泰坦尼克号沉没之谜,用数据还原真相——Titanic获救率分析(用pyecharts)
泰坦尼克号获救率数据分析报告,用数据揭露真相。
一,船上乘客生存率分析报告
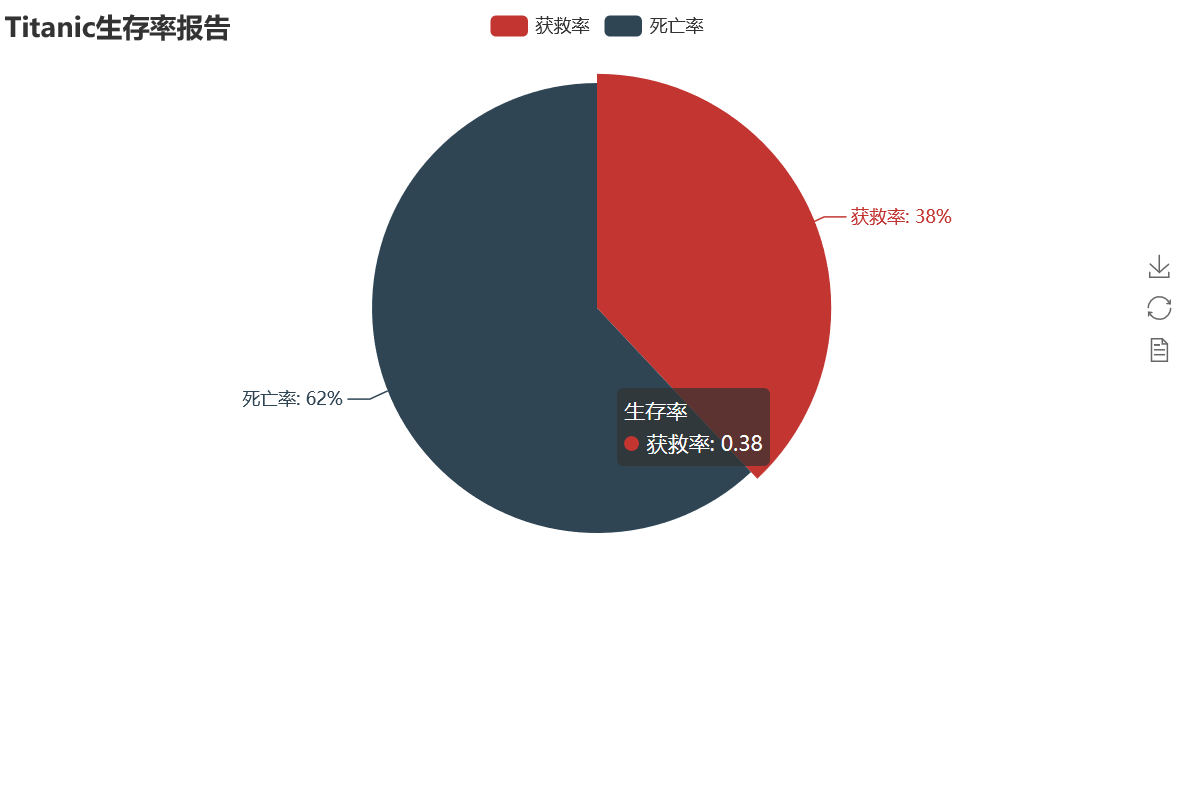
泰坦尼克号生存率仅有38%的,可见此次事件救援不力,救生艇严重不足,且泰坦尼克号号撞得是冰山,海水冷,没有救生艇,在水里冻死的乘客不少。
二,哪个年龄段存活率最高(青年人(18岁以下),中年人(18到50岁),老年人(50岁以上))

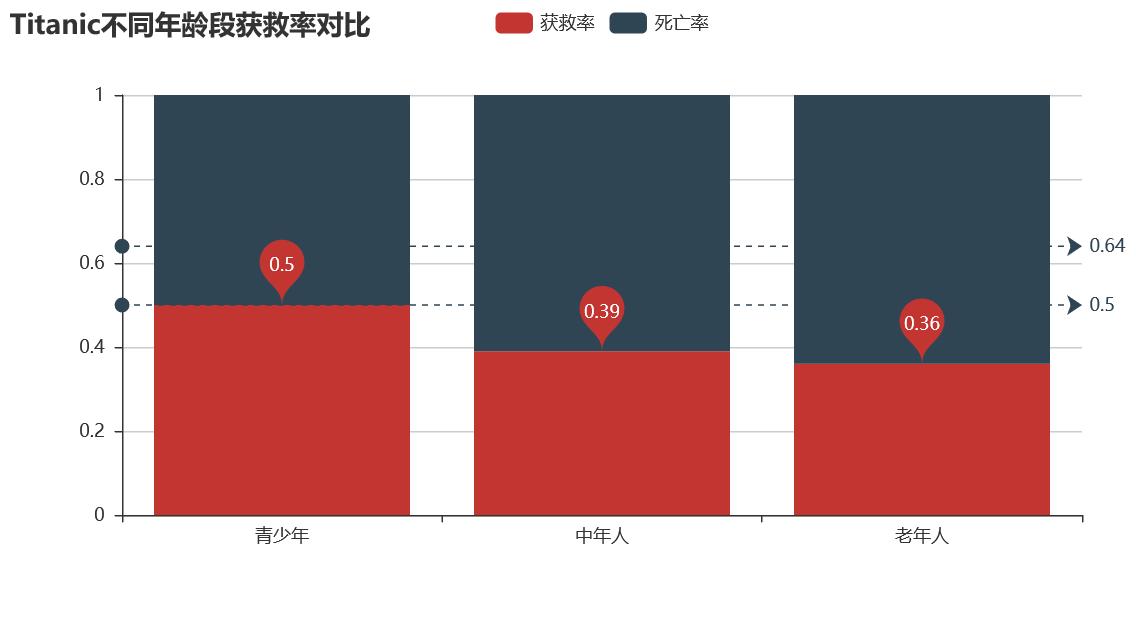
数据分析:看图我们得到,年轻人获救率最高50%,老年人获救率最低0.39,中年人死亡人数最多。发生生命危险时,自救能力最强的中年人还是起到了中流砥柱的作用。不要再叫猥琐油腻中年男了哦,他们才是社会的扛把子。
3,女性乘客和男性乘客获救率分析

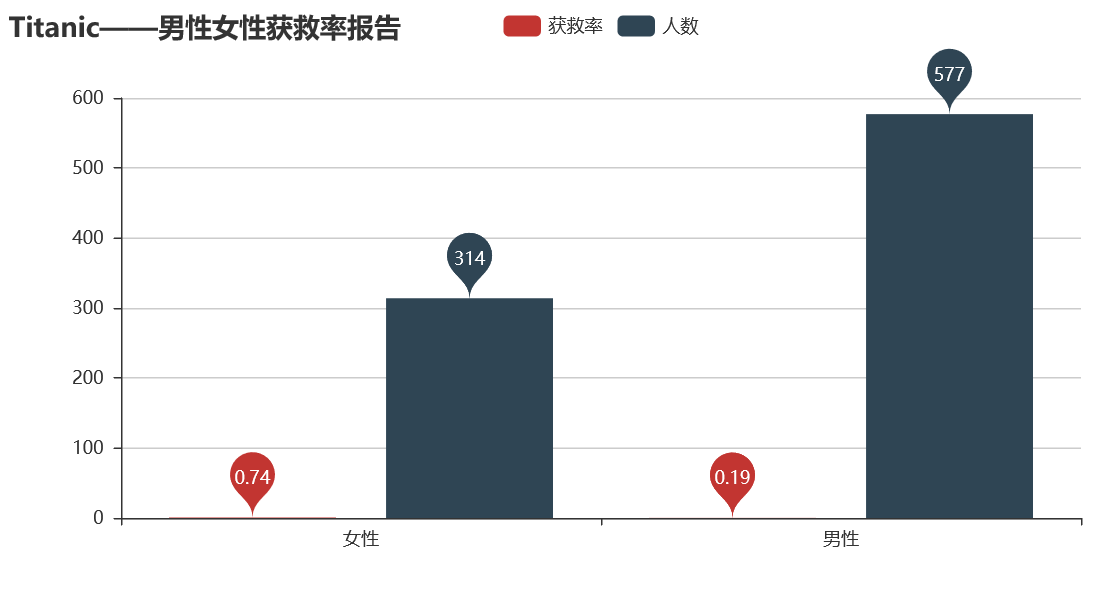
从图中可以看到,女性的获救率远远高于男性,女士优先不是一句空话。
4,船上一等舱二等舱三等舱的乘客贫富差距情况


从图中可以看出,一等舱占全船24%的人数,消费额时全船的67%的金额。嗯,符合著名的二八法则,80%的财富掌握在20%的人手里。
5,舱位和获救率关系分析
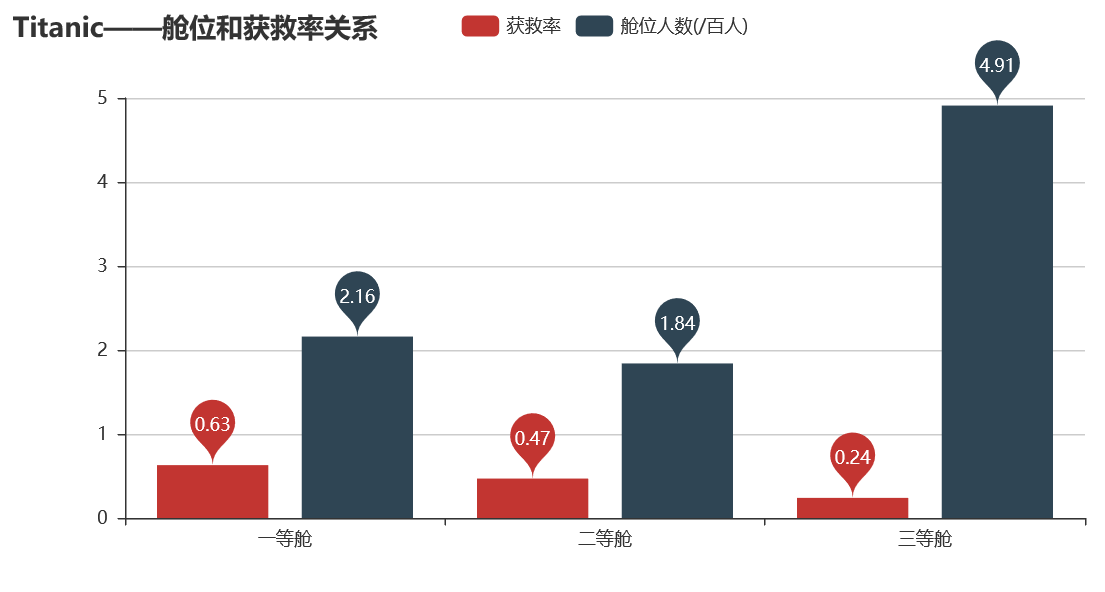
从图中可以看出,一等舱的获救率时三等舱的三倍左右,说明发生沉船事故时,一等舱先上救生艇的,有钱能使鬼推磨,古人诚不欺我也。
附上本人源代码:
import pandas as pd
import matplotlib.pyplot as plt#导入绘制函数
import numpy as np#导入数组库
from pylab import *#转义汉字
mpl.rcParams['font.sans-serif'] = ['SimHei']#
mpl.rcParams['axes.unicode_minus'] = False# from pyecharts import Pie,Bar,Gauge,EffectScatter,WordCloud,Map,Grid,Line,Timeline
import random df_Titanic = pd.read_csv('Titanic.csv')
# print(df_Titanic) #1,一获救率是多少
def Rescued_rate(): t1 = df_Titanic['Survived'].count()
t2 = df_Titanic[df_Titanic['Survived']==1]['Survived'].count()
t3=round(t2/t1,2)
print('一,存活率为:{}'.format(t3)) #Titanic存活率可视化
attr = ['获救率','死亡率' ]
v1 = [t3,(1-t3)]
pie = Pie('Titanic生存率报告')
pie.add('生存率', attr, v1, is_label_show=True)
pie.render('TItanic_1.html') Rescued_rate()
#2,哪个年龄段存活率最高
def age_survived():
#18岁以下的人存活率
