python之 MySQLdb 实践 爬一爬号码
0.目录
2.构建URL
3.新建数据库
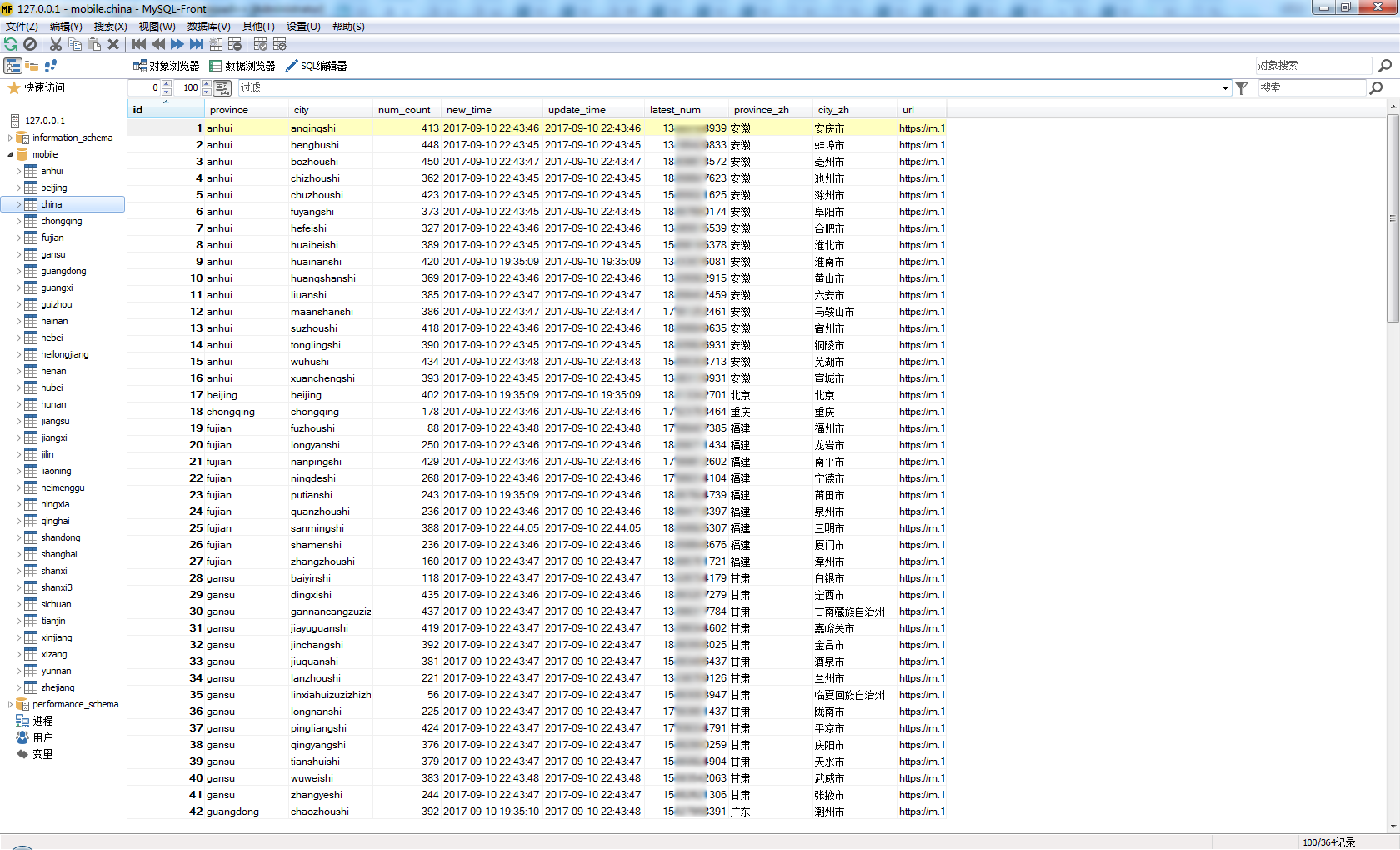
4.新建汇总表
5.定义连接数据库函数:connect_db(db=None, cursorclass=DictCursor)
6.汇总表填充必要数据
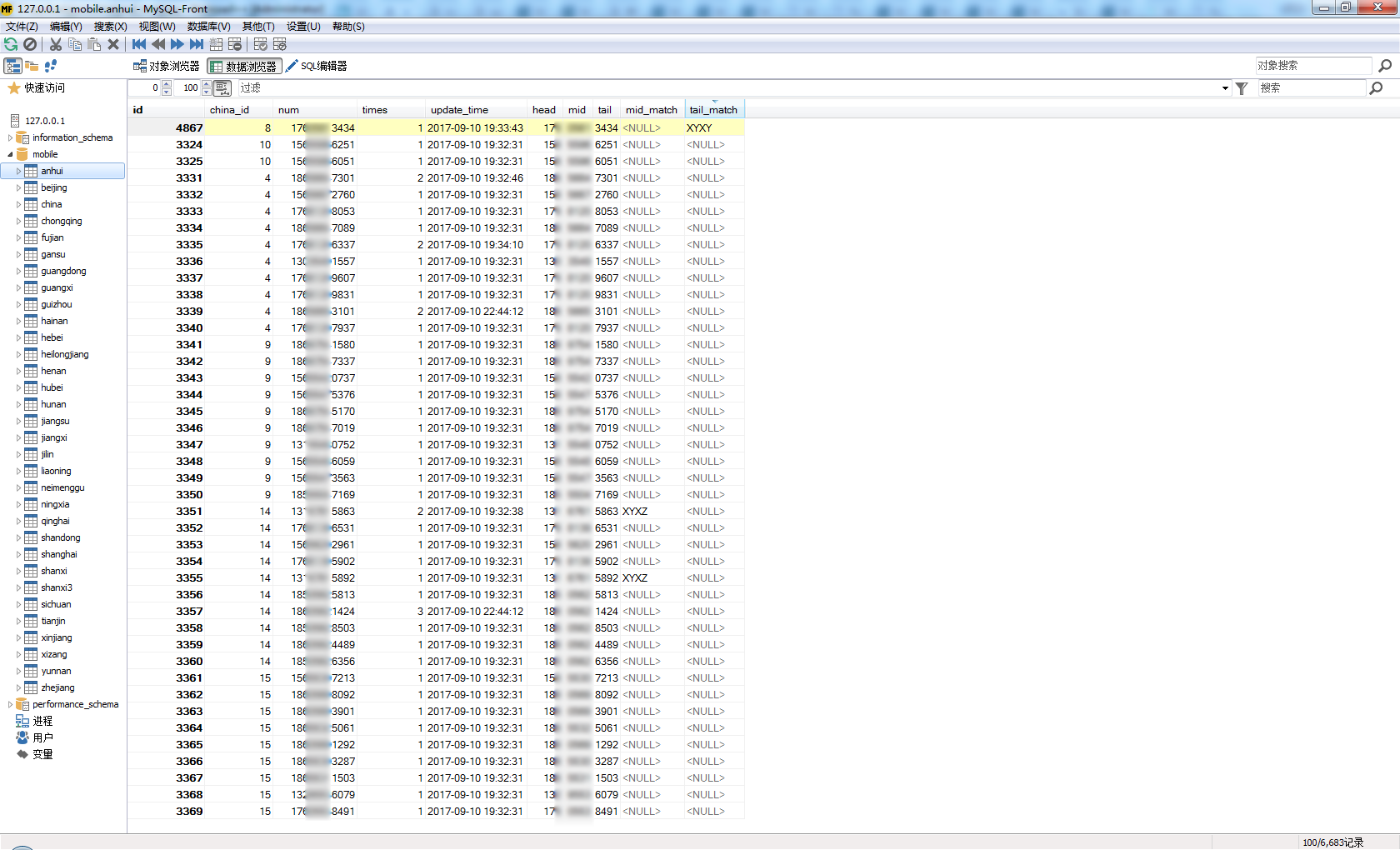
7.新建各省份子表
8.完整代码
1.参考
2.构建URL
3.新建数据库
mysql> CREATE DATABASE mobile
-> CHARACTER SET 'utf8'
-> COLLATE 'utf8_general_ci';
Query OK, 1 row affected (0.00 sec) mysql> use mobile;
Database changed
4.新建汇总表
int(M) M是显示宽度,无需设置。
int 带符号表示范围 [-2147483648,2147483647] ,手机号码11位数字已超。
mysql> use mobile
Database changed
mysql> CREATE TABLE china(
-> id INT NOT NULL auto_increment,
-> province VARCHAR(100) NOT NULL,
-> city VARCHAR(100) NOT NULL,
-> num_count INT NULL,
-> new_time DATETIME NULL,
-> update_time DATETIME NULL,
-> latest_num BIGINT NULL,
-> province_zh VARCHAR(100) NOT NULL,
-> city_zh VARCHAR(100) NOT NULL,
-> url VARCHAR(255) NOT NULL,
->
-> PRIMARY KEY(id)
-> )engine=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.01 sec)
5.定义连接数据库函数:connect_db(db=None, cursorclass=DictCursor)
import MySQLdb
from MySQLdb.cursors import Cursor, DictCursor
def connect_db(db=None, cursorclass=DictCursor):
conn= MySQLdb.connect(
host='127.0.0.1', #'localhost'
port = 3306,
user='root',
passwd='root',
# db ='mobile',
charset='utf8'
)
curs = conn.cursor(cursorclass)
if db is not None:
curs.execute("USE %s"%db)
return conn, curs
conn, curs = connect_db('mobile')
6.汇总表填充必要数据
info数据构成:
In [105]: info = pickle.load(open(''))
In [106]: info[0]
Out[106]:
('18xxxxx3664', #此处隐藏号码细节
u'\u6cb3\u5317',
u'\u79e6\u7687\u5c9b\u5e02',
u'hebei',
u'qinhuangdaoshi',
'https://m.1xxxx.com/xxxxxxxxxx') #此处隐藏url细节
In [107]: info = [dict(province_zh=i[1], city_zh=i[2], province=i[3], city=i[4], url=i[-1]) for i in info]
In [108]: info[0]
Out[108]:
{'city': u'qinhuangdaoshi',
'city_zh': u'\u79e6\u7687\u5c9b\u5e02',
'province': u'hebei',
'province_zh': u'\u6cb3\u5317',
'url': 'https://m.1xxxx.com/xxxxxxxxxx'} #此处隐藏url细节
