python Kmeans算法解析
一. 概述
首先需要先介绍一下无监督学习,所谓无监督学习,就是训练样本中的标记信息是位置的,目标是通过对无标记训练样本的学习来揭示数据的内在性质以及规律。通俗得说,就是根据数据的一些内在性质,找出其内在的规律。而这一类算法,应用最为广泛的就是“聚类”。
聚类算法可以对数据进行数据归约,即在尽可能保证数据完整的前提下,减少数据的量级,以便后续处理。也可以对聚类数据结果直接应用或分析。
而Kmeans 算法可以说是聚类算法里面较为基础的一种算法。
二. 从样例开始
我们现在在二维平面上有这样一些点
x y
1.658985 4.285136
-3.453687 3.424321
4.838138 -1.151539
-5.379713 -3.362104
0.972564 2.924086
-3.567919 1.531611
0.450614 -3.302219
-3.487105 -1.724432
2.668759 1.594842
-3.156485 3.191137
3.165506 -3.999838
-2.786837 -3.099354
4.208187 2.984927
-2.123337 2.943366
0.704199 -0.479481
-0.392370 -3.963704
2.831667 1.574018
-0.790153 3.343144
2.943496 -3.357075
...
它在二维平面上的分布大概是这样的:

好,这些点看起来隐约分成4个“簇”,那么我们可以假定它就是要分成4个“簇”。(虽然我们可以“看”出来是要分成4个“簇”,但实际上也可以分成其他个,比如说5个。)这里分成“4个簇“是我们看出来的。而在实际应用中其实应该由机器算得,下面也会有介绍的。
找出4个”簇”之后,就要找出每个“簇”的中心了,我们可以“看出”大概的中心点,但机器不知道啊。那么机器是如何知道的呢?答案是通过向量距离,也叫向量相似性。这个相似性计算有多种方法,比如欧式距离,曼哈顿距离,切比雪夫距离等等。
我们这里使用的是欧式距离,欧式距离其实就是反应空间中两点的直线距离。
知道这些后,我们就可以开始让机器计算出4个“簇”了。
主要做法是这样,先随机生成4个点,假设这4个点就是4个“簇”的中心。计算平面中每个点到4个中心点的距离,平面中每个点选取距离最近的那个中心作为自己的中心。
此时我们就完成第一步,将平面中所有点分成4个”簇“。但是刚刚那几个中心都是随机的,这样分成的4个簇明显不是我们想要的结果。怎么办呢?做法如下:
现在有4个簇,根据每个簇中所有点计算出每个簇的新中心点。这个新中心点就会比上一个旧的中心点更优,因为它更加中心。然后使用新中心点重复第一步的步骤。即再对平面中所有点算距离,然后分发到4个新簇中。不断迭代,直到误差较小。
这就是 Kmeans 算法的过程了。
三. 知识点浅析
3.1 确定“簇”的个数
上面所说的分成 4 个簇,这个 4 其实就是 Kmeans 中的K。要使用 Kmeans 首先就是要选取一个 K 作为聚类个数。而上面的例子其实是我们主观”看“出来的,但多数情况下我们是无法直观”看“出分多少个 K 比较好。那怎么办呢?
