alist, p, r): i = random.randint(p, r) alist[i], alist[r] = alist[r], alist[i] return self._partition(alist, p, r) def _quicksort(self, alist, p, r): if p<r: q = self._randomized_partition(alist, p, r) self._quicksort(alist, p, q-1) self._quicksort(alist, q+1, r) |
关于快速排序的讨论还没有结束。我们都知道,Python是一门很优雅的语言,而Python写出来的代码是相当简洁而可读性极强的。这里就介绍快排的另一种写法,只需要三行就能够搞定,但是又不失阅读性。(当然,要看懂是需要一定的Python基础的)代码如下:
|
1
2
3
4
5
6
|
def quick_sort_2(sort_list): if len(sort_list)<=1: return sort_list return quick_sort_2([lt for lt in sort_list[1:] if lt<sort_list[0]]) + \ sort_list[0:1] + \ quick_sort_2([ge for ge in sort_list[1:] if ge>=sort_list[0]]) |
怎么样看懂了吧,这段代码出自《Python cookbook 第二版》,这种写法展示出了列表推导的强大表现力。
对于比较排序算法,我们知道,可以把所有可能出现的情况画成二叉树(决策树模型),对于n个长度的列表,其决策树的高度为h,叶子节点就是这个列表乱序的全部可能性为n!,而我们知道,这个二叉树的叶子节点不会超过2^h,所以有2^h>=n!,取对数,可以知道,h>=logn!,这个是近似于O(nlogn)。也就是说比较排序算法的最好性能就是O(nlgn)。
那有没有线性时间,也就是时间复杂度为O(n)的算法呢?答案是肯定的。不过由于排序在实际应用中算法其实是非常复杂的。这里只是讨论在一些特殊情形下的线性排序算法。特殊情形下的线性排序算法主要有计数排序,桶排序和基数排序。这里只简单说一下计数排序。
计数排序是建立在对待排序列这样的假设下:假设待排序列都是正整数。首先,声明一个新序列list2,序列的长度为待排序列中的最大数。遍历待排序列,对每个数,设其大小为i,list2[i]++,这相当于计数大小为i的数出现的次数。然后,申请一个list,长度等于待排序列的长度(这个是输出序列,由此可以看出计数排序不是就地排序算法),倒序遍历待排序列(倒排的原因是为了保持排序的稳定性,及大小相同的两个数在排完序后位置不会调换),假设当前数大小为i,list[list2[i]-1]
= i,同时list2[i]自减1(这是因为这个大小的数已经输出一个,所以大小要自减)。于是,计数排序的源代码如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class counting_sort(object): def _counting_sort(self, alist, k): alist3 = [0 for i in range(k)] alist2 = [0 for i in range(len(alist))] for j in alist: alist3[j] += 1 for i in range(1, k): alist3[i] = alist3[i-1] + alist3[i] for l in alist[::-1]: alist2[alist3[l]-1] = l alist3[l] -= 1 return alist2 def __call__(self, sort_list, k=None): if k is None: import heapq k = heapq.nlargest(1, sort_list)[0] + 1 return self._counting_sort(sort_list, k) |
各种排序算法介绍完(以上的代码都通过了我写的单元测试),我们再回到Python这个主题上来。其实Python从最早的版本开始,多次更换内置的排序算法。从开始使用C库提供的qsort例程(这个方法有相当多的问题),到后来自己开始实现自己的算法,包括2.3版本以前的抽样排序和折半插入排序的混合体,以及最新的适应性的排序算法,代码也由C语言的800行到1200行,以至于更多。从这些我们可以知道,在实际生产环境中,使用经典的排序算法是不切实际的,它们仅仅能做学习研究之用。而在实践中,更推荐的做法应该遵循以下两点:
当需要排序的时候,尽量设法使用内建Python列表的sort方法。
当需要搜索的时候,尽量设法使用内建的字典。
我写了测试函数,来比较内置的sort方法相比于以上方法的优越性。测试序列长度为5000,每个函数测试3次取平均值,可以得到以下的测试结果:
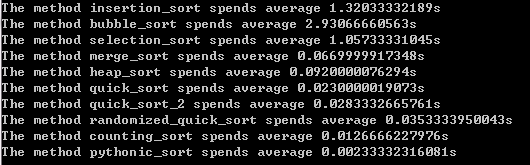
可以看出,Python内置函数是有很大的优势的。因此在实际应用时,我们应该尽量使用内置的sort方法。
由此,我们引出另外一个问题。怎么样判断一个序列中是否有重复元素,如果有返回True,没有返回False。有人会说,这不很简单么,直接写两个嵌套的迭代,遍历就是了。代码写下来应该是这样。
|
1
2
3
4
5
6
7
|
def normal_find_same(alist): length = len(alist) for i in range(length): for j in range(i+1, length): if alist[i] == alist[j]: return True return False |
这种方法的代价是非常大的(平均时间复杂度是O(n^2),当列表中没有重复元素的时候会达到最坏情况),由之前的经验,我们可以想到,利用内置sort方法极快的经验,我们可以这么做:首先将列表排序,然后遍历一遍,看是否有重复元素。包括完整的测试代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import time import random def record_time(func, alist): start = time.time() func(alist) end = time.time() return end - start def quick_find_same(alist): alist.sort() length = len(alist) for i in range(length-1): if alist[i] == alist[i+1]: return True return False if __name__ == "__main__": methods = (normal_find_same, quick_find_same) alist = range(5000) random.shuffle(alist) for m in methods: print 'The method %s spends %s' % (m.__name__, record_time(m, alist)) |
运行以后我的数据是,对于5000长度,没有重复元素的列表,普通方法需要花费大约1.205秒,而快速查找法花费只有0.003秒。这就是排序在实际应用中的一个例子。
Python实现各种排序算法的代码示例总结的更多相关文章
- Python实现八大排序算法(转载)+ 桶排序(原创)
插入排序 核心思想 代码实现 希尔排序 核心思想 代码实现 冒泡排序 核心思想 代码实现 快速排序 核心思想 代码实现 直接选择排序 核心思想 代码实现 堆排序 核心思想 代码实现 归并排序 核心思想 ...