# python中的排序问题——多属性排序
# https://www.2cto.com/kf/201312/265675.html
In [114]: info = sorted(info, key=lambda x:(x.get('province'), x.get('city')))
插入必要数据:
In [115]: curs.executemany("""
...: INSERT INTO china(province, city, province_zh, city_zh, url)
...: values(%(province)s,%(city)s,%(province_zh)s,%(city_zh)s,%(url)s)""", info)
...: conn.commit()
山西和陕西的拼音相同
mysql> select count(distinct province),count(distinct city),count(distinct province_zh),count(distinct city_zh),count(distinct url) from china;
+--------------------------+----------------------+-----------------------------+-------------------------+---------------------+
| count(distinct province) | count(distinct city) | count(distinct province_zh) | count(distinct city_zh) | count(distinct url) |
+--------------------------+----------------------+-----------------------------+-------------------------+---------------------+
| 30 | 326 | 31 | 331 | 339 |
+--------------------------+----------------------+-----------------------------+-------------------------+---------------------+
1 row in set (0.00 sec)
修正 陕西 为 shanxi3
mysql> set character_set_client = gbk;
Query OK, 0 rows affected (0.00 sec) mysql> set character_set_results = gbk;
Query OK, 0 rows affected (0.00 sec) mysql> UPDATE china
-> SET province = 'shanxi3'
-> WHERE province_zh = '陕西';
Query OK, 10 rows affected (0.01 sec)
Rows matched: 10 Changed: 10 Warnings: 0
如果使用curs 进行 update 操作需要 conn.commit()
In [99]: curs.execute("""
...: UPDATE china
...: SET province = 'shanxi3'
...: WHERE province_zh = '陕西';
...: """)
"\nUPDATE china\nSET province = 'shanxi3'\nWHERE province_zh = '\xe9\x99\x95\xe8\xa5\xbf';\n"
Out[99]: 10L
In [100]: conn.commit()
In [101]: curs.fetchall()
Out[101]: ()
7.新建各省份子表
curs.execute("""
SELECT DISTINCT province
FROM china
""")
table_names = [i.get('province') for i in curs]
# id 字段在这里并不是必要
# UNIQUE 用于后续插入行时对已有号码只更新原记录的部分属性 on duplicate
# FOREIGN KEY 用于同步跟随汇总表
for table_name in table_names:
curs.execute("""
CREATE TABLE %s(
id INT NOT NULL AUTO_INCREMENT,
china_id INT NOT NULL,
num BIGINT NOT NULL,
times INT NULL DEFAULT 1,
update_time datetime NULL,
head INT(3) NULL,
mid INT(4) ZEROFILL NULL,
tail INT(4) ZEROFILL NULL,
mid_match CHAR(4) NULL,
tail_match CHAR(4) NULL,
PRIMARY KEY(id),
UNIQUE KEY(num),
FOREIGN KEY (china_id)
REFERENCES china(id)
ON DELETE CASCADE
ON UPDATE CASCADE
)ENGINE=InnoDB DEFAULT CHARSET=utf8;"""%(table_name))
参看索引 index
mysql> show index from anhui;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| anhui | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| anhui | 0 | num | 1 | num | A | 0 | NULL | NULL | | BTREE | | |
| anhui | 1 | china_id | 1 | china_id | A | 0 | NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
8.完整代码
#!/usr/bin/env python
# -*- coding: UTF-8 -*
import time
import re
import MySQLdb
from MySQLdb.cursors import Cursor, DictCursor
import json
import traceback import threading
lock = threading.Lock()
import Queue
task_queue = Queue.Queue()
result_queue = Queue.Queue() import requests
from requests.exceptions import (ConnectionError, ConnectTimeout, ReadTimeout, SSLError,
ProxyError, RetryError, InvalidSchema)
s = requests.Session()
s.headers.update({'user-agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_5 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Mobile/13G36 MicroMessenger/6.5.12 NetType/4G'})
# 此处隐藏 Referer 细节,也可不用
# s.headers.update({'Referer':'https://servicewechat.com/xxxxxxxxxxx'})
s.verify = False
s.mount('https://', requests.adapters.HTTPAdapter(pool_connections=1000, pool_maxsize=1000)) import copy
sp = copy.deepcopy(s)
proxies = {'http': 'http://127.0.0.1:3128', 'https': 'https://127.0.0.1:3128'}
sp.proxies = proxies from urllib3.exceptions import InsecureRequestWarning
from warnings import filterwarnings
filterwarnings('ignore', category = InsecureRequestWarning) import logging
