一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题:
解决分布式系统中的负载均衡问题
背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务
硬Hash映射:将每台服务器结点进行编号,0到N-1,Key%N就是映射到的服务器结点编号
硬Hash映射存在的问题:当分布式系统中服务器结点个数N变化的时候,每个Key对应的服务器结点的映射关系都要被改变,这会导致大量的Key会被重定向到不同的服务器结点上从而造成大量的缓存不命中,这种情况在分布式系统中是非常糟糕的,这个就是所谓的缓存雪崩,当这种情况发生时,服务器的数据库会存在非常大的压力,很可能会直接宕机
怎么解决硬Hash映射存在的问题?
一致性Hash算法
一致性Hash算法
原理:将整个Hash空间组织成一个虚拟的圆环,如假设某个哈希函数H的值的空间为0到2的32次方-1,即hash值是一个32位的无符号整型数,整个Hash空间环如下:
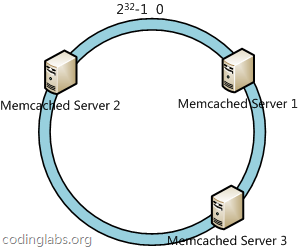
下一步将各个服务器结点使用H哈希函数进行哈希映射,具体可以选择服务器的IP或者主机名作为关键字进行映射,这样每台服务器就能确定其在Hash空间上的位置,比如下图:
接下来我们将数据对象映射到Hash空间环上,假设我们有A,B,C,D四个数据对象,他们的Hash空间环上的位置如下:
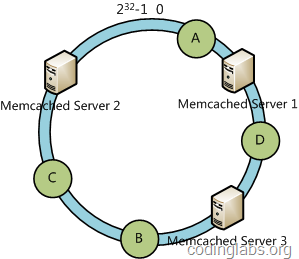
接下来就是怎么把数据对象映射到服务器结点的问题,映射规则:每个数据对象顺时针遇到的第一个服务器结点就是映射到的服务器结点,根据一致性Hash算法:A会被映射到服务结点1,D会被映射到服务器结点3,BC会被映射到服务器结点2
那一致性Hash算法的优势到底在哪里呢?
我们现在假设两种情况:
情况1:服务器3宕机了,不可用了
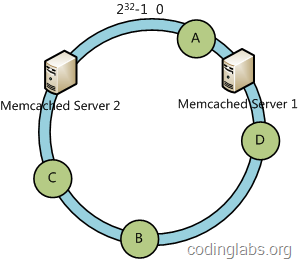
这种情况下,A还是映射到服务结点1,BC还是映射到服务结点2,因为服务器结点3宕机了,数据对象D无法映射到服务器结点3,根据我们的映像规则:数据对象D也映射到服务器结点2,我们可以发现当服务器结点3宕机的时候,影响到的数据对象只有服务器3和服务器1之间的数据对象,也就是数据对象D,对比硬Hash映射:当服务器结点N变化的时候,采用一致性Hash算法影响到的数据对象更少,也就是很多的映射关系对象都不用改变,不会造成缓存雪崩
情况2:新增一个服务器结点4
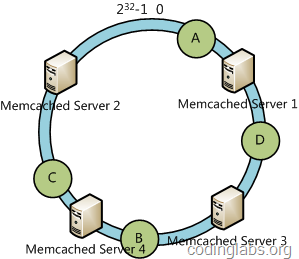
这种情况下,映射关系被改变的只有数据对象B,即新增服务器结点3和服务器结点3之间的数据对象(新增服务器结点逆时针遇到的第一个服务器结点)
这样情况下,当服务器结点数量N变化的时候,被影响的数据对象也很少,所以一致性Hash算法确实是有用的
当然有一种特殊情况需要我们考虑一下:
当服务器结点太少且服务器结点的Hash值台解决时,容易造成因为结点分布不均而造成的数据对象倾斜问题,比如下图:
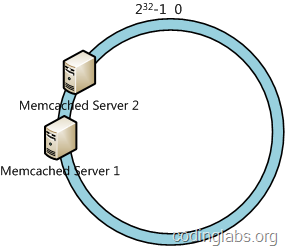
这种情况容易造成数据对象大大部分映射到服务器结点1的问题(数据倾斜问题),这样服务器结点1压力很大,而服务2却很空闲
那怎么解决这种问题呢?
