NEO4J亿级数据导入导出以及数据更新
1、添加配置
apoc.export.file.enabled=true
apoc.import.file.enabled=true
dbms.directories.import=import
dbms.security.allow_csv_import_from_file_urls=true
2、导出操作
CALL apoc.export.csv.all('C:\\Users\\11416\\.Neo4jDesktop\\neo4jDatabases\\database-bcbe66f8-2f8f-4926-a1b8-bbdb0c4c6409\\installation-3.4.1\\data\\back\\db.csv',{stream:true,batchSize:2})
db.csv文件内容样例
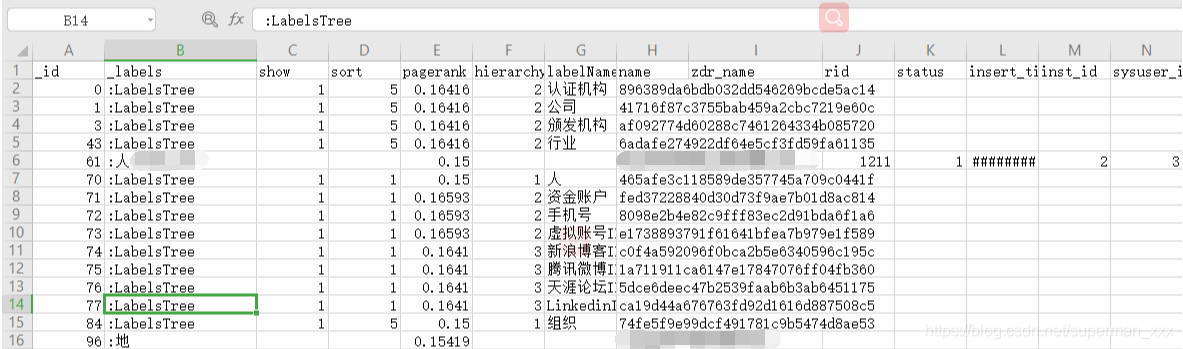
3、导入操作
// 导入大量数据不适用
CALL apoc.load.csv('C:\\Users\\11416\\.Neo4jDesktop\\neo4jDatabases\\database-bcbe66f8-2f8f-4926-a1b8-bbdb0c4c6409\\installation-3.4.1\\data\\back\\db.csv') yield lineNo, map, list
RETURN *
// 支持在开放事务中提交-使用之前需要先安装存储过程库
CALL apoc.periodic.iterate(
'CALL apoc.load.csv("file:/C:/Users/11416/.Neo4jDesktop/neo4jDatabases/database-06767a53-355b-44eb-b8a8-0156dff8f8e1/installation-3.4.1/import/test.csv") yield map as row return row',
'merge (n:Label {name:row.Linkin}) with * merge (m:Mark {name:row.学校}) with * merge (n)-[r:教育经历]->(m)'
,{batch:10000, iterateList:true, parallel:true})
// 不支持在开放事务中提交
using periodic commit 1000
load csv with headers from "file:///test.csv" as line with line
merge (n:Linkin {name:line.LinkedinID}) with *
merge (m:学校 {name:line.学校}) with *
merge (n)-[r:教育经历]->(m)
// CSV文件压缩为ZIP之后进行导入
using periodic commit 1000
load csv with headers from "file:///studentBatch.zip" as line with line
merge (n:Linkin {name:line.LinkedinID}) with *
merge (m:学校 {name:line.学校}) with *
merge (n)-[r:教育经历]->(m)
// Twitter公开数据导入测试(https://snap.stanford.edu/data/twitter-2010.txt.gz)
USING PERIODIC COMMIT 1000 LOAD CSV FROM "file:///twitter-2010.txt.gz" AS line FIELDTERMINATOR ' ' WITH toInt(line[0]) as id MERGE (n:Person {id:id}) ON CREATE SET n.name = toString(id), n.sex = ["男", "女"][(id % 2)],n.age = (id % 50) + 15,n.country = ["中国", "美国", "法国", "英国", "俄罗斯", "加拿大", "德国", "日本", "意大利"][(id % 9)];
4、批量更新还可以使用UNWIND子句
// 节点关系同时MERGE
UNWIND [{from:"Pamela May24173068",to:"United Nations Conference on Trade and Development (UNCTAD)9491230"},{from:"Carl Walsh33095175",to:"United Nations Conference on Trade and Development (UNCTAD)9491230"}] as row
MERGE (from:Linkin {name:row.from}) MERGE (to:认证机构 {name:row.to}) WITH from,to
CALL apoc.merge.relationship(from, '奖项', null, null, to) YIELD rel RETURN count(*) as count;
// 示例一:apoc.create.relationship的示例
UWNIND {batch} as row
MATCH (from) WHERE id(n) = row.from
MATCH (to:Label) where to.key = row.to
CALL apoc.create.relationship(from, row.type, row.properties, to) yield rel
RETURN count(*)
// 示例二:动态创建节点和关系(标签是一个String数组/属性就是一个Map):
// 1
UWNIND {batch} as row
CALL apoc.create.node(row.labels, row.properties) yield node
RETURN count(*)
// 2
UNWIND [{label:["label1","label2"],properties:{name:"Emil Eifrem",born:1978}}] as row