我们可以从较低的 K 值开始。使用较简单的 Kmeans 算法的结果(即较少的迭代次数,不求最佳结果,但求最快)。计算每个点到其归属的“簇”的中心点的距离,然后求和,求和结果就是误差值。
然后再增加 K 值,再计算误差值。比如上面的例子,我们可以从 K=2 开始,计算 K 值从 2 到 7 的 Kmeans 算法的误差值。
这样会得到类似这样一张图:
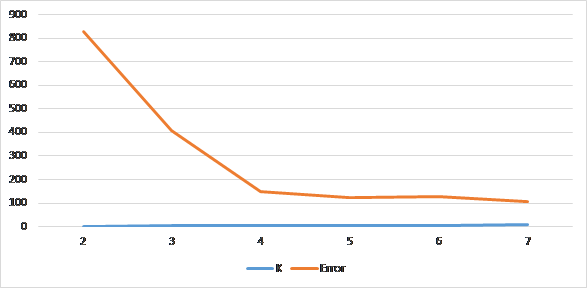
里面的 Error 可以理解未 Kmeans 的误差,而当分成越多“簇”的适合,误差肯定是越来越小。
但是不是“簇”越多越好呢?答案是否定的,有时候“簇”过多的话是不利于我们得到想要的结果或是做下一步操作的。
所以我们通常会选择误差减小速度比较平缓的那个临界点,比如上图中的 4。
可以发现,在分成 4 个簇之后,再增加簇的数量,误差也不会有很大的减少。而取 4 个簇也和我们所看到的相符。
3.2 欧式距离
3.2 欧式距离
欧氏距离是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,计算公式如下:
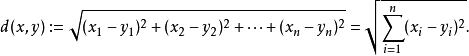
而本例种的是在二维空间种,故而本例的计算公式如下:
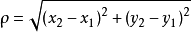
四. 代码和结果
加载数据的代码,使用了 numpy ,先是将代码加载成 matrix 类型。
import numpy as np
def loadDataSet(fileName):
'''
加载数据集
:param fileName:
:return:
'''
# 初始化一个空列表
dataSet = []
# 读取文件
fr = open(fileName)
# 循环遍历文件所有行
for line in fr.readlines():
# 切割每一行的数据
curLine = line.strip().split('\t')
# 将数据转换为浮点类型,便于后面的计算
# fltLine = [float(x) for x in curLine]
# 将数据追加到dataMat
fltLine = list(map(float,curLine)) # 映射所有的元素为 float(浮点数)类型
dataSet.append(fltLine)
# 返回dataMat
return np.matrix(dataSet)
接下来需要生成 K 个初始的质点,即中心点。这里采用随机生成的方法生成 k 个“簇”。
def randCent(dataMat, k):
'''
为给定数据集构建一个包含K个随机质心的集合,
随机质心必须要在整个数据集的边界之内,这可以通过找到数据集每一维的最小和最大值来完成
然后生成0到1.0之间的随机数并通过取值范围和最小值,以便确保随机点在数据的边界之内
:param dataMat:
:param k:
:return:
'''
# 获取样本数与特征值
m, n = np.shape(dataMat)
# 初始化质心,创建(k,n)个以零填充的矩阵
centroids = np.mat(np.zeros((k, n)))
# 循环遍历特征值
for j in range(n):
# 计算每一列的最小值
minJ = min(dataMat[:, j])
# 计算每一列的范围值
rangeJ = float(max(dataMat[:, j]) - minJ)
# 计算每一列的质心,并将值赋给centroids
centroids[:, j] = np.mat(minJ + rangeJ * np.random.rand(k, 1))
# 返回质心
return centroids
欧式距离计算
def distEclud(vecA, vecB):
'''
