Kafka技术内幕 读书笔记之(二) 生产者——服务端网络连接
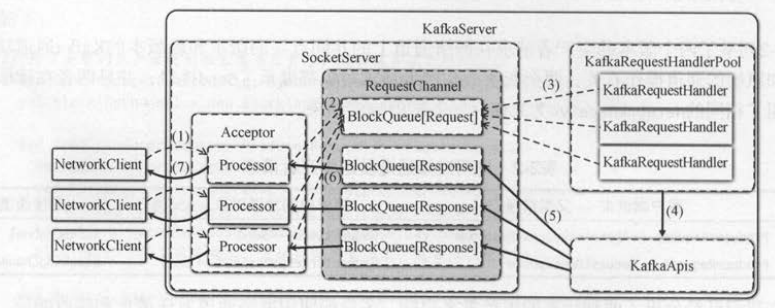
KafkaServer是Kafka服务端的主类, KafkaServer中和网络层有关的服务组件包括 SocketServer、KafkaApis 和 KafkaRequestHandlerPool后两者都使用了
SocketServer暴露出来的请求通道( RequestChannel )来处理网络请求 。 SocketServer主要关注网络层的通信协议,具体的业务处理逻辑 则交给
KafkaRequestHandler和 KafkaApis来完成 。 SocketServer和这两个组件一起完成一次请求处理的具体步骤如下 。
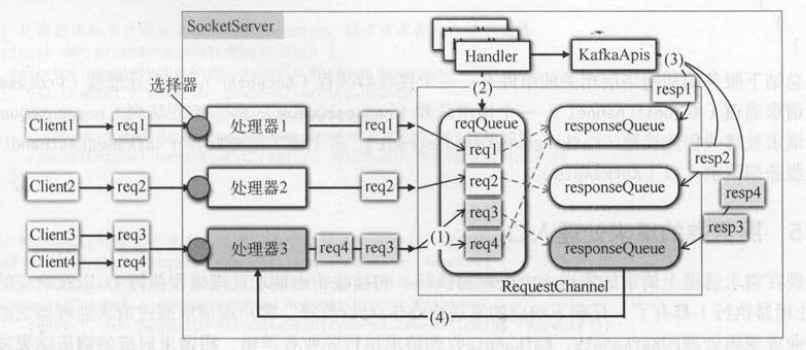
(1 ) 客户端发送的请求被接收器( Acceptor)转发给处理器( processor)处理 。
(2)处理器将请求放到请求通道( RequestChannel )的全局请求队列中 。
(3 ) KafkaRequestHandler取出请求通道中的客户端请求 。
(4)调用 KafkaApis进行业务逻辑处理 。
(5 ) KafkaApis将响应结果发送给请求通道中与处理器对应的响应队列 。
(6)处理器从对应的响应队列中取出响应结果 。
(7)处理器将响应结果返回给客户端,客户端请求处理完毕 。
服务端使用接收器接受客户端的连接
SocketServer是一个NIO服务,它会启动一个接收器线程( Acceptor )和多个处理器( processor )。NIO服务用一个接收器线程负责接收所有的客户端连接请求,
并将接收到的请求分发给不同的处理器处理。 这是一种典型的Reacto「模式,因为服务端要接收多个客户端的连接和请求 。
Reactor模式的设计思想,实际上是将连接部分和请求部分用不同的线程来处理,这样请求的处理不会阻塞不断到来的连接。 否则,如果服务端为每个客户端都维护一个连接,
不仅会耗光服务端的资源,而且会降低服务端的性能 。 使用Reactor模式并结合选择器管理多个客户端的网络连接,可以减少钱程之间的上下文切换和资源的开销 。
服务端资源有限,处理器数量不会很多,而客户端连接则成千上万,所以一个处理器会管理多个客户端的连接。接收器的工作职责很简单 只管接受客户端的连接请求,
并创建和客户端通信的 SocketChannel 。具体在这个SocketChannel上发生的读写操作都和接收器无关,因为它已经把创建好的 SocketChannel转交给了处理器,
那么处理器就应该全权负责这个通道上的操作了 。
接收器线程启动时就注册了 OP_ACCEPT事件, 接收器线程的选择器就会监听到OP_ACCEPT事件 。 服务端对OP_ACCEPT事件的处理是:获取绑定到选择键
上的 ServerSocketChannel ,调用它的accept ()方法,在服务端就会生成一个和客户端连接的网络通道。
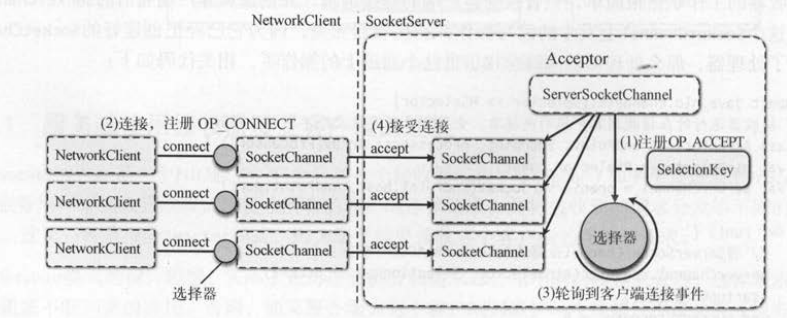