young_survived = df_Titanic[(df_Titanic['Age']<=18)&(df_Titanic['Survived']==1)]['Survived'].count()
young_all = df_Titanic[df_Titanic['Age']<=18]['Survived'].count()
#18岁到50岁的存活率
middle_survived = df_Titanic[(df_Titanic['Age']<50)&(df_Titanic['Age']>18)&(df_Titanic['Survived']==1)]['Survived'].count()
middle_all = df_Titanic[(df_Titanic['Age']<50)&(df_Titanic['Age']>18)]['Survived'].count()
#50岁以上乘客的存活率
old_survived = df_Titanic[(df_Titanic['Age'] >= 50) & (df_Titanic['Survived'] == 1)]['Survived'].count()
old_all = df_Titanic[df_Titanic['Age'] >= 50]['Survived'].count()
#三者的生存率
young_odds = round(young_survived/young_all,2)
middle_odds = round(middle_survived/middle_all,2)
old_odds = round(old_survived/old_all,2)
# list=[young_odds,middle_odds,old_odds]
# max_odds = max(list)
# df_odds = pd.Series([young_odds,middle_odds,old_odds])
# df_odds.plot(kind ='bar')
# plt.show() print('二,年轻人,中年人,老年人生存几率分别为{},{},{}'.format(young_odds,middle_odds,old_odds))
#获救率可视化对比图
attr = ['青少年', '中年人', '老年人']
v1 = [young_odds,middle_odds,old_odds]
v2 = [(1-young_odds), (1-middle_odds), (1-old_odds)]
v3 = [young_all,middle_all,old_all] bar = Bar('Titanic不同年龄段获救率对比') bar.add('获救率', attr, v1, mark_point=['average','max','min'], is_stack=True)
bar.add('死亡率', attr, v2, mark_line=['min', 'max'], is_stack=True) # stack是否堆叠显示
bar.add('人数',attr,v3,mark_point=['average','max','min'],is_stack=False)
bar.render('Titanic_2.html') age_survived() #3,女性存活率和男性存活率哪个高
def Rescued_rate_man():
