Index Condition Pushdown Optimization
Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from a table using an index(ICP是MySQL用索引从表中获取数据的一种优化). Without ICP, the storage engine traverses the index to locate rows in the base table and returns them to the MySQL server which evaluates the WHERE condition for the rows(如果没有ICP,存储引擎层将会穿过索引从基表里面定位行,并把结果返回给server层,MySQL server层将会根据where条件判断哪些结果合格并返回给客户端). With ICP enabled, and if parts of the WHERE condition can be evaluated by using only fields from the index, the MySQL server pushes this part of the WHERE condition down to the storage engine(如果用了ICP,如果能根据索引里的字段获取符合where条件,server层就会把where条件下推到存储引擎层). The storage engine then evaluates the pushed index condition by using the index entry and only if this is satisfied is the row read from the table(然后存储引擎层). ICP can reduce the number of times the storage engine must access the base table and the number of times the MySQL server must access the storage engine(ICP可以减少存储引擎层必须访问基表的次数和server层必须访问存储引擎层的次数).
Index Condition Pushdown optimization is used for the range, ref, eq_ref, and ref_or_null access methods when there is a need to access full table rows(ICP是为需要使用range,ref,eq_ref和ref_or_null方法访问全表数据优化的).另外MariaDB也针对索引下推做了一个优化,Batched Key Access.
This strategy can be used for InnoDB and MyISAM tables. (Note that index condition pushdown is not supported with partitioned tables in MySQL 5.6; this issue is resolved in MySQL 5.7.) For InnoDB tables, however, ICP is used only for secondary indexes(然而对于innodb表,ICP只适用于二级索引). The goal of ICP is to reduce the number of full-record reads and thereby reduce IO operations(ICP的目标是减少全表扫描的次数和减少IO操作). For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce IO(对于InnoDB的聚簇索引,所有的记录都已经在buffer pool里面了,所以使用ICP在这种情况下并没有减少IO).
The idea is to check part of the WHERE condition that refers to index fields (we call it Pushed Index Condition) as soon as we've accessed the index. If the Pushed Index Condition is not satisfied, we won't need to read the whole table record我认为是作者的笔误(概括来说,索引下推总的思想是当我们访问索引的时候,检查索引里的字段是否有满足where条件的,我们叫下推索引条件。如果下推索引条件满足,我们没必要访问全表记录).
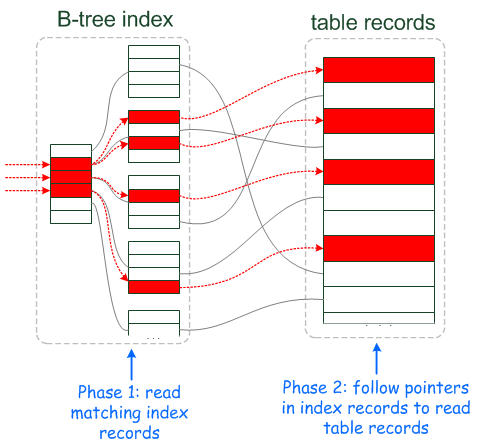
To see how this optimization works, consider first how an index scan proceeds when Index Condition Pushdown is not used:
Get the next row, first by reading the index tuple, and then by using the index tuple to locate and read the full table row.
Test the part of the
WHEREcondition that applies to this table. Accept or reject the row based on the test result.
用一张图表示更容易理解一点:
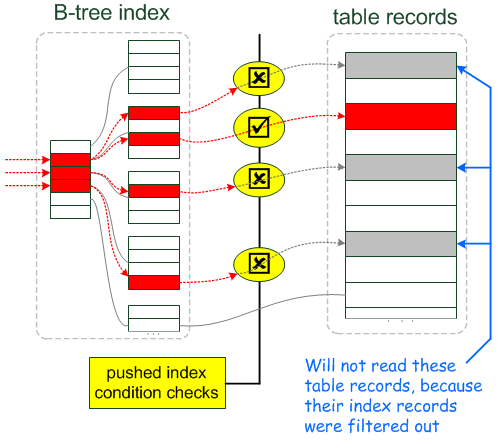
When Index Condition Pushdown is used, the scan proceeds like this instead:
Get the next row's index tuple (but not the full table row).
Test the part of the
WHEREcondition that applies to this table and can be checked using only index columns. If the condition is not satisfied, proceed to the index tuple for the next row.If the condition is satisfied, use the index tuple to locate and read the full table row.
Test the remaining part of the
WHEREcondition that applies to this table. Accept or reject the row based on the test result.
用一张图说明:
Index Condition Pushdown is enabled by default; it can be controlled with the optimizer_switch system variable by setting the index_condition_pushdown flag. See Section 8.9.2, “Controlling Switchable Optimizations”.
索引下推默认打开的.如果使用了索引下推你就会在执行计划中看到"Using index condition"字样,如:
Mysql [test]> explain select * from tbl where key_col1 between 10 and 11 and key_col2 like '%foo%';
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| 1 | SIMPLE | tbl | range | key_col1 | key_col1 | 5 | NULL | 2 | Using index condition |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
1 row in set (0.01 sec)
那么它能带来多少性能提升呢?
