Qualcomm_Mobile_OpenCL.pdf 翻译-9-OpenCL优化用例的学习
在这一章中,将会用一些例子来展示如何使用之前章节中讨论的技术来进行优化。除了一些小的简单代码片段的展示外,还有两个熟知的图像滤波处理,Epsilon滤波和Sobel滤波,将会使用之前章节中讨论的方法进行一步一步地优化。
9.1 应用程序的代码样本
9.1.1 提升算法
这个例子说明了如何简化代码来提升性能。给定一张图片,对它进行8x8的box模糊滤波。
优化前的原始kernel代码:
__kernel void ImageBoxFilter(__read_only image2d_t source,
__write_only image2d_t dest,
sampler_t sampler)
{
... // variable declaration
for( int i = 0; i < 8; i++ )
{
for( int j = 0; j < 8; j++ )
{
coor = inCoord + (int2) (i - 4, j - 4 );
// !! read_imagef is called 64 times per work item
sum += read_imagef( source, sampler, coor);
}
}
// Compute the average
float4 avgColor = sum / 64.0f;
... // write out result
}
为了减少texture访问,将上面的kernel函数分成两个步骤。第一个步骤,每个work item计算一个2x2的平均值,并将结果存放到临时的image中。第二个步骤使用临时的image进行最终的计算。
修改后的kernel
// First pass: 2x2 pixel average
__kernel void ImageBoxFilter(__read_only image2d_t source,
__write_only image2d_t dest,
sampler_t sampler)
{
... // variable declaration
// Sample an 2x2 region and average the results
for( int i = 0; i < 2; i++ )
{
for( int j = 0; j < 2; j++ )
{
coor = inCoord - (int2)(i, j);
// 4 read_imagef per work item
sum+=read_imagef(source,sampler,inCoord-(int2)(i,j));
}
}
//equivalent of divided by 4,in case compiler does not //optimize
float4 avgColor = sum * 0.25f;
... // write out result
}
// Second Pass: final average
__kernel void ImageBoxFilter16NSampling( __read_only image2d_t source,
__write_only image2d_t dest,
sampler_t sampler)
{
... // variable declaration
int2 offset = outCoord - (int2)(3,3);
// Sampling 16 of the 2x2 neighbors
for( int i = 0; i < 4; i++ )
{
for( int j = 0; j < 4; j++ )
{
coord = mad24((int2)(i,j), (int2)2, offset);
// 16 read_imagef per work item
sum += read_imagef( source, sampler, coord ); }
}
// equivalent of divided by 16, in case compiler does not // optimize
float4 avgColor = sum * 0.0625;
... // write out result
}
修改后的算法每个work item 只获取20(4+16)次 image buffer,明显比原始的64次read_imagef获取次数少很多。
9.1.2 向量化的装载和存储
这个例子说明如何在Adreno GPUs上使用向量化的装载和存储而更好地利用了带宽。
优化前的原始代码:
__kernel void MatrixMatrixAddSimple( const int matrixRows,
const int matrixCols,
__global float* matrixA,
__global float* matrixB,
__global float* MatrixSum)
{
int i = get_global_id(0);
int j = get_global_id(1);
// Only retrieve 4 bytes from matrixA and matrixB.
// Then save 4 bytes to MatrixSum.
MatrixSum[i*matrixCols+j] =
matrixA[i*matrixCols+j] + matrixB[i*matrixCols+j];
}
修改后的代码
__kernel void MatrixMatrixAddOptimized2( const int rows,
const int cols,
__global float* matrixA,
__global float* matrixB,
__global float* MatrixSum)
{
int i = get_global_id(0);
int j = get_global_id(1);
// Utilize built-in function to calculate index offset
int offset = mul24(j, cols);
int index = mad24(i, 4, offset);
// Vectorize to utilization of memory bandwidth for //performance gain.
// Now it retieves 16 bytes from matrixA and matrixB.
// Then save 16 bytes to MatrixSum
float4 tmpA = (*((__global float4*)&matrixA[index])); // //Alternatively
vload and vstore can be used in here
float4 tmpB = (*((__global float4*)&matrixB[index]));
(*((__global float4*)&MatrixSum[index])) = (tmpA+tmpB);
// Since ALU is scalar based, no impact on ALU operation.
}
新的kernel使用float4来实现向量化的装载/存储。因为向量化,新的kernel的global work size是之前的kernel的1/4.