s_man =df_Titanic[(df_Titanic['Sex']=='male')&(df_Titanic['Survived']==1)]['Sex'].count()#获救的男人数
c_man = df_Titanic[df_Titanic['Sex']=='male']['Sex'].count()#男人总数
rescued_man = round(s_man/c_man,2)#男人获救率
s_woman = df_Titanic[(df_Titanic['Sex']=='female')&(df_Titanic['Survived']==1)]['Sex'].count()
c_woman = df_Titanic[df_Titanic['Sex']=='female']['Sex'].count()
rescued_woman = round(s_woman/c_woman,2)
if rescued_woman > rescued_man:
print('三,女性获救率高')
else:
print('三,男性获救率高') #
attr = ['女性', '男性']
v1 = [rescued_woman,rescued_man]
# v2 = [(1 - rescued_woman), (1 - rescued_man)]
v3 = [c_woman,c_man] bar = Bar('Titanic——男性女性获救率报告') bar.add('获救率', attr, v1, mark_point=['average', 'max', 'min'], is_stack=True)
# bar.add('死亡率', attr, v2,mark_point=['average', 'max', 'min'], is_stack=True)
bar.add('人数', attr, v3,mark_point=['average', 'max', 'min'], is_stack=False)# stack是否堆叠显示
bar.render('Titanic_3.html') Rescued_rate_man() #船上的贫富差距
def wealth_gap():
#一等舱的人均消费
consume_one = round(df_Titanic[df_Titanic['Pclass']==1]['Fare'].mean(),2)
consume_two = round(df_Titanic[df_Titanic['Pclass']==2]['Fare'].mean(),2)
consume_three = round(df_Titanic[df_Titanic['Pclass']==3]['Fare'].mean(),2)
consume_std = round(df_Titanic['Fare'].std(),2)
#一等舱二等舱三等舱的人数
person_one = df_Titanic[df_Titanic['Pclass']==1]['Survived'].count()
person_two = df_Titanic[df_Titanic['Pclass'] == 2]['Survived'].count()
person_three = df_Titanic[df_Titanic['Pclass'] == 3]['Survived'].count()