def get_logger():
logger = logging.getLogger("threading_example")
logger.setLevel(logging.DEBUG) # fh = logging.FileHandler("d:/threading.log")
fh = logging.StreamHandler()
fmt = '%(asctime)s - %(threadName)-10s - %(levelname)s - %(message)s'
formatter = logging.Formatter(fmt)
fh.setFormatter(formatter) logger.addHandler(fh)
return logger logger = get_logger() def connect_db(db=None, cursorclass=DictCursor):
conn= MySQLdb.connect(
host='127.0.0.1', #'localhost'
port = 3306,
user='root',
passwd='root',
# db ='mobile',
charset='utf8'
)
curs = conn.cursor(cursorclass)
if db is not None:
curs.execute("USE %s"%db)
return conn, curs def read_table_china():
dict_conn, dict_curs = connect_db('mobile',DictCursor)
dict_curs.execute("""
SELECT id, province, province_zh, city_zh, url
FROM china
""")
table_china = dict_curs.fetchall()
dict_conn.close() return table_china def add_task():
while True:
if task_queue.qsize() < 1000:
for t in table_china:
task_queue.put(t) #队列里面依旧只有300多个id,重复引用,后续get还是得dict loop = 0
def do_task():
global loop
while True:
task = dict(task_queue.get()) ###########
nums = get_nums(task.get('url'))
if nums is None:
continue task.update(dict(update_time=time.strftime('%y-%m-%d %H:%M:%S'))) # results用于后续更新子表,executemany insert 效率更高
results = []
for num in nums:
result = dict(task) ###########
match_dict = parse_num(num)
result.update(match_dict)
results.append(result) result_queue.put(results)
task_queue.task_done() # 记得加u
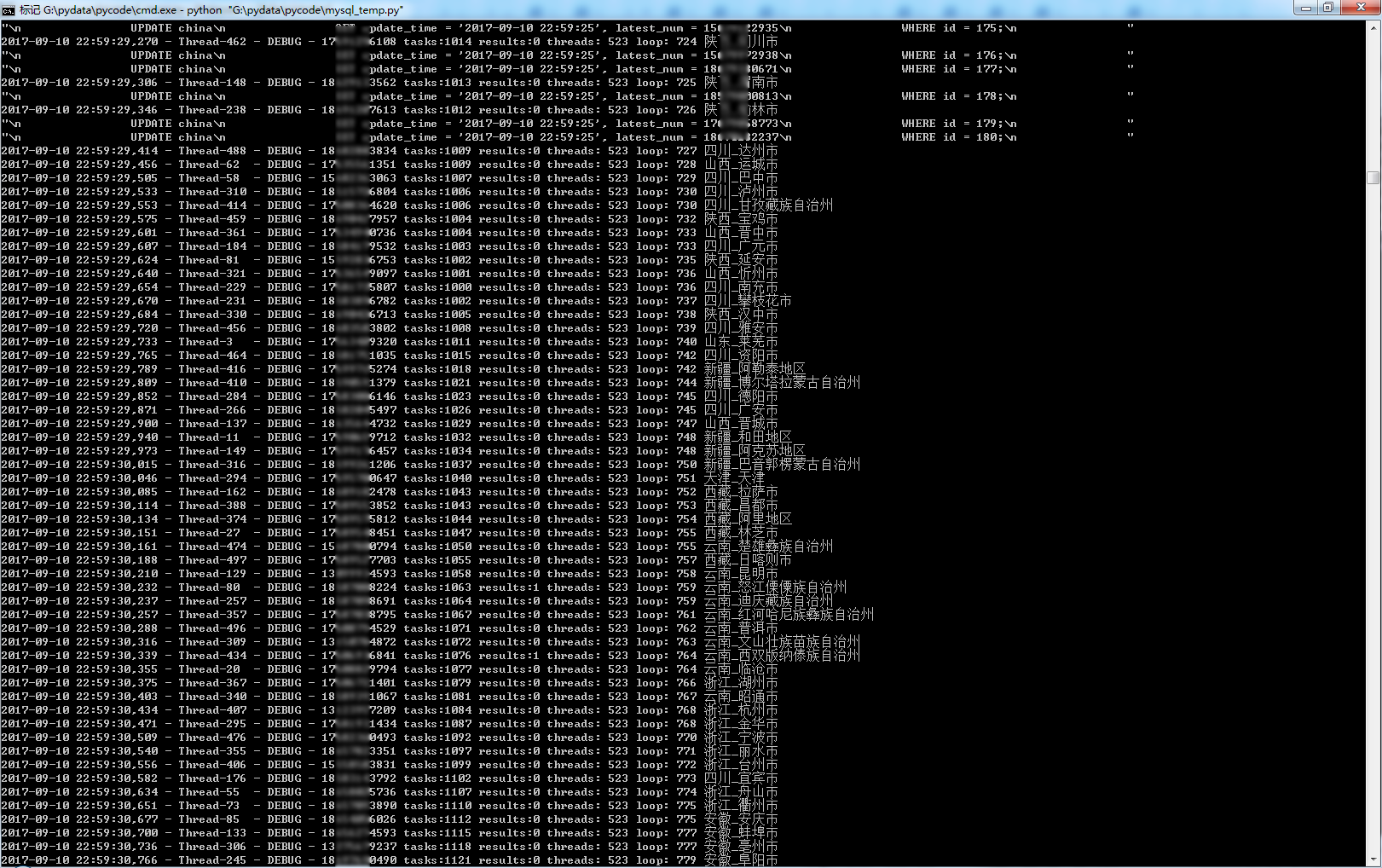
logger.debug(u'{} tasks:{} results:{} threads: {} loop: {} {}_{}'.format(nums[-1], task_queue.qsize(), result_queue.qsize(),
threading.activeCount(), loop,
task.get('province_zh'), task.get('city_zh'))) with lock:
loop += 1 def get_nums(url):
try:
url = url + str(int(time.time()*1000))
resp = sp.get(url)#, timeout=10) #加上超时,网络性能矩形陡降
rst = resp.content # rst = rst[rst.index('{'):rst.index('}')+1]