如图 所示,服务端接受客户端连接后,会创建对应的SocketChannel来和客户端通信。 而客户端和服务端建立连接的Kafka通道实际上也是一个SocketChannel
用来和服务端通信。 客户端和服务端对于各向的通道都使用了选择器模式 , 从客户端建立连接到服务端接受连接的步骤如下 。
(1)服务端的 ServerSocketChannel 向选择器注册OP_ACCEPT事件 。
(2)客户端向选择器注册OP_CONNECT事件,并调用 SocketChannel.connect () 连接服务端 。
(3)服务端的选择器监听到客户端的连接事件,接受客户端的连接 。
(4)服务端使用 ServerSocketChannel.accept ()创建和客户端通信的 SocketChannel 。
客户端和服务端的其他事件(比如读写)也都是类似的,都要先注册相应的事件,然后选择器才有可能监听到某种类型的事件。 客户端的选择器会处理连接/读写事件,
而接收器只处理连接事件,读写事件交给了处理器 。 总的来说,客户端和服务端的事件都是对应的,客户端连接OP_CONNECT对应服务端接受 OP_ACCEPT ,
客户端写入 OP_WRITE对应服务端读取 OP_READ ,服务端写入OP_WRITE对应客户端读取OP_READ 。
处理器使用选择器的轮询处理网络请求
接收器采用Round-Robin的方式分配客户端的SocketChannel给多个处理器,每个处理器都会有多个SocketChannel ,处理器也使用一个选择器管理多个客户端连接 。
处理器接受一个新的 SocketChannel通道连接时,先将其放入阻塞队列,然后唤醒选择器线程开始工作。
客户端连接服务端时会创建Kafka通道,这里服务端的处理器也会为 SocketChannel创建一个Kafka通道 。configueNewConnections ()方法会为 SocketChannel
注册读事件,创建Kafka通道,并将Kafka通道绑定到socketChannel的选择键上 。
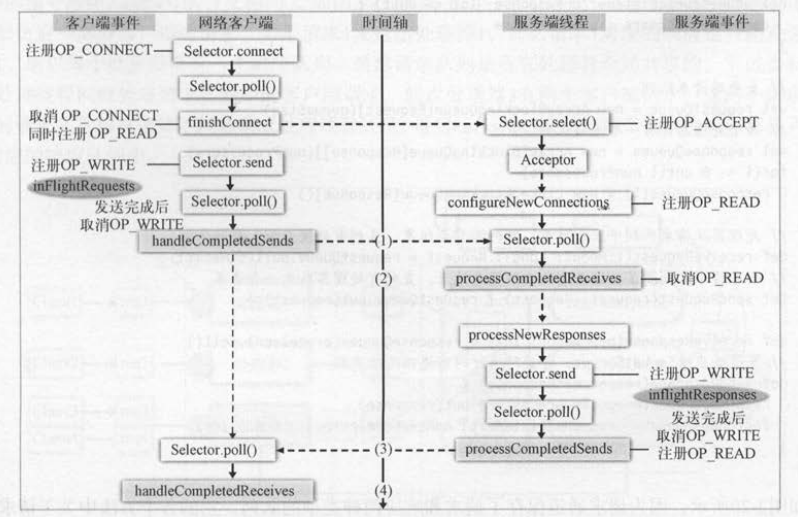
客户端的NetworkClient和服务端的处理器发送请求和接收响应,都是通过选择器的轮询才会触发 。 在轮询之前 , 客户端需要准备待发送的请求
( RequestSend );服务端需要准备待发送的响应( ResponseSend ),轮询之后才执行完成的发送和接收 。
客户端和服务端的交互都是通过各向的选择器轮询所驱动 。 结合客户端和服务端以及选择器的轮询,把一个完整的请求和响应过程串联起来的步骤如下 。
(1)客户端完成请求的发送,服务端轮询到客户端发送的请求 。
(2)服务端接收完客户端发送的请求,进行业务处理,并准备好响应结果准备发送 。
(3)服务端完成响应的发送,客户端轮询到服务端发送的响应 。
(4)客户端接收完服务端发送的响应
请求通道的请求队列和响应队列
在KafkaServer中, 会将SocketServer的请求通道传给Kafka请求处理线程( KafkaRequestHandler ,下文简称“请求处理线程”)和KafkaApis 。
