执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client
1、执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client,错误如下所示:
// :: ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:)
at $line3.$read$$iwC$$iwC.<init>(<console>:)
at $line3.$read$$iwC.<init>(<console>:)
at $line3.$read.<init>(<console>:)
at $line3.$read$.<init>(<console>:)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.<init>(<console>:)
at $line3.$eval$.<clinit>(<console>)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoop.reallyInterpret$(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$$$anonfun$apply$mcZ$sp$.apply$mcV$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply$mcZ$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:)
at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$process(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:)
at org.apache.spark.repl.Main$.main(Main.scala:)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
// :: INFO SparkUI: Stopped Spark web UI at http://192.168.19.131:4040
// :: INFO DAGScheduler: Stopping DAGScheduler
// :: INFO YarnClientSchedulerBackend: Shutting down all executors
// :: INFO YarnClientSchedulerBackend: Asking each executor to shut down
// :: INFO YarnClientSchedulerBackend: Stopped
// :: INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: ERROR Utils: Uncaught exception in thread main
java.lang.NullPointerException
at org.apache.spark.network.netty.NettyBlockTransferService.close(NettyBlockTransferService.scala:)
at org.apache.spark.storage.BlockManager.stop(BlockManager.scala:)
at org.apache.spark.SparkEnv.stop(SparkEnv.scala:)
at org.apache.spark.SparkContext$$anonfun$stop$.apply$mcV$sp(SparkContext.scala:)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:)
at org.apache.spark.SparkContext.stop(SparkContext.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:)
at $line3.$read$$iwC$$iwC.<init>(<console>:)
at $line3.$read$$iwC.<init>(<console>:)
at $line3.$read.<init>(<console>:)
at $line3.$read$.<init>(<console>:)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.<init>(<console>:)
at $line3.$eval$.<clinit>(<console>)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoop.reallyInterpret$(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$$$anonfun$apply$mcZ$sp$.apply$mcV$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply$mcZ$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:)
at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$process(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:)
at org.apache.spark.repl.Main$.main(Main.scala:)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
// :: INFO SparkContext: Successfully stopped SparkContext
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:)
at $iwC$$iwC.<init>(<console>:)
at $iwC.<init>(<console>:)
at <init>(<console>:)
at .<init>(<console>:)
at .<clinit>(<console>)
at .<init>(<console>:)