m = re.search(r'({.*?})', rst)
match = m.group()
rst = json.loads(match)
nums = [num for num in rst['numArray'] if num>10000]
# nums_len = len(nums)
# assert nums_len == 10
assert nums != [] return nums except (ConnectionError, ConnectTimeout, ReadTimeout, SSLError,
ProxyError, RetryError, InvalidSchema) as err:
pass
except (ValueError, AttributeError, IndexError) as err:
pass
except AssertionError as err:
pass
except Exception as err:
print err,traceback.format_exc() # 解析号码特征
def parse_num(num):
# num = 18522223333
num_str = str(num)
head = num_str[:3]
mid = num_str[3:7]
tail = num_str[-4:] match_dict = {'mid_match':mid, 'tail_match':tail}
for k,v in match_dict.items():
part_1, part_2, part_3, part_4 = [int(i) for i in v]
if part_1-part_2==part_2-part_3==part_3-part_4== -1:
match_dict[k] = 'ABCD'
elif part_1-part_2==part_2-part_3==part_3-part_4== 1:
match_dict[k] = 'DCBA'
elif part_1==part_2==part_3==part_4:
match_dict[k] = 'SSSS'
elif part_2==part_3 and (part_1==part_2 or part_3==part_4):
match_dict[k] = '3S'
elif part_1==part_2 and part_3==part_4:
match_dict[k] = 'XXYY'
elif part_1==part_3 and part_2==part_4:
match_dict[k] = 'XYXY'
elif part_1==part_3 and k == 'mid_match':
match_dict[k] = 'XYXZ'
else:
match_dict[k] = None match_dict.update(dict(num=num, head=int(head), mid=int(mid), tail=int(tail))) return match_dict def update_table_province():
conn, curs = connect_db('mobile', Cursor)
while True:
try:
results = result_queue.get() prefix = "insert into %s"%(results[0].get('province'))
# 已经设置 num 字段为unique,如果可能导致重复,则更新 update_time , 同时 times 加1
sql = (prefix+\
"""(china_id, num, update_time, head, mid, tail, mid_match, tail_match)
values(%(id)s, %(num)s, %(update_time)s, %(head)s, %(mid)s, %(tail)s, %(mid_match)s, %(tail_match)s)
ON DUPLICATE KEY UPDATE update_time=values(update_time), times=times+1""")
curs.executemany(sql, results) conn.commit()
result_queue.task_done()
