在一个情形中遇到下面一个情况
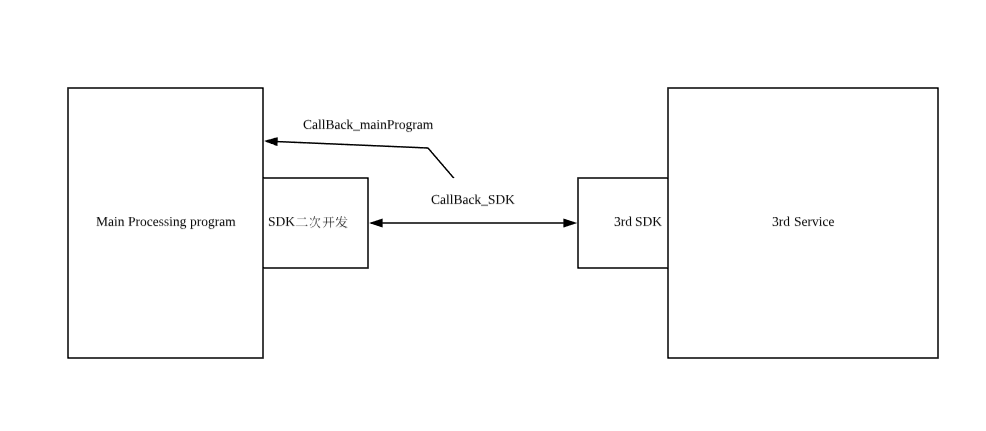
简述下该图片,对sdk进行二次开发,通过第三方sdk接口获取码流信息。具体实现方式是通过回调函数CallBack_SDK来不停的回调第三方服务的视频流。起初实现逻辑如下:
void CallBack_SDK(long flag, char* stream, int data,void* UsrData)
{
... //必要的信息处理
CallBack_mainProgram(); //调用主程序的回调函数,将码流回调给主程序
}
即回调函数中再调用主函数的回调函数。这样就遇到一个问题,CallBack_SDK 函数需要很快返回,而CallBack_mainProgram则返回慢,造成了一个生产者消费者问题,消费者的速度跟不上生产者的速度,造成CallBack_SDK不能及时返回造成3rd sdk认为socket阻塞从而造成断链。由于历史原因,CallBack_mainProgram()没有可能改动,只能CallBack_SDK动手脚。一共采取了以下这些方法:
1 有锁队列
构造一个有锁的队列,互斥锁和deque构造一个队列,互斥锁类的代码来自网络(具体地址忘了)
#pragma once
#ifndef _Lock_H
#define _Lock_H
#include <windows.h>
//锁接口类
class IMyLock
{
public:
virtual ~IMyLock() {}
virtual void Lock() const = ;
virtual void Unlock() const = ;
};
//互斥对象锁类
class Mutex : public IMyLock
{
public:
Mutex();
~Mutex();
virtual void Lock() const;
virtual void Unlock() const;
private:
HANDLE m_mutex;
};
//锁
class CLock
{
public:
CLock(const IMyLock&);
~CLock();
private:
const IMyLock& m_lock;
};
#endif
|
#include "Lock.h"
#include <cstdio>
//创建一个匿名互斥对象
Mutex::Mutex()
{
m_mutex = ::CreateMutex(NULL, FALSE, NULL);
}
//销毁互斥对象,释放资源
Mutex::~Mutex()
{
::CloseHandle(m_mutex);
}
//确保拥有互斥对象的线程对被保护资源的独自访问
void Mutex::Lock() const
{
DWORD d = WaitForSingleObject(m_mutex, INFINITE);
}
//释放当前线程拥有的互斥对象,以使其它线程可以拥有互斥对象,对被保护资源进行访问
void Mutex::Unlock() const
{
::ReleaseMutex(m_mutex);
}
//利用C++特性,进行自动加锁
CLock::CLock(const IMyLock& m) : m_lock(m)
{
m_lock.Lock();
// printf("Lock \n");
}
//利用C++特性,进行自动解锁
CLock::~CLock()
{
m_lock.Unlock();
//printf("UnLock \n");
}
|
上边左右分别为互斥锁类的头文件和实现文件。
#pragma once
#ifndef THREADSAFEDEQUE_H
#define THREADSAFEDEQUE_H
#include "Lock.h"
#include <DEQUE>
#include <vector>
typedef struct CframeBuf {
void* m_achframe;
int m_nsize;
bool m_bUsed;
CframeBuf()
{
m_achframe = NULL;
m_nsize = ;
m_bUsed = false;
}
}CFrameBuf;
#define MAX_FRAME_BUF_SIZE 150 /* 定义最大缓存队列长度 */
#define MEM_POOL_SLOT_SIZE 512 * 1024 /* 内存池最小单位 */
typedef struct mempool {
std::vector<char*> m_memFragment;
size_t m_nsize;
size_t m_nused;
mempool()
{
m_nused = ;
m_nsize = ;
}
}MemPool;
class SynchMemPool {
public:
SynchMemPool()
{
AllocatBuf();
}
~SynchMemPool()
{
EmptyBuf();
}
bool WriteDate2Mempool(CframeBuf & In, CframeBuf & Out); /* 写入一个结构体存储 */
bool ReadDataFromMempool(CframeBuf & Out); /* 读取datalen长数据 */
bool MinusOneMempool(); /* 减少一个结构体存储 */
private:
MemPool m_mempool; /*下载内存池 */
Mutex m_Lock; /* 互斥锁 */
bool AllocatBuf(); /* 分配内存 */
bool EmptyBuf(); /* 释放 */
};
class SynchDeque
{
private:
std::deque<CFrameBuf> q;
Mutex m_lock;
SynchMemPool memorypool;
public:
SynchDeque()
{
}
~SynchDeque()
{
}