采用虚拟结点的方式,即对每一个服务器结点计算多个Hash值,每个计算结果位置都放置一个服务器结点,叫做虚拟结点,具体可以在服务器IP或者主机名后面增加编号实现,比如下图:
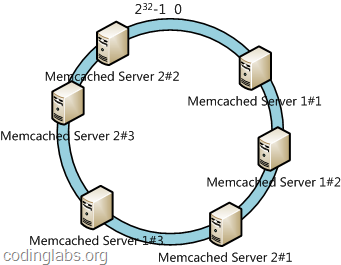
这样数据对象倾斜问题将会得到有效的解决
一致性Hash算法的原理与实现(分布式映射算法)的更多相关文章
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 分方式缓存常用的一致性hash是什么原理
分方式缓存常用的一致性hash是什么原理 一致性hash是用来解决什么问题的?先看一个场景有n个cache服务器,一个对象object映射到哪个cache上呢?可以采用通用方法计算object的has ...
- 一致性hash和solr千万级数据分布式搜索引擎中的应用
互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中 获得成功,这个和当前的开源技术.海量数据架构有着必不可分的关 ...
- redis分布式映射算法
redis分布式映射算法 一致性Hash算法的原理和实现 为了解决分布式系统中的负载均衡的问题 背景问题 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载 ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 一致性Hash的原理与实现
应用场景 在了解一致性Hash之前,我们先了解一下一致性Hash适用于什么场景,能解决什么问题?这里先放一下我自己认为适用的场景.一致性Hash适用于服务器动态扩展且需要负载均衡的场景 试想以下场景, ...
- Golang 实现 Redis(7): Redis 集群与一致性 Hash
本文是使用 golang 实现 redis 系列的第七篇, 将介绍如何将单点的缓存服务器扩展为分布式缓存.godis 集群的源码在Github:Godis/cluster 单台服务器的CPU和内存等资 ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
随机推荐
- 在centos7上编译安装nginx
题前,先放一个有图有真相的博客链接:https://www.cnblogs.com/zhang-shijie/p/5294162.html 虽然别人说的很详细,但还是记录一下 1.VMWare Wor ...
- python语言学习---3
第四天 1.set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的, 这点和 dict 的 key很像. (不信可以输出下试试 ~-~ )另外,其存储的对象必须不可变 ...
- Flutter 布局(二)- Padding、Align、Center详解
本文主要介绍Flutter布局中的Padding.Align以及Center控件,详细介绍了其布局行为以及使用场景,并对源码进行了分析. 1. Padding A widget that insets ...
- 【Apache运维基础(6)】Apache的日志管理与分析
简述 Apache 访问日志在实际工作中非常有用,比较典型的例子是进行网站流量统计,查看用户访问时间.地理位置分布.页面点击率等.Apache 的访问日志具有如下4个方面的作用: 记录访问服务器的远程 ...
- SQL Server 事务隔离级别
一.事务隔离级别控制着事务的如下表现: 读取数据时是否占用锁以及所请求的锁类型. 占用读取锁的时间. 引用其他事务修改的行的读操作是否: 在该行上的排他锁被释放之前阻塞其他事务. 检索在启动语句或事务 ...
- c/c++ 编译器提供的默认6个函数
c/c++ 编译器提供的默认6个函数 1,构造函数 2,拷贝构造函数 3,析构函数 4,=重载函数 5,&重载函数 6,const&重载函数 #include <iostream ...
- Zabbix监控文件是否存在/文件大小
检查C:\Zabbix\zabbix_agentd.log文件是否存在 zabbix_get -s 10.16.4.1 -k vfs.file.exists[C:\\Zabbix\\zabbix_ag ...
- Ubuntu下 MySQL的“ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)”
今天闲来无事,在Ubuntu上掏鼓一下mysql.但尴尬的是,当我输入mysql -u root -p的时候,抛出了一个错误:ERROR 1045 (28000): Access denied for ...
- 2802:小游戏利用bfs来实现
之前使用的是递归的方法来解决的问题,后来有点想用bfs(宽度优先搜索来尝试一下的想法,在网上看到有人使用了dfs(深度优先搜索)更加坚定了自己的这种想法. 这个方法首先是以顶点的四组开始,加入那些没有 ...
- 【2018.05.10 智能驾驶/汽车电子】AutoSar Database-ARXML及Vector Database-DBC的对比
最近使用python-canmatrix对can通信矩阵进行编辑转换时,发现arxml可以很容易转换为dbc,而dbc转arxml却需要费一番周折,需要额外处理添加一些信息. 注意:这里存疑,还是需要 ...