【CDN+】Kafka 的初步认识与入门
前言
项目中用到了Kafka 这种分布式消息队列来处理日志,本文将对Kafka的基本概念和原理做一些简要阐释
Kafka 的基本概念
官网解释:
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
消息处理方式有点对点,发布-订阅模式,Kafka就是一种发布-订阅模式。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展
那么我们就从Kafka的消息队列处理模式开始,逐步了解它的原理和构成。
Kafka 的消息处理模式
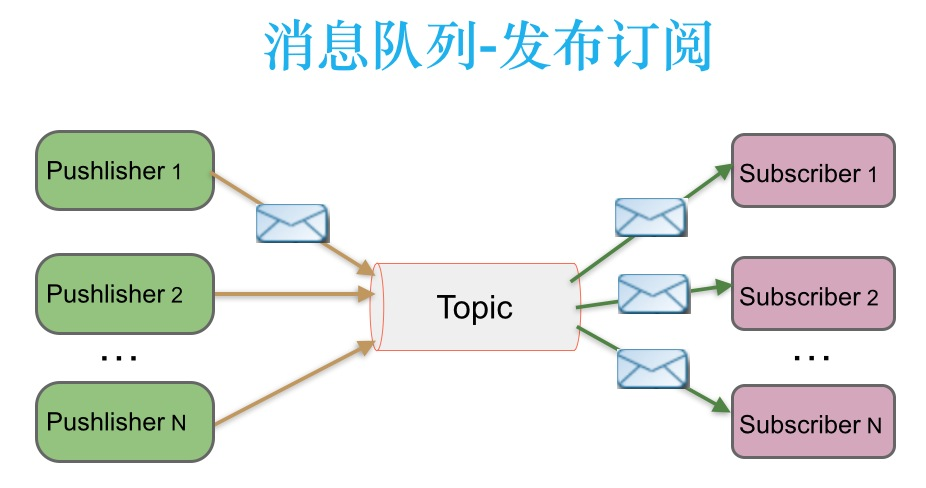
如上图所示,消息被持久化到一个topic中。消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者(producers)称为发布者,消费者(consumers)称为订阅者。
Kafka中的生产者-消费者模型
Producers : 主要数据来源是各种日志,mysql-source, Ngnix-source ,Hive,HDFS,各种数据库等等
Consumers: Spark 处理日志格式,内容等等,继续下发到Kylin
Brokers:服务器节点称为broker,指的是下图中间的kafka cluster,负责存储消息,是由多个server组成的集群。

Kafka中的Topic与Partition
上面的生产-消费模型里面提到了kafka里面的基本概念topic和partition ,那么它们是什么呢?
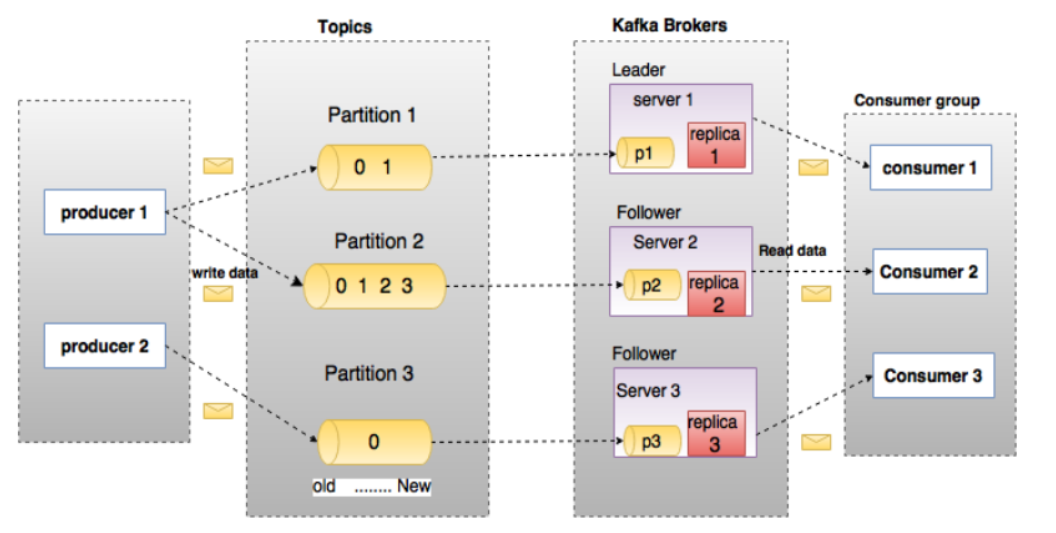
Topic:
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
类似于数据库的表名
Partition:
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Broker:
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Consumer Group:
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Consumer:
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Leader:
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower:
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
思考与总结:
Kafka 的高可用性原理就是基于:producer--topic--partition--broker(Leader--follower copy)--consumer 这个流程
数据源统一使用topic 进行分类,Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。
同时为了提高Kafka的容错能力,也需要将同一个Partition的Replica尽量分散到不同的机器。实际上,如果所有的Replica都在同一个Broker上,那一旦该Broker宕机,该Partition的所有Replica都无法工作,也就达不到HA(High Availability)的效果。同时,如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。
Kafka分配Replica的算法如下:
1.将所有Broker(假设共n个Broker)和待分配的Partition排序
2.将第i个Partition分配到第(i mod n)个Broker上
3.将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
如果要进一步学习Kafka ,建议自己进行搭建,参考: https://www.jianshu.com/p/5297773fcc1b
原理学习参考博客: https://www.cnblogs.com/qingyunzong/p/9004509.html
【CDN+】Kafka 的初步认识与入门的更多相关文章
- Erlang 编写 Kafka 客户端之最简单入门
Erlang 编写 Kafka 客户端之最简单入门 费劲周折,终于测通了 erlang 向kafka 发送消息,使用了ekaf 库,参考: An advanced but simple to use, ...
