在opencv3中的机器学习算法练习:对OCR进行分类
OCR (Optical Character Recognition,光学字符识别),我们这个练习就是对OCR英文字母进行识别。得到一张OCR图片后,提取出字符相关的ROI图像,并且大小归一化,整个图像的像素值序列可以直接作为特征。但直接将整个图像作为特征数据维度太高,计算量太大,所以也可以进行一些降维处理,减少输入的数据量。
处理过程一般这样:先对原图像进行裁剪,得到字符的ROI图像,二值化。然后将图像分块,统计每个小块中非0像素的个数,这样就形成了一个较小的矩阵,这矩阵就是新的特征了。opencv为我们提供了一些这样的数据,放在
\opencv\sources\samples\data\letter-recognition.data
这个文件里,打开看看:

每一行代表一个样本。第一列大写的字母,就是标注,随后的16列就是该字母的特征向量。这个文件中总共有20000行样本,共分类26类(26个字母)。
我们将这些数据读取出来后,分成两部分,第一部分16000个样本作为训练样本,训练出分类器后,对这16000个训练数据和余下的4000个数据分别进行测试,得到训练精度和测试精度。其中adaboost比较特殊一点,训练和测试样本各为10000.
完整代码为:
- #include "stdafx.h"
- #include "opencv2\opencv.hpp"
- #include <iostream>
- using namespace std;
- using namespace cv;
- using namespace cv::ml;
- // 读取文件数据
- bool read_num_class_data(const string& filename, int var_count,Mat* _data, Mat* _responses)
- {
- const int M = ;
- char buf[M + ];
- Mat el_ptr(, var_count, CV_32F);
- int i;
- vector<int> responses;
- _data->release();
- _responses->release();
- FILE *f;
- fopen_s(&f, filename.c_str(), "rt");
- if (!f)
- {
- cout << "Could not read the database " << filename << endl;
- return false;
- }
- for (;;)
- {
- char* ptr;
- if (!fgets(buf, M, f) || !strchr(buf, ','))
- break;
- responses.push_back((int)buf[]);
- ptr = buf + ;
- for (i = ; i < var_count; i++)
- {
- int n = ;
- sscanf_s(ptr, "%f%n", &el_ptr.at<float>(i), &n);
- ptr += n + ;
- }
- if (i < var_count)
- break;
- _data->push_back(el_ptr);
- }
- fclose(f);
- Mat(responses).copyTo(*_responses);
- return true;
- }
- //准备训练数据
- Ptr<TrainData> prepare_train_data(const Mat& data, const Mat& responses, int ntrain_samples)
- {
- Mat sample_idx = Mat::zeros(, data.rows, CV_8U);
- Mat train_samples = sample_idx.colRange(, ntrain_samples);
- train_samples.setTo(Scalar::all());
- int nvars = data.cols;
- Mat var_type(nvars + , , CV_8U);
- var_type.setTo(Scalar::all(VAR_ORDERED));
- var_type.at<uchar>(nvars) = VAR_CATEGORICAL;
- return TrainData::create(data, ROW_SAMPLE, responses,
- noArray(), sample_idx, noArray(), var_type);
- }
- //设置迭代条件
- inline TermCriteria TC(int iters, double eps)
- {
- return TermCriteria(TermCriteria::MAX_ITER + (eps > ? TermCriteria::EPS : ), iters, eps);
- }
- //分类预测
- void test_and_save_classifier(const Ptr<StatModel>& model, const Mat& data, const Mat& responses,
- int ntrain_samples, int rdelta)
- {
- int i, nsamples_all = data.rows;
- double train_hr = , test_hr = ;
- // compute prediction error on train and test data
- for (i = ; i < nsamples_all; i++)
- {
- Mat sample = data.row(i);
- float r = model->predict(sample);
- r = std::abs(r + rdelta - responses.at<int>(i)) <= FLT_EPSILON ? .f : .f;
- if (i < ntrain_samples)
- train_hr += r;
- else
- test_hr += r;
- }
- test_hr /= nsamples_all - ntrain_samples;
- train_hr = ntrain_samples > ? train_hr / ntrain_samples : .;
- printf("Recognition rate: train = %.1f%%, test = %.1f%%\n",
- train_hr*., test_hr*.);
- }
- //随机树分类
- bool build_rtrees_classifier(const string& data_filename)
- {
- Mat data;
- Mat responses;
- read_num_class_data(data_filename, , &data, &responses);
