clickhouse核心引擎MergeTree子引擎
在clickhouse使用过程中,针对数据量和查询场景,MergeTree是最常用也是较为合适的表引擎。针对特定的业务,MergeTree的子引擎可以针对不同的业务而定,但都基于MergeTree引擎
1. ReplacingMergeTree
说明:
该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。同时ReplacingMergeTree在一定程度上可以弥补clickhouse不能对数据做更新的操作。
a. 创建ReplacingMergeTree表
创表语法:

ver — 版本列。类型为UInt*,Date或``DateTime,可选参数。其他参数与父引擎MergeTree一样
被弃用的创表语法:

CREATE TABLE rmt_tab(date Date,id UInt8,name String,version UInt8) ENGINE=ReplacingMergeTree(version) PARTITION BY date ORDER BY (id,name) SAMPLE BY name
b. 插入数据
insert into rmt_tab values ('2019-07-11',1,'Jason',1);
insert into rmt_tab values ('2019-07-11',1,'Jason',1);
insert into rmt_tab values ('2019-07-11',1,'Jason',2);
insert into rmt_tab values ('2019-07-12',2,'Tom',1);
insert into rmt_tab values ('2019-07-12',2,'Tom',1);
insert into rmt_tab values ('2019-07-12',2,'Tom',2);
c. 等待后台自动merge或通过optimize table rmt_tab命令手动Merge后查询

name为Jason的数据并未去重,而name为Tom的数据去重后只有一条。总共有四片数据
d. 使用场景
在数据过多重复场景对数据进行去重
2. SummingMergeTree
说明:
当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值
a. 创建SummingMergeTree表
创表语法:

被弃用的语法:

CREATE TABLE smt_tab(date Date,id UInt8,name String,a UInt16) ENGINE=SummingMergeTree(a) PARTITION BY date ORDER BY (id,name) SAMPLE BY name
b. 插入数据
insert into smt_tab (date,id,name,a) values ('2019-12-12',1,'Jason',1)
insert into smt_tab (date,id,name,a) values ('2019-12-12',1,'Jason',2)
insert into smt_tab (date,id,name,a) values ('2019-12-12',1,'Jason',3)
c. 等待后台自动merge或通过optimize table smt_tab命令手动Merge后查询
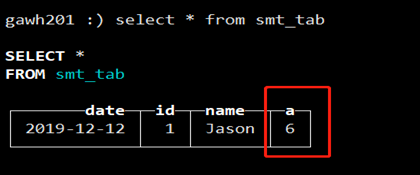
在非a列的相同的情况下,只有一行数据,a列被sum了。
相当于已经做了以下语句的操作:
select date,id,name,sum(a) from smt_tab group by a;
注意:
如果用于汇总的所有列中的值均为0,则该行会被删除。
如果汇总的类为主键则不会被汇总
d. 使用场景
对某个字段长期的汇总查询场景
3.AggregatingMergeTree
说明:
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将相同主键的所有行(在一个数据片段内)替换为单个存储一系列聚合函数状态的行。
可以使用 AggregatingMergeTree 表来做增量数据统计聚合,包括物化视图的数据聚合。
引擎需使用 AggregateFunction 类型来处理所有列。
如果要按一组规则来合并减少行数,则使用 AggregatingMergeTree 是合适的。
对于AggregatingMergeTree不能直接使用insert来查询写入数据。一般是用insert select。但更常用的是创建物化视图
a. 先创建一个MergeTree引擎的基表
CREATE TABLE amt_basic_tab(date Date,D1 String,D2 String,D3 String,M1 UInt16) ENGINE MergeTree() PARTITION BY date ORDER BY (D1,D2,D3)
b. 往基表写入数据
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '甲', 'a', '1', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '甲', 'a', '1', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '甲', 'b', '2', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '乙', 'b', '3', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丙', 'b', '2', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丙', 'c', '1', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丁', 'c', '2', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丁', 'a', '1', 1);
c. 创建一个AggregatingMergeTree的物化视图
create materialized view amt_tab_view ENGINE = AggregatingMergeTree() PARTITION BY date ORDER BY (D2,D3) as select date,D2, D3, uniqState(D1) as uv from amt_basic_tab group by date,D2,D3;
d. 根据b往基表写数据的方法重写写一次将数据填充到物化视图amt_tab_view中并查询
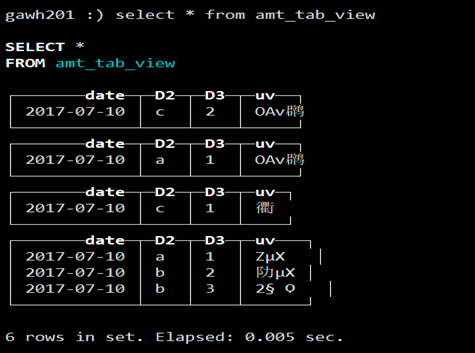
可以看出数据有四片
e. 通过optimize table amt_tab_view命令手动Merge后查询
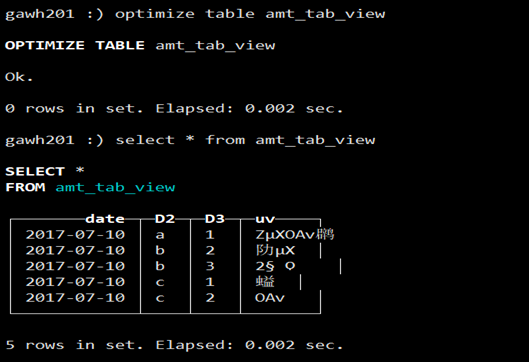
数据只有一片了
这里可能还是没有明白AggregatingMergeTree的作用
对比基表amt_basic_tab和物化视图amt_tab_view的数据就很清晰了
amt_basic_tab:
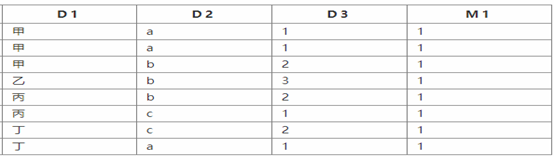
amt_tab_view