欧氏距离计算函数
:param vecA:
:param vecB:
:return:
'''
return np.sqrt(sum(np.power(vecA - vecB, 2)))
cost 方法将执行一个简化的 kMeans ,即较少次数的迭代,计算出其中的误差(即当前点到簇质心的距离,后面会使用该误差来评价聚类的效果)
def cost(dataMat, k, distMeas=distEclud, createCent=randCent,iterNum=300):
'''
计算误差的多少,通过这个方法来确定 k 为多少比较合适,这个其实就是一个简化版的 kMeans
:param dataMat: 数据集
:param k: 簇的数目
:param distMeans: 计算距离
:param createCent: 创建初始质心
:param iterNum:默认迭代次数
:return:
'''
# 获取样本数和特征数
m, n = np.shape(dataMat)
# 初始化一个矩阵来存储每个点的簇分配结果
# clusterAssment包含两个列:一列记录簇索引值,第二列存储误差(误差是指当前点到簇质心的距离,后面会使用该误差来评价聚类的效果)
clusterAssment = np.mat(np.zeros((m, 2)))
# 创建质心,随机K个质心
centroids = createCent(dataMat, k)
clusterChanged = True
while iterNum > 0:
clusterChanged = False
# 遍历所有数据找到距离每个点最近的质心,
# 可以通过对每个点遍历所有质心并计算点到每个质心的距离来完成
for i in range(m):
minDist = np.inf
minIndex = -1
for j in range(k):
# 计算数据点到质心的距离
# 计算距离是使用distMeas参数给出的距离公式,默认距离函数是distEclud
distJI = distMeas(centroids[j, :], dataMat[i, :])
# print(distJI)
# 如果距离比minDist(最小距离)还小,更新minDist(最小距离)和最小质心的index(索引)
if distJI < minDist:
minDist = distJI
minIndex = j
# 更新簇分配结果为最小质心的index(索引),minDist(最小距离)的平方
clusterAssment[i, :] = minIndex, minDist ** 2
iterNum -= 1;
# print(centroids)
# 遍历所有质心并更新它们的取值
for cent in range(k):
# 通过数据过滤来获得给定簇的所有点
ptsInClust = dataMat[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# 计算所有点的均值,axis=0表示沿矩阵的列方向进行均值计算
centroids[cent, :] = np.mean(ptsInClust, axis=0)
# 返回给定迭代次数后误差的值
return np.mat(clusterAssment[:,1].sum(0))[0,0]
最后可以调用 Kmeans 算法来进行计算。
def kMeans(dataMat, k, distMeas=distEclud, createCent=randCent):
'''
创建K个质心,然后将每个店分配到最近的质心,再重新计算质心。
这个过程重复数次,直到数据点的簇分配结果不再改变为止
:param dataMat: 数据集
:param k: 簇的数目
:param distMeans: 计算距离
:param createCent: 创建初始质心