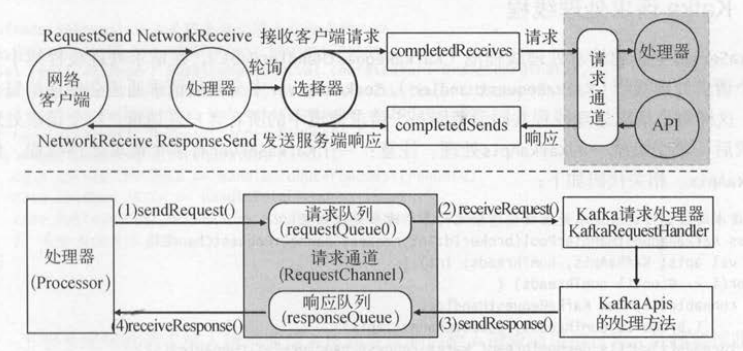
客户端的请求已经到达服务端的处理器( processor ),那么请求通道就是处理器与请求处理线程和 KafkaApis交换数据的地方
如果处理器往请求通道添加请求,请求处理线程和 KafkaApis都可以获取到请求通道中的请求;
如果请求处理线程和KafkaApis往请求通道添加响应,处理器也可以从请求通道获取响应 。
因为请求通道保存了请求和响应两种类型的队列 , 它的各个方法中关于请求和响应的接收和发送是有顺序的: 发送请求→接收请求→发送响应→接收响应 。
(1) sendRequest ():处理器接收到客户端请求后,将请求放入请求队列 。
(2) receiveRequest ():请求处理线程从队列中获取请求,并交给 KafkaApis处理 。
(3) sendResponse ( ) : KafkaApis处理完,将响应结果放入响应队列 。
(4) receiveResponse ():处理器从响应队列中获取响应结果发送给客户端 。
上面只是一个请求和响应在请求通道上的调用顺序,以服务端同时处理多个客户端请求为例,并结合其他相关的组件,来说明处理器将请求放入请求通道,
一直到从请求通道获取响应的过程 。如图所示,由于一个SocketServer有多个处理器,每个处理器都负责一部分客户端的请求 。
如果请求 1 发送给处理器 1,那么请求1对应的响应也只能发送给处理器1 ,所以每个处理器都有一个响应队列 。 请求队列是所有处理器全局共享的,不过会有多个
请求处理线程同时处理请求队列中的客户端请求 。 假设处理器3有两个客户端请求,这两个请求进入全局的请求队列后可能被不同的请求处理线程处理,
最后 KafkaApis会将这两个请求的响应都放入处理器3对应的响应队列中 。
Kafka 请求处理线程
KafkaServer会创建请求处理线程池( KafkaRequestHandlerPool ),在请求处理钱程池中会创建并启动多个请求处理线程( KafkaRequestHandler)。
SocketServer中全局的请求通道会传递给每个请求处理线程 。 这样每个请求处理线程共同消费同一个请求通道中的所有客户端请求 。 每个请求处理线程获
取到请求后 , 都交给统一的 KafkaApis处理。 注意 : 一个KafkaServer有多个请求处理线程,但是只有一个KafkaApis 。
总结下服务端和网络层相关的组件有 : 一个接收器线程( Acceptor)、 多个处理器( processor )、一个请求通道( RequestChannel )、 一个请求队列( RequestQueue )、
多个响应队列( ResponseQueue )、一个请求处理线程连接池 ( KafkaRequestHandlerPool )、多个请求处理线程( KafkaRequestHandler)、
一个服务端请求入口( KafkaApis )。
服务端的请求处理入口
客户端请求通过请求处理器交给负责具体业务逻辑处理的 KafkaApis , KafkaApis收到请求执行完业务逻辑, 将请求对应的响应结果发送到