at .<clinit>(<console>)
at $print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoop.reallyInterpret$(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$$$anonfun$apply$mcZ$sp$.apply$mcV$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply$mcZ$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:)
at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$process(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:)
at org.apache.spark.repl.Main$.main(Main.scala:)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) java.lang.NullPointerException
at org.apache.spark.sql.execution.ui.SQLListener.<init>(SQLListener.scala:)
at org.apache.spark.sql.SQLContext.<init>(SQLContext.scala:)
at org.apache.spark.sql.hive.HiveContext.<init>(HiveContext.scala:)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.spark.repl.SparkILoop.createSQLContext(SparkILoop.scala:)
at $iwC$$iwC.<init>(<console>:)
at $iwC.<init>(<console>:)
at <init>(<console>:)
at .<init>(<console>:)
at .<clinit>(<console>)
at .<init>(<console>:)
at .<clinit>(<console>)
at $print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoop.reallyInterpret$(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$.apply(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$$$anonfun$apply$mcZ$sp$.apply$mcV$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopInit.scala:)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply$mcZ$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$.apply(SparkILoop.scala:)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:)
at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$process(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:)
at org.apache.spark.repl.Main$.main(Main.scala:)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) <console>:: error: not found: value sqlContext
import sqlContext.implicits._
^
<console>:: error: not found: value sqlContext
import sqlContext.sql
解决方法如下所示:
参考文章:https://blog.csdn.net/chengyuqiang/article/details/69934382
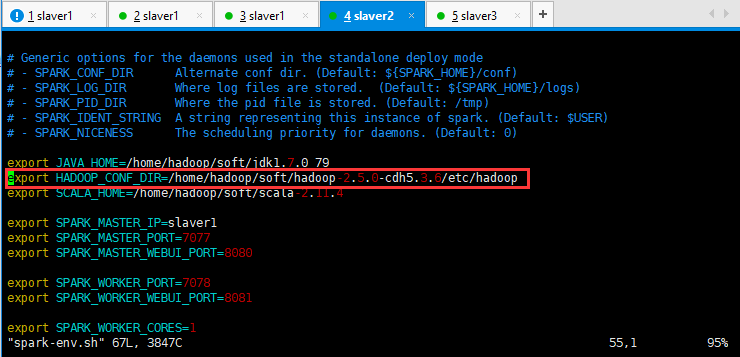
HADOOP_CONF_DIR的路径应该是如下所示,开始我写的是/home/hadoop/soft/hadoop-2.5.0-cdh5.3.6
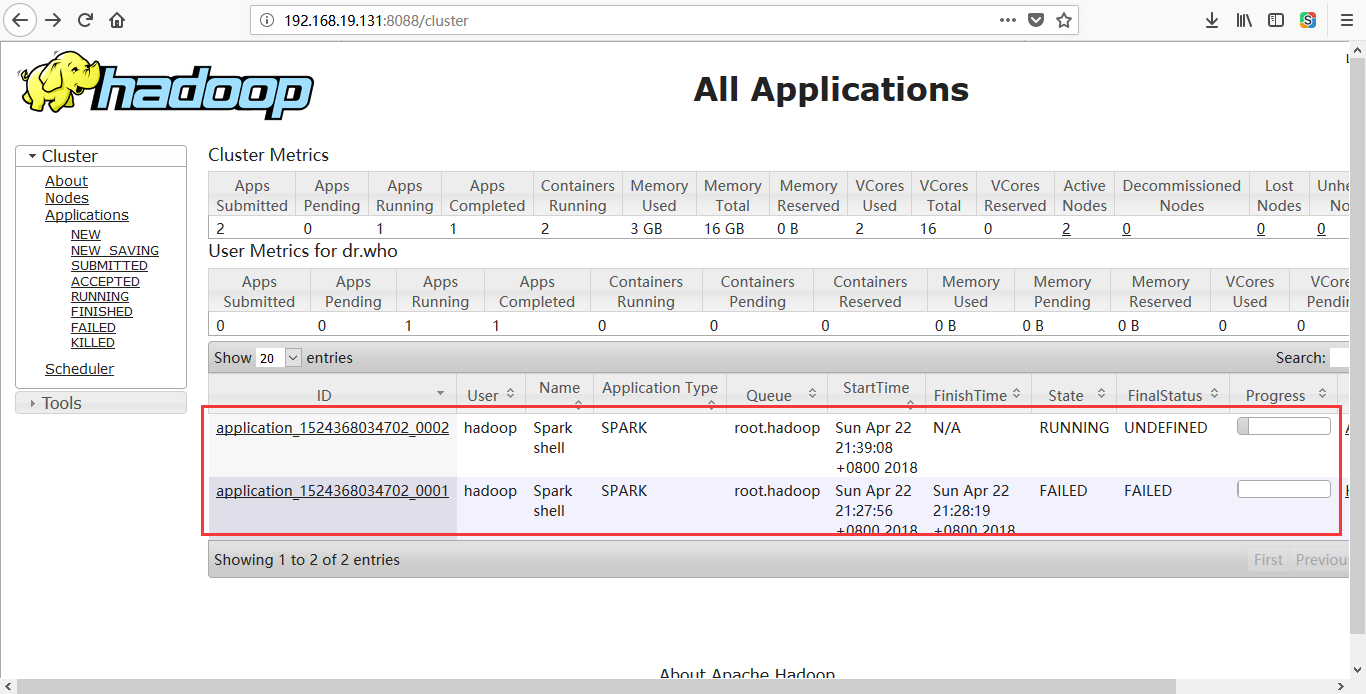
下面分别是运行失败前和运行成功后的效果如下所示:
命令运行如下所示:
[hadoop@slaver1 spark-1.5.-bin-hadoop2.]$ spark-shell --master yarn-client
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO SecurityManager: Changing view acls to: hadoop
// :: INFO SecurityManager: Changing modify acls to: hadoop
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
// :: INFO HttpServer: Starting HTTP Server
// :: INFO Utils: Successfully started service 'HTTP class server' on port .
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.
/_/ Using Scala version 2.10. (Java HotSpot(TM) -Bit Server VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
// :: INFO SparkContext: Running Spark version 1.5.
// :: WARN SparkConf:
SPARK_WORKER_INSTANCES was detected (set to '').
