Kali学习笔记13:操作系统识别
为什么要扫描操作系统呢?
其实和上一篇博客:《服务扫描》类似,都是为了能够发现漏洞
发现什么漏洞?
不同的操作系统、相同操作系统不同版本,都存在着一些可以利用的漏洞
而且,不同的系统会默认开放不同的一些端口和服务
如果能够知道操作系统和版本号,那么就可以利用这些默认选项做一些“事情”
OS的识别技术多种多样,有简单的也有复杂的,最简单的就是用TTL值去识别。
不同类型的OS默认的起始TTL值是不同的。
比如,windows的默认是128,然后每经过一个路由,TTL值减一。
Linux/Unix的值是64,但有些特殊的Unix会是255。
1.利用Python来识别:
- #!/usr/bin/python
- from scapy.all import *
- import logging
- logging.getLogger("scapy.runtime").setLevel(logging.ERROR)
- import sys
- if len(sys.argv) != 2:
- print("Usage --/ttl_os.py [IP Address]")
- print("Example --/ttl_os.py 192.168.0.1")
- print("Example will preform ttl analysis to attempt to determine whether the system is windows or linux/unix")
- sys.exit()
- ip = sys.argv[1]
- ans = sr1(IP(dst=str(ip)) / ICMP(), timeout=1, verbose=0)
- if ans == None:
- print("NO response was returned")
- elif int(ans[IP].ttl) <= 64:
- print("Host is Linux/Unix")
- else:
- print("Host is Windows")
使用场景:
我主机IP:10.14.4.252
Kali机器:192.168.22.130
Metasploitable机器:192.168.22.129
使用脚本:
如果脚本是从windows移过来的:
vi xxx.py
:set fileformat=unix
:wq
chmod u+x xxx.py
./xxx.py
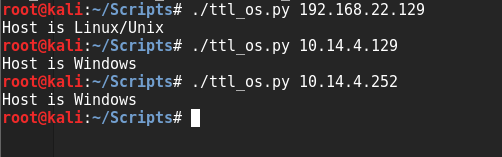
我还多扫描了一个本地的机器,得到的结果都很准确
不过呢,这只是利用TTL简单判断出操作系统
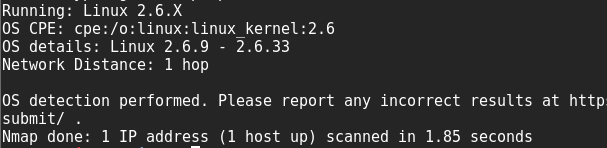
利用Nmap,不仅可以实现这里的功能,甚至还可以得到版本:
-O:参数,识别操作系统

除了强大的工具,还有一些其他的:
xprobe2:直接输入IP地址即可

这个扫描工具相对于Nmap,差距很大,结果不精确
上边的工具都是主动识别操作系统的:主动向目标发送数据包,分析回包
而下边这个工具是被动识别的:
基于网络监听的工作原理:Windows和Linux发送出来的包是有很大区别的。
被动式的扫描可以部署在网络进出口的地方,目的是让所经过的流量通过我的流量分析器。
同样在Kali中也存在这般的工具p0f,他会监听凡是通过本地网卡的流量。
开启:p0f
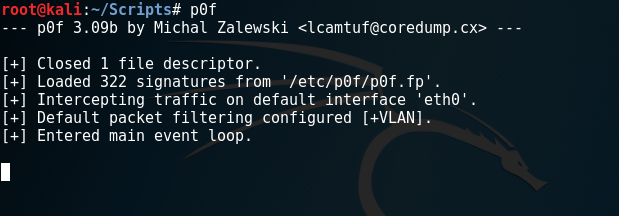
这里是开启了监听,如果什么都不做,他也没有反应
接下来我访问某网站,看看变化:
随意挑出一条信息来看看:
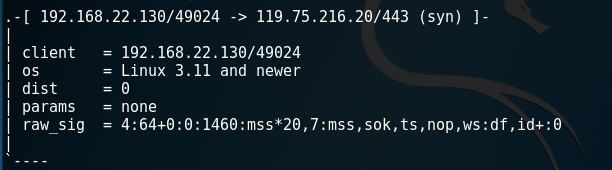
我49024端口向某IP发送了SYN包,这里就得到了我Kali机的版本:3.11或者更高
总之,我推荐Nmap
Kali学习笔记13:操作系统识别的更多相关文章
- Python3+Selenium3+webdriver学习笔记13(js操作应用:弹出框无效如何处理)
#!/usr/bin/env python# -*- coding:utf-8 -*-'''Selenium3+webdriver学习笔记13(js操作应用:弹出框无效如何处理)'''from sel ...
