事件,IO,select
事件驱动模型
对于普通编程来说,代码遵循线性流程:开始--》代码A--》代码B--》代码C--》。。。--》结束,编程者知道代码的运行顺序,由编程者控制
事件驱动模型,流程则是:开始--》初始化--》等待,这个等待不同于常规编程的等待,如input(),强制需要用户输入某种数据。
事件驱动模型的等待,是不知道的,不需要强制用户输入,而是当某个事件发生,程序就会做出反应,这些事件包括鼠标点击,信息输入,键盘固定设置的键等
对于编写服务器处理模型的程序,有3种方式
1.每接到一个请求,创建一个线程处理
2.每接到一个请求,创建一个进程处理
3.每接到一个请求,放到一个事件列表中,让主进程通过IO阻塞的方式处理
第三种就是协程、事件驱动模型方式,大多网络服务器都是采用这种方式
例:
对于UI编程来说,常常对鼠标点击要做出反应,如果采用创建一个线程循环检测是否有鼠标点击,则会有很多弊端
如:CPU资源的浪费,阻塞情况下,其他的情况的检测,将无法进行,监测多个设备时,会造成响应时间延迟
所以对UI编程来说,都会采用事件驱动模型,如很多平台都会提供onClick()事件
事件驱动模型的大致流程如下:
1.有一个事件队列
2.当发生一个事件时,向列表中增加这个事件
3.有一个循环,不断从队列中取出事件,根据事件的不同,调用不同的函数
4.事件都各自保存自己的函数指针,这样,每个事件都有自己的处理函数
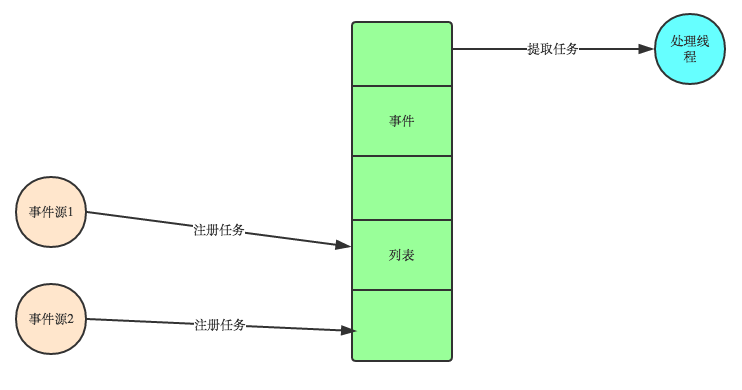
事件驱动模型编程是一种编程范式,这里的执行流由外部的事件决定,它的特点是有一个事件循环,当外部事件发生时通过回调机制触发相应处理
另外两种编程范式是单线程同步,多线程编程
综述:
1.事件驱动模型可以节省CPU资源,它有机会释放CPU进入睡眠状态(注意这是有机会,也可以自主选择不释放),当时间触发时再被唤醒
2.典型的事件驱动的程序就是一个死循环,并以一个线程的方式存在,包含两部分,按照一定条件接收并选择要处理的事件和处理事件的过程,
且当事件没有被触发时,程序会因为查询事件队列失败而进入睡眠状态,从而释放CPU
3.事件驱动的程序必定直接或间接拥有一个事件队列,用于存储未处理的事件
4.事件驱动程序完全由外部输入的事件控制,
5.事件驱动程序,可以按照一定的顺序处理队列中的事件,而这个顺序是由事件触发的顺序决定,这一特性往往用于保证某个过程的原子化
6.注意:事件驱动的监听事件是由操作系统调用CPU完成的
IO多路复用
用户空间和内核空间
操作系统采用虚拟存储器,对于32位操作系统而言,它的寻址空间为4G(2的32次方)
操作系统的核心是内核,独立于普通应用程序,可以访问被保护的内存空间,也拥有访问底层硬件设备的所有权
为了保证用户程序不能直接访问内核(kernel),保护内核的安全,操作系统将虚拟内存分为两部分,一部分为内核空间,一部分为用户空间
针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,
而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起进程的执行,这种行为称为进程切换,由操作系统完成