- 《KAFKA官方文档》入门指南(转)
1.入门指南 1.1简介 Apache的Kafka™是一个分布式流平台(a distributed streaming platform).这到底意味着什么? 我们认为,一个流处理平台应该具有三个关键 ...
- 沉淀,再出发:jQuery的初步了解和入门
沉淀,再出发:jQuery的初步了解和入门 一.前言 对于后端开发者来说,是不是真的不需要了解前端的开发经过和相关技术,从我个人的角度来说,我觉得如果不了解或者接触很少,极有可能造成开发的时候 ...
- Kafka(一)【概述、入门、架构原理】
目录 一.Kafka概述 1.1 定义 二.Kafka快速入门 2.1 安装部署 2.2 配置文件解析 2.3Kafka群起脚本 2.4 topic(增删改查) 2.5 生产和消费者命令行操作 三.K ...
- kafka第四篇--快速入门(如何使用kafka)
Quick Start Step 1: Download the code Download the 0.8 release. > tar xzf kafka-<VERSION>.t ...
- Kafka学习笔记2: 快速入门
在开始Kafka环境搭建之前,首先要安装Linux系统,并在Linux系统上安装JDK1.8版本,关于linux虚拟机的安装和linux系统下jdk的安装可以参考我的博文: http://blog.c ...
- kafka扫盲笔记,实战入门
Kafka作为大数据时代的产物,自有其生存之道.让我们跟随扫盲班的培训,进行大致了解与使用kafka吧.(平时工作有使用不代表就知道kafka了哟) 1. kafka介绍 1.1. 拥有的能力(能干什 ...
- 分布式消息系统Kafka初步
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
- 分布式消息系统Kafka初步(一) (赞)
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
随机推荐
- Robot Framework课件汇总
http://www.testclass.net/rf/ 测试教程网http://www.testclass.net/all
- MYSQL的ACID
原子性 (Atomicity) 原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做. 隔离性 (Isolation) 隔离性是指多个事务并发执行的时候,事务内部的操作与其他事务 ...
- JavaSE编码试题强化练习7
1.编写应用程序,创建类的对象,分别设置圆的半径.圆柱体的高,计算并分别显示圆半径.圆面积.圆周长,圆柱体的体积. /** * 圆类 */ public class Circle { /** * 类属 ...
- linux shell中的正则表达式
正则表达式的使用 正则表达式,又称规则表达式.(英语:Regular Expression [ˈreɡjulə] 规则的 [ iksˈpreʃən] 表达 ),在代码中常简写为regex.regexp ...
- SpringBoot内嵌数据库的使用(H2)
配置数据源(DataSource) Java的javax.sql.DataSource接口提供了一个标准的使用数据库连接的方法. 传统做法是, 一个DataSource使用一个URL以及相应的证书去构 ...
- org.apache.ibatis.exceptions.PersistenceException: ### Error querying database. Cause: java.lang.NumberFormatException: For input string: "W%" ### Cause: java.lang.NumberFormatException: For input s
一个常见的myBatis xml文件中的引号错误: org.apache.ibatis.exceptions.PersistenceException: ### Error querying data ...
- MongoDB 基本操作(增改删)
1.插入数据 和关系型数据库一样,增加数据记录可以使用insert语句,这是很简单的. 当插入数据时,如果此集合不存在,则MongoDB系统会自动创建一个集合,即不需要刻意预先创建集合 每次插入数据时 ...
- 浏览器输入url按回车背后经历了哪些?
在PC浏览器的地址栏输入一串URL,然后按Enter键这个页面渲染出来,这个过程中都发生了什么事? 1.首先,在浏览器地址栏中输入url,先解析url,检测url地址是否合法2.浏览器先查看浏览器缓存 ...
- 攻防世界--simple-check-100
测试文件:https://adworld.xctf.org.cn/media/task/attachments/2543a3658d254c30a89e4ea7b8950c27.zip 这道题很坑了, ...
- 使用Python和AWK两种方式实现文本处理的长拼接案例
最近由于业务系统新需求的需要,我们平台需要将供应商G提供一类数据转换格式后提供给客户K.比较头疼是供应商G提供的数据都是在Windows下使用Excel存储的,而客户K先前与我们相关对接人员商定的数据 ...