MySQL学习-数据库设计以及sql的进阶语句
1.数据库设计
关系型数据库建议在E-R模型的基础上,我们需要根据产品经理的设计策划,抽取出来模型与关系,制定出表结构,这是项目开始的第一步
在开发中有很多设计数据库的软件,常用的如power designer,db desinger等,这些软件可以直观的看到实体及实体间的关系
设计数据库,可能是由专门的数据库设计人员完成,也可能是由开发组成员完成,一般是项目经理带领组员来完成
1.1 实体
就是我们根据开发需求,要保存到数据库中作为一张表存在的事物。实体的名称最终会变成表名
实体会有属性,实体的属性就是描述这个事物的内容,实体的属性最终会在表中作为字段存在。
实体与实体之间会存在关系,这种关系一般就是根据三范式提取出来的主外键。
1.1.1 三范式
- 数据要保证不可分割.
- 数据不能冗余(多余).
- 数据不能重复.重复的数据,新建一张表存储.
实际中关于三范式的整理
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式(Normal Form)
目前有迹可寻的共有8种范式,一般需要遵守3范式即可
◆ 第一范式(1NF):强调的是列的原子性,即列不能够再分成其他几列。
考虑这样一个表:【联系人】(姓名,性别,电话) 如果在实际场景中,一个联系人有家庭电话和公司电话,那么这种表结构设计就没有达到 1NF。要符合 1NF 我们只需把列(电话)拆分,即:【联系人】(姓名,性别,家庭电话,公司电话)。1NF 很好辨别,但是 2NF 和 3NF 就容易搞混淆。
◆ 第二范式(2NF):首先是 1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
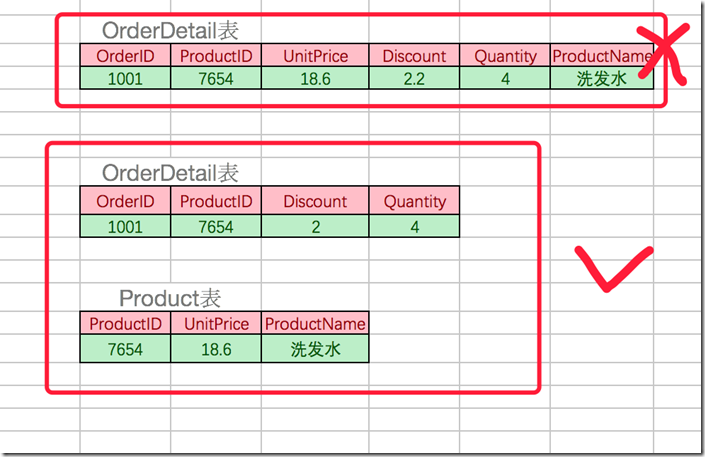
考虑一个订单明细表:【OrderDetail】(OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)。 因为我们知道在一个订单中可以订购多种产品,所以单单一个 OrderID 是不足以成为主键的,主键应该是(OrderID,ProductID)。显而易见 Discount(折扣),Quantity(数量)完全依赖(取决)于主键(OderID,ProductID),而 UnitPrice,ProductName 只依赖于 ProductID。所以 OrderDetail 表不符合 2NF。不符合 2NF 的设计容易产生冗余数据。
可以把【OrderDetail】表拆分为【OrderDetail】(OrderID,ProductID,Discount,Quantity)和【Product】(ProductID,UnitPrice,ProductName)来消除原订单表中UnitPrice,ProductName多次重复的情况。
◆ 第三范式(3NF):首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
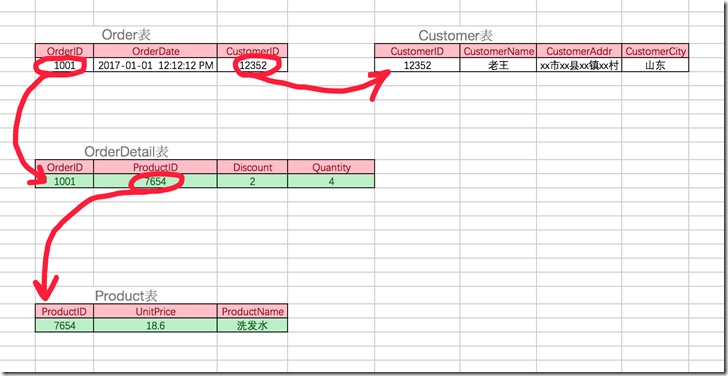
考虑一个订单表【Order】(OrderID,OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity)主键是(OrderID)。 其中 OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity 等非主键列都完全依赖于主键(OrderID),所以符合 2NF。不过问题是 CustomerName,CustomerAddr,CustomerCity 直接依赖的是 CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。 通过拆分【Order】为【Order】(OrderID,OrderDate,CustomerID)和【Customer】(CustomerID,CustomerName,CustomerAddr,CustomerCity)从而达到 3NF。 *第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键点在于,2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分;3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。