:return:
'''
# 获取样本数和特征数
m, n = np.shape(dataMat)
# 初始化一个矩阵来存储每个点的簇分配结果
# clusterAssment包含两个列:一列记录簇索引值,第二列存储误差(误差是指当前点到簇质心的距离,后面会使用该误差来评价聚类的效果)
clusterAssment = np.mat(np.zeros((m, 2)))
# 创建质心,随机K个质心
centroids = createCent(dataMat, k)
# 初始化标志变量,用于判断迭代是否继续,如果True,则继续迭代
clusterChanged = True
while clusterChanged:
clusterChanged = False
# 遍历所有数据找到距离每个点最近的质心,
# 可以通过对每个点遍历所有质心并计算点到每个质心的距离来完成
for i in range(m):
minDist = np.inf
minIndex = -1
for j in range(k):
# 计算数据点到质心的距离
# 计算距离是使用distMeas参数给出的距离公式,默认距离函数是distEclud
distJI = distMeas(centroids[j, :], dataMat[i, :])
# 如果距离比minDist(最小距离)还小,更新minDist(最小距离)和最小质心的index(索引)
if distJI < minDist:
minDist = distJI
minIndex = j
# 如果任一点的簇分配结果发生改变,则更新clusterChanged标志
if clusterAssment[i, 0] != minIndex: clusterChanged = True
# 更新簇分配结果为最小质心的index(索引),minDist(最小距离)的平方
clusterAssment[i, :] = minIndex, minDist ** 2
# print(centroids)
# 遍历所有质心并更新它们的取值
for cent in range(k):
# 通过数据过滤来获得给定簇的所有点
ptsInClust = dataMat[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# 计算所有点的均值,axis=0表示沿矩阵的列方向进行均值计算
centroids[cent, :] = np.mean(ptsInClust, axis=0)
# 返回所有的类质心与点分配结果
return centroids, clusterAssment
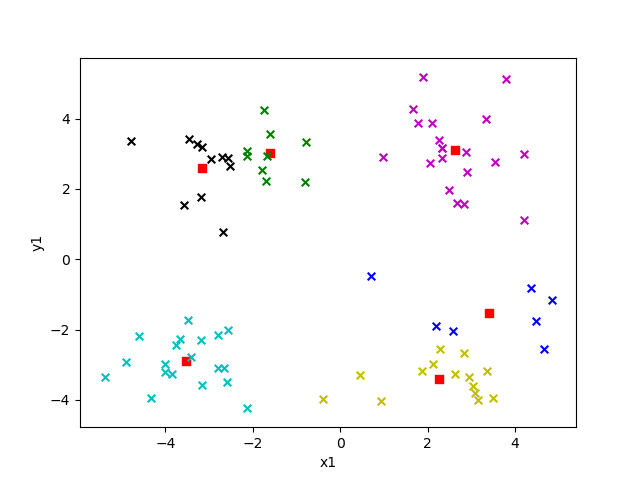
选取不同的 k 值对结果影响有多大呢?我们来看看就知道了,下面给出的是 k 值为 2 到 6 的效果。
图中红色方块即为“簇”的中心点,每个“簇”所属的点用不同的颜色表示。
K = 2
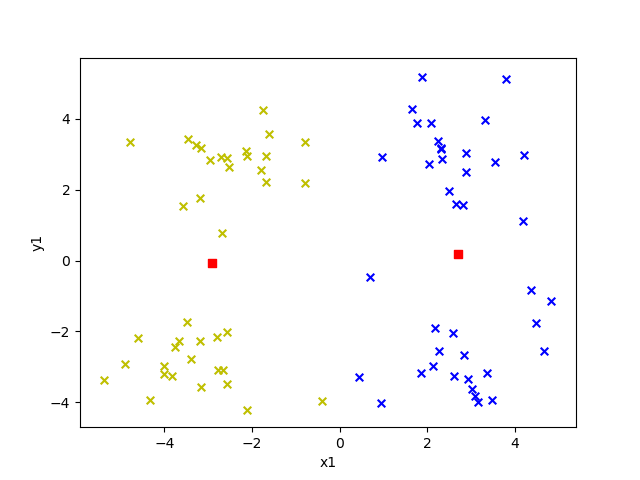
K = 3
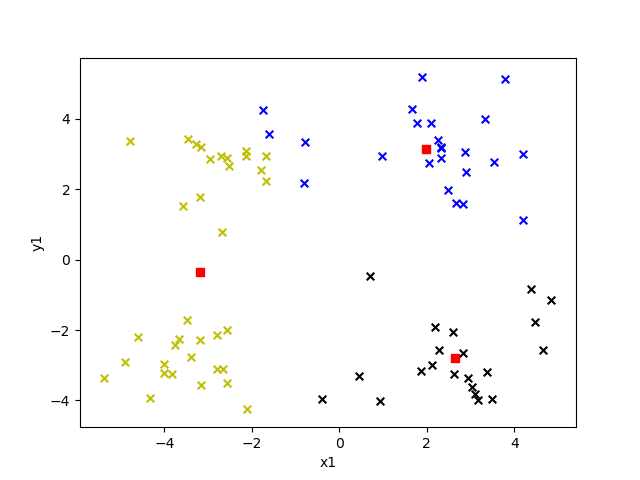
K = 4

K = 5

K = 6
python Kmeans算法解析的更多相关文章
- Python—kmeans算法学习笔记
一. 什么是聚类 聚类简单的说就是要把一个文档集合根据文档的相似性把文档分成若干类,但是究竟分成多少类,这个要取决于文档集合里文档自身的性质.下面这个图就是一个简单的例子,我们可以把不同的文档聚合 ...
- mahout运行测试与kmeans算法解析
在使用mahout之前要安装并启动hadoop集群 将mahout的包上传至linux中并解压即可 mahout下载地址: 点击打开链接 mahout中的算法大致可以分为三大类: 聚类,协同过滤和分类 ...
