论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)

论文链接:https://arxiv.org/abs/1506.04924
摘要
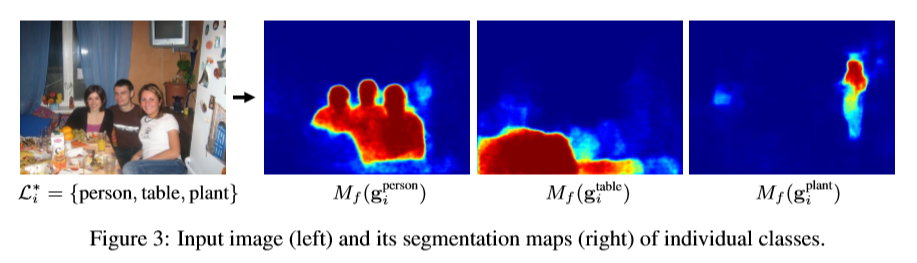
该文提出了基于混合标签的半监督分割网络。与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类任务分离,并为每个任务单独学习一个分离的网络。分类网络识别与图片相关的标签,然后在每个识别的标签中进行二进制的分割。Decoupled网络可以基于图像级别标签学习分类网络,基于像素级别标签学习分割网络。该网络通过桥链接层获得类别明确的激活maps来减少分割的搜索空间。该文在少量训练数据的条件下仍优于其他半监督方法。
介绍
分割网络对图片中目标物进行标记问题的挑战有:物体位置的变化,尺寸大小的变化,模糊,背景干扰等。DNN在标准数据集VOC上变现较好。但训练DNN需要大量的标签,因此,可以利用的标签只适用于小数量类别的图片,从而有监督的DNN应用于包含较多目标的分割任务较困难。
半监督或者弱监督通过利用每个bounding box的弱标签来进行训练。在缺失较完整的训练样本时,通常假设有许多可利用的弱标签可用于训练。实际中通过迭代可以获得较好的效果,但模型的训练条件要求较高,不易收敛,很难复现。
该文利用一小部分的完好的标签和大部分弱标签(每个图片中物体的类别)进行半监督训练分割。输入图片的每个类别由分类网络进行分类,而对每个标签的前景分割依赖于后续的分割网络。另外,桥结构的作用是将确定的类别的信息从分类网络传递到分割网络中进而让分割网络一次只关注由分类网络确定的一个类别的分割。
分类网络和分割网络的训练是彼此分离的,分别基于图片级标签和像素级的标签。同时,算法不需要迭代训练,易于复现。分类和分割大大减少了分割的搜索空间,进而可以训练大规模标签的数据。
相关工作
对于若标记标签,利用CNN基于EM或者MIL算法进行预测潜在的分割masks。但相比有监督学习,弱监督由于训练时没有用于分割的直接监督信号,因此表现效果较差。半监督学习是连接全监督和弱监督之间的桥梁。在标准的半监督学习框架中,只提供部分带有完整标签的训练数据,然后将剩下的数据进行预测所有的分割类别。然而,在深度网络中训练大量的参数,这十分不合理,采用混合的标签进行训练。混合标签中目标物体的类别相比strong labels更易获得。通过挖掘其他带有strong labels的训练样本,弱监督更利于深层网络的训练。
对于有监督的CNN,基于strong labels的监督进行迭代推理,并增强对弱监督图片像素标签(图片级与bounding box级别)的分类。虽然利用部分strong annotations确实提高了分割的准确率,但需要进行大量的迭代操作,效果是启发式的,具有不确定性,同时,也增加了对结果的复现。
算法
网络结构如下,由三部分组成:(1)分类网络(2)分割网络(3)连接二者的桥连接层
该模型中语义分割通过连续的分类和分割操作进行实现。过程:输入一张图片,分类网络会识别出与图片相关的类别。然后,分割网络针对每一个单独的类别进行像素级别的前景分割。这里,分类于分割之间的差异会带来影响,该文通过在这两个网络之间增加一个桥连接层将分类网路确定的类别信息传递到分割网络中,进而可以对分离的目标函数进行优化。
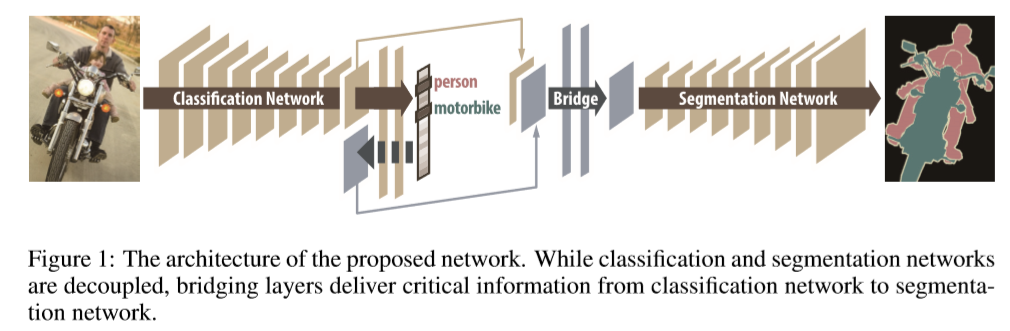
网络的训练:含有像素级标签较少,但图片级标签较多的混合的类别不平衡的可训练的数据。(1)利用丰富的像素级的标签训练分类网络,(2)固定分类网络,利用带strong labels的样本联合训练桥连接层和分割网络。(3)对于strong label的样本数据较少,采用数据增强。
该文做的贡献:(1)提出利用混合标签训练的半监督DNN。(2)桥连接层构建了激活maps,将分类网络映射至分割网络中,为后面的分割提高了较强的预判,同时,减少了训练和测试时的搜索空间。(3)训练过程十分简便,并未使用其他半监督方法常用的迭代操作。
结构
分类网络:
input: 一张图片x,
outputs: a normalized score vector  ,对于L个类别,基于优化后的分类模型
,对于L个类别,基于优化后的分类模型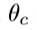 预测出的对应的score。
预测出的对应的score。
目标函数:  ,
, 表示第i个样本对应的ground truth,ec为每个yi对应的loss损失。
表示第i个样本对应的ground truth,ec为每个yi对应的loss损失。
用VGG16作为分类网络(13*(conv+rectification+pooling)+3*fully connected layers)。
loss:sigmoid cross-entropy
对于分类网络预测出的标签对应的区域x,由分割网络进行处理。
分割网络
将由桥连接层得到输入图像xi的类别激活映射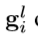 送如分割网络,经过softmax 变换后得到一个两通道的类别确定的分割map
送如分割网络,经过softmax 变换后得到一个两通道的类别确定的分割map 。
。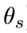 为分割网络的参数。M有前景和背景两个通道,分割相当于对像素级别的回归。目标函数如下
为分割网络的参数。M有前景和背景两个通道,分割相当于对像素级别的回归。目标函数如下