#一等舱二等舱三等舱的消费总额
consumeall_one =df_Titanic[df_Titanic['Pclass']==1]['Fare'].sum()
consumeall_two = df_Titanic[df_Titanic['Pclass'] == 2]['Fare'].sum()
consumeall_three = df_Titanic[df_Titanic['Pclass'] == 3]['Fare'].sum() print('四,一等舱人均消费:{},二等舱人均消费:{},三等舱人均消费:{},人均消费标准差:{}'.format(consume_one,consume_two,consume_three,consume_std)) #可视化
attr = ['一等舱', '二等舱','三等舱']
v2 = [consume_one,consume_two,consume_three]
v1 = [person_one,person_two,person_three]
v3 = [consumeall_one,consumeall_two,consumeall_three] bar = Bar('Titanic——贫富差距报告') bar.add('人均消费', attr, v2, mark_point=['average', 'max', 'min'], is_stack=False)
bar.add('舱位人数', attr, v1,mark_point=['average', 'max', 'min'], is_stack=False) # stack是否堆叠显示
bar.add('消费总额', attr, v3, mark_point=['average', 'max', 'min'],is_stack=False)
bar.render('Titanic_4.html') wealth_gap() #头等舱的生存率是否高于三等舱 def Survival_comparison():
#一等舱的获救率
s1=df_Titanic[(df_Titanic['Pclass']==1)&(df_Titanic['Survived']==1)]['Survived'].count()
c1 = df_Titanic[df_Titanic['Pclass']==1]['Survived'].count()
svl_1 = round(s1/c1,2)
#二等舱的获救率
s2 = df_Titanic[(df_Titanic['Pclass'] == 2) & (df_Titanic['Survived'] == 1)]['Survived'].count()
c2 = df_Titanic[df_Titanic['Pclass'] == 2]['Survived'].count()
svl_2 = round(s2 / c2,2)
#三等舱的获救率
s3 = df_Titanic[(df_Titanic['Pclass'] == 3) & (df_Titanic['Survived'] == 1)]['Survived'].count()
c3 = df_Titanic[df_Titanic['Pclass'] == 3]['Survived'].count()
svl_3 = round(s3 / c3,2)