- mahout运行测试与数据挖掘算法之聚类分析(一)kmeans算法解析
在使用mahout之前要安装并启动hadoop集群 将mahout的包上传至linux中并解压即可 mahout下载地址: 点击打开链接 mahout中的算法大致可以分为三大类: 聚类,协同过滤和分类 ...
- 机器学习中的K-means算法的python实现
<机器学习实战>kMeans算法(K均值聚类算法) 机器学习中有两类的大问题,一个是分类,一个是聚类.分类是根据一些给定的已知类别标号的样本,训练某种学习机器,使它能够对未知类别的样本进行 ...
- python常见排序算法解析
python——常见排序算法解析 算法是程序员的灵魂. 下面的博文是我整理的感觉还不错的算法实现 原理的理解是最重要的,我会常回来看看,并坚持每天刷leetcode 本篇主要实现九(八)大排序算法 ...
- DeepFM算法解析及Python实现
1. DeepFM算法的提出 由于DeepFM算法有效的结合了因子分解机与神经网络在特征学习中的优点:同时提取到低阶组合特征与高阶组合特征,所以越来越被广泛使用. 在DeepFM中,FM算法负责对一阶 ...
- GBDT+LR算法解析及Python实现
1. GBDT + LR 是什么 本质上GBDT+LR是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题.这个方法出自于Facebook 2014年的论文 Practical L ...
- 数据挖掘-聚类分析(Python实现K-Means算法)
概念: 聚类分析(cluster analysis ):是一组将研究对象分为相对同质的群组(clusters)的统计分析技术.聚类分析也叫分类分析,或者数值分类.聚类的输入是一组未被标记的样本,聚类根 ...
- Python之机器学习K-means算法实现
一.前言: 今天在宿舍弄了一个下午的代码,总算还好,把这个东西算是熟悉了,还不算是力竭,只算是知道了怎么回事.今天就给大家分享一下我的代码.代码可以运行,运行的Python环境是Python3.6以上 ...
随机推荐
- Linux编程 20 shell编程(shell脚本创建,echo显示信息)
一概述 前面19章里已经掌握了linux系统和命令行的基础知识,从本章开始继续学习shell脚本的基础知识.在大量编辑shell脚本前,先来学习下一些基本概念. 1.1 使用多个命令 Shell ...
- 解决app安装成功后,直接点击“打开”再按home返回,再次打开app会重新启动的问题
在主activity的onCreate中加入以下代码 @Override protected void onCreate(Bundle savedInstanceState) { super.onCr ...
- form详解
form ** form常用属性 action 指定请求的地址 method 请求方式,如果是post形式发出的,表单的输入值就会放在请求体中,并且会进行编码处理,编码的方式在请求头中的Content ...
- centos 7 linux 安装与卸载 tomcat 7
一.声明 本文采用操作系统版本: Centos 7 Linux系统 版本源:CentOS-7-x86_64-DVD-1708.iso 官网下载地址:http://isoredirect.centos. ...
- centos7编译linux的内核源码
昨天编译了一个linux 内核源码,遇到一些问题, 今天把我遇到的问题和解决方法分享给大家.希望可以帮助到需要的人. 1.检查是否安装了相应的包 我第一次编译的时候只安装的“Development T ...
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- shell的命令替换和命令组合
bash&shell系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html Linux中使用反引号"``"(在波浪线的 ...
- ZooKeeper系列(3):znode说明和znode状态
ZooKeeper系列文章:https://www.cnblogs.com/f-ck-need-u/p/7576137.html#zk 1.znode znode的官方说明:http://zookee ...
- meterpreter持久后门
meterpreter持久后门 背景:meterpreter好是好,但有个大问题,只要目标和本机连接断开一次后就再也连不上了,需要再次用exploit打才行!!! 解决方案:在与目标设备的meterp ...
- Owin Middleware如何在IIS集成管道中执行
Owin Middleware Components(OMCs) 通过安装Install-Package Microsoft.Owin.Host.SystemWeb 可以让OMCs在IIS集成管道下工 ...