基于Redis做内存管理
1 Redis存储机制:
redis存储的数据类型包括,String,Hash,List,Set,Sorted Set,它内部使用一个redisObject对象来表示所有的key和value,这个对象基本结构见下:
typedef struct redisObject {
unsigned type, // 4字节,数据类型
unsigned encoding, // 4字节,编码方式
unsigned lru, // 24字节,置换算法
int refcount, // 对象引用计数
void *ptr // 数据具体存储的指向
} robj;
type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,这么表示主要是为了给Redis不同数据类型提供一个统一的管理接口。
String是最常用的一种类型,是最普通的key/value的hash存储,读写的时间复杂度都是O(1)。
Hash存储会在基本kv的hash里再创建一层hash,两层hash结构,取值时可以直接通过ID+key的方式取到value,读写的时间复杂度都是O(1)。
List存储的是一个双向链表,即可以支持反向查找和遍历,查询插入一个数据的时间复杂度为O(n),如果是在最后添加或弹出则为O(1)。
Set存储的是一个自动去重的List,内部实现Set存储的是一个值为null的map,所以Set支持直接判定值的存在性,Set读写的时间复杂度都是O(1)。
Sorted Set存储的是按用户的指定的分数排序的Set,Sorted Set存储采用了一个跳表,和一个hash,跳表存储了所有数据,hash存储数据和分数的关系。Sorted Set读写主要是从跳表中查询数据或位置的复杂度,为O(log(n))。
8.2 Redis内存管理机制:
内存控制:
Redis通过控制内存上限和回收策略实现内存管理,使用maxmemory参数限制最大可用内存,比如我们的nfvo就是设置的512mb,代表我们最大不能存储超过512mb的数据。
对于过期的数据,redis有两种方式释放内存,一个是惰性删除,在下次查询某key的时候先检查超时时间,如果已超时则删除数据并返回空;另一个是定时任务,默认每10秒一次(可以同hz参数配置,我们使用的默认配置10),检查超时时间,超时则删除。
对于溢出的数据,有几种处理方式,可通过maxmemory-policy配置。
1、noeviction,不删除,拒绝新插入的消息。
2、volatile-lru,根据LRU(最近最少使用)置换算法,对于配置了超时时间的数据进行清理,这个也是我们目前配置的清理策略,巴展时期经常出现数据丢失的情况就是由于这个策略的存在,所以在使用时因小心。
3、allkeys-lru,根据LRU(最近最少使用)置换算法,对于所有数据进行清理,直到内存满足需要。
4、allkeys-random,随机删除所有key,直到满足内存需要。
5、volatile-random,随机删除配置了超时时间的key,直到满足内存需要。
6、volatile-ttl,根据键对象的生存时间属性,删除最近将要过期的数据。
当客户端执行一条新命令,导致数据库需要增加数据(比如set key value),Redis会检查内存使用,如果内存使用超过maxmemory,就会按照置换策略删除一些key来给新数据准备存储区。
Redis还会通过对大小数据的不同处理来节约内存,比如上面提到的redis的几个类型,list,set,map,在数据量小的时候Redis会采用线性紧凑存储来节省空间,数据量多大这个是可配置的:
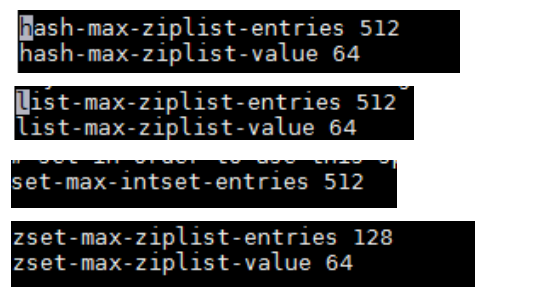
entries含义是当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,value含义是当value这个Map内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间,这个值不能无限扩大,因为线性存储意味着线性查找,数据少是效率没问题,数据量大的时候如果采用这种方式会降低查询效率。
8.3 Redis持久化机制:
Redis一共支持四种持久化方式,分别是:定时快照方式(snapshot),基于语句追加文件的方式(aof),虚拟内存(vm),Diskstore方式。主要使用的是前两种,vm方式甚至已经被废弃掉了,而Diskstore也只是在实验阶段,也就是说,Redis目前还是作为内存数据库使用,数据量不允许很大。
定时快照方式实际是在 Redis 内部一个定时器事件,每隔固定时间去检查当前数据发生的改变次数与时间是否满足配置的持久化触发的条件,如果满足则通过操作系统 fork 调用来创建出一个子进程,这个子进程默认会与父进程共享相同的地址空间,这时就可以通过子进程来遍历整个内存来进行存储操作,而主进程则仍然可以提供服务,当有写入时由操作系统按照内存页(page)为单位来进行copy-on-write保证父子进程之间不会互相影响。该持久化的主要缺点是定时快照只是代表一段时间内的内存映像,所以系统重启会丢失上次快照与重启之间所有的数据。定时快照方式根据redis.conf中配置的save的时间间隔去检查当前数据改变次数和时间是否满足配置,如果满足则从父进程fork(copy-on-write机制)出一个子进程,通过该子进程遍历内存来转换成rdb文件,在redis.conf里见下:
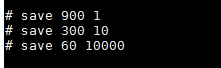
分别代表900秒内1个key变化,300秒内10个key,60秒内10000个key触发,由于我们的nfvo和vnfm由于每次都会清理Redis,并未用到其持久化机制,所以配置被注掉了。
aof方式每条会使Redis内存数据发生改变的命令都会追加到一个log文件中,也就是说这个log文件就是Redis的持久化数据,aof的方式的主要缺点是追加log文件可能导致体积过大,当系统重启恢复数据时如果是aof的方式则加载数据会非常慢,因为读取的所有命令都要在内存中执行一遍。另外由于每条命令都要写log,所以使用aof的方式,Redis的读写性能也会有所下降。aof有三种模式调用fsync写入磁盘,fsync函数可以同步内存中所有已修改的文件数据到储存设备,1、总是写入,即每次有变更都调用fsync写入;2、每秒调用fsync写入一次;3、不主动调用fsync同步数据到磁盘,而是依赖os的定时fsync写入,一般为30秒,不推荐。aof方式在redis.conf内配置见下:

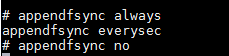
appendonly代表是否开启AOF,我们并未开启,appendfilename是文件名,appendfsync是写入模式。
基于Redis做内存管理的更多相关文章
- ML2021 | (腾讯)PatrickStar:通过基于块的内存管理实现预训练模型的并行训练
前言 目前比较常见的并行训练是数据并行,这是基于模型能够在一个GPU上存储的前提,而当这个前提无法满足时,则需要将模型放在多个GPU上.现有的一些模型并行方案仍存在许多问题,本文提出了一种名为 ...