9.1.3 使用image替代buffer
这个例子是对给定500万对向量计算每一对向量的点积。原始代码是使用buffer对象,修改完后,使用texture对象(read_imagef)来提升常用数据的访问性能。这是一个简单的例子,但是使用到的技术可以适用到许多类似情况,这些情况下buffer对象的访问不如texture对象访问有效。
|
优化前的原始kernel函数 |
优化后的kernel函数 |
|
__kernel void DotProduct(__global const float4 *a, __global const float4 *b,__global float *result){ // a and b contain 5 million vectors each // Arrays are stored as linear buffer in global memory result[gid] = dot(a[gid], b[gid]); } |
__kernel void DotProduct(__read_only image2d_t c, __read_only image2d_t d, __global float *result){ // Image c and d are used to hold the data instead of linear buffer // read_imagef goes through the texture engine int2 gid = (get_global_id(0), get_global_id(1)); result[gid.y * w + gid.x] = dot(read_imagef(c, sampler, gid), read_imagef(d, sampler, gid)); } |
9.2 Epsilon 滤波
Epsilon滤波被广泛用在图像处理中用来减少蚊式噪音,这种噪音是一种发生在高频区域(比如图像的边)的缺陷。这种滤波是非线性的和基于点式的低通滤波,支持空间的变化,而且只有特定阈值的像素点会被滤掉。
在这个例子中,Epsilon滤波仅被用在YUV图像中的Y通道,因为噪音经常在这个通道可见。另外,假设Y通道是连续存储的(NV12格式),与UV通道的存储分开。Figure9-1阐述了滤波算法的两个基本步骤:
n 对于一个要滤波的像素点,计算9x9的范围内所有像素点到中心像素点的绝对差值。
n 如果绝对值小于一个阈值,这个邻居像素点就用来平均。注意,阈值通常是在程序中预先定义的一个常量。

图9-1 Epsilon 滤波算法
9.2.1 第一次的实现
这个程序计算的YUV图片的分辨率是3264x2448(宽度是3264,高度是2448),每个像素点是8位的数据宽度。这里说的性能数据是基于Snadragon 810(MSM8994,Adreno 430 )的高性能模式。
下面是第一次实现的参数和策略:
- 使用OpenCL的image对象替代buffer对象。
- 使用image替代buffer能够避免边界检测和充分利用Adreno GPUs中的L1 cache。
- 使用CL_R | CL_UNORM_INT8图片格式/数据类型
- 单个通道,比如这里的Y通道,而且读取到SP的像素点,都被Adreno GPUs内建的texture管道归一化到[0,1]。
- 每个work item 处理一个输出的元素。
- 使用2D的kernel,global 的worksize大小被设置为[3264,2448].
在这个实现中,每个work item需要获取81个浮点类型的像素点。在Adreno A430上这个实现的性能数据作为进一步优化的基准。
9.2.2数据包优化