This is deprecated in Spark 1.0+. Please instead use:
- ./spark-submit with --num-executors to specify the number of executors
- Or set SPARK_EXECUTOR_INSTANCES
- spark.executor.instances to configure the number of instances in the spark config. // :: INFO SecurityManager: Changing view acls to: hadoop
// :: INFO SecurityManager: Changing modify acls to: hadoop
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
// :: INFO Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.19.131:33571]
// :: INFO Utils: Successfully started service 'sparkDriver' on port .
// :: INFO SparkEnv: Registering MapOutputTracker
// :: INFO SparkEnv: Registering BlockManagerMaster
// :: INFO DiskBlockManager: Created local directory at /tmp/blockmgr-309a3ff2-fb4f-4f01-a5d9-2ab7db4d765c
// :: INFO MemoryStore: MemoryStore started with capacity 534.5 MB
// :: INFO HttpFileServer: HTTP File server directory is /tmp/spark-049ba1b9---b3dc-34f44c846003/httpd-d1991045-b8e1-419f--a4c7762e1e2c
// :: INFO HttpServer: Starting HTTP Server
// :: INFO Utils: Successfully started service 'HTTP file server' on port .
// :: INFO SparkEnv: Registering OutputCommitCoordinator
// :: INFO Utils: Successfully started service 'SparkUI' on port .
// :: INFO SparkUI: Started SparkUI at http://192.168.19.131:4040
// :: WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
// :: WARN YarnClientSchedulerBackend: NOTE: SPARK_WORKER_MEMORY is deprecated. Use SPARK_EXECUTOR_MEMORY or --executor-memory through spark-submit instead.
// :: WARN YarnClientSchedulerBackend: NOTE: SPARK_WORKER_CORES is deprecated. Use SPARK_EXECUTOR_CORES or --executor-cores through spark-submit instead.
// :: INFO RMProxy: Connecting to ResourceManager at slaver1/192.168.19.131:
// :: INFO Client: Requesting a new application from cluster with NodeManagers
// :: INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster ( MB per container)
// :: INFO Client: Will allocate AM container, with MB memory including MB overhead
// :: INFO Client: Setting up container launch context for our AM
// :: INFO Client: Setting up the launch environment for our AM container
// :: INFO Client: Preparing resources for our AM container
// :: INFO Client: Uploading resource file:/home/hadoop/soft/spark-1.5.-bin-hadoop2./lib/spark-assembly-1.5.-hadoop2.4.0.jar -> hdfs://slaver1:9000/user/hadoop/.sparkStaging/application_1524368034702_0002/spark-assembly-1.5.1-hadoop2.4.0.jar
// :: INFO Client: Uploading resource file:/tmp/spark-049ba1b9---b3dc-34f44c846003/__spark_conf__1110039413441655708.zip -> hdfs://slaver1:9000/user/hadoop/.sparkStaging/application_1524368034702_0002/__spark_conf__1110039413441655708.zip
// :: INFO SecurityManager: Changing view acls to: hadoop
// :: INFO SecurityManager: Changing modify acls to: hadoop
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
// :: INFO Client: Submitting application to ResourceManager
// :: INFO YarnClientImpl: Submitted application application_1524368034702_0002
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: root.hadoop
start time:
final status: UNDEFINED
tracking URL: http://slaver1:8088/proxy/application_1524368034702_0002/
user: hadoop
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as AkkaRpcEndpointRef(Actor[akka.tcp://sparkYarnAM@192.168.19.132:39065/user/YarnAM#-650752241])
// :: INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> slaver1, PROXY_URI_BASES -> http://slaver1:8088/proxy/application_1524368034702_0002), /proxy/application_1524368034702_0002
// :: INFO JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: ACCEPTED)
// :: INFO Client: Application report for application_1524368034702_0002 (state: RUNNING)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.19.132
ApplicationMaster RPC port:
queue: root.hadoop
start time:
final status: UNDEFINED
tracking URL: http://slaver1:8088/proxy/application_1524368034702_0002/
user: hadoop
// :: INFO YarnClientSchedulerBackend: Application application_1524368034702_0002 has started running.