void Enqueue( CFrameBuf & item );
void Dequeue( CFrameBuf & item );
void ClearDeque()
{
q.clear();
}
int GetSize()
{
return(q.size() );
}
};
#endif
|
#include "threadSafeDeque.h"
bool SynchMemPool::AllocatBuf(){
CLock clock(m_Lock);
for (int i = ; i< MAX_FRAME_BUF_SIZE; ++i){
char* mem = new char[MEM_POOL_SLOT_SIZE];
if (mem != NULL)
{
m_mempool.m_memFragment.push_back(mem);
}
m_mempool.m_nsize++;
}
printf("分配内存池成功,大小为 %d\n",m_mempool.m_nsize);
return TRUE;
}
bool SynchMemPool::EmptyBuf(){
CLock clock(m_Lock);
for (size_t i = ; i < m_mempool.m_memFragment.size();++i){
if (m_mempool.m_memFragment[i])
{
delete [] m_mempool.m_memFragment[i];
}
}
m_mempool.m_nsize = ;
m_mempool.m_nused = ;
printf("释放内存池成功\n");
return TRUE;
}
bool SynchMemPool::WriteDate2Mempool(CframeBuf & In, CframeBuf & Out) {
if (In.m_achframe == NULL)
{
return false;
}
if (m_mempool.m_nsize == m_mempool.m_nused)
{
return false;
}
CLock clock(m_Lock);
char* avaibleaddr = m_mempool.m_memFragment[m_mempool.m_nused];
if (avaibleaddr)
{
memcpy(avaibleaddr,In.m_achframe,In.m_nsize);
Out.m_achframe = avaibleaddr;
Out.m_nsize = In.m_nsize;
++m_mempool.m_nused;
return true;
}
else
return false;
}
bool SynchMemPool::ReadDataFromMempool(CframeBuf& Out){
if (Out.m_achframe != NULL && m_mempool.m_memFragment[m_mempool.m_nused -] != NULL && Out.m_nsize < MEM_POOL_SLOT_SIZE)
{
memcpy(Out.m_achframe,m_mempool.m_memFragment[m_mempool.m_nused -],Out.m_nsize);
}
return true;
}
bool SynchMemPool::MinusOneMempool(){
if (m_mempool.m_nused == )
{
return false;
}
CLock clock(m_Lock);
if (m_mempool.m_memFragment[m_mempool.m_nused - ] != NULL)
{
memset(m_mempool.m_memFragment[m_mempool.m_nused - ],,MEM_POOL_SLOT_SIZE);
--m_mempool.m_nused;
}
return true;
}
void SynchDeque::Enqueue(CFrameBuf& item) {
CLock clock(m_lock);
{
CFrameBuf tmpfram;
memorypool.WriteDate2Mempool(item, tmpfram);
q.push_back(tmpfram);
}
}
void SynchDeque::Dequeue(CFrameBuf& item)
{
CLock clock(m_lock); // <= create critical block, based on q
{
if (q.size() != && item.m_achframe && q.front().m_achframe)
{
memcpy(item.m_achframe,q.front().m_achframe,q.front().m_nsize);
item.m_bUsed = q.front().m_bUsed;
item.m_nsize = q.front().m_nsize;
q.pop_front();
// memorypool.ReadDataFromMempool(item.m_achframe,item.m_nsize); //读取一个数据
memorypool.MinusOneMempool(); //归还一个slot给内存池
}
}
}
|
上边为采用互斥锁的队列简单实现。
但是问题又出现了,采用上述方式,一个线程写,一个线程读,但写的速度更快了(3rd sdk似乎是当回调函数返回就立即写入,并没有次数或时长的调用限制),这就意味着队列的锁不停的由写线程持有,导致读线程饿死,或者队列一直处于饱和状态。
遂考虑无锁队列,网络上有很多无锁队列的实现,我采用了环形队列,这种原理在linux内核的网络包处理中也有使用。下面给一个简单的实现,带内存形式:
/*
本文件实现了对于单个消费者和单个接收者之间无锁环形队列,注意,不适用于多线程(多消费者和多生产者)
*/
#pragma once