if svl_1>svl_2>svl_3:
print('五,一等舱二等舱三等舱的获救率分别为:{},{},{},一等舱获救率最高'.format(svl_1,svl_2,svl_3))
else:
print('获救率和舱位关系不大')
#舱位和获救率的关系
attr = ['一等舱', '二等舱', '三等舱']
v2 = [c1/100, c2/100,c3/100]
v1 = [svl_1,svl_2,svl_3] bar = Bar('Titanic——舱位和获救率关系') bar.add('获救率', attr, v1, mark_point=['average', 'max', 'min'], is_stack=False)
bar.add('舱位人数(/百人)', attr, v2, mark_point=['average', 'max', 'min'], is_stack=False) # stack是否堆叠显示
bar.render('Titanic_4.html') Survival_comparison()
#6,带家属的乘客占的比率,有家属是否会影响生存率
def family_survived():
family_yes = df_Titanic[(df_Titanic['SibSp']==1)|(df_Titanic['Parch']==1)]['Survived'].count()#带家属的乘客人数
family_no = df_Titanic[(df_Titanic['SibSp'] == 0) & (df_Titanic['Parch'] == 0)]['Survived'].count()#不带家属的乘客人数
family_all = df_Titanic['Survived'].count()
family_odds = round(family_yes/family_all,2)
#带家属获救的人数
family_survive = df_Titanic[(df_Titanic['SibSp']==1)|(df_Titanic['Parch']==1)&(df_Titanic['Survived']==1)]['Survived'].count()
#不带家属获救的人数
family_no_survive = df_Titanic[(df_Titanic['SibSp']==0)&(df_Titanic['Parch']==0)&(df_Titanic['Survived']==1)]['Survived'].count() #带家属获救的几率
family_survive_odds = round(family_survive/family_yes,2)
#不带家属获救的几率
familyno_survive_odds = round(family_no_survive / family_no, 2)
if family_survive_odds>familyno_survive_odds:
print('六,带家属的生存率为{},不带家属的生存率为{},带家属的生存率高一些'.format(family_survive_odds,familyno_survive_odds))
else:
print('带家属的乘客获救几率和其他乘客一样') family_survived() #七,从哪个港口登陆是否影响生存率