通过比较计算量和数据装载量,这个例子明显是内存瓶颈。因此,主要的优化是如何提升数据的装载效率。
首先需要注意到,使用32位的浮点来表示像素点是对内存的浪费。对许多图像处理算法来说,8位或者16位的数据类型就够用了。因为Adreno GPUs对16位浮点类型有内嵌的硬件支持,比如half或者fp16,所以可以使用下面的优化方法:
- 使用16位浮点数据类型来替换32位浮点
- 现在每个work item获取81个half 数据
- 使用CL_RGBA| CL_UNORM_INT8图像类型或者数据类型
- 使用CL_RGBA 去装载4个通道能更好的的利用TP的带宽。
- 使用read_imagef 替代read_imageh。TP会将数据自动转换成16位half数据。
- 每个work item
- 每行使用3个half4向量
- 输出一个已经被处理的像素点
- 对于每一个输出的像素点,访问的内存数是3x9 = 27 (half4)
- 性能提升1.4x
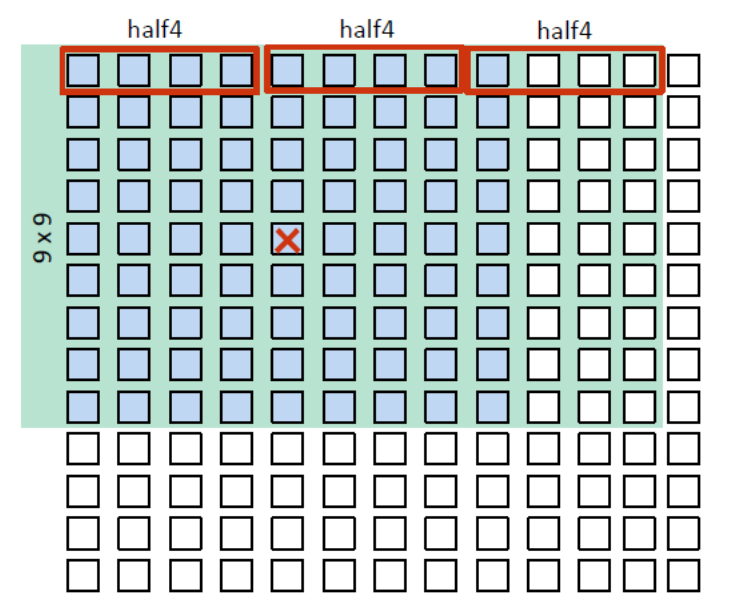
图9-2 使用16位 half类型(fp16)打包数据
9.2.3 向量化装载/存储优化
在之前的步骤中,只要计算一个输出像素,就有很多邻居像素点需要装载。可以通过额外装载一些像素点,那么久可以滤波更多的像素点,如下所示:
- 每个work item
- 每一行读3个half4的向量
- 输出4个像素
- 每个输出像素点需要获取的内存数量是:3x9/4 = 6.75(half4)
- 全局的work size:(width/4)x height
- 对每一行循环展开。
- 在每一行内,使用活动窗口的方法。

图9-3 每一个work item滤波更多的像素点
图9-3 阐述了通过装载额外的像素点,处理多个像素的方法。以下是几个具体的步骤:
Read center pixel c;//读取中心像素点c
For row = 1 to 9, do://从行1到行9,执行以下操作
read data p1;//读取数据p1
Perform 4 computation with pixel c;//对c执行1次计算
read data p2;//读取数据p2
Perform 4 computations with pixel c; //对c执行4次计算
read data p3;//读取数据p3
Perform 4 computations with pixel c; //与c执行4次计算
end for//结束循环
write results back to pixel c.//将结果写回中心像素点
通过这些步骤,性能比基准性能提高了3.4x。
9.2.4 进一步提升每个work item的工作量
提升每个work item的工作量,性能可能会有所提升。下面是一些可选的操作:
- 读取多个half4向量,提升输出的像素个数到8个。
n 全局的work size : width/8 xheight
n 每个work item
- 每一行读4个half4 向量。
- 输出8个像素
- 每个输出像素点需要访问的内存次数为:4x9/8 = 4.5 (half4)
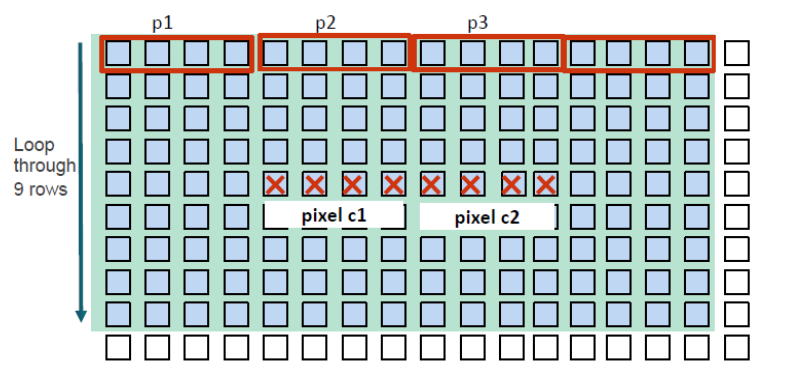
图9-4 每个work item 处理8个像素点
这些改变仅提升了很少的性能(仅提升0.1x),下面是为什么这么做不起作用的原因:
- 在cache命中率上没有很大的改变,这个在之前的步骤上已经做的很好了。
- 更多的寄存器被使用,导致了更少的wave,这将会损失平行性和延迟的隐藏性。
为了实验的目的,下面的方法可以装载更多的像素点:
- 读取更多的half4的向量,提升输出像素点的个数到16.