#ifndef _RINGQUEUE_H
#define _RINGQUEUE_H
#include <cstring>
#include <VECTOR>
#define MAX_RING_SIXE 150
#define PACKAGE_SIZE 512*1024
//数据包和大小
typedef struct package{
char* rawdata; //数据包buf地址
int len; //数据包大小
int pos; //用于下载时获取下载位置
package(){
rawdata = NULL;
len = ;
pos = ;
}
}TPackage,*PPackage;
//实现一个环形队列对象,注意,在构造和析构中创建和销毁了内存池
class RingQue {
public:
RingQue();
~RingQue();
RingQue(int memSize){
cap = memSize;
}
bool EnQue(TPackage& package);
bool DeQue(TPackage& package);
bool Empty();
bool Full();
size_t Size();
private:
size_t head;
size_t tail;
size_t cap;
std::vector<TPackage> memPool;
// TPackage mem[MAX_RING_SIXE];
};
typedef struct TMemNode{
TMemNode *prev; //前一个内存节点
TMemNode *next; //后一个内存节点
size_t idataSize; //节点大小
bool bUsed; //节点是否正被使用
bool bMemBegin; //是否内存池分配的首地址
void *data; // 当前节点分配的地址
void **pUser; //使用者对象的地址
}TmemLinkNode;
#endif // _RINGQUEUE_H
|
#include <new>
#include "ringque.h"
#include <exception>
using namespace std;
RingQue::RingQue(){
head = ;
tail = ;
cap = MAX_RING_SIXE;
int i = ;
while (i < MAX_RING_SIXE)
{
TPackage tpack;
char* mem = NULL;
mem = new char[PACKAGE_SIZE];
if (NULL == mem)
{
continue;
}
tpack.rawdata = mem;
memPool.push_back(tpack);
++i;
}
cap = memPool.size();
}
RingQue::~RingQue(){
for (int i = ;i <memPool.size();++i)
{
if (memPool[i].rawdata)
{
delete []memPool[i].rawdata;
memPool[i].rawdata = NULL;
}
}
}
bool RingQue::Full(){
return (tail + ) % cap == head;
}
bool RingQue::Empty(){
return (head + ) % cap == tail;
}
bool RingQue::EnQue(TPackage& package){
if (Full())
{
return false;
}
memcpy(memPool[tail].rawdata,package.rawdata,package.len);
memPool[tail].len = package.len;
memPool[tail].pos = package.pos;
tail = (tail + ) % cap;
return true;
}
bool RingQue::DeQue(TPackage& package){
if (Empty())
{
return false;
}
memcpy(package.rawdata,memPool[head].rawdata,memPool[head].len);
package.len = memPool[head].len;
package.pos = memPool[head].pos;
head = (head + ) % cap;
return true;
}
size_t RingQue::Size(){
if (head > tail)
{
return cap + tail - head;
}
else
return tail - head;
}
|
这种方式实现了无锁队列,可以使用。
在读线程中,使用了while(true) 不停的读该无锁队列,但是该方式读取会占用cpu过高,因为不停的查询队列中是否有数据到来,这样很类似select的机制,当然有更先进的机制,或者也可以在队列中实现CallBack_mainProgram的调用,这类似epoll的机制,但这个方法我没有实现,而是采用了更为粗糙的方法,睡眠,这种方式带来的后果是唤醒不及时或者回调不及时,会出现视频码流的拖影。只能将睡眠间隔调到一个折中的时间。这一块还得深入分析。
另外一个值得使用的方法是,Sleep(0)。Sleep()函数的精确度不高,但Sleep(0)的作用是让那些优先级高的线程获得执行的机会,在单线程函数结尾使用该函数,能够降低性能开销。
https://stackoverflow.com/questions/1739259/how-to-use-queryperformancecounter
- 开源实时视频码流分析软件:VideoEye
本文介绍一个自己做的码流分析软件:VideoEye.为什么要起这个名字呢?感觉这个软件的主要功能就是对"视频"进行"分析".而分析是要用眼睛来看的,因此取了&q ...