CALL apoc.create.node(row.labels, row.properties) yield node
RETURN count(*)
// 3
UNWIND [{labels:["Person"],properties:{name:"Emil Eifrem"}}] as row
CALL apoc.merge.node(row.labels, row.properties,null) yield node
RETURN node
// 示例三
UNWIND {batch} as row
UNWIND [{from:"alice@example.com",to:"bob@example.com",properties:{since:2012}},{from:"alice@example.com",to:"charlie@example.com",properties:{since:2016}}] as row
MATCH (from:Label {from:row.from})
MATCH (to:Label {to:row.to})
MERGE (from)-[rel:KNOWS]->(to)
ON CREATE SET rel.since = row.properties.since
5、亿级数据量更新操作
执行一
// 1、根据节点属性对已有节点添加新的标签(更新失败)-超时设置:dbms.transaction.timeout=180s
MATCH (n:Lable) WHERE n.userDefinedImageUrl IS NOT NULL SET n:头像
更新失败

执行二
// 2、根据节点属性对已有节点添加新的标签(更新成功)
CALL apoc.periodic.iterate('MATCH (n:LinkedinID) WHERE n.userDefinedImageUrl IS NOT NULL RETURN n','WITH {n} AS n SET n:头像',{batchSize:10,parallel:true});
更新成功

参考
NEO4J亿级数据全文索引构建优化 一.数据量规模(亿级) 二.构建索引的方式 三.构建索引发生的异常 四.全文索引代码优化 1.Java.lang.OutOfMemoryError 2.访问数据库时 ... 前提条件: 数据库容量上亿级别,索引只有id,没有创建时间索引 达到目标: 把阿里云RDS Mysql表数据同步到hive中,按照mysql表数据的创建时间日期格式分区,每天一个分区方便查询 每天运行 ... 先上图:425万nodes.180万relationships只用了30s 243ms 项目需要生成关系图,开始考虑的是用Neo4j官网提供的REST API,从solr中查出2组数据先创建节点再创建 ... 工作中需要将 A 图数据库的数据完全导出,并插入到 B 图数据库中.查找资料,好多都是通过导入,导出 CSV 文件来实现.然而,经过仔细研究发现,导出的节点/关系 都带有 id 属性 ,因为 A B ... neo4j 官方文档有说明,使用 neo4j-admin restore / dump 导出和恢复数据库的时候需要停掉数据,否则会报数据库正在使用的错误:command failed: the dat ... 今天玩了一下QQ的导入导出聊天记录的功能,感觉自己有些白痴,因为作为一个软件开发人员对自己平时使用的软件的功能掌握的不够,别说其他的任何东西了就连功能性的操作有些也不知道更别说熟练或精通了,这不是一个 ... 声明:此文供学习使用,原文:https://blog.csdn.net/xiaobaismiley/article/details/41015783 [实验背景] 项目中需要对数据库中一张表进行重新设 ... using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ... http://www.21andy.com/new/20100917/1952.html MySQL导出的SQL语句在导入时有可能会非常非常慢,在处理百万级数据的时候,可能导入要花几小时.在导出时合理 ... 当某天,本蒟蒻沉迷于卡常的时候: 我-- 突然,YYKdalao说:用文操快读啊! 然后 喔-目瞪口呆 不多说,上源码: 本来用的读入方式: inline void Read( int &x ... 题目传送门(内部题124) 输入格式 第一行一个整数$n$代表环的长度. 第二行$n$个整数表示每个冰锥的高度. 输出格式 一行一个整数表示有多少对冰锥是危险的. 样例 样例输入1: 51 2 4 5 ... 使用Redis 对问题下的回答按点赞数排序的思路; 1根据问题id查出所有的回答列表; 2吧回答的ids添加到zset1中; key为id,value为赞的数量;(用于点赞排行); //批量添加 Lo ... 1. 跟据某个属性分组OfficeId: Map<String, List<IncomeSumPojo>> collect = list.stream().collect(Co ... 在Java对流的读取是下面的那样,当前不要忘记流的关闭close. // java 代码void someFunc(InputStream in, OutputStream out) throws I ... 函数组合 让我们创建两个函数: def f(s: String) = "f(" + s + ")" def g(s: String) = "g(&qu ... 答:只需要在 form.on里面的底部添加return false;即可 例如: form.on('submit(component-form-demo1)', function(data){ var ... 第一步 先将一个包引进来 第二步创建一个类加入你想要的字段 首先看一下文件的存放结构: 我们现在希望在上面标记的JS文件里面读取html里面的内容,我们的代码如下: var fs=require("fs"); fs.readFile('te ... 目录 目录 前言 RPM rpm常用指令 YUM yum常用指令RHEL7 最后 前言 yum:yellow dog updater modifier(黄狗包管理器),是RHEL默认的基于RPM包的软 ...NEO4J亿级数据导入导出以及数据更新的更多相关文章
随机推荐