def port_survived():
#S口进入获救的人数
S_survived = df_Titanic[(df_Titanic['Survived']==1)&(df_Titanic['Embarked']=='S')]['Survived'].count()
#S口进入的总人数
S_all = df_Titanic[df_Titanic['Embarked']=='S']['Survived'].count()
#C口进入获救的人数
C_survived = df_Titanic[(df_Titanic['Survived']==1)&(df_Titanic['Embarked']=='C')]['Survived'].count()
#C口进入的总人数
C_all = df_Titanic[df_Titanic['Embarked'] == 'C']['Survived'].count()
#Q口进入获救的人数
Q_survived = df_Titanic[(df_Titanic['Survived']==1)&(df_Titanic['Embarked']=='Q')]['Survived'].count()
#Q口进入的总人数
Q_all = df_Titanic[df_Titanic['Embarked'] == 'Q']['Survived'].count()
#从S,C,Q,进入生存的几率
s_odds = round(S_survived/S_all,2)
c_odds = round(C_survived/C_all,2)
q_odds = round(Q_survived/Q_all,2)
print('七,s,c,q港口进入的乘客的生存率分别为{},{},{}'.format(s_odds,c_odds,q_odds))
port_survived()
泰坦尼克号沉没之谜,用数据还原真相——Titanic获救率分析(用pyecharts)的更多相关文章
- NetAnalyzer笔记 之 九 使用C#对HTTP数据还原
[创建时间:2016-05-12 00:19:00] NetAnalyzer下载地址 在NetAnalyzer2016中加入了一个HTTP分析功能,很过用户对此都很感兴趣,那么今天写一下具体的实现方式 ...
- C#对HTTP数据还原
使用C#对HTTP数据还原 [创建时间:2016-05-12 00:19:00] NetAnalyzer下载地址 在NetAnalyzer2016中加入了一个HTTP分析功能,很过用户对此都很感兴 ...
- 实际使用Elasticdump工具对Elasticsearch集群进行数据备份和数据还原
文/朱季谦 目录 一.Elasticdump工具介绍 二.Elasticdump工具安装 三.Elasticdump工具使用 最近在开发当中做了一些涉及到Elasticsearch映射结构及数据导出导 ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- 基于TILE-GX实现快速数据包处理框架-netlib实现分析【转】
最近在研究suricata源码,在匹配模式的时候,有tilegx mpipe mode,转载下文,了解一下. 原文地址:http://blog.csdn.net/lhl_blog/article/de ...