答案是取决于它能过滤掉的记录数和要获取结果集的成本。前者取决于语句和结果集,后者取决于表的记录数,在什么样的硬盘上和表中是否有大字段(如:blob)。
来看个例子:
alter table lineitem add index s_r (l_shipdate, l_receiptdate);
select count(*) from lineitemwhere
l_shipdate between '1993-01-01' and '1993-02-01' and
datediff(l_receiptdate,l_shipdate) > 25 and
l_quantity > 40;
没有下推索引条件-+----------+-------+----------------------+-----+---------+------+--------+-------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra |-+----------+-------+----------------------+-----+---------+------+--------+-------------+ | lineitem | range | s_r | s_r | 4 | NULL | 152064 | Using where |-+----------+-------+----------------------+-----+---------+------+--------+-------------+使用了下推索引-+-----------+-------+---------------+-----+---------+------+--------+------------------------------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra |-+-----------+-------+---------------+-----+---------+------+--------+------------------------------------+ | lineitem | range | s_r | s_r | 4 | NULL | 152064 | Using index condition; Using where |-+-----------+-------+---------------+-----+---------+------+--------+------------------------------------+速度上的提升呢?
冷buffer pool:从 5 min 下降到 1 min
热buffer pool:从0.19 sec 下降到 0.07 sec
在MariaDB中有两个变量来查看使用下推索引的状态:
Status variables
There are two server status variables:
| Variable name | Meaning |
|---|---|
| Handler_icp_attempts | Number of times pushed index condition was checked. |
| Handler_icp_match | Number of times the condition was matched. |
That way, the value Handler_icp_attempts - Handler_icp_match shows the number records that the server did not have to read because of Index Condition Pushdown.
如果用的不是MariaDB,我们怎么知道索引下推带来了多少优化呢?我们可以使用这个参数Handler_read_next来看,
参考手册:
http://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
https://mariadb.com/kb/en/mariadb/index-condition-pushdown/
Index Condition Pushdown Optimization的更多相关文章
- MySQL 优化之 ICP (index condition pushdown:索引条件下推)
ICP技术是在MySQL5.6中引入的一种索引优化技术.它能减少在使用 二级索引 过滤where条件时的回表次数 和 减少MySQL server层和引擎层的交互次数.在索引组织表中,使用二级索引进行 ...
- MySQL索引与Index Condition Pushdown(二)
实验 先从一个简单的实验开始直观认识ICP的作用. 安装数据库 首先需要安装一个支持ICP的MariaDB或MySQL数据库.我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版 ...
- 【mysql】关于Index Condition Pushdown特性
ICP简介 Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from ...
- 8.2.1.5 Engine Condition Pushdown Optimization 引擎条件下推优化
8.2.1.5 Engine Condition Pushdown Optimization 引擎条件下推优化 这种优化改善了直接比较在一个非索引列和一个常量比较的效率. 在这种情况下, 条件是 下推 ...
- MySQL索引与Index Condition Pushdown
实际上,这个页面所讲述的是在MariaDB 5.3.3(MySQL是在5.6)开始引入的一种叫做Index Condition Pushdown(以下简称ICP)的查询优化方式.由于本身不是一个层面的 ...
- 1229【MySQL】性能优化之 Index Condition Pushdown
转自http://blog.itpub.net/22664653/viewspace-1210844/ [MySQL]性能优化之 Index Condition Pushdown2014-07-06 ...
- 浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
本文出处:http://www.cnblogs.com/wy123/p/7374078.html(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误 ...
- MySQL 5.6新特性 -- Index Condition Pushdown
Index Condition Pushdown(ICP)是针对mysql使用索引从表中检索行数据时的一种优化方法. 在没有ICP特性之前,存储引擎根据索引去基表查找并将数据返回给mysql se ...
- MySQL 5.6 Index Condition Pushdown
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作.ICP的思想是:存储引擎在访问索引的时候 ...
随机推荐
- iOS发送短信
iPhone开发,发送短信的方法: iPhone开发中,发送短信方法有二: 1.URL Scheme,这样不可以设置短信内容 1 2 3 [[UIApplication sharedApplicati ...
- Failed to load PDF in chrome/Firefox/IE
笔者的公司搭建了一个Nexus服务器,用来管理我们自己的项目Release构件和Site文档. 今天的问题是当用户访问一个Site里的PDF文件的时候,报错说“detected that the ne ...
- npy in c
https://jcastellssala.com/2014/02/01/npy-in-c/
- 微信小店 API 手册
微信商铺API手册V1.13 目录 1. 商品管理接口.................................................................... ...
- django忘记管理员账号和密码处理
1.忘记密码: >>> from django.contrib.auth.models import User >>> user = User.object.get ...
- C语言下WebService的使用方式
用gSoap工具: 1.在dos环境中到gSoap工具对应的目录gsoap_2.8.18\gsoap-2.8\gsoap\bin\win32路径下,执行wsdl2h -c -o *.h ht ...
- MongoDB安装、管理工具、操作
1. mongoDB安装.启动.关闭 1.1 下载安装包 wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.3.tgz 1.2 ...
- nsstring字符串重组
// // main.m // 05-字符串重组 // // Created by apple on 14-3-20. // Copyright (c) 2014年 apple. All ri ...
- Swagger简介
前言 Swagger 是一款RESTFUL接口的文档在线自动生成+功能测试功能软件.本文简单介绍了在项目中集成swagger的方法和一些常见问题.如果想深入分析项目源码,了解更多内容,见参考资料. S ...
- SWING
第一个图形界面应用程序.图形用户界面简称GUI(Graphical User Interface),通过GUI用户可以更好地与计算机进行交互.Swing简介Swing工具包提供了一系列丰富的GUI 组 ...