- 全局的work size: width/16 xheight
图9-5 表示了每个work item 会执行以下几个步骤:
- 每行读6个half4个向量。
- 输出16个像素点
- 每个输出像素点需要访问的内存次数为:6x9/16 = 3.375(half4)
经过这些改变后,性能从3.4x退化到0.5x。装载更多的像素点进入kernel中会引起寄存器溢出,这将会严重地损害性能。
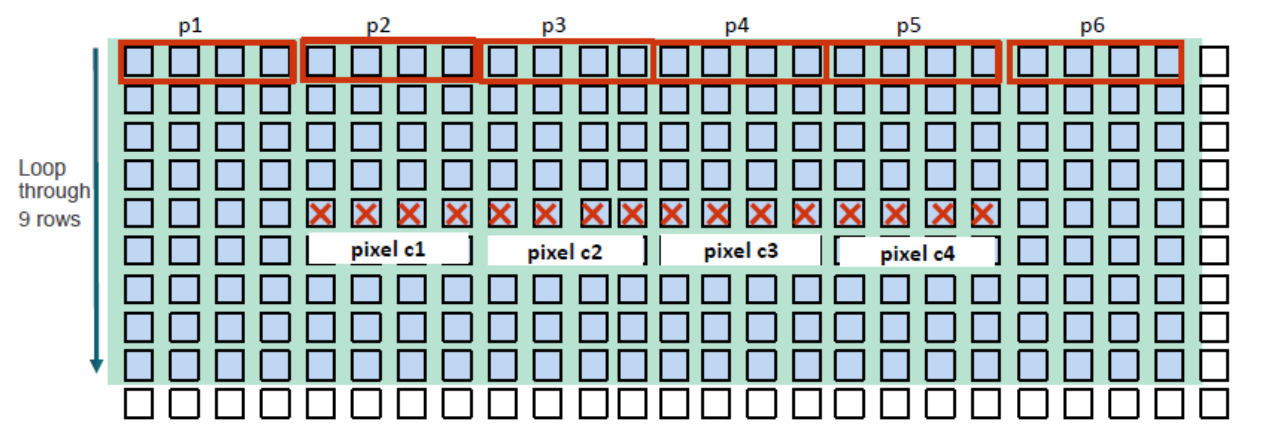
图9-5 每个work item处理16个像素
9.2.5 使用本地内存优化
本地内存比全局内存有更短的延迟,因为本地内存是片上内存。一个选择是,将像素点装载进本地内存,避免重复从全局内存中加载。而且,对于要处理的中心元素,由于9x9范围的滤波,所以它周围的元素也需要,所以如图9-6所示,装载进内存。

图9-6 使用本地内存进行Epsilon 滤波
表9-1 列出了两种情况的设置和他们的性能。整体性能比原始的要更好,然而从9.3.4节中可以看出,并没有获得最好的性能。
表9-1 使用本地内存的性能
|
情况1 |
情况2 |
|
|
workgroup |
8x16 |
8x24 |
|
本地内存大小(byte) |
10x18x8=1440 |
10x26x8 = 2080 |
|
性能 |
2.4x |
2.8x |
如7.1.1节所讨论的,本地内存使用时,通常需要使用barrier进行workgroup中work item之间的同步,这样会导致性能不比使用全局内存时的好。而且,如果同步导致许多开销的话,它可能会有更差的性能。在这种情况下,如果全局内存有高cache命中率的话,那么全局内存可能是一个更好的选择。
9.2.6 分支操作的优化
Epsilon滤波需要进行像素之间的比较,如下:
Cond = fabs(c -p) <= (half4)(T);
sum += cond ? p : consth0;
cnt += cond ? consth1 : consth0;
三元素符 ?: 是发生在硬件上的分支,因为同一个wave中的不是所有的fiber都会执行相同的分支。分支操作可以被ALU 操作替代,如下所示:
Cond = convert_half4(-(fabs(c -p) <= (half4)(T)));
sum += cond * p;
cnt += cond;
这种优化方法之前就应用在9.2.2章中描述过的一个例子中,性能从3.4x提升到5.4x。
这个操作的关键差异是,新代码是在高度并行的ALU下执行,而且在同一个wave中所有的fiber基本上执行的是同一块代码,尽管变量Cond可能有不同的值,而原来的代码会使用非常耗时的硬件逻辑来处理分支。
9.2.7 总结
表9-2总结了优化的步骤和性能数据。最初,算法是内存瓶颈的。通过数据打包,向量化装载,它变成ALU瓶颈。总的来说,对于这个例子的关键是优化装载数据的方式。许多其他的内存瓶颈的用例可以使用相似的技术来加速。
表9-2 优化和性能的总结
|
步骤 |
优化方法 |
imag类型 |
kernel中的数据类型 |
向量化操作 |
速度提升 |
|
1 |
最初的GPU实现 |
CL_R | CL_UNORM_INT8 |
float |
1-pixlel/work item |
|
|
2 |
在kernel中使用half类型 |
CL_R | CL_UNORM_INT8 |
half |
1.0x |
|
|
3 |
数据打包 |
CL_RGBA| CL_UNORM_INT8 |
1.4x |
||
|
4 |
向量化处理 循环展开 |
4-pixel/work item (halt4 output) |
3.4x |
||
|
5 |
每个work item处理更多的像素 |
8-pixel/work item |
3.5x |
||
|
6 |
每个work item处理更多的像素 |
16-pixel/work item |
0.5x |
||
|
4-1 |
使用LM (workgroup 大小为8x16) |
