Spark随机深林扩展—OOB错误评估和变量权重
本文目的
当前spark(1.3版)随机森林实现,没有包括OOB错误评估和变量权重计算。而这两个功能在实际工作中比较常用。OOB错误评估可以代替交叉检验,评估模型整体结果,避免交叉检验带来的计算开销。现在的数据集,变量动辄成百上千,变量权重有助于变量过滤,去掉无用变量,提高计算效率,同时也可以帮助理解业务。所以,本人在原始代码基础上,扩展了这两个功能,下面记录实现过程,作为备忘录(参考代码)。
整体思路
Random Forest实现中,大多数内部对象是私有(private[tree])的,所以扩展代码使用了org.apache.spark.mllib.tree的命名空间,复用这些内部对象。实现过程中,需要放回抽样数据,Random Forest的原始实现是放在局部变量baggedInput中,外部无法访问,所以扩展代码必须冗余部分原始代码,用于访问baggedInput变量。原始实现中,会先将LabeledPoint转成装箱对象TreePoint,但是在计算OOB时,需要LabeledPoint,所以需要实现TreePoint到LabeledPoint的转换逻辑。对于连续变量,取每个箱的中间值作为反转后的结果;离散变量不需要做修改。当然为什么取中间值,为什么取三分之一或其他什么地方?因为在装箱过程中,数据的分布信息已丢失,所以取0.5是一个可以接受的选择。
OOB错误评估
原理
OOB是Out-Of-Bag的缩写,顾名思义,使用那些out of bag的数据进行错误度量。随机森林在训练开始时,会根据树的数量n,进行n次有放回采样,用于训练每一棵树。放回采样,必然导致一部分数据被选中,另外一部分数据没有选中,选中了就放到bag中,没有选中的就是out of bag。平均而言,每次放回采用中,37%的数据不会被选中,详细推导见附录【Out Of Bag概率】。这些没有选中的数据不参与建模,所以可以作为验证数据,评估模型效果。对于每一条记录,若参与了m棵树的建模,则n-m树没有参与建模,那么就可以将这剩下的n-m棵树作为子森林,进行分类验证,列子如下:
|
Tree 1 |
Tree 2 |
Tree 3 |
Tree 4 |
Tree 5 |
Tree 6 |
Tree 7 |
|
|
Data 1 |
* |
* |
* |
||||
|
Data 2 |
* |
* |
* |
* |
|||
|
Data 3 |
* |
* |
* |
||||
|
Data 4 |
* |
* |
* |
* |
|||
|
Data 5 |
* |
* |
* |
上面的表格中,每行表示一个记录,每列表示一颗树,"*"表示该记录参与了某棵树的建模。对于Data 1,参与了Tree 2,4,6的建模过程,那么可选取Tree 3,5,7作为子随机森林模型,并计算Data 1的分类结果。
实现
上面提到了OOB的原理和评估方法,下面介绍如何实现,
|
private def computeOobError( strategy: Strategy, baggedInput: RDD[BaggedPoint[TreePoint]], bins: EnhancedRandomForest.BinList, forest: RandomForestModel): Double = { val actualPredictPair = baggedInput .map(x => { val labeledPoint = EnhancedTreePoint.treePointToLabeledPoint( x.datum, bins, strategy) (x.subsampleWeights.zipWithIndex.filter(_._1 == 0) .map(_._2).map(index => forest.trees(index)), labeledPoint) }) .filter(_._1.size > 0) // 过滤掉无树的森林 .map({ case (oobTrees, labeledPoint) => { val subForest = new RandomForestModel(strategy.algo, oobTrees) (labeledPoint.label, subForest.predict(labeledPoint.features)) } }) val totalCount = actualPredictPair.count assert(totalCount > 0, s"OOB error measure: data number is zeror") strategy.algo match { case Regression => actualPredictPair.map(x => Math.pow(x._1 - x._2, 2)).reduce(_ + _) / totalCount case Classification => actualPredictPair.filter(x => x._1 != x._2).count.toDouble / totalCount } } |
上面函数截取了oob实现的主逻辑,baggedInput是一个特殊的数据结构,用于记录每一条记录选中的信息。比如需要建立10棵树,那么bagged有10列,每一列记录了在当前这棵树,该记录被选中了几次。所以,使用0标示那些没有选中的记录。得到了那些当前数据没有参与建模的树后,构建字随机森林模型并预测结果,最后通过真实数据与预测数据,计算OOB错误评估。对于回归问题,使用平方错误;分类问题,使用错误率。当然,错误的评估方式,后面还可以扩展。
变量重要性
原理
如何描述变量重要性,一种直观的理解是变量越重要,如果混淆它,那么模型效果会越差。混淆处理有几种方案,比如根据某种随机分布,加减随机值,或者随机填充值。但是需要额外的参数,并且会影响原有的数据分布。所以,采取随机排序混淆变量,这样不会改变原始的数据分布,也不需要而外的参数。
具体做法是如下:
- 计算整体OOB(D)
- 选取变量i,随机排序,计算OOB(Di)
- 针对所有变脸,重复步骤2,
