Task9.Attention
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。

图1 人类的视觉注意力
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
上图形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Encoder-Decoder框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图2是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
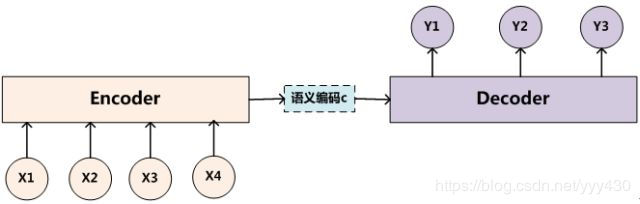
图2 抽象的文本处理领域的Encoder-Decoder框架
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
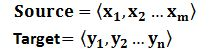
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息:
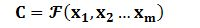
来生成i时刻要生成的单词:
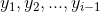
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,图2所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
Soft Attention模型
这里先以机器翻译作为例子讲解最常见的Soft Attention模型的基本原理,之后抛离Encoder-Decoder框架抽象出了注意力机制的本质思想,然后简单介绍最近广为使用的Self Attention的基本思路。
图2中展示的Encoder-Decoder框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
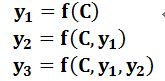
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子Source的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
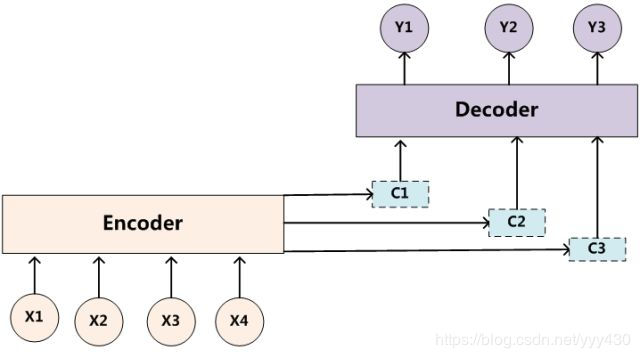