4-pixel/work item |
2.4x |
||
|
4-1-1 |
使用LM (workgroup 大小为8x24) |
2.8x |
|||
|
4-1-2 |
使用LM移除分支操作,workgroup大小为8x24 |
2.9x |
|||
|
4-2 |
移除分支操作 |
5.4x |
表9-3中展示了在三种分辨率的图片上使用Epsilon滤波后的OpenCL性能。从图中可以看出,越大的图像,性能提升越大。对于一个3264x2448的图像,可以看到有5.4x的性能提升,相比之言,在512x512的图像上,优化后的代码性能比最初的OpenCL代码的性能,只有4.3x的提升。这是很容易理解的,因为在不考虑任务量的情况下,消耗的时间与kernel的执行时间是正相关的,而且任务量越大,他在整个性能数据中的权重越小。
表9-3 不同分辨率的图片的性能统计
|
图片的分辨率 |
512x512 |
1920x1080 |
3245x2448 |
|
|
像素点的个数 |
0.26MP |
2MP |
8MP |
|
|
设备(A430) |
GPU的最初实现结果 |
1x |
1x |
1x |
|
GPU优化后的结果 |
4.3x |
5.2x |
5.4x |
|
9.3 Sobel 滤波
Sobel滤波,也被称作Sobel操作,用在很多图像处理和计算机视觉算法的边界检测中。它使用两个3x3的kernels与原始图片结合,近似得出导数。这里有两个kernel:一个负责水平方向,一个负责垂直方向,如图9-7所示:
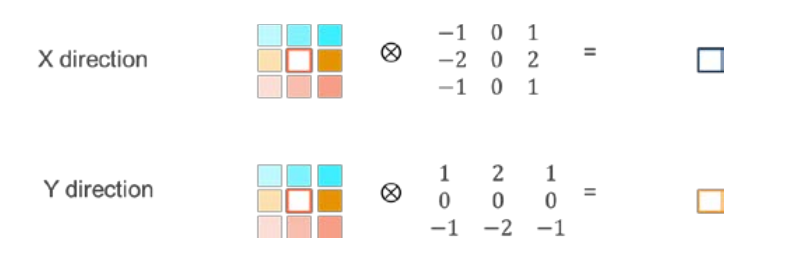
图9-7 Sobel滤波的两个方向操作
9.3.1 算法优化
Sobel的滤波是一个可分离的滤波器,可以如下分解:
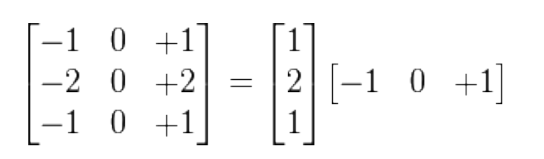
图9-8 Sobel 滤波分离
相比于不可分离的2D滤波,一个可分离的2D滤波器可能将复杂度从O(n2)降低到O(n)。由于2D的高复杂性和计算的耗时,理想的情况就是使用可分离的滤波器。
9.3.2 数据打包的优化
尽管可分离的滤波,已经减少了很多计算,但是每一个要被滤波的像素点所需要的像素点个数是一样的,比如对3x3kernel来说,需要8个邻居像素点加上中心像素点。可以明显地看出来,这个一个内存瓶颈的问题。所以,如果有效的将像素点装载进GPU是性能优化的关键。下面的图片中阐述了3种可以使用的选择:

图9-9 每个work item处理一个像素点,每个kernel装载3x3个像素点
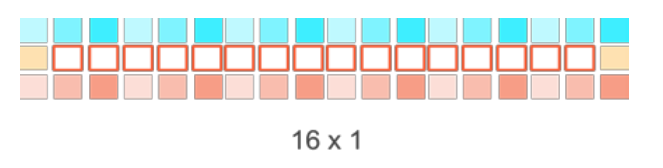
图9-10 处理16x1 个像素点,装载18x3个像素点
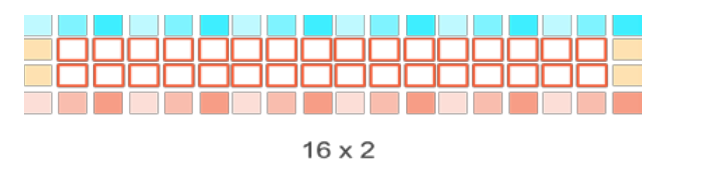
图9-11 处理16x2个像素点,装载18x4个像素点
下面的表格中总结了每种情况下总的字节数和平均字节数。对于表9-9所述的第一个种情况,每个work item只对一个像素点进行Sobel滤波。随着每个工作项处理的像素点的个数的增加,需要装载的数据数量将会减少,如9-10和9-11所示。这将会减少全局内存到GPU的数据量,从而提升性能。
表9-4 3种情况下数据装载/存储的数量
|
1 pixel/work item |
16x1 pixels/work item |
16x2 pixels/work item |
|
|
总的输入字节数 |
9 |
54 |
72 |
|
平均输入字节数 |
9 |
3.375 |
2.25 |
|
平均存储字节数 |
2 |
2 |
2 |
9.3.3 向量化的装载/存储优化
对于16x1 和16x2 这两种情况,装载/存储的次数可以通过使用OpenCL中的向量化装载存储函数进行进一步的减少,比如float4,Int4和char4等。表9-5表示了使用了向量化的情况下,需要的装载/存储的次数(假设像素的数据类型是8-bit)。
表9-5 使用向量化的装载/存储方法需要的装载和存储次数
|
16x1 向量化 |
16x2 向量化 |
|
|
装载 |