- 重要性I(i) = OOB(Di)-OOB(D)
I(i)越高,说明变量i越重要;如果I(i) = 0,那么说明变量i没有什么作用;如果I(i) < 0,那么说明变量i有很明显的噪音,对模型产生了负面影响。
实现
实现的难点是随机排序,在大规模分布式数据上,实现随机排序至少需要一次排序,会非常消耗计算资源。扩展代码中使用了一个小技巧,利用spark随机森林的内部结构TreePoint,避免排序,提高随机排序效率。因为TreePoint是装箱数据,每个变量的值是箱索引,一般不超过100个。所以只需要将箱索引进行随机排序,就可以达到对整个数据进行随机排序的目的。
|
private def computeVariableImportance( strategy: Strategy, baggedInput: RDD[BaggedPoint[TreePoint]], bins: EnhancedRandomForest.BinList, forest: RandomForestModel, oobError: Double): Array[Double] = { (0 until bins.size).par.map(featureIndex => { val binCount = if (strategy.categoricalFeaturesInfo.contains(featureIndex)) { // category feature strategy.categoricalFeaturesInfo(featureIndex) } else { // continuous feature bins(featureIndex).size } val shuffleBinFeature = Random.shuffle((0 until binCount).toList) // 每个元素对应shuffle后的数据 val shuffleOneFeatureBaggedInput = baggedInput.map(x => { val currentFeatureBinIndex = x.datum.binnedFeatures(featureIndex) x.datum.binnedFeatures(featureIndex) = shuffleBinFeature(currentFeatureBinIndex) x }) computeOobError(strategy, shuffleOneFeatureBaggedInput, bins, forest) - oobError }).toArray } |
上面的使用中,使用list.par.map的并发操作,同时对所有的变量计算重要性,具体的调度有spark服务器控制,最大限度利用spark的资源。
聚合模型稳定的理论依据
随机森林背后的主要思想是聚合模型(Ensemble Model)。为什么聚合模型效果好于单一模型(理论推导,请参考附录【聚合模型错误评估】)?直观的理解,当很多模型进行投票时,有一些模型会犯错,另外一些模型正确,那么正确的投票会与错误的投票抵消,整体上只要最终正确的投票多于错误的投票,哪怕多一票,那么就会得到正确的结果。由于相互抵消,所以聚合效果比单一模型稳定。聚合模型中,需要模型间具有较大差异,这样才能覆盖数据的不同方面,这也是为什么随机森林在数据的行和列两个维度上,添加随机过程,用于增大模型之间的差异。
引用一句谚语,"三个臭皮匠,顶一个诸葛亮",可以形象的解释。比如这里有101个臭皮匠,假设他们对一件事情的判断正确的概率是0.57,而诸葛亮对这件事情判断正确的概率是0.9。那么,假设这101个臭皮匠通过投票判断,那么概率可以达到0.92(R代码:sum(dbinom(51:101,101,0.57))),比诸葛亮强!
总结
通过扩展这两个功能,重新温习了台大《机器学习技法》相关课程,同时在真实数据上检验了Random Forest的模型效果。实践检验了整理,学以致用,感觉很满足。同时,在阅读org.apache.spark.mllib.tree源代码的时候,学习到了一些分布式数据集上算法实现的技巧。希望这些分享对你有用。
参考资料
附录
Out Of Bag概率
设N为样本大小,那么N次有放回抽样中,一次没有选中的概率可以表示如下,
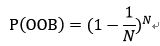
当N趋近于无求大时,P(OOB)会收敛到常量,下面给出证明,

其中数学常数定义如下:
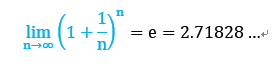
聚合模型错误评估
下面通过聚合回归模型进行简单推导,gt是相同数据集D中,使用T个算法生成的T个模型中随机选择的一个模型,G是这T个模型聚合,使用平均作为最终结果,有
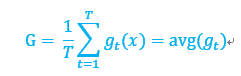
f模型用于生成数据D,需要用T个机器学习算法逼近。现在期望研究(G(x)-f(x))2与avg((gt(x)-f(x))2)的关系。x是固定值,后面的公式为了简单,会省略。
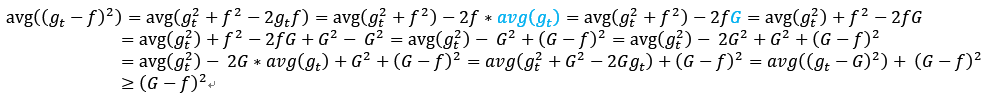
直观的理解,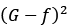 是偏差(Bias),
是偏差(Bias),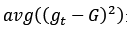 是方差(Variance),任意单一模型的平方错误期望大于等于平均模型的错误的平方。而且,模型差异如果越大,那么方差variance越大,那么Bias越小,也就是聚合模型与f越接近。
是方差(Variance),任意单一模型的平方错误期望大于等于平均模型的错误的平方。而且,模型差异如果越大,那么方差variance越大,那么Bias越小,也就是聚合模型与f越接近。
Spark随机深林扩展—OOB错误评估和变量权重的更多相关文章
- Spark随机森林实现学习
前言 最近阅读了spark mllib(版本:spark 1.3)中Random Forest的实现,发现在分布式的数据结构上实现迭代算法时,有些地方与单机环境不一样.单机上一些直观的操作(递归),在 ...