不遵循1NF

不遵循2NF
不遵循3NF

最终表
1.1.2 E-R模型
E表示entry,实体,设计实体就像定义一个类一样,指定从哪些方面描述对象,一个实体转换为数据库中的一个表
R表示relationship,关系,关系描述两个实体之间的对应规则,关系的类型包括包括一对一、一对多、多对多
关系也是一种数据,需要通过一个字段存储在表中
实体之间会因为引用相互引用字段而存在关系,这种关系一般有三种:
1-1
1-n
n-m[ 多对多一般表现为2个 1对多 ]
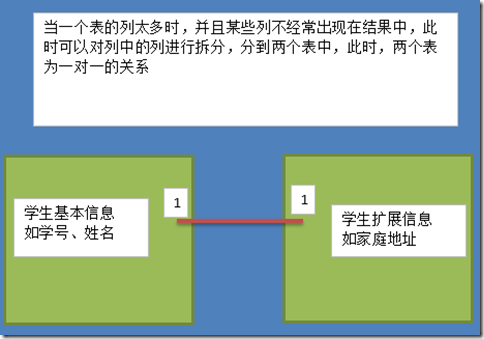
实体A对实体B为1对1,则在表A或表B中创建一个字段,存储另一个表的主键值
实体A对实体B为1对多:在表B中创建一个字段,存储表A的主键值
实体A对实体B为1对1,则在表A或表B中创建一个字段,存储另一个表的主键值
实体A对实体B为1对多:在表B中创建一个字段,存储表A的主键值

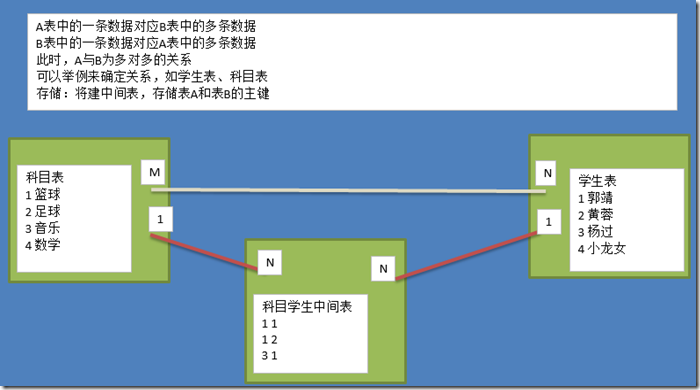
实体A对实体B为多对多:新建一张表C,这个表只有两个字段,一个用于存储A的主键值,一个用于存储B的
实体A对实体B为多对多:新建一张表C,这个表只有两个字段,一个用于存储A的主键值,一个用于存储B的主键值
逻辑删除
对于重要数据,并不希望物理删除,一旦删除,数据无法找回
删除方案:设置isDelete的列,类型为bit,表示逻辑删除,默认值为0
对于非重要数据,可以进行物理删除
数据的重要性,要根据实际开发决定
可以在设计表的时候加上一个字段isdelete
2.sql进阶知识
2.1 select消除重复行
在select后面列前使用distinct可以消除重复的行
distinct的使用需要放在第一个字段的位置,针对第一个字段进行去重。
select distinct 列1,... from 表名;
例:
select distinct gender from students;
例如,统计下在学生表的所有的学生班级
select distinct class from student;
2.2 where条件的运算符进阶-空判断
判空is null
例1:查询没有填写个性签名的学生
select * from student where description is null;
例2:查询填写了个性签名的学生
select * from student where description is not null;
例3:查询填写了身高的男生
select * from student where description is not null and sex=1;
2.3 运算优先级
优先级由高到低的顺序为:小括号,not,比较运算符,逻辑运算符
and比or先运算,如果同时出现并希望先算or,需要结合()使用
2.4. 连接查询(连表查询,多表查询)
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
mysql支持三种类型的连接查询,分别为:
2.4.1 内连接查询-inner join
查询的结果为两个表匹配到的数据
使用内连接,必须保证两个表都会对应id的数据才会被查询出来。
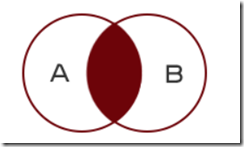
select 字段1,字段2... from 主表 inner join 从表 on 主表.主键=从表.外键
例如:查询学生的信息[ 成绩、名字、班级 ]
我们给学生表添加一个学生信息,然后使用该学生的主键id来连表查询成绩、名字和班级。
insert into student (name,sex,age,class,description) values ('刘德华',1,17,406,'');
select achievement,name,class
from student as a
inner join achievement as b
on a.id=b.sid
where id=101;
# 上面语句因位该学生只在学生表student中有数据,而成绩表中没有数据,所以使用内连接,连表查询的结果是
Empty set (0.00 sec)
同样,如果从表有数据,而主表没有数据,则使用内连接查询一样无法查询到结果。
#例如,添加一个成绩记录,是不存在学生