从一个进程运行转到另一个进程运行,发生的变化:
保存处理机上下文,包括程序计数器和其他寄存器
更新PCB信息,把进程的PCB移入相应的队列,如:就绪,在某事件阻塞队列等
选择另一进程执行,并更新其PCB
更新内存管理的数据结构,恢复处理机上下文
进程阻塞
正在执行的程序,由于期待的某个事件未发生,如请求系统资源失败,等待某种操作,新数据尚未到达等等,
则由系统自动执行阻塞原语(block),当进程进入阻塞状态,是不占用CPU资源的
文件描述符(file descriptor),计算机术语,是一个用于指向文件引用的抽象概念,在形式上是一个非负整数
它是一个索引值,当打开或创建一个文件时,内核向进程返回一个描述符
一些涉及底层程序编写时多围绕文件描述符编写,只适用于Linux和Unix
缓存I/O
缓存I/O又称标准I/O,大多文件系统的默认I/O操作都是缓存I/O,Linux的缓存I/O机制中,
操作系统会将I/O的数据缓存在文件系统的页缓存(page cache)
即数据会先拷贝到操作系统内核的缓存区,然后再从内核的缓存区拷贝到用户的地址空间
缺点:数据在传输时的内核和用户空间的拷贝操作,对CPU和内存带来的开销是非常大的
blocking IO(阻塞IO)
在Linux下,所有的socket默认情况下都是blocking,其大致流程如下
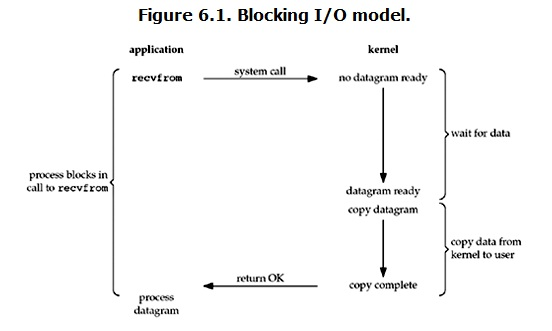
当用户调用recvfrom时,内核(kernel)开始准备数据,对于network IO来说,很多时候数据在开始时并未到达,于是kernel就会等待,
用户这边,进程就会阻塞,直到kernel拿到所有数据,并copy到用户内存中,kernel会返回一个结果,用户进程才会解除block状态
所以,blocking IO的特点就是IO执行的两个过程都被block了
non-blocking IO(非阻塞IO)
Linux下,可以设置socket使其变为non-blocking IO,流程如下
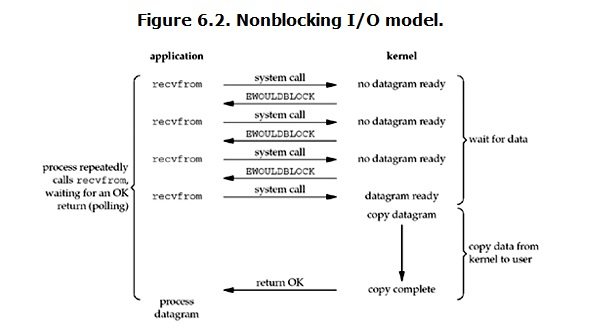
与blocking IO不同,non-blocking IO在发出询问时,如果数据没有准备好,kernel会立刻回一个消息,用户不用等待
用户进程通过的轮询,直到kernel检测到数据准备好,然后将数据copy到用户内存
它将一个长时间的阻塞分成多个小阻塞,在此期间,进程不断被CPU访问,CPU权限还在自己手中,这段期间是可以再操作其他的事情,
也因此导致任务响应延迟增大
注意当kernel检测到数据准备好了之后的拷贝操作,依然是阻塞状态
#server端 import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sk.setsockopt
sk.bind(('127.0.0.1',6667))
sk.listen(5)
sk.setblocking(False) #设置为非阻塞IO
while True:
try:
print ('waiting client connection .......')