请求通道的响应队列中 。
KafkaApis . handle ()方法是服务端处理各种请求 的入口 。 不仅仅是客户端( 比如生产者或消费者),Kafka服务端节点之间的通信也会走这个统一的入口
( 比如备份副本的拉取请求 ,以及其他内部请求)。
处理器接收完从客户端发送过来的NetworkReceive对象,会解析NetworkReceive的内容,再加上当前处理器编号 ,包装成RequestChannel . Request对象,
然后将RequestChannel.Request放入请求通道的请求 队列中 。
客户端发送的请求对象是ClientRequest ,但是在经过网络发送给服务端 , 会被包装成Send对象。服务端通过处理器中选择器的轮询读取客户端的请求,
得到的是NetworkReceive对象。 服务端需要解析NetworkReceive的内容才能创建RequestChannel.Request请求对象。
请求处理线程从请求通道中获取请求 , 并交给KafkaApis去处理。 KafkaApis在处理完请求后,会创建响应对象( RequestChannel. Response )并放入请求通道中 。
响应对象也持有请求对象的引用,因为请求对象中有处理器编号,所以响应对象可以从请求对象中获取处理器编号, 确保对请求和响应的
处理都是在同一个处理器中完成。
Kafka技术内幕 读书笔记之(二) 生产者——服务端网络连接的更多相关文章
- Kafka技术内幕 读书笔记之(二) 生产者——新生产者客户端
消息系统通常由生产者(producer ). 消费者( consumer )和消息代理( broker ) 三大部分组成,生产者会将消息写入消息代理,消费者会从消息代理中读取消息 . 对于消息代理而言 ...
- Kafka技术内幕 读书笔记之(一) Kafka入门
在0.10版本之前, Kafka仅仅作为一个消息系统,主要用来解决应用解耦. 异步消息 . 流量削峰等问题. 在0.10版本之后, Kafka提供了连接器与流处理的能力,它也从分布式的消息系统逐渐成为 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——新消费者客户端(二)
消费者拉取消息 消费者创建拉取请求的准备工作,和生产者创建生产请求的准备工作类似,它们都必须和分区的主副本交互.一个生产者写入的分区和消费者分配的分区都可能有多个,同时多个分区的主副本有可能在同一个节 ...
- Kafka技术内幕 读书笔记之(三) 生产者——消费者:高级API和低级API——基础知识
1. 使用消费组实现消息队列的两种模式 分布式的消息系统Kafka支持多个生产者和多个消费者,生产者可以将消息发布到集群中不同节点的不同分区上:消费者也可以消费集群中多个节点的多个分区上的消息 . 写 ...
- Kafka技术内幕 读书笔记之(六) 存储层——日志的读写
-Kafka是一个分布式的( distributed ).分区的( partitioned ).复制的( replicated )提交日志( commitlog )服务 . “分布式”是所有分布式系统 ...