// :: INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO NettyBlockTransferService: Server created on
// :: INFO BlockManagerMaster: Trying to register BlockManager
// :: INFO BlockManagerMasterEndpoint: Registering block manager 192.168.19.131: with 534.5 MB RAM, BlockManagerId(driver, 192.168.19.131, )
// :: INFO BlockManagerMaster: Registered BlockManager
// :: INFO EventLoggingListener: Logging events to hdfs://slaver1:9000/spark/history/application_1524368034702_0002.snappy
// :: INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: (ms)
// :: INFO SparkILoop: Created spark context..
Spark context available as sc.
// :: INFO YarnClientSchedulerBackend: Registered executor: AkkaRpcEndpointRef(Actor[akka.tcp://sparkExecutor@slaver2:44020/user/Executor#-1604999953]) with ID 1
// :: INFO BlockManagerMasterEndpoint: Registering block manager slaver2: with 417.6 MB RAM, BlockManagerId(, slaver2, )
// :: INFO HiveContext: Initializing execution hive, version 1.2.
// :: INFO ClientWrapper: Inspected Hadoop version: 2.4.
// :: INFO ClientWrapper: Loaded org.apache.hadoop.hive.shims.Hadoop23Shims for Hadoop version 2.4.
// :: INFO HiveMetaStore: : Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
// :: INFO ObjectStore: ObjectStore, initialize called
// :: INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
// :: INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
// :: WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
// :: WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
// :: INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
// :: INFO ObjectStore: Initialized ObjectStore
// :: WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.
// :: WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
// :: INFO HiveMetaStore: Added admin role in metastore
// :: INFO HiveMetaStore: Added public role in metastore
// :: INFO HiveMetaStore: No user is added in admin role, since config is empty
// :: INFO HiveMetaStore: : get_all_databases
// :: INFO audit: ugi=hadoop ip=unknown-ip-addr cmd=get_all_databases
// :: INFO HiveMetaStore: : get_functions: db=default pat=*
// :: INFO audit: ugi=hadoop ip=unknown-ip-addr cmd=get_functions: db=default pat=*
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO SessionState: Created HDFS directory: /tmp/hive/hadoop
// :: INFO SessionState: Created local directory: /tmp/a864abec-e802-46d6--168ef2747988_resources
// :: INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/a864abec-e802-46d6--168ef2747988
// :: INFO SessionState: Created local directory: /tmp/hadoop/a864abec-e802-46d6--168ef2747988
// :: INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/a864abec-e802-46d6--168ef2747988/_tmp_space.db
// :: INFO HiveContext: default warehouse location is /user/hive/warehouse
// :: INFO HiveContext: Initializing HiveMetastoreConnection version 1.2. using Spark classes.
// :: INFO ClientWrapper: Inspected Hadoop version: 2.4.
// :: INFO ClientWrapper: Loaded org.apache.hadoop.hive.shims.Hadoop23Shims for Hadoop version 2.4.
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO HiveMetaStore: : Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
// :: INFO ObjectStore: ObjectStore, initialize called
// :: INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
// :: INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
// :: WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
// :: WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
// :: INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Query: Reading in results for query "org.datanucleus.store.rdbms.query.SQLQuery@0" since the connection used is closing
// :: INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
// :: INFO ObjectStore: Initialized ObjectStore
// :: INFO HiveMetaStore: Added admin role in metastore
// :: INFO HiveMetaStore: Added public role in metastore
// :: INFO HiveMetaStore: No user is added in admin role, since config is empty
// :: INFO HiveMetaStore: : get_all_databases
// :: INFO audit: ugi=hadoop ip=unknown-ip-addr cmd=get_all_databases
// :: INFO HiveMetaStore: : get_functions: db=default pat=*
// :: INFO audit: ugi=hadoop ip=unknown-ip-addr cmd=get_functions: db=default pat=*
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO SessionState: Created local directory: /tmp/5990c858--40f6-80a5-cb10039ec99a_resources
// :: INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/5990c858--40f6-80a5-cb10039ec99a
// :: INFO SessionState: Created local directory: /tmp/hadoop/5990c858--40f6-80a5-cb10039ec99a
// :: INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/5990c858--40f6-80a5-cb10039ec99a/_tmp_space.db
// :: INFO SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext. scala>
执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client的更多相关文章
- 异常笔记:运行hdfs copyFromLocal 上传文件报错
把本地文件系统,复制到dfs文件系统时报错的错 [hadoop@localhost ~]$ hdfs dfs -copyFromLocal /home/hadoop/mk.txt /xg_test/ ...