connection,address = sk.accept() # 进程主动轮询
print("+++",address)
client_messge = connection.recv(1024)
print(str(client_messge,'utf8'))
connection.close()
except Exception as e:
print (e)
time.sleep(4)
#client端 import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) while True:
sk.connect(('127.0.0.1',6667))
print("hello")
sk.sendall(bytes("hello","utf8"))
time.sleep(2)
break
IO multilexing(IO多路复用)
利用select或epoll轮询所负责的socket,当数据到达时,就通知用户进程,select/epoll的好处在于单个process可以处理多个网络连接的IO
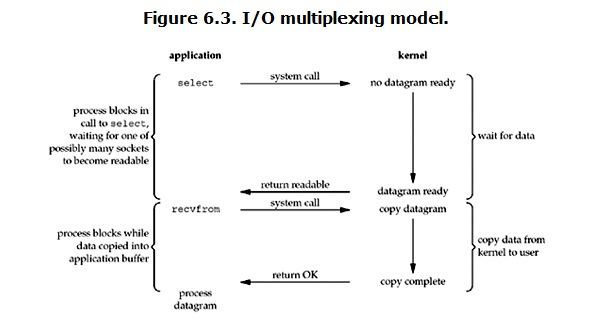
当用户调用select后,整个进程都会被block,同时kernel会监测所有select负责的socket,当任何一个socket数据准备好后,select就会返回
此时,用户在read操作,将数据从kernel中copy到用户进程
想比较blocking IO ,IO multilexing 优势在于可以同时处理多个connection(如果处理的链接数不多的话,不一定比multi-threading+blocking IO快)
#server端 import socket
import select
sk=socket.socket()
sk.bind(("127.0.0.1",8801))
sk.listen(5)
inputs=[sk,]
while True:
r,w,e=select.select(inputs,[],[],5) #通过select监测socket连接,返回3个结果
#4个参数,第1个为可读集合,第2个位可写,第3个为异常信息,第4个是等待的最大时间
# print(len(r)) for obj in r:
if obj==sk:
conn,add=obj.accept()
print(conn)
inputs.append(conn)
else:
data_byte=obj.recv(1024)
print(str(data_byte,'utf8'))
inp=input('回答%s号客户>>>'%inputs.index(obj))
obj.sendall(bytes(inp,'utf8')) # print('>>',r)
#client.py import socket
sk=socket.socket()
sk.connect(('127.0.0.1',8801)) while True:
inp=input(">>>>")
sk.sendall(bytes(inp,"utf8"))
data=sk.recv(1024)
print(str(data,'utf8'))
asynchronous I/o(异步IO)
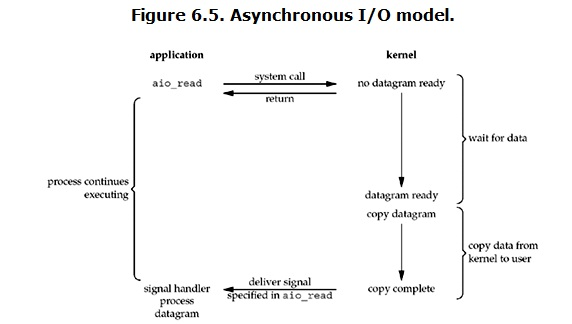
全程不存在阻塞,用户发起read后,kernel会立刻返回结果,然后用户就会去做其他的事情,然后kernel等待数据准备好,然后copy到用户内存
全部做好之后,kernel会发送一个signal,告诉用户已read完成
各个IO model过程比较

select,poll,epoll
select:通过select()系统调用来监测多个系统描述符的数组,当select()返回时,该数组中的文件描述符就会被修改标志位,
使得进程可以获得这些标志位,从而进行后续的读写操作,select全平台支持,但单个进程监测文件描述符存在最大限制,Linux一般最大1024
poll:与select差不多,但它没有最大限制
epoll:无最大限制,和select不同,当某个 链接活跃时,能直接提供具体的链接,而不用像select将整个链接轮询一遍才能得到这个链接
IO多路复用的触发方式
水平触发:如果文件描述符已经就绪,可以非阻塞的执行IO时,此时触发通知,允许任意时刻重复检测IO状态,而不必尽可能多的执行IO
边缘触发:如果文件描述符在上一次状态改变后又有新的IO操作来了,触发通知,此时就要尽可能多的执行IO
select属于水平触发,epoll既属于水平触发,又属于边缘触发
两种触发的区别:当水平触发时,select/epoll会立即返回,不会有阻塞,因为已经有数据了
当边缘触发时,不会返回,此时是阻塞状态,等到新的数据到来时,epoll才会返回,此时新数据,老数据都可以读到
从电子角度来看:水平触发是只在高电平和低电平情况下才会触发。边缘触发是在电平发生改变(高->低,低->高)时触发
事件,IO,select的更多相关文章
- 事件驱动模型 IO多路复用 阻塞IO与非阻塞IO select epool
一.事件驱动 1.要理解事件驱动和程序,就需要与非事件驱动的程序进行比较.实际上,现代的程序大多是事件驱动的,比如多线程的程序,肯定是事件驱动的.早期则存在许多非事件驱动的程序,这样的程序,在需要等待 ...
- IO模型之IO多路复用 异步IO select poll epoll 的用法
IO 模型之 多路复用 IO 多路复用IO IO multiplexing 这个词可能有点陌生,但是如果我说 select/epoll ,大概就都能明白了.有些地方也称这种IO方式为 事件驱动IO ( ...