- (转载)H.264码流的RTP封包说明
H.264的NALU,RTP封包说明(转自牛人) 2010-06-30 16:28 H.264 RTP payload 格式 H.264 视频 RTP 负载格式 1. 网络抽象层单元类型 (NALU) ...
- ECharts外部调用保存为图片操作及工作流接线mouseenter和mouseleave由于鼠标移动速度过快导致问题解决办法
记录两个项目开发中遇到的问题,一个是ECharts外部调用保存为图片操作,一个是workflow工作流连接曲线onmouseenter和onmouseleave事件由于鼠标移动过快触发问题. 一.外部 ...
- sendto频率过快导致发送丢包
编写一个转发模块,虽然没有要求一转多时要达到多少路(不采用组播的情况下,单纯的一路转成多路),但是本着物尽其用的原则,尽可能测试一下极限. 网络环境:1000M,直连,多网卡 系统:Linux ver ...
- 关于ES、PES、PS/TS 码流
一.基本概念 )ES ES--Elementary Streams (原始流)是直接从编码器出来的数据流,可以是编码过的视频数据流(H.264,MJPEG等),音频数据流(AAC),或其他编码 ...
- H264码流打包分析
转自:http://www.360doc.com/content/13/0124/08/9008018_262076786.shtml SODB 数据比特串-->最原始的编码数据 RBSP ...
- H264码流打包分析(精华)
H264码流打包分析 SODB 数据比特串-->最原始的编码数据 RBSP 原始字节序列载荷-->在SODB的后面填加了结尾比特(RBSP trailing bits 一个bit“1”)若 ...
- H264码流解析及NALU
ffmpeg 从mp4上提取H264的nalu http://blog.csdn.net/gavinr/article/details/7183499 639 /* bitstream fil ...
- 【转】打包AAC码流到FLV文件
AAC编码后数据打包到FLV很简单.1. FLV音频Tag格式 字节位置 意义0x08, ...
随机推荐
- SqlServer索引的原理与应用(转载)
SqlServer索引的原理与应用 索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类 ...
- java:LeakFilling (Linux)
1.Nosql 列数据库,没有update,非关系型数据库: 为了解决高并发.高可扩展.高可用.大数据存储问题而产生的数据库解决方案,就是NoSql数据库. NoSQL,泛指非关系型的数据库,NoS ...
- ubuntu下终端代理方法
起因 正常使用shadowsocks后只能在浏览器中访问google,而终端中却无法使用. 解决方法 ProxyChains是一个终端代理方案,使用比较简单. 在源里有这个软件,直接安装 sudo ...
- 【HANA系列】SAP HANA SQL计算某日期是当月的第几天
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA SQL计算某日 ...
- php composer 开发自己的包
以往都是在项目直接写自己的包文件,并没有把他放在packagist上面,以composer来管理使用. 今天没事来整一下,供大家一起学习 一,在github和packagist分别注册自己的账号,这里 ...
- NativeContainer
安全系统复制数据的过程的缺点是它还隔离了每个副本中作业的结果.要克服此限制,您需要将结果存储在一种名为NativeContainer的共享内存中. 什么是NativeContainer? A Nati ...
- 手写一个简单到SpirngMVC框架
spring对于java程序员来说,无疑就是吃饭到筷子.在每次编程工作到时候,我们几乎都离不开它,相信无论过去,还是现在或是未来到一段时间,它仍会扮演着重要到角色.自己对spring有一定的自我见解, ...
- mysql命令行备份方法
一.mysql备份 1.备份命令 格式:mysqldump -h主机IP -P端口 -u用户名 -p密码 --database 数据库名 > 文件名.sql # 本地备份可以不添加端口和主机IP ...
- Linux C/C++基础——内存分区
1.内存分区 在生活中,为了提高办事效率,某个单位经常会分成N个部门,每个部门职责不同,同样,为了提高 效率,我们的内存也会被分成N个区.这里我们将内存分为五个区.也有四区模型. 首先看一下一个二进制 ...
- C++学习笔记-C++与C语言的一些区别
本文主要是整理一些C++与C的一些小的区别,也就是在使用C与C++时候需要注意的一些问题,C++是以C语言为基础的,并且完全兼容C语言的特性 注释 C语言的注释形式为 /* 注释内容 */ 而C++提 ...