- 随机森林之oob error 估计
摘要:在随机森林之Bagging法中可以发现Bootstrap每次约有1/3的样本不会出现在Bootstrap所采集的样本集合中,当然也就没有参加决策树的建立,那是不是意味着就没有用了呢,答案是否定的 ...
- Spark Streaming揭秘 Day9 从Receiver的设计到Spark框架的扩展
Spark Streaming揭秘 Day9 从Receiver的设计到Spark框架的扩展 Receiver是SparkStreaming的输入数据来源,从对Receiver整个生命周期的设计,我们 ...
- Spark RDD API扩展开发
原文链接: Spark RDD API扩展开发(1) Spark RDD API扩展开发(2):自定义RDD 我们都知道,Apache Spark内置了很多操作数据的API.但是很多时候,当我们在现实 ...
- sql server常有的问题-实时错误'91' 对象变量或with块变量未设置
这样的问题,对于我们这样的初学者来说,无疑是一个接触sql server后第一个艰难的问题,“实时错误'91' 对象变量或with块变量未设置”这句话到底透露出什么信息?直至写此博文,我依然看不出什么 ...
- 理解dropout——本质是通过阻止特征检测器的共同作用来防止过拟合 Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
理解dropout from:http://blog.csdn.net/stdcoutzyx/article/details/49022443 http://www.cnblogs.com/torna ...
- 随机森林之oob的计算过程
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计.它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计. 随机森林在生成每颗决策 ...
- Spark随机森林实战
package big.data.analyse.ml.randomforest import org.apache.spark.ml.Pipeline import org.apache.spark ...
- 随机深林和GBDT
随机森林(Random Forest): 随机森林是一个最近比较火的算法,它有很多的优点: 在数据集上表现良好 在当前的很多数据集上,相对其他算法有着很大的优势 它能够处理很高维度(feature很多 ...
随机推荐
- Unity5的AssetBundle的一点使用心得
昨天一位朋友在我这里留言,想让我写点Unity5的AssetBundle心得.于是我就看了相关的介绍,和自己确切的做了一次.下面来谈谈所谓的心得. 如果你觉得自己对AssetBundle不熟悉,建议先 ...
- HDU 5024 Wang Xifeng's Little Plot (DP)
题意:给定一个n*m的矩阵,#表示不能走,.表示能走,让你求出最长的一条路,并且最多拐弯一次且为90度. 析:DP,dp[i][j][k][d] 表示当前在(i, j)位置,第 k 个方向,转了 d ...
- Lvs之NAT、DR、TUN三种模式的应用配置案例
LVS 一.LVS简介 LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟服务器集群系统.本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的 ...
- 斯坦福第十六课:推荐系统(Recommender Systems)
16.1 问题形式化 16.2 基于内容的推荐系统 16.3 协同过滤 16.4 协同过滤算法 16.5 矢量化:低秩矩阵分解 16.6 推行工作上的细节:均值归一化 16.1 问题形式 ...
- iOS设置UISearchBar光标的颜色
[[UISearchBar appearance] setTintColor:[UIColor blackColor]];
- 第44讲:Scala中View Bounds代码实战及其在Spark中的应用源码解析
今天学习了view bounds的内容,来看下面的代码. //class Pair[T <: Comparable[T]](val first : T,val second : T){// d ...
- h5自动生成工具
一.前言 写了很多h5之后,对于写手写html和css已经麻木的我决定动手写个工具自动生成h5结构和样式.其实这个想法由来已久,但总是觉得自己技术不够,所以一直没实行.直到某天我真的写够了,我决定动手 ...
- SQL 注入
我们的团队项目中有课程名称输入框,其中的内容会拼接到类sql查询语句中. 所以可能会产生类sql注入的问题,我们团队采用了利用正则表达式判断输入内容的形式来规避这类注入. 下面简单介绍一下sql注入 ...
- 备份MYSQL出现:mysqldump: Got error: 1049: Unknown database 'test 'when selecting the data
解决办法 后面不要加分号: 如: mysqldump -uroot -p test>test.sql 不加分号 直接回车
- atitit.android模拟器使用报告
atitit.android模拟器使用报告 靠谱助手 仅仅7--15M,只助手,没android模拟器.. BlueStacks新版本App Player采用名为Layercake的技术,可以让针对A ...