- int nsamples_all = data.rows;
- int ntrain_samples = (int)(nsamples_all*0.8);
- Ptr<RTrees> model;
- Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
- model = RTrees::create();
- model->setMaxDepth();
- model->setMinSampleCount();
- model->setRegressionAccuracy();
- model->setUseSurrogates(false);
- model->setMaxCategories();
- model->setPriors(Mat());
- model->setCalculateVarImportance(true);
- model->setActiveVarCount();
- model->setTermCriteria(TC(, 0.01f));
- model->train(tdata);
- test_and_save_classifier(model, data, responses, ntrain_samples, );
- cout << "Number of trees: " << model->getRoots().size() << endl;
- // Print variable importance
- Mat var_importance = model->getVarImportance();
- if (!var_importance.empty())
- {
- double rt_imp_sum = sum(var_importance)[];
- printf("var#\timportance (in %%):\n");
- int i, n = (int)var_importance.total();
- for (i = ; i < n; i++)
- printf("%-2d\t%-4.1f\n", i, .f*var_importance.at<float>(i) / rt_imp_sum);
- }
- return true;
- }
- //adaboost分类
- bool build_boost_classifier(const string& data_filename)
- {
- const int class_count = ;
- Mat data;
- Mat responses;
- Mat weak_responses;
- read_num_class_data(data_filename, , &data, &responses);
- int i, j, k;
- Ptr<Boost> model;
- int nsamples_all = data.rows;
- int ntrain_samples = (int)(nsamples_all*0.5);
- int var_count = data.cols;
- Mat new_data(ntrain_samples*class_count, var_count + , CV_32F);
- Mat new_responses(ntrain_samples*class_count, , CV_32S);
- for (i = ; i < ntrain_samples; i++)
- {
- const float* data_row = data.ptr<float>(i);
- for (j = ; j < class_count; j++)
- {
- float* new_data_row = (float*)new_data.ptr<float>(i*class_count + j);
- memcpy(new_data_row, data_row, var_count*sizeof(data_row[]));
- new_data_row[var_count] = (float)j;
- new_responses.at<int>(i*class_count + j) = responses.at<int>(i) == j + 'A';
- }
- }
- Mat var_type(, var_count + , CV_8U);
- var_type.setTo(Scalar::all(VAR_ORDERED));
- var_type.at<uchar>(var_count) = var_type.at<uchar>(var_count + ) = VAR_CATEGORICAL;
- Ptr<TrainData> tdata = TrainData::create(new_data, ROW_SAMPLE, new_responses,
- noArray(), noArray(), noArray(), var_type);
- vector<double> priors();
- priors[] = ;
- priors[] = ;
- model = Boost::create();
- model->setBoostType(Boost::GENTLE);
- model->setWeakCount();
- model->setWeightTrimRate(0.95);
- model->setMaxDepth();
- model->setUseSurrogates(false);
- model->setPriors(Mat(priors));
- model->train(tdata);
- Mat temp_sample(, var_count + , CV_32F);
- float* tptr = temp_sample.ptr<float>();
- // compute prediction error on train and test data
- double train_hr = , test_hr = ;
- for (i = ; i < nsamples_all; i++)
- {
- int best_class = ;
- double max_sum = -DBL_MAX;
- const float* ptr = data.ptr<float>(i);
- for (k = ; k < var_count; k++)
- tptr[k] = ptr[k];
- for (j = ; j < class_count; j++)
- {
- tptr[var_count] = (float)j;
- float s = model->predict(temp_sample, noArray(), StatModel::RAW_OUTPUT);
- if (max_sum < s)
- {
- max_sum = s;
- best_class = j + 'A';