- 基于 Redis 做分布式锁
基于 REDIS 的 SETNX().EXPIRE() 方法做分布式锁 setnx() setnx 的含义就是 SET if Not Exists,其主要有两个参数 setnx(key, value) ...
- 深入redis内部--内存管理
1. Redis内存管理通过在zmalloc.h和zmalloc.c中重写c语言对内存的管理来完成的. redis内存管理 c内存管理 原型 作用 zmalloc malloc void *mallo ...
- 基于STM32F429的内存管理
1.内存管理介绍 内存管理,是指软件运行时对计算机内存资源的分配和使用的技术.其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源. 内存管理的实现方法有很多种,他们其实最终都是要 ...
- 为什么说Python采用的是基于值的内存管理模式?
Python中的变量并不直接存储值,而是存储了值的内存地址或者引用,假如为不同变量赋值为相同值,这个值在内存中只有一份,多个变量指向同一块内存地址.
- redis源码解析之内存管理
zmalloc.h的内容如下: void *zmalloc(size_t size); void *zcalloc(size_t size); void *zrealloc(void *ptr, si ...
- redis源码笔记-内存管理zmalloc.c
redis的内存分配主要就是对malloc和free进行了一层简单的封装.具体的实现在zmalloc.h和zmalloc.c中.本文将对redis的内存管理相关几个比较重要的函数做逐一的介绍 参考: ...
- Redis的持久化机制与内存管理机制
1.概述 Redis的持久化机制有两种:RDB 和 AOF ,这两种机制有什么区别?正式环境应该采用哪种机制? 我们的服务器内存资源是有限的,如果内存被Redis的缓存占满了怎么办?这就要看Redis ...
- 内存管理内幕mallco及free函数实现
原文:https://www.ibm.com/developerworks/cn/linux/l-memory/ 为什么必须管理内存 内存管理是计算机编程最为基本的领域之一.在很多脚本语言中,您不必担 ...
随机推荐
- http协议的深刻理解
https://www.cnblogs.com/mayite/p/9095986.html
- Oracle Or子句
Oracle Or子句 作者:初生不惑 Oracle基础 评论:0 条 Oracle技术QQ群:175248146 在本教程中,我们来学习如何使用Oracle OR运算符来组合两个或更多的布尔表达式. ...
- Xcode Server持续集成
这是一篇2017-11-12 年我还在 ezbuy 的一篇文章,时间过去很早了,最近在整理笔记的时候发现了, 同步过来,文章内容现在是否有效不确定,应该大差不差,读者仅做参考 最后更新 2017-11 ...
- SpringBoot 集成 Spring Session
SpringBoot 集成 Spring Session 应该讲解清楚,为什么要使用 Redis 进行 Session 的管理. Session 复制又是什么概念. Spring Session 在汪 ...
- java虚拟机规范-运行时数据区
前言 java虚拟机是java跨平台的基石,本文的描述以jdk7.0为准,其他版本可能会有一些微调. 引用 java虚拟机规范 数据类型 java总共有两种数据类型:基本类型和引用类型.java虚拟机 ...
- Hibernate入门简介
什么是Hibernate框架? Hibernate是一种ORM框架,全称为 Object_Relative DateBase-Mapping,在Java对象与关系数据库之间建立某种映射,以实现直接存取 ...
- 【C++进阶:STL常见性质3】
STL3个代表性函数:for_each(), random_shuffle(), sort() vector<int> stuff; random_shuffle(stuff.begin( ...
- C#之委托(二)
其实在上一篇委托(一)中,创建委托还是太繁琐了点.代码量过多,可能会妨碍我们对代码和逻辑的理解.有些时候可能处理逻辑的代码都笔声明委托的代码要少,这就不可避免的增加了重复代码的量.所以在c#2中极大的 ...
- yolov--7--解决报错:/bin/sh: 1: nvcc: not found make: *** [obj/convolutional_kernels.o] Error 127
1.配置darknet配置darknet出现错误: qhy@qhy-desktop:~/darknet$ make cleanqhy@qhy-desktop:~/darknet$ make……gcc ...
- StringBuffer 和Stringbuilder源码分析
首先看一下他们的继承关系 这个两个对象都继承了AbstractStringBuilder抽象类. 1.他们的实现方式都一样的,唯一区别的StringBuffer在多线程的时候是保证了数据安全, ...