什么是DOM(文档对象模型)?
㈠什么是DOM?
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口。
DOM 定义了访问 HTML 和 XML 文档的标准:
"W3C 文档对象模型 (DOM) 是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。"
㈡分类
W3C DOM 标准被分为 3 个不同的部分:
⑴核心 DOM - 针对任何结构化文档的标准模型
⑵XML DOM - 针对 XML 文档的标准模型
⑶HTML DOM - 针对 HTML 文档的标准模型
㈢什么是 HTML DOM?
HTML DOM 是:
⑴HTML 的标准对象模型
⑵HTML 的标准编程接口
⑶W3C 标准
HTML DOM 定义了所有 HTML 元素的对象和属性,以及访问它们的方法。
换言之,HTML DOM 是关于如何获取、修改、添加或删除 HTML 元素的标准。
㈣HTML DOM 节点
在 HTML DOM 中,所有事物都是节点。DOM 是被视为节点树的 HTML。
1.根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
⑴整个文档是一个文档节点
⑵每个 HTML 元素是元素节点
⑶HTML 元素内的文本是文本节点
⑷每个 HTML 属性是属性节点
⑸注释是注释节点
2.HTML DOM 节点树
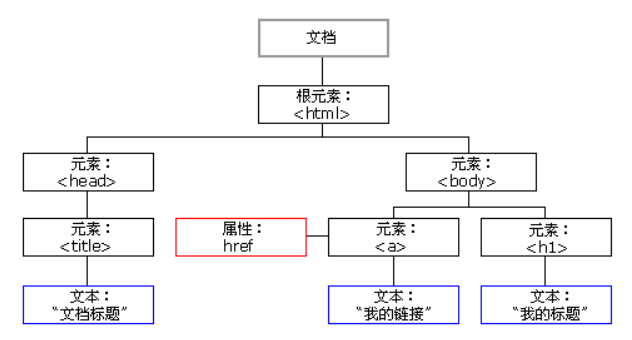
3.节点父、子和同胞
节点树中的节点彼此拥有层级关系。
♠我们常用父(parent)、子(child)和同胞(sibling)等术语来描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
⑴在节点树中,顶端节点被称为根(root)。
⑵每个节点都有父节点、除了根(它没有父节点)。
⑶一个节点可拥有任意数量的子节点。
⑷同胞是拥有相同父节点的节点。
♠具体事例:
<html>
<head>
<meta charset="utf-8">
<title>DOM 教程</title>
</head>
<body>
<h1>DOM 课程1</h1>
<p>Hello world!</p>
</body>
</html>
从上面的 HTML 中:
- <html> 节点没有父节点;它是根节点
- <head> 和 <body> 的父节点是 <html> 节点
- 文本节点 "Hello world!" 的父节点是 <p> 节点
并且:
- <html> 节点拥有两个子节点:<head> 和 <body>
- <head> 节点拥有两个子节点:<meta> 与 <title> 节点
- <title> 节点也拥有一个子节点:文本节点 "DOM 教程"
- <h1> 和 <p> 节点是同胞节点,同时也是 <body> 的子节点
并且:
- <head> 元素是 <html> 元素的首个子节点
- <body> 元素是 <html> 元素的最后一个子节点
- <h1> 元素是 <body> 元素的首个子节点
- <p> 元素是 <body> 元素的最后一个子节点
㈤HTML DOM 方法
☞HTML DOM 方法是我们可以在节点(HTML 元素)上执行的动作。
☞HTML DOM 属性是我们可以在节点(HTML 元素)设置和修改的值。
★HTML DOM 对象 - 方法和属性
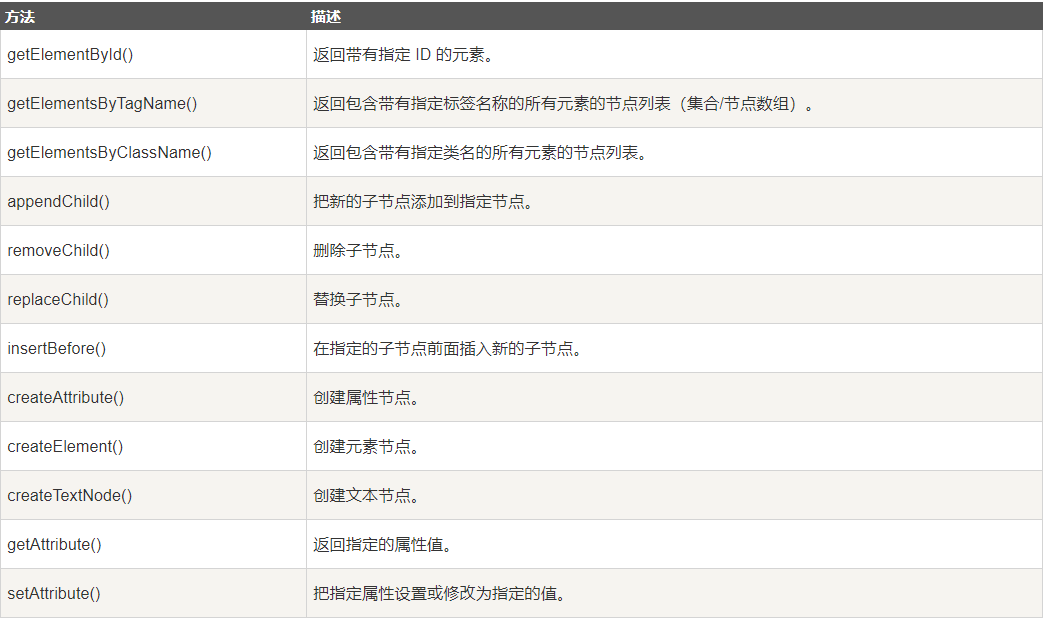
一些常用的 HTML DOM 方法:
- getElementById(id) - 获取带有指定 id 的节点(元素)
- appendChild(node) - 插入新的子节点(元素)
- removeChild(node) - 删除子节点(元素)
一些常用的 HTML DOM 属性:
- innerHTML - 节点(元素)的文本值
- parentNode - 节点(元素)的父节点
- childNodes - 节点(元素)的子节点
- attributes - 节点(元素)的属性节点
★DOM对象方法:
㈥HTML DOM 属性
属性是节点(HTML 元素)的值,能够获取或设置。
⑴innerHTML 属性
获取元素内容的最简单方法是使用 innerHTML 属性。
innerHTML 属性对于获取或替换 HTML 元素的内容很有用。包括<html>和<body>。
★示例:下面的代码获取 id="zq" 的 <p> 元素的 innerHTML:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body> <p id="zq">早上起来,拥抱太阳。</p> <script>
var mychar=document.getElementById("zq").innerHTML;
document.write(mychar);
</script> </body>
</html>
效果图:

☞在上面的例子中,getElementById 是一个方法,而 innerHTML 是属性。
⑵nodeValue 属性
★nodeValue 属性规定节点的值。
▪元素节点的 nodeValue 是 undefined 或 null
▪文本节点的 nodeValue 是文本本身
▪属性节点的 nodeValue 是属性值
★nodeName 属性规定节点的名称。
- nodeName 是只读的
- 元素节点的 nodeName 与标签名相同
- 属性节点的 nodeName 与属性名相同
- 文本节点的 nodeName 始终是 #text
- 文档节点的 nodeName 始终是 #document
注意: nodeName 始终包含 HTML 元素的大写字母标签名。
★ 示例:获取元素的值
下面的例子会取回 <p id="intro"> 标签的文本节点值:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body> <p id="intro">早睡早起,身体好。</p> <script>
z=document.getElementById("intro");
document.write(z.firstChild.nodeValue);
</script> </body>
</html>
效果图:

㈦HTML DOM 访问
访问 HTML 元素(节点)
访问 HTML 元素等同于访问节点
★能够以不同的方式来访问 HTML 元素:
⑴通过使用 getElementById() 方法
⑵通过使用 getElementsByTagName() 方法
⑶通过使用 getElementsByClassName() 方法
1.getElementById() 方法
getElementById() 方法返回带有指定 ID 的元素引用:
☼语法 :node.getElementById("id");
☼示例:下面的例子获取 id="intro" 的元素
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body> <p id="intro">我爱洗澡,皮肤好好。</p>
<p>这个实例演示了 <b>getElementById</b> 方法!</p> <script>
x=document.getElementById("intro");
document.write("<p>段落的文本为: " + x.innerHTML + "</p>");
</script> </body>
</html>
效果图:

2.getElementsByTagName() 方法
getElementsByTagName() 返回带有指定标签名的所有元素。
☼语法:node.getElementsByTagName("tagname");
☼示例1:下面的例子返回包含文档中所有 <p> 元素的列表:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body> <p>洗刷刷,洗刷刷,喔噢~</p>
<p>DOM 是非常有用的!</p>
<p>这个实例演示了 <b>getElementsByTagName</b> 方法的使用。</p> <script>
x=document.getElementsByTagName("p");
document.write("第一个段落的文本为: " + x[0].innerHTML);
</script> </body>
</html>
效果图:

☼示例2:下面的例子返回包含文档中所有 <p> 元素的列表,并且这些 <p> 元素应该是 id="main" 的元素的后代(子、孙等等):
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body> <p>Hello World!</p> <div id="main">
<p>时间过得总是让人猝不及防。</p>
<p>这个实例演示了 <b>getElementsByTagName</b> 方法的使用。</p>
</div> <script>
x=document.getElementById("main").getElementsByTagName("p");
document.write("div 中的第一个段落为: " + x[0].innerHTML);
</script> </body>
</html>
效果图:

3.The getElementsByClassName() Method
如果希望查找带有相同类名的所有 HTML 元素,请使用这个方法:
document.getElementsByClassName("intro");
上面的例子返回包含 class="intro" 的所有元素的一个列表
什么是DOM(文档对象模型)?的更多相关文章
- javascript之DOM文档对象模型编程的引入
/* DOM(Document Object Model) 文档对象模型 一个html页面被浏览器加载的时候,浏览器就会对整个html页面上的所有标签都会创建一个对应的 对象进行描述,我们在浏览器上看 ...
- JavaScript(三、DOM文档对象模型)
一.什么是DOM DOM 是 Document Object Model(文档对象模型)的缩写. DOM 是 W3C(万维网联盟)的标准. DOM 定义了访问 HTML 和 XML 文档的标准: &q ...
- html--JavaScript之DOM (文档对象模型)
一.简介 当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model). HTML DOM 定义了用于 HTML 的一系列标准的对象,以及访问和处理 HTML 文档的标 ...
- DOM文档对象模型简介
DOM简介 DOM是W3C(万维网联盟)的标准 "W3C文档对象模型DOM是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容.结构.样式".W3C DOM ...
- dom文档对象模型图
- 文档对象模型 DOM
1 DOM概述 1.1 什么是DOM 文档对象模型 Document Object Model 文档对象模型 是表示和操作 HTML和XML文档内容的基础API 文档对象模型,是W3C组织推荐的处理可 ...
- JavaScript交互式网页设计 • 【第4章 JavaScript文档对象模型】
全部章节 >>>> 本章目录 4.1 文档对象模型简介及属性 4.1.1 文档对象模型概述 4.1.3 实践练习 4.2 document 对象查找 HTML 元素 4.2 ...
- DOM(文档对象模型)
1.定义: DOM是Document Object Model文档对象模型的缩写.是针对HTML和XML文档的一个API,通过DOM可以去改变文档. 例如:我们有一段HTML,那么如何访问第二层第一个 ...
- 文档对象模型(DOM)中的结点属性
在文档对象模型中,每个结点都是一个对象.DOM结点有三个重要的属性:nodeName .nodeValue和nodeType,分别表示结点名称.结点的值和结点的类型 一.nodeName,结点名称,只 ...
- 文档对象模型(DOM)
文档对象模型(DOM) DOM可以将任何HTML或XML文档描绘成一个由多层节点构成的结构.节点分为几种不同的类型:文档型节点.元素节点.特性节点.注释节点等共有12种节点类型.DOM1级定义了 ...
随机推荐
- Mac下搭建Apache+PHP+MySql运行环境
https://www.cnblogs.com/xiaovw/p/8854896.html 前言 我们在Mac上搭建Apache+PHP+MySql环境是非常方便的,因为Mac预装的有Apache和P ...
- SpringMVC异常体系
在服务端经常会遇到需要手动的抛出异常,比如业务系统,校验异常,比较通用的处理方案是在最顶层进行拦截异常,例如Struts的全局异常处理,而Spring的异常处理机制就相对于Struts来说好用多了 ...
- 基于FCN的图像语义分割
语义图像分割的目标在于标记图片中每一个像素,并将每一个像素与其表示的类别对应起来.因为会预测图像中的每一个像素,所以一般将这样的任务称为密集预测.(相对地,实例分割模型是另一种不同的模型,该模型可以区 ...
- SpringMVC实现全局异常处理器 (转)
出处: SpringMVC实现全局异常处理器 我们知道,系统中异常包括:编译时异常和运行时异常RuntimeException,前者通过捕获异常从而获取异常信息,后者主要通过规范代码开发.测试通过手 ...
- Java后端技术面试汇总(第三套)
1.基础题 • 怎么解决Hash冲突:(开放地址法.链地址法.再哈希法.建立公共溢出区等)• 写出一个必然会产生死锁的伪代码:• Spring IoC涉及到的设计模式:(工厂模式.单利模式..)• t ...
- Scala学习一——基础
一.使用Scala解释器 如果以命令行的方式运行,输出的结果会把类型带上,且结果名默认为res0递增.且Scala解释器读到一个解释器求值打印然后读取下一个(这个过程为读取-求值-打印-循环[REPL ...
- AWS In Action
Core Services of AWS Elastic Cloud Compute(EC2) Simple Storage Service(S3) Relational Database Servi ...
- js css3 固定点拖拽旋转
一.直接上效果图: 然后是代码: 一共两种实现方式: <!DOCTYPE html> <html lang="en"> <head> <m ...
- 1.css选择器
1.引入外部样式表的格式: <link rel=”stylesheet” type=”text/css” href=”../css/style1.css”> 2.样式表第一行应注明编码类型 ...
- vue路由(基于VScode开发)
index.js如果在router目录下,代表这个js文件只是路由使用 main.js中为全局,需要引入使用到的组件,一般vue中不用写东西vue中el挂载哪个就哪个组件为根目录,传值数据绑定的时候在 ...