except Exception as err:
# pass
print err,traceback.format_exc()
result_queue.put(results)
try:
conn.close()
except:
pass
conn, curs = connect_db('mobile', Cursor) def update_table_china():
dict_conn, dict_curs = connect_db('mobile', DictCursor)
province_list = set([info.get('province') for info in table_china])
while True:
try:
for province in province_list:
# 先按照id降序,最后获取的新号码靠前
dict_curs.execute("""
SELECT china_id, count(*) AS num_count, update_time AS new_time
FROM (select * from %s order by id desc) AS temp
GROUP BY china_id;
"""%(province)) # dict_curs的复用?
dict_curs.executemany("""
UPDATE china
SET num_count = %(num_count)s, new_time = %(new_time)s
WHERE id = %(china_id)s;
""", dict_curs)
dict_conn.commit() # 先按照更新时间降序
dict_curs.execute("""
SELECT china_id, update_time, num AS latest_num
FROM (select * from %s order by update_time desc) AS temp
GROUP BY china_id;
"""%(province)) dict_curs.executemany("""
UPDATE china
SET update_time = %(update_time)s, latest_num = %(latest_num)s
WHERE id = %(china_id)s;
""", dict_curs)
dict_conn.commit() time.sleep(300)
except Exception as err:
# pass
print err,traceback.format_exc()
try:
dict_conn.close()
except:
pass
dict_conn, dict_curs = connect_db('mobile', DictCursor) if __name__ == '__main__': table_china = read_table_china() threads = [] t = threading.Thread(target=add_task) #args接收元组,至少(a,)
threads.append(t) for i in range(500):
t = threading.Thread(target=do_task)
threads.append(t) for i in range(20):
t = threading.Thread(target=update_table_province)
threads.append(t) t = threading.Thread(target=update_table_china)
threads.append(t) # for t in threads:
# t.setDaemon(True)
# t.start()
# while True:
# pass for t in threads:
t.start()
# for t in threads:
# t.join() while True:
pass
9.运行结果
python之 MySQLdb 实践 爬一爬号码的更多相关文章
- Python爬虫初学(二)—— 爬百度贴吧
Python爬虫初学(二)-- 爬百度贴吧 昨天初步接触了爬虫,实现了爬取网络段子并逐条阅读等功能,详见Python爬虫初学(一). 今天准备对百度贴吧下手了,嘿嘿.依然是跟着这个博客学习的,这次仿照 ...