- UNP——第六章,多路转接IO——select
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); ...
- jQuery 事件——关于select选中
场景: eg:在管理一篇博文时,因博文的管理有一列叫:状态的列,该列有诸多状态,如:正常,待审核,删除等... 此时,若使用Select下拉列表进行状态选择,并在选中具体项值后,通过Ajax异步提交, ...
- jquery事件之select选中事件
根据select下拉列表选中的不同选项执行不同的方法,工作中经常会用到,这里就要用到Jquery的select选中事件 这里给select加一个叫label_id的id,然后通过id选择器找到这个节点 ...
- Python 协程/异步IO/Select\Poll\Epoll异步IO与事件驱动
1 Gevent 协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到 ...
- Python自动化 【第十篇】:Python进阶-多进程/协程/事件驱动与Select\Poll\Epoll异步IO
本节内容: 多进程 协程 事件驱动与Select\Poll\Epoll异步IO 1. 多进程 启动多个进程 进程中启进程 父进程与子进程 进程间通信 不同进程间内存是不共享的,要想实现两个进程间 ...
- 转一贴,今天实在写累了,也看累了--【Python异步非阻塞IO多路复用Select/Poll/Epoll使用】
下面这篇,原理理解了, 再结合 这一周来的心得体会,整个框架就差不多了... http://www.haiyun.me/archives/1056.html 有许多封装好的异步非阻塞IO多路复用框架, ...
- 《UNIX网络编程》之select IO
select 函数的原理 select 管理者 用select来管理多个IO 一旦其中的一个或者多个IO检测到我们所感兴趣的事件, select 函数返回,返回值为检测到的事件个数 然后,遍历事件,进 ...
- Linux下select, poll和epoll IO模型的详解
http://blog.csdn.net/tianmohust/article/details/6677985 一).Epoll 介绍 Epoll 可是当前在 Linux 下开发大规模并发网络程序的热 ...
随机推荐
- antd form表单一行多个组件并对其校验
一行一个标签对应多个输入组件,这个需求很常见但在官方例子没看到合适的,因为官方建议: 注意:一个 Form.Item 建议只放一个被 getFieldDecorator 装饰过的 child,当有多个 ...
- 微信小程序打印json log
微信小程序中如果 res.data数据是一个json格式数据.console.log("===data===" + res.data);//如果这样打印出了是只会打印一个对象名称, ...
- mysql workbench中PK,NN,UQ,BIN,UN,ZF,AI字段类型标识说明
PK:primary key 主键 NN:not null 非空 UQ:unique 唯一索引 BIN:binary 二进制数据(比text更大) UN:unsigned 无符号(非负数) ZF:ze ...
- scss 用法 及 es6 用法讲解
scss 用法的准备工作,下载 考拉 编译工具 且目录的名字一定不能出现中文,哪里都不能出现中文,否则就会报错 es6 用法 let 和 const let 声明变量的方式 在 {} 代码块里面才 ...
- 微信小程序 视频 组件
video 组件 视频组件 相关的api :wx.createVideoContext 支持的格式: 支持的编码格式 video 组件的属性: src:类型 字符串 必填 要播放视频的资源地址 (支持 ...
- zabbix分布式监控环境搭建
本次测试主要是在 centos 系统环境实践,测试内容:集群多台服务器资源监控做后续铺垫.zabbix的简介和自身的特点.在这就不阐述了 查询防火墙状态service iptables status停 ...
- a = a + b 与 a += b 的区别
1.对于同样类型的a,b来说 两个式子执行的结果确实没有什么区别.但是从编译的角度看吧(武让说的),a+=b;执行的时候效率高. 2.对于不同类型的a,b来说 2.1 不同类型的两个变量在进行运 ...
- python 调用c++类方法(1)
myTest.cpp: #include<iostream> #include<vector> class MyTest { public: MyTest(); ~MyTest ...
- Chrome 浏览器添加跨域支持
开发前端本地项目时,涉及到与后端服务器的通信联调,在使用 ajax 时由于浏览器的安全策略不允许跨域.一种方式是本地搭建转发服务器,今天又 GET 到一种更直接的方式,在 Chrome 浏览器开启时添 ...
- laravel 5.6 使用RabbitMQ作为消息中间件
1.Composer安装laravel-queue-rabbitmqcomposer require vladimir-yuldashev/laravel-queue-rabbitmq2.在confi ...