- 大数据江湖之即席查询与分析(下篇)--手把手教你搭建即席查询与分析Demo
上篇小弟分享了几个“即席查询与分析”的典型案例,引起了不少共鸣,好多小伙伴迫不及待地追问我们:说好的“手把手教你搭建即席查询与分析Demo”啥时候能出?说到就得做到,差啥不能差人品,本篇只分享技术干货 ...
- Oracle字符乱码、数据越界訪问典型Bug分析
Oracle字符乱码.数据越界訪问典型Bug分析 前言: 作为乙方,在甲方客户那里验收阶段发现两个诡异Bug. 下面就问题来源.问题根因.解决方式.怎样避免做具体描写叙述. .且两 ...
- vue 快速入门 系列 —— 侦测数据的变化 - [vue 源码分析]
其他章节请看: vue 快速入门 系列 侦测数据的变化 - [vue 源码分析] 本文将 vue 中与数据侦测相关的源码摘了出来,配合上文(侦测数据的变化 - [基本实现]) 一起来分析一下 vue ...
随机推荐
- tomcat启动前端项目
前后端分离项目,前端使用vue,部署启动前端项目可以使用NodeJS,Nginx,Tomcat. *)使用Tomcat部署启动: 1.把vue项目build生成的dist包,放到Tomcat的weba ...
- linux内核,驱动,应用程三者的概念和之间的关系
驱动程序属于内核的一个部分.准确的说是内核的一个组件.不包含驱动的内核也叫做内核,并且这也是我们常说的内核.内核要干的事情无非5件. 1,内存管理 2,虚拟文件系统 3,进程调度 4,网络接口 5,进 ...
- 测开之路三十九:js基础
js的两种使用方式 第一种使用方式:单独写js文件 在static下新建一个js文件并写入内容 alert('这是一个弹窗'); 在html文件里面,用script标签引入 <script sr ...
- [题解]Print a 1337-string...-数学(codeforces 1202D)
题目链接:https://codeforces.com/problemset/problem/1202/D 题意: 构造一串只由 ‘1’,‘3’,‘7’ 组成的字符串,使其 ‘1337’ 子序列数量为 ...
- QTP与QC整合
QC-QTP整合 在本节中,我们将学习如何将QTP和QC整合.通过整合,在QTP自动化脚本可以直接从Quality Center执行.建立连接,第一个步骤是安装所需的加载项.我们将了解如何通过采取样品 ...
- Bentley二次开发中的,沿曲线构造拉伸实体问题
引用文件:Bentley.Interop.MicroStationDGN 本人开发过程中遇到问题: 创建多个线段及弧线,通过自动创建复杂链获得,沿曲线构造拉伸实体的Path参数,拉伸曲线路径首尾特别近 ...
- 常用css代码(scss mixin)
溢出显示省略号 参过参数可以只是单/多行. /** * 溢出省略号 * @param {Number} 行数 */ @mixin ellipsis($rowCount: 1) { @if $rowCo ...
- 解决Ubuntu与Windows双系统时间不同步问题
目录 1.Windows修改法 1.1设置UTC 1.2恢复LocalTime 2.Ubuntu修改法 2.1设置LocalTime 2.2恢复UTC 切换系统后,往往发现时间差了8小时.这恰恰是北京 ...
- web 项目引入 maven jar 工具类异常
普通的web 项目引入 maven 子项目后,,启动web不会出现异常,登录web 页面异常提示: HTTP Status 500 - java.lang.NoSuchMethodError: o ...
- CentOS 7虚拟机下设置固定IP详解
说明 1.笔记本主机IP为设置自动获取,不管什么情况下,不受虚拟机影响,只要连接外网就可以正常上网: 2.只要笔记本主机可以正常访问外网,启动虚拟机中的CentOS 7系统就可以正常访问外网,无需再进 ...