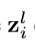 :代表第i张图片类别为l的grount truth值,取值为0或1。
:代表第i张图片类别为l的grount truth值,取值为0或1。
该文应用转置卷积网络作为分割网络。通过一系列的上采样,转置卷积和非线性处理来恢复与图片x相同大小的feature map。利用softmax loss损失来优化上式。
该文改进:分割网络中的分类为二值分类,是某个类别L或者不是, 借助于分类网络所确定的类别,极大的减少了分割网络中的参数。
桥连接层
分割网络的输入需要包含确定的类别及空间信息。桥连接针对每个类别构建一个激活mp。为了编码图片中存在的目标物体。该文利用分类网络中间层的输出(最后一个pooling 层,用fspat表示)。经过卷积池化层后保存空间信息,越深层捕捉更加抽象的全局信息。
虽然fspat包含着丰富的信息,但仍包含图像中相关标签的混合信息。因此,我们需要确定fspat中的类别。该文用BP来得到类别确定的显著图。f(i)作为分类网络中第i层的输出。基于一个确定的类别l下,f(k)中激活函数的相关性由链式法则计算。

 代表class-specific 显著图,
代表class-specific 显著图,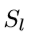 代表类别L的score,上式描述,f(k)中的激活与类别L的相关性。
代表类别L的score,上式描述,f(k)中的激活与类别L的相关性。
class-specific activation map 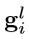 结合fspat与fclsl,将fspat于fclsl按通道进行拼接,产生的同时包含空间信息和class-specific 信息。而由于fspat是固定的,因此,对不同的类别,变化的是fclsl。
结合fspat与fclsl,将fspat于fclsl按通道进行拼接,产生的同时包含空间信息和class-specific 信息。而由于fspat是固定的,因此,对不同的类别,变化的是fclsl。