- python 网络爬虫(一)爬取天涯论坛评论
我是一个大二的学生,也是刚接触python,接触了爬虫感觉爬虫很有趣就爬了爬天涯论坛,中途碰到了很多问题,就想把这些问题分享出来, 都是些简单的问题,希望大佬们以宽容的眼光来看一个小菜鸟
- python反反爬,爬取猫眼评分
python反反爬,爬取猫眼评分.解决网站爬取时,内容类似:$#x12E0;样式,且每次字体文件变化.下载FontCreator . 用FontCreator打开base.woff.查看对应字体关系 ...
- 孤荷凌寒自学python第八十一天学习爬取图片1
孤荷凌寒自学python第八十一天学习爬取图片1 (完整学习过程屏幕记录视频地址在文末) 通过前面十天的学习,我已经基本了解了通过requests模块来与网站服务器进行交互的方法,也知道了Beauti ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- itchat 爬了爬自己的微信通讯录
参考 一件有趣的事: 爬了爬自己的微信朋友 忘记从谁那里看到的了,俺也来试试 首先在annconda prompt里面安装了itchat包 pip install itchat 目前对python这里 ...
- SharePoint如何将使列表不被爬网爬到。
有一个项目,没有对表单进行严格的权限管理,虽然用户在自己的首页只能看到属于的单子,但是在搜索的时候,所有人的单子都能被搜到,所以客户造成了困惑. 那么问题来了,怎么让列表或者文档库不被爬网爬到. 有两 ...
- Redis的Python实践,以及四中常用应用场景详解——学习董伟明老师的《Python Web开发实践》
首先,简单介绍:Redis是一个基于内存的键值对存储系统,常用作数据库.缓存和消息代理. 支持:字符串,字典,列表,集合,有序集合,位图(bitmaps),地理位置,HyperLogLog等多种数据结 ...
随机推荐
- SQL SERVER 常见SQL和函数使用
一.语法 参考原文:https://blog.csdn.net/xushaozhang/article/details/55053037 1.查询插入 (1)SELECT INTO 语句格式: Ora ...
- MySQL--表操作(innodb表字段数据类型、约束条件)、sql_mode操作
一.创建表的完整语法 #[]内的可有可无,即创建表时字段名和类型是必须填写的,宽度与约束条件是可选择填写的.create table 表名(字段名1 类型[(宽度) 约束条件],字段名2 类型[(宽度 ...
- 简单的三级联动demo
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- linux 进程监控软件 supervisor
2017年8月21日 17:51:33 星期一 supervisor python写的, 用来监控进程是否启动, 之前监控进程是否启动, 没有就拉起的shell代码是写在crontab里的, 这个软件 ...
- FreeSWITCH异常原因总结
最经在玩FreeSWITCH的时候,遇到很多的问题,特此总结一下,希望以后不要犯类似的错误了: 1.Client端无法注册,但是FS运行正常? 解决办法:查看防火墙是否关闭./etc/init.d/i ...
- HBase在HDFS上的目录介绍
总所周知,HBase 是天生就是架设在 HDFS 上,在这个分布式文件系统中,HBase 是怎么去构建自己的目录树的呢? 第一,介绍系统级别的目录树. 一.0.94-cdh4.2.1版本 系统级别的一 ...
- LuoGu P2835 刻录光盘
题目传送门 这个题和消息扩散那个题,一模一样啊 除了数据范围小一点,搜索能过之外,没啥区别 但是我写WA了QwQ不知道为什么 和消息扩散的代码fc/diff了半天也没找出来哪不一样 换了输入就过了反正 ...
- Confluence 6 配置校验和识别
校验你的设置 查看你 Confluence 当前使用的设置,请参考 Viewing System Properties 页面中的内容. 识别系统属性 请参考 Recognized System Pro ...
- Confluence 6 重新获得站点备份文件
Confluence 将会创建备份,同时压缩 XML 文件后存储熬你的 <home-directory>/backups> 目录中.你需要自己访问你安装的 Confluence 服务 ...
- Confluence 6 H2 数据库连接与合并整合
使用 H2 console 连接到你嵌入的 H2 数据库 可以选的,你可以使用 H2 console 来连接到你的 H2 数据库.最简单的访问 Console 的方法是双击 H2 数据库的 jar 文 ...