- Ext.Net学习笔记13:Ext.Net GridPanel Sorter用法
Ext.Net学习笔记13:Ext.Net GridPanel Sorter用法 这篇笔记将介绍如何使用Ext.Net GridPanel 中使用Sorter. 默认情况下,Ext.Net GridP ...
- SQL反模式学习笔记13 使用索引
目标:优化性能 改善性能最好的技术就是在数据库中合理地使用索引. 索引也是数据结构,它能使数据库将指定列中的某个值快速定位在相应的行. 反模式:无规划的使用索引 1.不使用索引或索引不足 2.使用了 ...
- 并发编程学习笔记(13)----ConcurrentLinkedQueue(非阻塞队列)和BlockingQueue(阻塞队列)原理
· 在并发编程中,我们有时候会需要使用到线程安全的队列,而在Java中如果我们需要实现队列可以有两种方式,一种是阻塞式队列.另一种是非阻塞式的队列,阻塞式队列采用锁来实现,而非阻塞式队列则是采用cas ...
- MongoDB学习笔记:Python 操作MongoDB
MongoDB学习笔记:Python 操作MongoDB Pymongo 安装 安装pymongopip install pymongoPyMongo是驱动程序,使python程序能够使用Mong ...
- golang学习笔记13 Golang 类型转换整理 go语言string、int、int64、float64、complex 互相转换
golang学习笔记13 Golang 类型转换整理 go语言string.int.int64.float64.complex 互相转换 #string到intint,err:=strconv.Ato ...
- springmvc学习笔记(13)-springmvc注解开发之集合类型參数绑定
springmvc学习笔记(13)-springmvc注解开发之集合类型參数绑定 标签: springmvc springmvc学习笔记13-springmvc注解开发之集合类型參数绑定 数组绑定 需 ...
- Javascript学习笔记二——操作DOM
Javascript学习笔记 DOM操作: 一.GetElementById() ID在HTML是唯一的,getElementById()可以定位唯一的一个DOM节点 二.querySelector( ...
- python 学习笔记 13 -- 经常使用的时间模块之time
Python 没有包括相应日期和时间的内置类型.只是提供了3个相应的模块,能够採用多种表示管理日期和时间值: * time 模块由底层C库提供与时间相关的函数.它包括一些函数用于获取时钟时间和处 ...
随机推荐
- OO前三次作业分析
一,第一次作业分析 度量分析: 第一次的oo作业按照常理来说是不应该有这么多的圈复杂度,但是由于第一次写的时候,完全不了解java的相关知识,按照c语言的方式来写,完全的根据指导书的逻辑,先写好了正确 ...
- 获取当前最顶层的VC
#pragma mark - 获取当前最顶层的ViewController - (UIViewController*)topVC:(UIViewController*)VC { if([VC isK ...
- linux简单安装方法
一.配置静态IP NAT:模式: 修改网卡eth0 vim /etc/sysconfig/network-scripts/ifcfg-eth0 内容如下: DEVICE=eth0 HWADDR=:0C ...
- oracle中的日期函数的使用
TO_DATE格式(以时间:2007-11-02 13:45:25为例) Year: yy two digits 两位年 显示值:07 ...
- OO第9-11作业总结
一. 规格化设计 规格化抽象,即将执行的细节抽象为用户所需求的行为(模块做什么). 主要作用在于提高工程设计中的可维护性,可读性,明确功能,使整个编程任务变得清晰有序以减少程序BUG. 说其发展历 ...
- npm -S -D -g i 有什么区别
npm i module_name -S = > npm install module_name --save 写入到 dependencies 对象 //开发环境能使用,生产环境也能使用or ...
- oracle表空间自增
https://blog.csdn.net/windylfm/article/details/78085669
- Linux 云计算运维之路
搭建中小型网站的架构图 s1-2 Linux 硬件基础 s3-4 linux 基础 文件系统 用户权限 s5-6 Linux 标准输出 系统优化 目录结构 w7 rsync-备份服务器 w8 NFS服 ...
- java策略设计模式
1.概述 策略模式定义了一系列的算法,并将每一个算法封装起来,而且使他们可以相互替换,让算法独立于使用它的客户而独立变化. 其实不要被晦涩难懂的定义所迷惑,策略设计模式实际上就是定义一个接口,只要实现 ...
- Day08 (黑客成长日记) 命名空间和作用域
Day08:命名空间和作用域: 1.命名空间: (1)内置命名空间(python解释器): 就是python解释器一旦启动就可以使用的名字储存在内置命名空间中: eg: len() print() a ...