- Kafka技术内幕 读书笔记之(六) 存储层——服务端处理读写请求、分区与副本
如下图中分区到 日 志的虚线表示 : 业务逻辑层的一个分区对应物理存储层的一个日志 . 消息集到数据文件的虚线表示 : 客户端发送的消息集最终会写入日志分段对应的数据文件,存储到Kafka的消息代理节 ...
- Kafka技术内幕 读书笔记之(五) 协调者——延迟的加入组操作
协调者处理不同消费者的“加入组请求”,由于不能立即返回“加入组响应”给每个消费者,它会创建一个“延迟操作”,表示协调者会延迟发送“加入组响应”给消费者 . 但协调者不会为每个消费者的 “加入组请求 ...
- Kafka技术内幕 读书笔记之(三) 消费者:高级API和低级API——消费者消费消息和提交分区偏移量
消费者拉取钱程拉取每个分区的数据,会将分区的消息集包装成一个数据块( FetchedDataChunk )放入分区信息的队列中 . 而每个队列都对应一个消息流( KafkaStream ),消费者客户 ...
- Kafka技术内幕 读书笔记之(五) 协调者——消费组状态机
协调者保存的消费组元数据中记录了消费组的状态机 , 消费组状态机的转换主要发生在“加入组请求”和“同步组请求”的处理过程中 .协调者处理“离开消费组请求”“迁移消费组请求”“心跳请求” “提交偏移量请 ...
随机推荐
- The Embarrassed Cryptographer POJ - 2635 同余模+高精度处理 +线性欧拉筛(每n位一起处理)
题意:给出两数乘积K(1e100) 和 一个数L(1e6) 问有没有小于L(不能等于)的素数是K的因数 思路:把数K切割 用1000进制表示 由同余模公式知 k%x=(a*1000%x+b* ...
- P1064 金明的预算方案
思路:就是一个背包问题 因为数据范围小,所以不把 1个带附着物的东西 拆成 带1个带2个或不带 #include<bits/stdc++.h> using namespace std; ...
- 【XSY2680】玩具谜题 NTT 牛顿迭代
题目描述 小南一共有\(n\)种不同的玩具小人,每种玩具小人的数量都可以被认为是无限大.每种玩具小人都有特定的血量,第\(i\)种玩具小人的血量就是整数\(i\).此外,每种玩具小人还有自己的攻击力, ...
- Log Parser Studio 分析 IIS 日志
Log Parser Studio 分析 IIS 日志 来源 https://www.cnblogs.com/lonelyxmas/p/8671336.html 软件下载地址: Log Parser ...
- ATR102E Stop. Otherwise... [容斥]
第一道容斥 \(ans[i] = \sum_{j = 0}^{min(cnt, n / 2)} (-1)^j \tbinom{cnt}{j} \tbinom{n - 2*j + k - 1}{k - ...
- RequestContextHolder 很方便的获取 request
在 Spring boot web 中我们可以通过 RequestContextHolder 很方便的获取 request. ServletRequestAttributes requestAttri ...
- Dynamic CRM 2015学习笔记(2)更改系统显示语言
默认装的是英文的系统,想换成中文的.下面列出操作步骤: 1. 下载并安装语言包 http://www.microsoft.com/en-US/download/details.aspx?id=4501 ...
- linux中,使用cat、head、tail命令显示文件指定行
小文件可以用cat(也可以用head.tail) 显示文件最后20行:cat err.log | tail -n 20 显示文件前面20行:cat err.log | head -n 20 从20行开 ...
- 老铁,告别postman,用pycharm来调接口,顺便把接口脚本也写了
最近,一位同事在用postman调涉及到依赖的接口的时候 postman设置了环境变量,但是老是获取不到依赖接口返回的值,至于的啥原因呢,@#¥%……&*()! 其实,用pycharm一样可以 ...
- Baker Vai LightOJ - 1071 (MCMF)
在个给出的矩阵从,从左上角走到右下角,然后再从右下角走到左上角,两次不能经过想同的点,每个点都有一个价值,问最大的价值是多少. 可以把原来的问题化简成从左上角走两条路到右下角,然后把价值加起来,然是这 ...