一脸懵逼学习MapReduce的原理和编程(Map局部处理,Reduce汇总)和MapReduce几种运行方式
1:MapReduce的概述:
(1):MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
(2):MapReduce由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
(3):这两个函数的形参是key、value对,表示函数的输入信息。
2:MapReduce执行步骤:
(1): map任务处理
(a):读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
(b):写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
(2)reduce任务处理
(a)在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。
(b)写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
(c)把reduce的输出保存到文件中。
例子:实现WordCountApp
3:map、reduce键值对格式:
4:MapReduce流程:
(1)代码编写
(2)作业配置
(3)提交作业
(4)初始化作业
(5)分配任务
(6)执行任务
(7)更新任务和状态
(8)完成作业
5:MapReduce介绍及wordcount和wordcount的编写和提交集群运行的案例:
WcMap类进行单词的局部处理:
package com.mapreduce; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /***
*
* @author Administrator
* 1:4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的值
* KEYOUT是输入的key的类型,VALUEOUT是输入的value的值
* 2:map和reduce的数据输入和输出都是以key-value的形式封装的。
* 3:默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
* 4:key-value数据是在网络中进行传递,节点和节点之间互相传递,在网络之间传输就需要序列化,但是jdk自己的序列化很冗余
* 所以使用hadoop自己封装的数据类型,而不要使用jdk自己封装的数据类型;
* Long--->LongWritable
* String--->Text
*/
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{ //重写map这个方法
//mapreduce框架每读一行数据就调用一次该方法
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value
//key是这一行数据的起始偏移量,value是这一行的文本内容 //1:切分单词,首先拿到单词value的值,转化为String类型的
String str = value.toString();
//2:切分单词,空格隔开,返回切分开的单词
String[] words = StringUtils.split(str," ");
//3:遍历这个单词数组,输出为key-value的格式,将单词发送给reduce
for(String word : words){
//输出的key是Text类型的,value是LongWritable类型的
context.write(new Text(word), new LongWritable());
} }
}
WcReduce进行单词的计数处理:
package com.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /***
*
* @author Administrator
* 1:reduce的四个参数,第一个key-value是map的输出作为reduce的输入,第二个key-value是输出单词和次数,所以
* 是Text,LongWritable的格式;
*/
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{ //继承Reducer之后重写reduce方法
//第一个参数是key,第二个参数是集合。
//框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法
//<hello,{1,1,1,1,1,1.....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
//将values进行累加操作,进行计数
long count = ;
//遍历value的list,进行累加求和
for(LongWritable value : values){ count += value.get();
} //输出这一个单词的统计结果
//输出放到hdfs的某一个目录上面,输入也是在hdfs的某一个目录
context.write(key, new LongWritable(count));
} }
WcRunner用来描述一个特定的作业
package com.mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /***
* 1:用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理中的map,那个作为reduce
* 2:还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
* @author Administrator
*
*/
public class WcRunner { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建配置文件
Configuration conf = new Configuration();
//获取一个作业
Job job = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包
job.setJarByClass(WcRunner.class); //本job使用的mapper和reducer的类
