论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)

论文源址:https://arxiv.org/abs/1709.04609
摘要
该文提出了基于深度学习的实例分割框架,主要分为三步,(1)训练一个基于ResNet-101的通用模型,用于分割图像中的前景和背景。(2)将通用模型进行微调成为一个实例分割模型,借助于视频第一帧的标签文件对不同个体进行实例分割。同时,从实例分割模型中得到每一个物体的像素级score map。每张score map代表物体类别的概率,并且只和视频第一帧的ground truth 计算。(3)提出空间传播网络用于增强前面得到的score map。此结构的目的是如何基于视频中成对的相似性对粗糙的score map在空间上进行传播。此外,该文在强化后的score map上引入了一个核函数,基于视频的时空关联性得到一个最好的连通区域。
介绍
该文主要解决对于给定第一帧中每个目标物体的ground truth,在视频流中都可以进行追踪与预测标记的问题,当处理非刚性物体,比如说人动物等是存在较大挑战性的,因为其有不同的视角,姿态也不同。由于在视频帧中,前景可能被全部覆盖,因此,重合也是一个较大的挑战。
目前使用FCN对视频中的每一帧进行前景/背景的分割。基于无监督学习,通过训练集学习得到一个前景的生成模型。基于半监督,可以使用视频中第一帧的分割mask最为关注的前景区域对模型进行微调。该文将此法进行扩展,分解为前景分割和实例分割。通过训练集的所有物体实现前景的分割训练,通过每一个确定的实例将前景分割的结果进行分类。
由于基于FCN网络进行的分割得到的结果标签不准确,虽然引入了CRF的后处理,但占用内存与较大的计算消耗,导致效果并不理想。该文为此将边界增强任务处理成一个有效像素预测的空间传播问题。提出了空间传播网络(SPN),确切的说,是使用一个2D的传播模型学习好的像素级有效性作为指导将分割概率进行传播的过程。为了消除不相关的分割,提出了 connected region-aware filter (CRAF)。
本文整体流程如下:

本文的主要贡献如下:
(1)将分割网络处理成实例分割。将任务分解为前景分割和实例识别。
(2)提出了SPN通过学习空间的相关性进而增强分割边界。
(3)建立connected region-aware filter (CRAF)用于消除不相关的分割结果。
相关工作
视频物体分割:两种方式,无监督和半监督,无监督旨在分割物体的前景,主要方法有超像素,显著性检验和光流。为了结合高层次的信息像目标物,proposals用于追踪分割的目标,并进而通过视频生成连续的区域。但由于这种方式需要大量的计算资源,产生大量的proposals与分割区域,不适合线上的应用。
实例分割:该文与实例分割相关,包括遮挡的处理与分割边界的增强处理。大多数的解决方式是先生成proposal,然后对proposal进行分割预测。
一个多阶段的网络迭代的产生边界框proposals,对proposals进行分割预测,生成class score。然而,实例分割经常会遇到大量的遮挡问题。为此,可以引入dense CRF应用于patch -level用于生成实例的mask。为了细化不同实例之间的边界,可以将概率模型当作是后处理的一种手段。比如使用全连接的CRF当作RNN,用于端到端的训练。
分割实例的学习
给定视频第一帧中实例的标签,该文的目标是整个视频中的物体能够实现实例分割。因此,先训练一个前景/背景分割的模型用于定位物体。然后,对此通用模型进行微调学习得到一个实例级别的分割模型。
I:前景分割:该文基于ResNet-101进行搭建前景/背景分割网络。对ResNet-101做了以下两点的改进:(1)将用于分类的全连接层全部移除(2)在上采样的过程中将不同卷积层得到的feature map进行融合用于获得更多的细节信息。
ResNet-101包含5个卷积模块,每个模块中都包含几个卷积层。该文参考ResNet-101中的第三至第五的卷积模块,得到的feature map大小分别为输入的1/8,1/16,1/32。最后,将这些feature map进行上采样并进行拼接操作。流程如下:

损失函数为基于softmax的像素级的交叉熵损失用于优化,由于前景/背景所占比不同,因此,在损失函数中增加了权重。损失函数如下:

II:实例识别:前景分割完后,需要对分割的前景进行实例识别,仍采用上述的损失函数,并对其进行微调,对于每一个实例,损失函数包含目标实例与背景两个通道。由于视频中可能会包含大量的目标实例,而且不同实例的模型并不相同。为了解决这种混淆问题,比如针对两个相邻的实例,从每个实例级的模型中计算得到一个score map,这个score map象征着实例分割中类别的概率。为了有效的利用分割的前景图,强制将score map中包含前景部分的值设置为非0值。一旦从不同的实例模型中得到score map,按照score map中概率最大的类别进行标记进而实现实例分割。
III:网络的强化与训练:为了训练通用(前景/背景)分割模型,采用DAVIS训练集的标注数据进行预训练,接着使用DAVIS测试中第一帧目标的标注进行微调增强。通用模型的训练寻用ResNet-101的参数作为权重的初始化。基于SGD进行优化,batch size 为1,学习率为1e-8迭代10万步。对于实例识别网络的训练,batch size 设置为1,学习率初始化为1e-8,后每隔10000步学习率减半,共迭代30000步,由于训练样本的数量较少,采用相关性变换,为每一帧采样1000个样本。
MASK 增强
该部分对每个帧分割的结果进行增强,通过空间传播网络(SPN)将目标物体粗略的边界形状进行优化,同时,CRAF用于消除非相关联区域。这里值得注意的是,这两个强化步骤对与实例来说是独立的。训练好的SPN可以应用到任意一个实例中。
I:空间传播网络:SPN包含一个深度卷积网络用于学习相关的实例及一个空间线性传播模型用于增强粗略的mask。粗略的mask基于相关性进行优化,包括每对像素之间的联系。每个模型都是不同的,同时使用SGD进行优化。空间线性传播模型由于循环结构的线性复杂度,因此在inference时高效的进行计算。
SPN的传播模型通过在一个2D的map上进行线性传播操作进而构建一个可学习的图。 代表在mxn大小feature map上的一个传播隐藏层。h_i,j,x_i,j代表在(i,j)处的隐藏层的像素,与feature map值。
代表在mxn大小feature map上的一个传播隐藏层。h_i,j,x_i,j代表在(i,j)处的隐藏层的像素,与feature map值。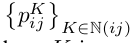 代表一系列(i,j)处的权重,K是(i,j)的相邻坐标,由
代表一系列(i,j)处的权重,K是(i,j)的相邻坐标,由 表示。
表示。
2D的线性传播按照从左至右的顺序进行传播:

hK代表隐藏层中的相邻像素。反向传播过程中的导数为
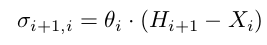

该文使用常规的对称的分割卷积网络输出所有Pi-1,i。误差流在隐藏层中反向流动,传递到引导网络中,最终实现端到端的训练。
CRAF
由于未考虑时间信息,在实例之间存在遮挡问题,提出了CRAF根据视频中相邻帧的一致性来修正实例混淆问题。


Reference
[1] T. Brox and J. Malik. Object segmentation by long term analysis of point trajectories. In ECCV, 2010. 2
[2] S. Caelles, K.-K. Maninis, J. Pont-Tuset, L. Leal-Taixé,D. Cremers, and L. Van Gool. One-shot video object segmentation. In CVPR, 2017. 1, 2
[3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. 2015. 1, 2
论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)的更多相关文章
- 论文阅读笔记二十:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(CVPR2017)
源文网址:https://arxiv.org/abs/1707.03718 tensorflow代码:https://github.com/luofan18/linknet-tensorflow 基于 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 论文阅读笔记六十三:DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling(CVPR2017)
论文原址:https://arxiv.org/abs/1703.10295 github:https://github.com/lachlants/denet 摘要 本文重新定义了目标检测,将其定义为 ...
- 论文阅读笔记二十九:SSD: Single Shot MultiBox Detector(ECCV2016)
论文源址:https://arxiv.org/abs/1512.02325 tensorflow代码:https://github.com/balancap/SSD-Tensorflow 摘要 SSD ...
- 论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)
论文源址:https://arxiv.org/abs/1506.02640 tensorflow代码:https://github.com/nilboy/tensorflow-yolo 摘要 该文提出 ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- 论文阅读笔记二十六:Fast R-CNN (ICCV2015)
论文源址:https://arxiv.org/abs/1504.08083 参考博客:https://blog.csdn.net/shenxiaolu1984/article/details/5103 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
随机推荐
- HashSet、TreeSet和LinkedHashSet分别基于HashMap、TreeMap和LinkedHashMap
1.如果你需要一个访问快速的Set,你应该使用HashSet: 当你需要一个排序的Set,你应该使用TreeSet: 当你需要记录下插入时的顺序时,你应该使用LinedHashSet. 2.因为Tre ...
- 由JDBC而来的对Class.forName()用法发散
昨日在帮一个学习java的小伙子指导JDBC链接数据库时,在对数据库驱动进行加载时,用到Class.forName(),一直都是照葫芦画瓢,对这种写法一直不是太理解,故查询了相关文档后,将心得记录一下 ...
- nginx 开启静态 gzip 配合 Vue 构建
在站点配置添加如下代码: location ~* \.(css|js)$ { gzip_static on; } 这是 nginx 的静态 gzip功能,会自动查找对应扩展名的文件,如果存在 gzip ...
- 20165237 2017-2018-2 《Java程序设计》第2周学习总结
20165237 2017-2018-2 <Java程序设计>第2周学习总结 教材学习内容总结 1.标识符第一个字符不能是数字. 2.标识符不能是关键字,也不能是true.false和nu ...
- C语言中用于计算数组长度的函数 “strlen() ”。
de>#include<stdio.h>#include<stdlib.h>#define MAX_LEN 255int my_strlen1(const char* s ...
- Photoshop CS6打开图片后看不到怎么办
https://jingyan.baidu.com/album/54b6b9c0d45c632d583b4793.html
- LordPE修复从进程dump出来的内存文件
场景 应急响应中从进程发现被注入了EXE文件,通过processhacker的Memory模块dump出来注入的文件.PE修复后在IDA里反汇编查看这个恶意代码的功能是什么. 解决 LordPE 虚拟 ...
- Pytorch Visdom
fb官方的一些demo 一. show something 1. vis.image:显示一张图片 viz.image( np.random.rand(3, 512, 256), opts=dic ...
- XE7/X10.2 Datasnap使用 dbExpress 连接MySQL数据库
本人使用:DELPHI X10.2.2 版本连接 MYSQL 5.1 (安装 mysql-5.1.72-win32.msi)的32位版本,开始连接不了: 将 MYSQL 5.1 安装目录下bin 中的 ...
- 关于PJ 10.27
题1 : Orchestra 题意: 给你一个 n*m 的矩阵,其中有一些点是被标记过的. 现在让你求标记个数大于 k 个的二维区间个数. n.m .k 最大是 10 . 分析: part 1: 10 ...