f. 使用场景
可以使用AggregatingMergeTree表来做增量数据统计聚合,包括物化视图的数据聚合。
4. CollapsingMergeTree
说明:
yandex官方给出的介绍是CollapsingMergeTree 会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。该引擎可以显著的降低存储量并提高 SELECT 查询效率。
CollapsingMergeTree引擎有个状态列sign,这个值1为”状态”行,-1为”取消”行,对于数据只关心状态列为状态的数据,不关心状态列为取消的数据
a. 创建CollapsingMergeTree表
创表语法:

CREATE TABLE cmt_tab(sign Int8,date Date,name String,point String) ENGINE=CollapsingMergeTree(sign) PARTITION BY date ORDER BY (name) SAMPLE BY name
b. 插入数据:
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','cctv','100000')
insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','cctv','100000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','hntv','10000')
insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','hntv','10000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','hbtv','11000')
insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','hbtv','11000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','cctv','200000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','hntv','15000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','hbtv','16000')
c. 通过optimize table amt_tab_view命令手动Merge后查询
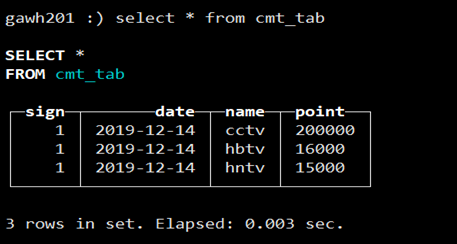
d.使用场景
大数据中对于数据更新很难做到,比如统计一个网站或TV的在用户数,更多场景都是选择用记录每个点的数据,再对数据进行一定聚合查询。而clickhouse通过CollapsingMergeTree就可以实现,所以使得CollapsingMergeTree大部分用于OLAP场景
5. VersionedCollapsingMergeTree
这个引擎和CollapsingMergeTree差不多,只是对CollapsingMergeTree引擎加了一个版本,比如可以适用于非实时用户在线统计,统计每个节点用户在在线业务
a. 创表语法