insert into achievement (sid,cid,achievement) values (102,10,85); select achievement,name,class
from student as a
inner join achievement as b
on a.id=b.sid
where id=102;
2.4.2 右连接查询-right join
只要从表有数据,不管主表是否有数据,都会查询到结果。[以从表的结果为主]
查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充

select 字段1,字段2... from 主表 right join 从表 on 主表.主键=从表.外键
例如,上面的成绩id为102的学生, 我们使用右连接查询。
select achievement,name,class
from student as a
right join achievement as b
on a.id=b.sid;
2.4.3左连接查询-left join
只要主表有数据,不管从表是否有数据都会被查询出来。
查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充
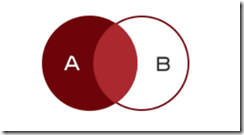
select * from 表1 left join 表2 on 表1.列 = 表2.列
例如,使用左连接查询学生表与成绩表,查询学生姓名及分数
select achievement,name,class
from student as a
left join achievement as b
on a.id=b.sid; 等同于
select achievement,name,class
from achievement as b
right join student as a
on a.id=b.sid;
总结:三种连表查询,最常用的是 left join,然后inner join保证数据的一致性。右连接基本上都是使用左连接代替。
2.5 多表关联
语句:
select 表.字段1,表.字段2,表.字段3.....
from 主表
left join 从表1 on 主表.主键=从表1.外键
left join 从表2 on 主表.主键=从表2.外键
# 这里和从表2连接的on条件看实际情况,也会出现从表1.主键=从表2.外键的情况
left join 从表3 on 主表.主键=从表3.外键
# 这里可以是(从表1或从表2).主键=从表2.外键的情况
left join ...
多表查询的缺点:
多表查询的效率,性能比单表要差。
多表查询以后,还会带来字段多了会引起字段覆盖的情况、
主表student 从表1 achievement 从表2 course
name xxx name
上面三张表如果连表,则出现主表的name覆盖从表2的name这种情况。
上面两个问题:
把多表查询语句可以替换成单表查询语句【需要优化的情况】
把重复的字段名,分别使用as来设置成别的名称。
例如,查询白杨的班级、id、年龄和课程名称以及对应课程的成绩
select a.id,a.class,a.age,c.course,b.achievement
from student as a
left join achievement as b on a.id=b.sid
left join course as c on c.id=b.cid
where a.name='白杨';
2.6 单表的连表查询(自关联查询)
核心就是把一张表看做2张表来操作
# 建表:
create table area(
id smallint not null auto_increment comment '主键ID',
name char(30) not null comment '地区名称',
pid smallint not null default 0 comment '父级地区ID',
primary key (id)
) engine=innodb charset=utf8; insert into area (name,pid) values ('广东',0),('深圳',1),('龙岗',2),('福田',2),('宝安',2);
格式
select 字段1,字段2...
