爬虫_电影天堂 热映电影(xpath)
写了一天才写了不到100行。不过总归是按自己的思路完成了
import requests
from lxml import etree
import time BASE = 'http://www.dytt8.net'
def get_one_page(url):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'}
try: response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
return response.text
except:
return 0 def parse_one_page_href(html):
str_hrefs = []
html_element = etree.HTML(html)
# //div[@class="co_content8"]/ul/table//a/@href
hrefs = html_element.xpath('//table[@class="tbspan"]//a/@href')
for href in hrefs:
href = BASE + href
str_hrefs.append(href)
return str_hrefs """
return
['http://www.dytt8.net/html/gndy/dyzz/20180731/57193.html',
'http://www.dytt8.net/html/gndy/dyzz/20180730/57192.html',
......
'http://www.dytt8.net/html/gndy/dyzz/20180702/57064.html',
'http://www.dytt8.net/html/gndy/dyzz/20180630/57056.html']
""" def get_all_pages(page_nums):
hrefs = []
for index in range(1, page_nums + 1):
url = 'http://www.dytt8.net/html/gndy/dyzz/list_23_' + str(index) + '.html'
html = get_one_page(url)
while html == 0:
time.sleep(3)
html = get_one_page(url)
hrefs.extend(parse_one_page_href(html))
return hrefs def get_detail(page_nums):
movie = []
hrefs = get_all_pages(page_nums)
for href in hrefs: #href: every page url
informations = {} response = requests.get(href)
response.encoding = response.apparent_encoding
html = response.text html_element = etree.HTML(html) title = html_element.xpath('//font[@color="#07519a"]/text()')[0]
informations['title'] = title image_src = html_element.xpath('//p//img/@src')
informations['image_src'] = image_src[0] download_url = html_element.xpath('//td[@bgcolor="#fdfddf"]/a/@href')
informations['download_url'] = download_url texts = html_element.xpath('//div[@id="Zoom"]//p/text()')
for index, text in enumerate(texts): if text.startswith('◎片 名'):
text = text.replace('◎片 名', '').strip()
informations['english_name'] = text elif text.startswith('◎产 地'):
text = text.replace('◎产 地', '').strip()
informations['location'] = text elif text.startswith('◎上映日期'):
text = text.replace('◎上映日期', '').strip()
informations['date'] = text elif text.startswith('◎片 长'):
text = text.replace('◎片 长', '').strip()
informations['time'] = text elif text.startswith('◎导 演'):
text = text.replace('◎导 演', '').strip()
informations['director'] = text elif text.startswith('◎主 演'):
text = text.replace('◎主 演', '').strip()
actors = []
actors.append(text)
for x in range(index+1, len(texts)):
actor = texts[x].strip()
if texts[x].startswith('◎简 介'):
break
actors.append(actor)
informations['actors'] = actors elif text.startswith('◎简 介 '):