训练
数据增强:组合裁剪,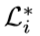 代表与图片相关的一系列ground truth Label,该文枚举了类别中所有可能的组合。通过设置与类别l相关的像素的值({0,1})分为前景和背景。基于region proposal 选取包含前景的图片,同时进行随机采样来增强数据。
代表与图片相关的一系列ground truth Label,该文枚举了类别中所有可能的组合。通过设置与类别l相关的像素的值({0,1})分为前景和背景。基于region proposal 选取包含前景的图片,同时进行随机采样来增强数据。
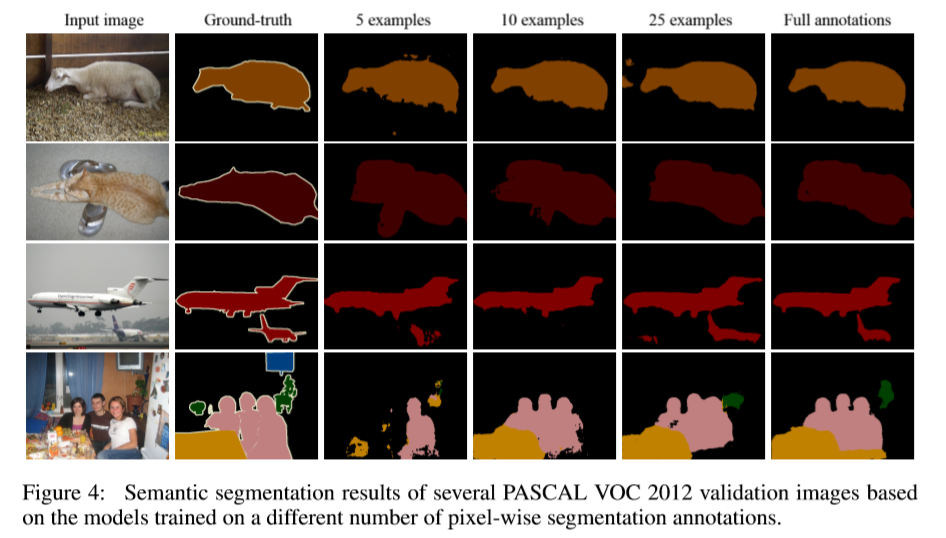
实验

参考
[1] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. IJCV, 88(2):303–338, 2010.
[2] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015.
论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)的更多相关文章
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
- 论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)
论文链接:https://arxiv.org/abs/1802.02611 tensorflow 官方实现: https: //github.com/tensorflow/models/tree/ma ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- [论文阅读笔记] Community aware random walk for network embedding
[论文阅读笔记] Community aware random walk for network embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 先前许多算法都 ...
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLabv2)(CVPR2016)
论文链接:https://arxiv.org/pdf/1606.00915.pdf 摘要 该文主要对基于深度学习的分割任务做了三个贡献,(1)使用空洞卷积来进行上采样来进行密集的预测任务.空洞卷积可以 ...
随机推荐
- SpringBoot多模块搭建,依赖管理
1.创建springboot-multi-module父工程 File→New→Project 然后,Next,选择POM,其他名称自定义 Next→Finish. 说明:打开父工程的pom.xml ...
- 20165237 预备作业3 Linux安装及学习
Linux安装及学习 安装 对操作系统略知一二的我,按照老师发的基于VirtualBox虚拟机安装Ubuntu图文教程慢慢一步步往下做,虽然中间有些小困难,但最终都得以解决,安装成功. 遇到的小困难: ...
- nginx使用https协议
效果: nginx添加ssl模块 ./configure --with-http_ssl_module 生成证书 openssl genrsa -out ca.key 2048 openssl req ...
- Focal Loss
为了有效地同时解决样本类别不均衡和苦难样本的问题,何凯明和RGB以二分类交叉熵为例提出了一种新的Loss----Focal loss 原始的二分类交叉熵形式如下: Focal Loss形式如下: 上式 ...
- CSS3 Hover 动画特效
根据 奇舞团:http://www.75team.com/archives/807 做的demo 根据视频中跟着做的 demo1: <!DOCTYPE html> <html lan ...
- QT 出现信号槽不触发的问题
主要有以下三点: 1)槽函数未声明为 slots 类型, 信号函数未声明为 signals所致 2)槽函数和信号函数的参数不一致所致 3)connect关联时失败
- 使用percona-xtrabackup工具对mysql数据库的备份方案
使用percona-xtrabackup工具对mysql数据库的备份方案 需要备份mysql的主机 172.16.155.23存放备份mysql的主机 172.16.155.22 目的:将155.23 ...
- python pip下载速度慢的解决方法
pip是python内置的非常好用的下载工具,基本可以下载全部的python库.它还有一个非常好的特点,当你安装一个库的时候,它会自动帮你安装所有这个库的依赖库.完全一键式操作.非常方便.但是由于pi ...
- Light OJ 1012
经典搜索水题...... #include<bits/stdc++.h> using namespace std; const int maxn = 20 + 13; const int ...
- PHP中使用Redis长连接笔记
pconnect函数声明 其中time_out表示客户端闲置多少秒后,就断开连接.函数连接成功返回true,失败返回false: pconnect(host, port, time_out, pers ...