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如图3所示。
即生成目标句子单词的过程成了下面的形式:
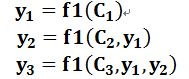
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
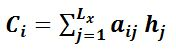
其中,Lx代表输入句子Source的长度,aij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而hj则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似图4。
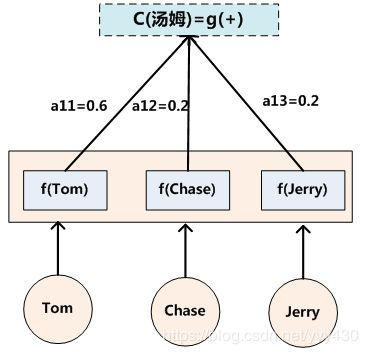
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
为了便于说明,我们假设对图2的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图2的框架转换为图5。

图5 RNN作为具体模型的Encoder-Decoder框架
那么用图6可以较为便捷地说明注意力分配概率分布值的通用计算过程。
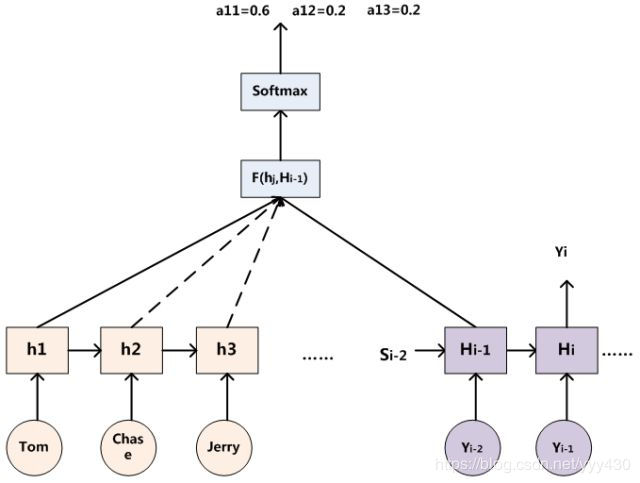
图6 注意力分配概率计算
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值Hi-1的,而我们的目的是要计算生成Yi时输入句子中的单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态Hi-1去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
绝大多数Attention模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。图7可视化地展示了在英语-德语翻译系统中加入Attention机制后,Source和Target两个句子每个单词对应的注意力分配概率分布。
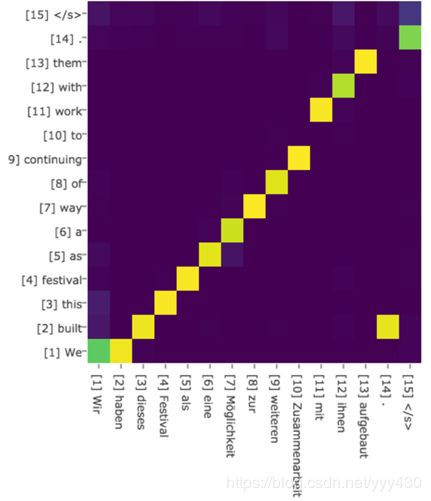
图7 英语-德语翻译的注意力概率分布
上述内容就是经典的Soft Attention模型的基本思想,那么怎么理解Attention模型的物理含义呢?一般在自然语言处理应用里会把Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型,这是非常有道理的。