job.setMapperClass(WcMap.class);
job.setReducerClass(WcReduce.class); //指定reduce的输出数据key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); //指定mapper的输出数据key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放路径
FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000/wc/srcdata")); //指定处理结果的输出数据存放路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/wc/output")); //将job提交给集群运行
job.waitForCompletion(true);
} }
书写好上面的三个类以后打成jar包上传到虚拟机上面进行运行: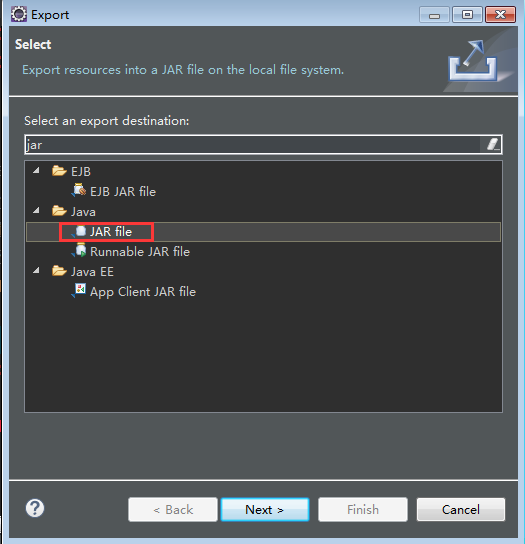
然后启动你的hadoop集群:start-dfs.sh和start-yarn.sh启动集群;然后将jar分发到节点上面进行运行;
之前先造一些数据,如下所示:

内容自己随便搞吧:
然后上传到hadoop集群上面,首选创建目录,存放测试数据,将数据上传到创建的目录即可;但是输出目录不需要手动创建,会自动创建,自己创建会报错:
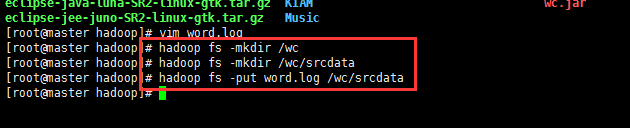
然后将jar分发到节点上面进行运行;命令格式如hadoop jar 自己的jar包 主类的路径
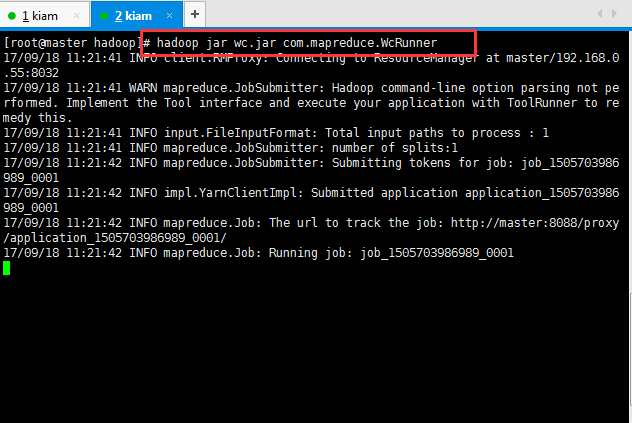
正常性运行完过后可以查看一下运行的效果:
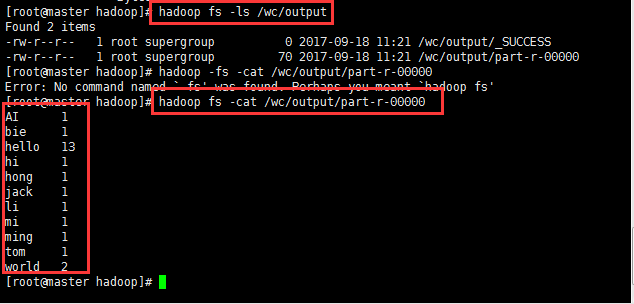
6:MapReduce的本地模式运行如下所示(本地运行需要修改输入数据存放路径和输出数据存放路径):
package com.mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /***
* 1:用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理中的map,那个作为reduce
* 2:还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
* @author Administrator
*
*/
public class WcRunner { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建配置文件
Configuration conf = new Configuration();
//获取一个作业
Job job = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包
job.setJarByClass(WcRunner.class); //本job使用的mapper和reducer的类
job.setMapperClass(WcMap.class);
job.setReducerClass(WcReduce.class); //指定reduce的输出数据key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); //指定mapper的输出数据key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放路径
//FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000/wc/srcdata/"));
FileInputFormat.setInputPaths(job, new Path("d:/wc/srcdata/")); //指定处理结果的输出数据存放路径
//FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/wc/output/"));
FileOutputFormat.setOutputPath(job, new Path("d:/wc/output/")); //将job提交给集群运行
job.waitForCompletion(true);
} }
然后去自己定义的盘里面创建文件夹即可:
然后直接运行出现下面的错误:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "main" java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120)
at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:82)
at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:75)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1255)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1251)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:1250)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1279)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at com.mapreduce.WcRunner.main(WcRunner.java:57)
解决办法:
缺少Jar包:hadoop-mapreduce-client-common-2.2.0.jar
好吧,最后还是没有实现在本地运行此运行,先在这里记一下吧。下面这个错搞不定,先做下笔记吧;
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception
in thread "main" java.lang.IllegalArgumentException: Pathname
/c:/wc/output from hdfs://master:9000/c:/wc/output is not a valid DFS
filename.