clickhouse核心引擎MergeTree子引擎的更多相关文章
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
目录 建表语法 数据处理策略 资料分享 参考文章 MergeTree拥有主键,但是它的主键却没有唯一键的约束.这意味着即便多行数据的主键相同,它们还是能够被正常写入.在某些使用场合,用户并不希望数据表 ...
- 关于广州xx公司对驰骋BPM, 流程引擎表单引擎 常见问题解答
关于广州xx公司对驰骋BPM, 流程引擎表单引擎 常见问题解答 @驰骋工作流,ccflow周朋 周总早, ccflow 功能很强大,在体验过程中,以下几个问题需沟通下: 先使用.net 再使用java ...
- 浏览器内核、排版引擎、js引擎
[定义] 浏览器最重要或者说核心的部分是“Rendering Engine”,可大概译为“渲染引擎”,不过我们一般习惯将之称为“浏览器内核”.负责对网页语法的解释(如标准通用标记语 言下的一个应用HT ...
- 深入浏览器工作原理和JS引擎(V8引擎为例)
浏览器工作原理和JS引擎 1.浏览器工作原理 在浏览器中输入查找内容,浏览器是怎样将页面加载出来的?以及JavaScript代码在浏览器中是如何被执行的? 大概流程可观察以下图: 首先,用户在浏览器搜 ...
- 【repost】浏览器内核、渲染引擎、js引擎
[1]定义 浏览器内核分成两部分渲染引擎和js引擎,由于js引擎越来越独立,内核就倾向于只指渲染引擎 渲染引擎是一种对HTML文档进行解析并将其显示在页面上的工具[2]常见引擎 渲染引擎: firef ...
- 浏览器内核、渲染引擎、js引擎
[1]定义 浏览器内核分成两部分渲染引擎和js引擎,由于js引擎越来越独立,内核就倾向于只指渲染引擎 渲染引擎是一种对HTML文档进行解析并将其显示在页面上的工具 [2]常见引擎 渲染引擎: fire ...
- F2工作流引擎这工作流引擎体系架构(二)
F2工作流体系架构概览图 为了能更好的了解F2工作流引擎的架构体系,花了些时间画了整个架构的体系图.F2工作流引擎遵循参考WFCM规范,目标是实现轻量级的工作流引擎,支持多种数据库及快速应用到任何基于 ...
- 【转】浏览器内核、渲染引擎、js引擎
[1]定义 浏览器内核分成两部分渲染引擎和js引擎,由于js引擎越来越独立,内核就倾向于只指渲染引擎 渲染引擎是一种对HTML文档进行解析并将其显示在页面上的工具[2]常见引擎 渲染引擎: firef ...
- GIS中的引擎:地图引擎
什么是地图引擎?它和地图软件有什么区别? 引擎一词是英文单词engine的音译,通常指发动机,就是动力输出设备.诸如汽车.轮船.飞机的动力提供的核心设备就是引擎.IT领域中,常听说的有搜索引擎.图形引 ...
随机推荐
- SSD的理解,为PyramidBox做准备
目标检测主流方法有两大类 two-stage,以rcnn系列为主,采用建议框的方式对目标进行预测,过程首先要经过网络生成候选框,分类背景前景与进行第一次回归,之后再进行一次精细回归. 优点是准确率高, ...
- C/C++ C++ 11 std::move()
{ 0. C++ 标准库使用比如vector::push_back 等这类函数时,会对参数的对象进行复制,连数据也会复制.这就会造成对象内存的额外创建, 本来原意 是想把参数push_back进去就行 ...
- linux文件查找工具——locate,find
一文件查找介绍 文件的查找就是在文件系统上查找符合条件的文件. 文件查找的方式:locate, find非实时查找也就是基于数据库查找的locate,效率特别高. 实时查找:find 二locate ...
- Monkeyrunner学习
可以写一个pyhon工程,安装在android进行测试,还可以截屏操作.Monkeyrunner为framework层开发.MonkeyRunner本身是Java做的,为了和Python连接,做了一个 ...
- idea 配置tomcat
[Toc] #一.配置全局tomcat (类似eclipse中配置tomcat的路径) ##1.1 看图,打开Edit Configuratioms... ##1.2 展开Defaults,找到tom ...
- ssh登录失败的常见问题分析
操作系统为了安全,一般只允许普通用户使用public_key登录,这时如果以root用户登录,就会出现各种错误.下面是常见的错误及解决方案. Permission denied (publickey) ...
- 漫谈C语言结构体
相信大家对于结构体都不陌生.在此,分享出本人对C语言结构体的学习心得.如果你发现这个总结中有你以前所未掌握的,那本文也算是有点价值了.当然,水平有限,若发现不足之处恳请指出.代码文件test.c我放在 ...
- 262K Color
262K色=2^18=262144色. 320*240是指屏幕分辨率. 你可以理解为一块黑板,这款黑板宽是3.2M,长是2.4米,以1cm为最小单位,整个黑板被分为320*240个小格子,这个小格子里 ...
- Linux / Unix Command: rz
yum install lrzsz Most communications programs invoke rz and sz automatically. You can also connect ...
- 微信小程序观察者模式 observers
const app = getApp(); const request = require('../../../utils/request.js'); Component({ options: { m ...