from 主表(当前表) as a
left join 从表(当前表) as b on a.主键=b.外键
查找深圳地区的子地区,SQL代码:
# 主表看成保存深圳的表,
# 从表看成保存深圳子地区的表 select b.id,b.name
from area as a
left join area as b on a.id=b.pid
where a.name='深圳';
2.7 子查询
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句格式:select 字段 from 表名 where 条件(另一条查询语句)主查询与子查询的关系
子查询是嵌入到主查询中
子查询是辅助主查询的,要么充当条件,要么充当数据源
子查询是可以独立存在的语句,是一条完整的 select 语句
例如:查询406班级大于平均年龄的学生
使用 子查询:
查询406班学生平均年龄
查询大于平均年龄的学生
查询406班级学生的平均年龄
select name,age from student where age > (select avg(age) as avg from student where class=406) and class=406;
2.8 having
group by 字段 having 条件;
过滤筛选,主要作用类似于where关键字,用于在SQL语句中进行条件判断,过滤结果的。但是与where不同的地方在于having只能跟在group by 之后使用。
例如:查询301班级大于班上平均成绩的学生成绩信息(name,平均分,班级)。
# 先求301班的平均成绩
select avg(achievement) as achi from student as a
left join achievement as b on a.id=b.sid
where class=301; # 判断301中的每个人平均成绩大于上面的到的平均成绩
select name,avg(achievement) from student as a
left join achievement as b on a.id=b.sid
where class=301 group by name having avg(achievement) > (select avg(achievement) as achi from student as a left join achievement as b on a.id=b.sid
where class=301);
2.9 select查询语句的完整格式
select distinct 字段1,字段2....
from 表名 as 表别名
left join 从表1 on 表名.主键=从表1.外键
left join ....
where ....
group by ... having ...
order by ...
limit start,count
执行顺序为:
from 表名[包括连表]
where ....
group by ...
select distinct *
having ...
order by ...
limit start,count
实际使用中,只是语句中某些部分的组合,而不是全部
3.数据库的备份与恢复
3.1 备份
运行mysqldump命令
mysqldump –uroot –p 数据库名 > python.sql; # 按提示输入mysql的密码
3.2 恢复
连接mysql,创建新的数据库
退出连接,执行如下命令
1.第一种方式
mysql -uroot –p 新数据库名 < python.sql # 根据提示输入mysql密码
2.第二种方式
mysql> create database abc; # 创建数据库
mysql> use abc; # 使用已创建的数据库
mysql> set names utf8; # 设置编码
mysql> source /home/abc/abc.sql # 导入备份数据库
俩种方式的区别
1.第一种方式可以本地和远程操作
2,第二种方式只能本地操作
4.python操作mysql
一般使用pymysql模块操作数据库
import pymysql # from pymysql import * # 创建和数据库服务器的连接 connection
conn = pymysql.connect(host='localhost',port=3306,user='root',password='root123456',
db='student',charset='utf8') # 创建游标对象
cursor = conn.cursor() # 中间可以使用游标完成对数据库的操作
sql = "select * from student;" # 执行sql语句的函数 返回值是该SQL语句影响的行数
count = cursor.execute(sql)
print("操作影响的行数%d" % count)
# print(cursor.fetchone()) # 返回值类型是元祖,表示一条记录 # 获取本次操作的所有数据
for line in cursor.fetchall():
print("数据是%s" % str(line)) # 关闭资源 先关游标
cursor.close()
# 再关连接
conn.close()
执行语句
#执行sql,更新单条数据,并返回受影响行数
result = cursor.execute("SQL语句") #插入多条,并返回受影响的函数,例如批量添加
result2 = cursor.executemany("多条数据")
#获取最新自增ID
new_id = cursor.lastrowid
获取结果
#获取一行
result1 = cursor.fetchone()
#获取多行[参数可以设置指定返回数量]
result2 = cursor.fetchmany(整型)
#获取所有
result3 = cursor.fetchall()
操作数据
#提交,保存新建或修改的数据,如果是查询则不需要
conn.commit() # 写在execute()之后
ok
MySQL学习-数据库设计以及sql的进阶语句的更多相关文章
- 在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案。
在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计.SQL语句.java等层面的解决方案. 解答: 1)数据库设计方面: a. 对查询进行优化,应尽量避免全表扫描,首先应考虑在 whe ...
- mysql优化-数据库设计基本原则
mysql优化-数据库设计基本原则 一.数据库设计三范式 第一范式:字段具有原子性 原子性是指数据库的所有字段都不可被再次划分,如下表就不满足原子性,起点与终点 字段就可被拆分为起点与终点两个字段. ...