at org.apache.hadoop.hdfs.DistributedFileSystem.getPathName(DistributedFileSystem.java:194)
at org.apache.hadoop.hdfs.DistributedFileSystem.access$000(DistributedFileSystem.java:102)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398)
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:145)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:458)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:343)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at com.mapreduce.WcRunner.main(WcRunner.java:57)
7:MapReduce程序的几种提交运行模式:
本地模型运行
1:在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
----输入输出数据可以放在本地路径下(c:/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://master:9000/wc/srcdata)
2:在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://master:9000/wc/srcdata)
集群模式运行
1:将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner
2:在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml
----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar");3:在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改
----要在windows中存放一份hadoop的安装包(解压好的)
----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件
----再要配置系统环境变量 HADOOP_HOME 和 PATH
----修改YarnRunner这个类的源码
一脸懵逼学习MapReduce的原理和编程(Map局部处理,Reduce汇总)和MapReduce几种运行方式的更多相关文章
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置(三台机器跑集群)
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- 一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)
Hive只在一个节点上安装即可: 1.上传tar包:这个上传就不贴图了,贴一下上传后的,看一下虚拟机吧: 2.解压操作: [root@slaver3 hadoop]# tar -zxvf hive-0 ...
- 一脸懵逼学习HBase---基于HDFS实现的。(Hadoop的数据库,分布式的,大数据量的,随机的,实时的,非关系型数据库)
1:HBase官网网址:http://hbase.apache.org/ 2:HBase表结构:建表时,不需要指定表中的字段,只需要指定若干个列族,插入数据时,列族中可以存储任意多个列(即KEY-VA ...
- 一脸懵逼学习HBase的搭建(注意HBase的版本)
1:Hdfs分布式文件系统存的文件,文件存储. 2:Hbase是存储的数据,海量数据存储,作用是缓存的数据,将缓存的数据满后写入到Hdfs中. 3:hbase集群中的角色: ().一个或者多个主节点, ...
- 一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual Hive的数据存储 1.Hiv ...
- 一脸懵逼学习Hive的元数据库Mysql方式安装配置
1:要想学习Hive必须将Hadoop启动起来,因为Hive本身没有自己的数据管理功能,全是依赖外部系统,包括分析也是依赖MapReduce: 2:七个节点跑HA集群模式的: 第一步:必须先将Zook ...
随机推荐
- 前端清除缓存方法(微信缓存引起的bug)
bug1:在新版微信中,部门安卓机子(华为)出现window.location.href/window.location.reload....等方法来刷新本页面链接,发现页面没有被刷新,经过排查,发现 ...
- Delta DVP 系列 PLC 各装置 Modbus 地址
此Modbus地址表以 1 为基础地址 Device Range Type DVP address (Hex) Modbus address (Dec) Effective ES/EX/SS SA/S ...
- 转-CSRF&OWASP CSRFGuard
一. 什么是CSRF?CSRF(Cross-Site Request Forgery)直译的话就是跨站点请求伪造也就是说在用户会话下对某个需要验证的网络应用发送GET/POST请求——而这些请求是未经 ...
- (常用)loogging模块及(项目字典)
loogging模块 '''import logging logging.debug('debug日志') # 10logging.info('info日志') # 20logging.warni ...
- Windows10下Django虚拟环境配置和简单入门实例
环境win10家庭版64位 + python 3.5 + Django 1.8.2 1.创建virtualenv目录 开始/运行/cmd回车,进入cmd窗口,到自己指定的目录下创建virtualenv ...
- mysql的csv数据导入与导出
# 需要station_realtime存在 load data infile 'd:/xxxx/station_realtime2013_01.csv' into table `station_re ...
- python 基础 Two day
1.格式化输出 %s 字符串 %d 数字 %% 转义 % %f 小数 现在有以下需求,让用户输入name, age, job,hobby 然后输出如下所示: ------------ i ...
- linux命令tar压缩解压
tar -c: 建立压缩档案-x:解压-t:查看内容-r:向压缩归档文件末尾追加文件-u:更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个.下面的 ...
- mysql运维
反反复复装了好多次的mysql,上学的时候从来没有考虑过稳定性,装起来,能跑通,增删改查没有问题万事大吉.参与工作后参与平台搭建和维护,平台的稳定性是首先必须要考虑的问题,之前装mysql使用经历了密 ...
- IntelliJ IDEA使用教程 (总目录篇)
注:本文来源于< IntelliJ IDEA使用教程 (总目录篇) > IntelliJ IDEA使用教程 (总目录篇) 硬件要求 IntelliJ IDEA 的硬件要求 安装包云 ...