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
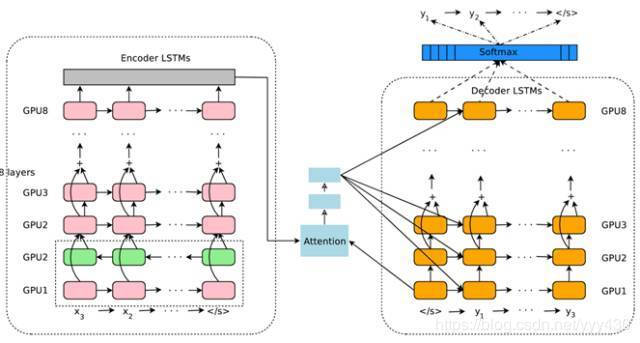
图8 Google 神经网络机器翻译系统结构图
图8所示即为Google于2016年部署到线上的基于神经网络的机器翻译系统,相对传统模型翻译效果有大幅提升,翻译错误率降低了60%,其架构就是上文所述的加上Attention机制的Encoder-Decoder框架,主要区别无非是其Encoder和Decoder使用了8层叠加的LSTM模型。
考试之前总结的:


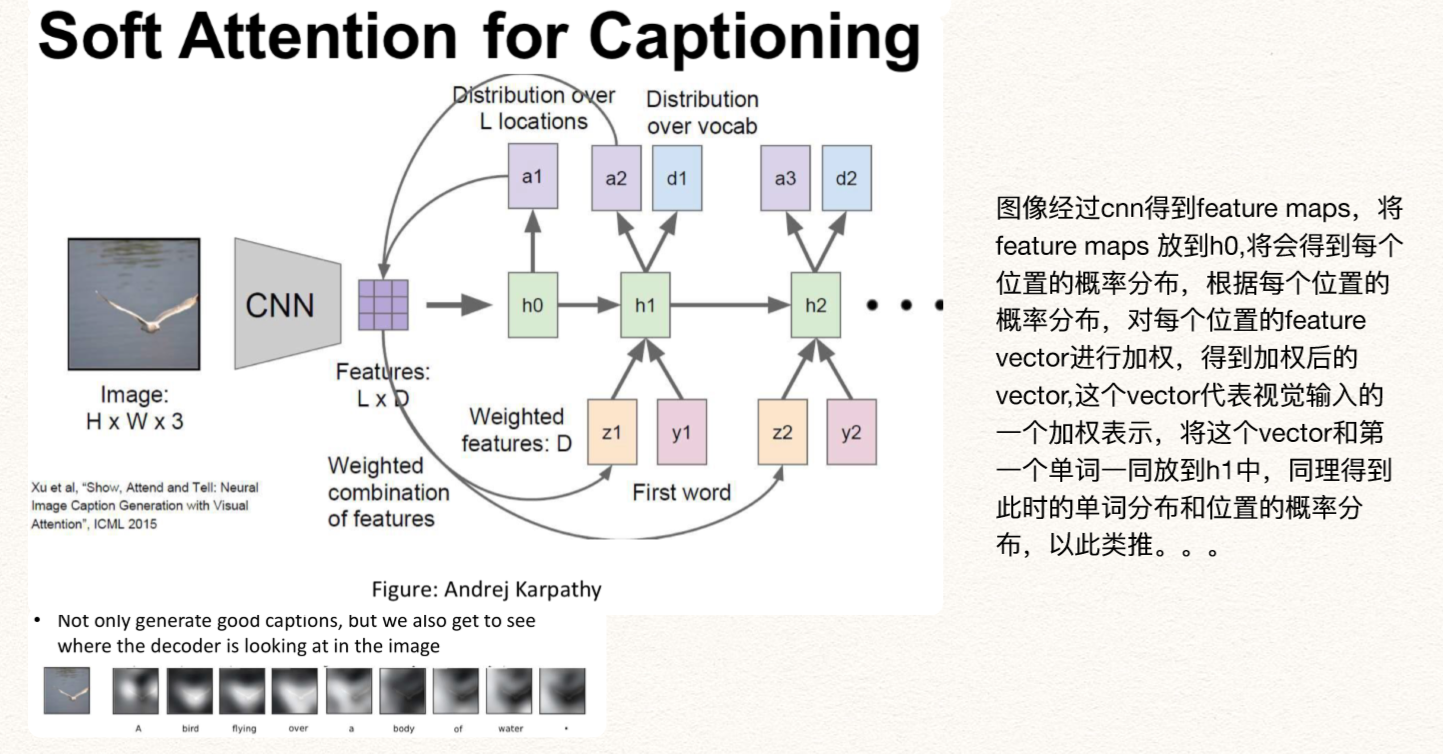
HAN的原理(Hierarchical Attention Networks)
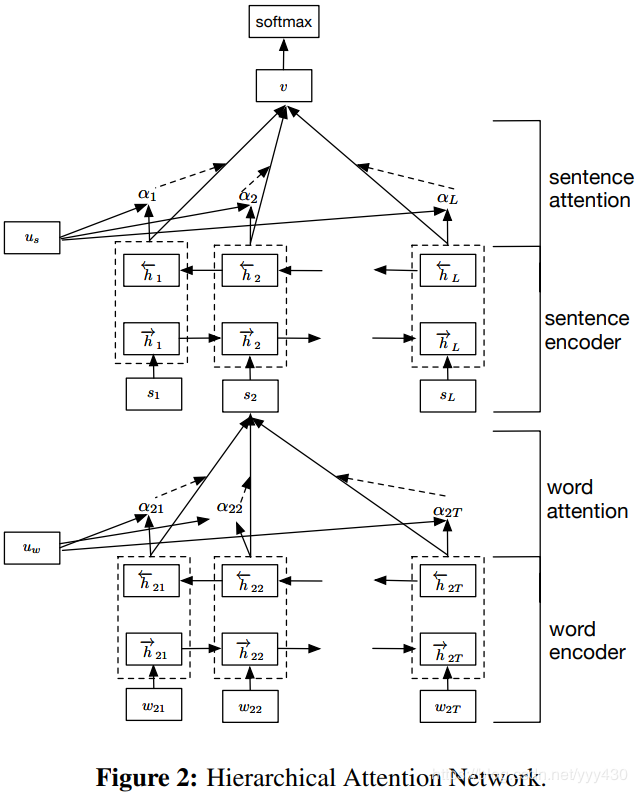
HAN模型就是分层次的利用注意力机制来构建文本向量表示的方法。
文本由句子构成,句子由词构成,HAN模型对应这个结构分层的来构建文本向量表达;
文本中不同句子对文本的主旨影响程度不同,一个句子中不同的词语对句子主旨的影响程度也不同,因此HAN在词语层面和句子层面分别添加了注意力机制;
分层的注意力机制还有一个好处,可以直观的看出用这个模型构建文本表示时各个句子和单词的重要程度,增强了可解释性。
这篇论文里面使用双向GRU来构建句子表示和文本表示,以句子为例,得到循环神经网络中每个单元的输出后利用注意力机制整合得到句子向量表示(不使用attention时,一般会使用MAX或AVE),过程如下:
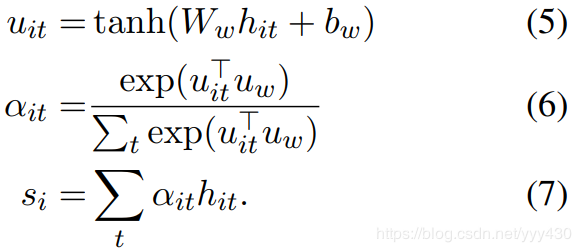
按照文中说法,先经过一层MLP得到隐层表示;然后与word level context vector (词语级别的context vector)做点积,各词语得到的结果再经过softmax函数后的结果就是各自的重要程度,即;最后加权和得到句子表示。文本向量的构建与此一致,之后经过全连接层和softmax分类。
参考:https://blog.csdn.net/yyy430/article/details/88635646
Task9.Attention的更多相关文章
- Attention:本博客暂停更新
Attention:本博客暂停更新 2016年11月17日08:33:09 博主遗产 http://www.cnblogs.com/radiumlrb/p/6033107.html Dans cett ...