- 【学习记录】第一章 数据库设计-《SQL Server数据库设计和开发基础篇视频课程》
一.课程笔记 1.1 软件开发周期 (1)需求分析阶段 分析客户的业务和数据处理需求. (2)概要设计阶段 设计数据库的E-R模型图,确认需求信息的正确和完整. /* E-R图:实体-关系图(Ent ...
- sql数据库设计学习---数据库设计规范化的五个要求
http://blog.csdn.net/taijianyu/article/details/5945490 一:表中应该避免可为空的列: 二:表不应该有重复的值或者列: 三: 表中记录应该有一个唯一 ...
- MySql学习---数据库基本类型,事务,多表查询
数据库分类 关系型数据库 行列, 列如Mysql,oracle 通过表和表之间,行和列之间的关系进行数据的存储 非关系型数据库: Redis,MongDb 以对象存储,同过对象的自身属性来决定 表与表 ...
- 大数据量查询优化——数据库设计、SQL语句、JAVA编码
数据库设计方面: 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将 ...
- MySql三大范式与数据库设计和表创建常用语句
[数据库设计的三大范式] 1.第一范式(1NF First Normal Fromate):数据表中的每一列(字段),必须是不可拆分的最小单元.也就是确保每一列的原子性. 例如: userInfo: ...
- MySQL学习笔记(一):SQL基础
定义:SQL即Structure Query Language(机构化查询语言)的缩写,是使用关系数据库的应用语言. 包括三个类别: (1):DDL(Data Definition Language) ...
- Mysql之数据库设计
一.三大范式 1.第一范式:消除一个字段包含多个数据库值,消除一个记录包含重复的组(单独的一列包含多个项目),即可满足1NF. 2.第二范式:消除部分依赖性即可转化为2NF.部分依赖性表示一个记录中包 ...
随机推荐
- 关于PHP://input
$data = file_get_contents("php://input"); php://input 是个可以访问请求的原始数据的只读流. POST 请求的情况下,最好 ...
- zencart 输出产品特价折扣百分比
通过调用zen_get_products_base_price($products_id)获取原价,zen_get_products_special_price($products_id)获取特价,进 ...
- 如何在Linux下安装JDK1.8
本文会详细介绍如何在Linux下安装JDK1.8 首先要设置虚拟机的IP地址,不知道如何设置的话可以 翻看我的前一篇博客 http://www.cnblogs.com/xiaoxiaoSMILE/ ...
- spring+mybatis事务配置(转载)
原文地址:http://blog.csdn.net/wgh1015398431/article/details/52861048 申明式事务配置步骤 .xml文件头部需要添加spring的相关支持: ...
- 【转】原生js实现移动端h5长按事件
$("#target").on({ touchstart: function(e) { // 长按事件触发 timeOutEvent = setTimeout(function() ...
- springCloud——Dalston.SR5升级到Greenwich.SR2
老项目: SpringBoot 版本 :1.5.13.RELEASE SpringCloud 版本:Dalston.SR5 项目升级: SpringBoot 版本 :2.1.6.RELEASE Spr ...
- 3828. 三角形计数 3829. ZCC loves Isaac 3830. 字符消除
3828 给定n个点的坐标(0<=xi,yi<=10000)求选出任意三个点能组成的三角形的总面积. 题解 太naive了 枚举三角形的y最小的点,把剩余的点按角度排序 然后随便算,可以用 ...
- SqlServer 随机生成中文姓名(转)
,) )) -- 姓氏 ,) )) -- 名字 INSERT @fName VALUES ('赵'),('钱'),('孙'),('李'),('周'),('吴'),('郑'),('王'),('冯'),( ...
- package.json文件
http://javascript.ruanyifeng.com/nodejs/packagejson.html#toc7(copy) 通常我们使用npm init命令来创建一个npm程序时,会自动生 ...
- Tire树模板-于是他错误的点名开始了
题目背景 XS中学化学竞赛组教练是一个酷爱炉石的人. 他会一边搓炉石一边点名以至于有一天他连续点到了某个同学两次,然后正好被路过的校长发现了然后就是一顿欧拉欧拉欧拉(详情请见已结束比赛CON900). ...