text = text.replace('◎简 介 ', '').strip()
intros = []
# intros.append(text)
for x in range(index+1, len(texts)):
intro = texts[x].strip()
if texts[x].startswith('◎获奖情况'):
break
intros.append(intro)
informations['intros'] = intros
movie.append(informations)
return movie def main():
page_nums = 1 #
movie = get_detail(page_nums)
print(movie) if __name__ == '__main__':
main()
运行结果:(选中的是一部电影, 一页中有25部电影,网站里一共有176页)
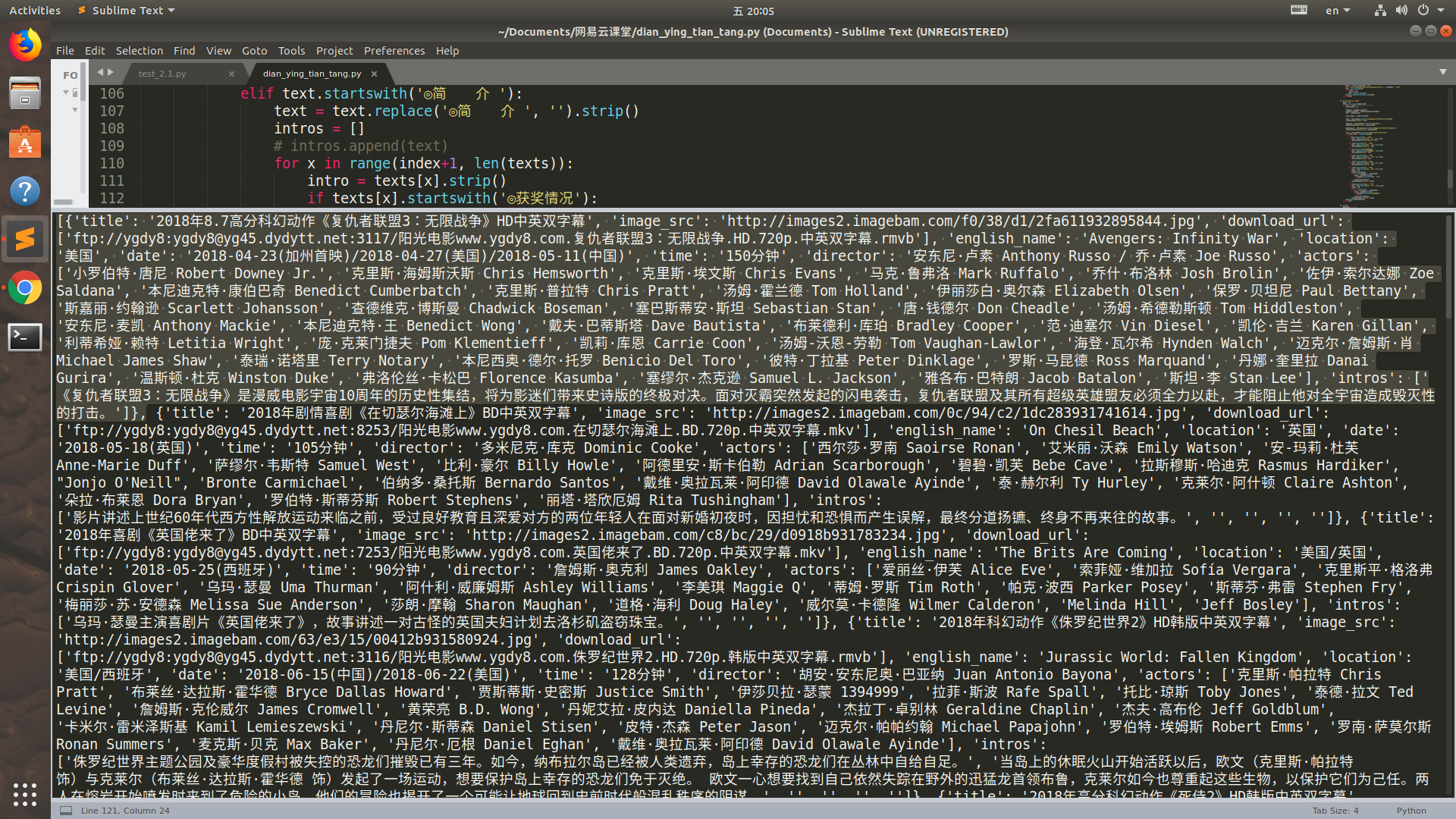
感受到了代码的魅力了吗
爬虫_电影天堂 热映电影(xpath)的更多相关文章
- python爬虫——爬取淘票票正在热映电影
今天正好学习了一下python的爬虫,觉得收获蛮大的,所以写一篇博客帮助想学习爬虫的伙伴们. 这里我就以一个简单地爬取淘票票正在热映电影为例,介绍一下一个爬虫的完整流程. 首先,话不多说,上干货——源 ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- 爬虫_豆瓣全部正在热映电影 (xpath)
单纯地练习一下xpath import requests from lxml import etree def get_url(url): html = requests.get(url) retur ...
- python爬虫——词云分析最热门电影《后来的我们》
1 模块库使用说明 1.1 requests库 requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更 ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- LOL电影天堂下载攻略
LOL电影天堂&&飘花电影网下载攻略 CreateTime--2017年7月27日08:52:29Author:Marydon 以进击的巨人为例 下载地址:http://www.l ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- scrapy电影天堂实战(二)创建爬虫项目
公众号原文 创建数据库 我在上一篇笔记中已经创建了数据库,具体查看<scrapy电影天堂实战(一)创建数据库>,这篇笔记创建scrapy实例,先熟悉下要用到到xpath知识 用到的xpat ...
- 用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件 #coding=utf-8 from ...
随机推荐
- 初用Ajax
早就有学习Ajax的想法了,但每次拿起一本Ajax的书,翻了不到百页就学不下去了,里面讲的东西实在太多了,前面讲javaScript的内容看了好 几遍都记不住,也就没心思去看后面的内容:看Ajax案例 ...
- nginx 编译安装以及简单配置
前言 Nginx的大名如雷贯耳,资料太多了,网上一搜一大把,所以这里就不阐述nginx的工作原理了,只是简单的编译安装nginx,然后呢,简单配置一下下. 下载Nginx.安装 下载地址:http:/ ...
- 搭建RISC-V错误记录
错误:riscv64-unknown-elf-gcc: Command not found 解决办法:将riscv64-unknown-elf-gcc文件拷贝到根目录的/bin目录下. 原因是make ...
- vue-lazyload简单使用
vue-lazyload简单使用 npm地址:https://www.npmjs.com/package/vue-lazyload github地址:https://github.com/hilong ...
- mysql uuid() 相同 重复
mysql select UPPER(REPLACE(uuid(),'-','')) from xxxtable 得到相同的uuid的问题 - LWJdear的博客 - CSDN博客 https:// ...
- css太极
自己用css做的太极,留个纪念. 用css做太极有很多种实现方法,我这种大概是最简单的了吧,因为div用得太多了,哈哈. 高级一点的应该是用伪类:before和:after去减少div的用量(手动滑稽 ...
- 2.请介绍一下List和ArrayList的区别,ArrayList和HashSet区别
第一问: List是接口,ArrayList实现了List接口. 第二问: ArrayList实现了List接口,HashSet实现了Set接口,List和Set都是继承Collection接口. A ...
- VUE项目问题之:去掉url中的#/
一.问题 使用VUE路由,项目的url总是带有锚点,如下: http://localhost:8082/#/ 二.解决 修改路由文件中 index.js 文件,即 src --> router ...
- springMVC中@RequestParam和@RequestBody的作用
@RequestParam和@RequestBody是什么区别,估计很多人还是不太清楚, 因为一般用@ RequestParam就足够传入参数了,要说他们区别,就需要知道contentType是什么? ...
- Linux基础学习笔记6-SHELL编程
编程基础 程序:指令+数据 程序编程风格: 过程式:以指令为中心,数据服务于指令 对象式:以数据为中心,指令服务于数据 shell程序:提供了编程能力,解释执行 编程基本概念: 顺序执行:循环执行:选 ...