- attention 机制
参考:modeling visual attention via selective tuning attention问题定义: 具体地, 1) the need for region of inte ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network 5vision groups 摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性.(前段时间做 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- PowerVault TL4000 Tape Library 告警:“Media Attention”
Dell PowerVault TL4000 磁带库机的指示灯告警,从Web管理平台登录后,在菜单"Library Status"下发现如下告警信息: Library Sta ...
- paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
1. 早期C. Koch与S. Ullman的研究工作. 他们提出了非常有影响力的生物启发模型. C. Koch and S. Ullman . Shifts in selective visual ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- (转)Attention
本文转自:http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.ht ...
随机推荐
- Android Build System Ultimate Guide
Android Build System Ultimate Guide April 8,2013 Lately, Android Open Source Project has gone throug ...
- 查看磁盘和文件的使用情况df和du
df, du: disk filesystem, disk usage. df : 查看一级目录的使用情况, df -h du: 则是可以查看目录或者某个文件的占用磁盘空间的情况, du -h: 使用 ...
- 如何吸引用户打开自己发送的EDM邮件
一般来说,邮件发送到用户的收件箱,但用户不一定会阅读.因为每个用户收到的邮件都很多.那么,究竟应该如何吸引读者打开自己的EDM邮件呢? 只有当用户认识并信任发件人的时候,此时邮件的打开率是最高的,可以 ...
- @TableLogic表逻辑处理注解(逻辑删除)
在字段上加上这个注解再执行BaseMapper的删除方法时,删除方法会变成修改 例: 实体类: @TableLogic private Integer del; service层: 调用Ba ...
- Codeforces Round #573
http://codeforces.com/contest/1191 A 给一个数,可以加0,1或2然后取模,再映射到字母,字母有排名,求最大排名. 总共只有4种情况,讨论即可 #include< ...
- 深入理解webpack基本配置(一)
1. 安装webpack到全局 在学习构建之前,我们来在本地文件新建一个存放项目的文件夹,比如叫demo1这个项目,然后进入demo1该项目的根目录后,执行命令 npm init运行下,一路回车(先简 ...
- 类StringBuffer
1字符串声明和创建 public StringBuffer() 无参构造函数 public StringBuffer(int capacity) 指定容量的字符串缓冲区对象 public String ...
- 如何统计序列中元素的频度---Python数据结构与算法相关问题与解决技巧
实际案例: 1. 某随机序列 [12,5,6,4,6,5,5,7]中,找到出现次数最高的3个元素,它们出现的次数是多少? 2. 对于某英文文章的单词,进行词频统计,找到出现次数最高的10个单词,它们出 ...
- nginx-->基本使用
Nginx基本使用 一.下载 http://nginx.org/en/download.html 二.解压文件 在当前文件夹下通过终端就可以操作nginx nginx -v 三.配置详解 #use ...
- python+selenium下拉列表option对象操作方法二
options = driver.find_elements_by_tag_name('option') #获取所有的option子元素 o ...