- 安装atlas后执行hive命令报错
在集群中安装atlas,在安装atlas的节点上执行hive -e "show databases;" 正常,但是在集群中其他节点上执行hive -e "show dat ...
- 解决Homestead yarn , npm run dev, 命令报错问题!
解决Homestead yarn , npm run dev, 命令报错问题! 2018年06月01日 11:50:51 偶尔发发颠 阅读数:1654 版权声明:本文为博主原创,未经博主同意,不 ...
- php artisan 命令报错,什么命令都是这个错误,cmd下运行也不行,又没看到语法错误
Laravel 5.1 以上的版本的框架需求PHP的版本是5.5以上的版本.如果你的PHP版本等级太低,将会出现上述的问题. 估计你要升级你的PHP版本了.
- 运行spark官方的graphx 示例 ComprehensiveExample.scala报错解决
运行spark官方的graphx 示例 ComprehensiveExample.scala报错解决 在Idea中,直接运行ComprehensiveExample.scala,报需要指定master ...
- Python3安装Celery模块后执行Celery命令报错
1 Python3安装Celery模块后执行Celery命令报错 pip3 install celery # 安装正常,但是执行celery 命令的时候提示没有_ssl模块什么的 手动在Python解 ...
- hadoop命令报错:权限问题
root用户执行hadoop命令报错: [root@vmocdp125 conf]# hadoop fs -ls /user/ [INFO] 17:50:42 main [RetryInvocatio ...
- RedHat中敲sh-copy-id命令报错:-bash: ssh-copy-id: command not found
RedHat中敲sh-copy-id命令报错:-bash: ssh-copy-id: command not found 在多台Linux服务器SSH相互访问无需密码, 其中进入一台Linus中,对其 ...
- Python3 pip命令报错:Fatal error in launcher: Unable to create process using '"'
Python3 pip命令报错:Fatal error in launcher: Unable to create process using '"' 一.问题 环境:win7 同时安装py ...
随机推荐
- GAN_李弘毅讲解
GAN_李弘毅讲解: 上式中,xi从data中sample的一部分,现在的目的就是最大化这个似然函数,使得Generator最可能产生data中的这些sample: 上式中之所以如此设计V函数,是为了 ...
- 前端清除缓存方法(微信缓存引起的bug)
bug1:在新版微信中,部门安卓机子(华为)出现window.location.href/window.location.reload....等方法来刷新本页面链接,发现页面没有被刷新,经过排查,发现 ...
- The superclass "javax.servlet.http.HttpServlet" was not found on the Java Build Path 解决办法
♦ 未在 Java构建路径中 找到父类 "javax.servlet.http.HttpServlet" ♦ 解决办法: 项目右击 → Build Path → 右侧 Add L ...
- MYSQL在centos上主从配置
主从配置理论传送门:http://blog.csdn.net/hguisu/article/details/7325124 具体配置方案: 一:MYSQL主从配置 1.1 部署环境 主(maste ...
- 【转】采用dlopen、dlsym、dlclose加载动态链接库
1.前言 为了使程序方便扩展,具备通用性,可以采用插件形式.采用异步事件驱动模型,保证主控制逻辑不变,将各个业务以动态链接库的形式加载进来,这就是所谓的插件.linux提供了加载和处理动态链接库的系统 ...
- mysql:批量插入不同的UUID
INSERT INTO t_base_role_resource_ref (refID, roleID, resID, orgID, belongTo) SELECT uuid() AS refID, ...
- peizhiwenjian
自定义配置文件 如果你不想使用application.properties作为配置文件,怎么办?完全没问题 java -jar myproject.jar --spring.config.locati ...
- mybatis xml中不能直接用大于号、小于号要用转义字符
2.使用 <![CDATA[ ]]>标记
- Codeforces 1114F Please, another Queries on Array? [线段树,欧拉函数]
Codeforces 洛谷:咕咕咕 CF少有的大数据结构题. 思路 考虑一些欧拉函数的性质: \[ \varphi(p)=p-1\\ \varphi(p^k)=p^{k-1}\times (p-1)= ...
- 表单,table的css
table{table_layout:fixed;border-collapse: collapse;border-spacing: 0}border-collapse: collapse 边框合并在 ...