- Python实现常用排序算法
Python实现常用排序算法 冒泡排序 思路: 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完 ...
- 用python实现各种排序算法
最简单的排序有三种:插入排序,选择排序和冒泡排序.它们的平均时间复杂度均为O(n^2),在这里对原理就不加赘述了. 贴出源代码: 插入排序: def insertion_sort(sort_list) ...
- python实现八大排序算法
插入排序 核心思想 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的.个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为 O(n^2).是稳定的排序方法.插入算法 ...
- 使用Python处理Excel文件的一些代码示例
笔记:使用Python处理Excel文件的一些代码示例,以下代码来自于<Python数据分析基础>一书,有删改 #!/usr/bin/env python3 # 导入读取Excel文件的库 ...
- 使用Python处理CSV文件的一些代码示例
笔记:使用Python处理CSV文件的一些代码示例,来自于<Python数据分析基础>一书,有删改 # 读写CSV文件,不使用CSV模块,仅使用基础Python # 20181110 wa ...
- 排序算法Java代码实现(一)—— 选择排序
以下几篇随笔都是记录的我实现八大排序的代码,主要是贴出代码吧,讲解什么的都没有,主要是为了方便我自己复习,哈哈,如果看不明白,也不要说我坑哦! 本片分为两部分代码: 常用方法封装 排序算法里需要频繁使 ...
- python 的常见排序算法实现
python 的常见排序算法实现 参考以下链接:https://www.cnblogs.com/shiluoliming/p/6740585.html 算法(Algorithm)是指解题方案的准确而完 ...
- 【Python】常用排序算法的python实现和性能分析
作者:waterxi 原文链接 背景 一年一度的换工作高峰又到了,HR大概每天都塞几份简历过来,基本上一天安排两个面试的话,当天就只能加班干活了.趁着面试别人的机会,自己也把一些基础算法和一些面试题整 ...
随机推荐
- oracle: tochar(sysdate,'D')函数
学习oracle时碰到tochar(sysdate,'D')函数,但是发现并不是星期几,如今天是20150317,周二,但是得到的值为3 开始以为是系统日期什么的原因,试了试 select to_ch ...
- iOS 1-2年经验面试参考题
Model层: 数据持久化存储方案有哪些? 沙盒的目录结构是怎样的?各自一般用于什么场合? SQL语句问题:inner join.left join.right join的区别是什么? SQLite的 ...
- Did not find handler method for springMVC资源文件扫描不到---关于spring的那些坑
今天将项目的spring版本升级到4.2.5版本后,登录首页发现资源文件全部访问不到,页面彻底挂掉: 查找原因,后来又查找spring的更新文档后,才确认下来原来是mvc-dispatcher-ser ...
- 如何确定某个counter对应的rrd文件
info.py #!/usr/bin/env python import requests import json import sys d = [ { "endpoint": s ...
- 利用tween,使用原生js实现模块回弹动画效果
最近有一个需求,就是当屏幕往下一定像素时,下方会有一个隐藏的模块马上显现出来,向上运动后带有回弹效果.然后屏幕滚回去时这个模块能够原路返回 其实这个效果css3就可以很轻松实现,但是公司要求最低兼容i ...
- WEB压力测试工具Pylot试用
Pylot介绍 转载自[http://www.freehao123.com/pylot-web/] 为了能够准确地评估网站服务器对网络流量的承受能力,我们一般会采取模拟网站用户访问,通过不断地增加并发 ...
- mac上mysql乱码问题解决
一.mysql出现乱码问题: 出现的问题是下图这样的乱码问题,我是使用java在做练习的时候发现出现字符集编码问题的: 当时是使用jdbc来添加的数据,我的jdbc包括web前端后端的编码都是设置的是 ...
- 产品Backlog
产品BACKLOG ID Name Imp Est How to demo Notes 1 界面(首页.订单.资料) 50 2 进入界面,选择需要的界面 使用分栏界面 2 首页里的功能按钮 40 6 ...
- JDBC-java访问数据库
定义:JDBC是一个独立于数据库管理系统的,通用的SQL数据库存取和操作的公共接口 (由JAVA类和接口组成,接口由各数据库厂家负责实现) 使用方法: 1.加载驱动 Class.forName(&qu ...
- AJAX-----07XMLHttpRequest对象的处理返回的JSON类型数据
要玩json首先就需要知道一般都数据是怎么处理的: <!DOCTYPE html> <html lang="en"> <head> <me ...