6/16=1.375 |
8/32=0.374 |
|
存储 |
2/16=0.125 |
4/32 = 0.125 |
下面是一小段向量化装载的代码:
short16 line_a = convert_short16(as_uchar16(*((__global uint4
*)(inputImage+offset))));
如下,在边界处,需要装载两个像素
short2 line_b = convert_short2(*((__global uchar2 *)(inputImage + offset +16)));
注意:每个工作项处理像素点的数量提升可能会导致严重的寄存器使用空间的压力,从而导致寄存器溢出到私有内存和性能下降。
9.3.4 性能统计和总结
在使用了两种优化步骤之后,可以看到性能的显著提升,如图9-12所示,图中在MSM8994(Adreno418)上的原始算法性能(每个work item处理单个像素点)被归一化为1.

图9-12 通过使用数据打包和向量化装载/存储带来的性能提升
为了总结,下面是这个用例优化的几个关键点:
- 数据打包提升了内存访问效率
- 向量化装载/存储是减少内存繁忙的关键点。
- 在这种情况下,优先选择更短的数据类型比如整型或者char型。
在这种情况下,没有使用本地内存。数据打包和向量化的装载/存储已经最小化了可复用数据的重叠。因此,使用本地内存并不能提升性能。
可能还存在其他的提升性能的选项,比如使用texture来替换global buffer。
9.4 总结
在这一章节中提供了一些简单的例子和代码片段来证实了前几章说明的优化规则,并且指出了性能是如何改变的。开发者可以尝试在真实的设备上使用这些步骤。由于编译器和驱动的升级,这些结果可能不会被准确的重现。但是,一般地,通过这些优化步骤,肯定会实现同样的性能提升。
Qualcomm_Mobile_OpenCL.pdf 翻译-9-OpenCL优化用例的学习的更多相关文章
- Qualcomm_Mobile_OpenCL.pdf 翻译-5-性能优化的概述
这章提供了一个OpenCL应用程序优化的总体概述.更多的细节将会在接下来的章节中找到. 注意:OpenCL程序的优化是具有挑战性的.相比初始的程序开发工作,经常需要做更多的工作. 5.1 性能移植性 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-4-Adreno OpenCL的程序开发
这章将简要讨论一些开发Adreno OpenCL应用程序的基本要求,下面将会介绍如何调试和统计程序性能. 4.1 安卓平台上开发OpenCL程序 目前,Adreno GPU主要是在安卓操作系统和在部 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-8-kernel性能优化
这章将会说明一些kernel优化的小技巧. 8.1 kernel合并或者拆分 一个复杂的应用程序可能包含很多步骤.对于OpenCL的移植性和优化,可能会问需要开发有多少个kernel.这个问题很难回答 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-7 内存性能优化
内存优化是最重要也是最有效的OpenCL性能优化技术.大量的应用程序是内存限制而不是计算限制.所以,掌握内存优化的方法是OpenCL优化的基础.在这章中,将会回顾OpenCL的内存模型,然后是最优的实 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-10-总结
这篇文档主要是介绍了关于在Adreno GPUs上优化OpenCL代码的详细方法.文档中提供的大量信息能够帮助开发者理解OpenCL基础和Adreno结构,还有最重要的,掌握OpenCL优化技能. O ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-6-工作组尺寸的性能优化
对于许多kernels来说,工作组大小的调整会是一种简单有效的方法.这章将会介绍基于工作组大小的基础知识,比如如何获取工作组大小,为什么工作组大小非常重要,同时也会讨论关于最优工作组大小的选择和调整的 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-2
2 Opencl的简介 这一章主要讨论Opencl标准中的关键概念和在手机平台上开发Opencl程序的基础知识.如果想知道关于Opencl更详细的知识,请查阅参考文献中的<The OpenCL ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-1
1 前言 1.1 目的 这篇文档的主要目的是,向原始设备制造商(OEMs),独立软件供应商(ISVs),第三方开发者们,提供在基于高通骁龙400系列.600系列,和800系列的手机平台和芯片上进行开发 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-3
3 在骁龙上使用OpenCL 在今天安卓操作系统和IOT(Internet of Things)市场上,骁龙是性能最强的也是最被广泛使用的芯片.骁龙的手机平台将最好的组件组合在一起放到了单个芯片上,这 ...
随机推荐
- 使用 sed 命令查找和替换文件中的字符串的 16 个示例
当你在使用文本文件时,很可能需要查找和替换文件中的字符串.sed 命令主要用于替换一个文件中的文本.在 Linux 中这可以通过使用 sed 命令和 awk 命令来完成. 在本教程中,我们将告诉你使用 ...
- Android如何使用Https与Nohttp框架使用
什么是Https? HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全 ...
- OpenStack RPM Sample 解析
目录 文章目录 目录 前言 RPM 打包环境安装 RPM 打包流程 OpenStack RPM SPEC Sample RPM 升级/回退 前言 软件功能升级,尤其是 Python 这类解析型语言的软 ...
- 配置pip镜像源(转)
使用pip安装python扩展时,如若没有配置国内镜像源,在未翻墙的情况下,其下载速度将会特别缓慢.因此,有些时候我们必须使用国内镜像源,来解决pip下载安装速度慢的问题,比较常用的国内镜像包括: 阿 ...
- LoadRunner 技巧之 添加事务
事务(Transaction)用于模拟用户的一个相对完整的.有意义的业务操作过程,例如登录.查询.交易.转账,这些都可以作为事务,而一般不会把每次HTTP请求作为一个事务. 拿笔者所测试的邮箱系统为例 ...
- Python字符和字符值(ASCII或Unicode码值)转换方法
Python字符和字符值(ASCII或Unicode码值)转换方法 这篇文章主要介绍了Python字符和字符值(ASCII或Unicode码值)转换方法,即把字符串在ASCII值或者Unicode值之 ...
- 关机命令 shutdown
参考资料:[http://jingyan.baidu.com/article/49ad8bce705f3f5834d8faec.html]
- Tensorflow 对上一节神经网络模型的优化
本节涉及的知识点: 1.在程序中查看变量的取值 2.张量 3.用张量重新组织输入数据 4.简化的神经网络模型 5.标量.多维数组 6.在TensorFlow中查看和设定张量的形态 7.用softmax ...
- PEP8-python编码规范(上)
包含主要 Python 发行版中的标准库的 Python 代码的编码约定. 1.代码缩进 (1)每个缩进需要使用 4 个空格.一般使用一个Tab键. Python 3 不允许混合使用制表符和空格来缩进 ...
- 【VS开发】【图像处理】双边滤波器bilateral filter
目录(?)[-] 简介 原理 代码实现 1 Spatial Weight 2 Similarity Weight 3 Color Filtering 在SSAO中的使用 1. 简介 图像平滑是一个重要 ...