- }
- }
- double r = std::abs(best_class - responses.at<int>(i)) < FLT_EPSILON ? : ;
- if (i < ntrain_samples)
- train_hr += r;
- else
- test_hr += r;
- }
- test_hr /= nsamples_all - ntrain_samples;
- train_hr = ntrain_samples > ? train_hr / ntrain_samples : .;
- printf("Recognition rate: train = %.1f%%, test = %.1f%%\n",
- train_hr*., test_hr*.);
- cout << "Number of trees: " << model->getRoots().size() << endl;
- return true;
- }
- //多层感知机分类(ANN)
- bool build_mlp_classifier(const string& data_filename)
- {
- const int class_count = ;
- Mat data;
- Mat responses;
- read_num_class_data(data_filename, , &data, &responses);
- Ptr<ANN_MLP> model;
- int nsamples_all = data.rows;
- int ntrain_samples = (int)(nsamples_all*0.8);
- Mat train_data = data.rowRange(, ntrain_samples);
- Mat train_responses = Mat::zeros(ntrain_samples, class_count, CV_32F);
- // 1. unroll the responses
- cout << "Unrolling the responses...\n";
- for (int i = ; i < ntrain_samples; i++)
- {
- int cls_label = responses.at<int>(i) -'A';
- train_responses.at<float>(i, cls_label) = .f;
- }
- // 2. train classifier
- int layer_sz[] = { data.cols, , , class_count };
- int nlayers = (int)(sizeof(layer_sz) / sizeof(layer_sz[]));
- Mat layer_sizes(, nlayers, CV_32S, layer_sz);
- #if 1
- int method = ANN_MLP::BACKPROP;
- double method_param = 0.001;
- int max_iter = ;
- #else
- int method = ANN_MLP::RPROP;
- double method_param = 0.1;
- int max_iter = ;
- #endif
- Ptr<TrainData> tdata = TrainData::create(train_data, ROW_SAMPLE, train_responses);
- model = ANN_MLP::create();
- model->setLayerSizes(layer_sizes);
- model->setActivationFunction(ANN_MLP::SIGMOID_SYM, , );
- model->setTermCriteria(TC(max_iter, ));
- model->setTrainMethod(method, method_param);
- model->train(tdata);
- return true;
- }
- //K最近邻分类
- bool build_knearest_classifier(const string& data_filename, int K)
- {
- Mat data;
- Mat responses;
- read_num_class_data(data_filename, , &data, &responses);
- int nsamples_all = data.rows;
- int ntrain_samples = (int)(nsamples_all*0.8);
- Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
- Ptr<KNearest> model = KNearest::create();
- model->setDefaultK(K);
- model->setIsClassifier(true);
- model->train(tdata);
- test_and_save_classifier(model, data, responses, ntrain_samples, );
- return true;
- }
- //贝叶斯分类
- bool build_nbayes_classifier(const string& data_filename)
- {
- Mat data;
- Mat responses;
- read_num_class_data(data_filename, , &data, &responses);
- int nsamples_all = data.rows;
- int ntrain_samples = (int)(nsamples_all*0.8);
- Ptr<NormalBayesClassifier> model;
- Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
- model = NormalBayesClassifier::create();
- model->train(tdata);
- test_and_save_classifier(model, data, responses, ntrain_samples, );
- return true;
- }
- //svm分类
- bool build_svm_classifier(const string& data_filename)
- {
- Mat data;
- Mat responses;
- read_num_class_data(data_filename, , &data, &responses);
- int nsamples_all = data.rows;
- int ntrain_samples = (int)(nsamples_all*0.8);
- Ptr<SVM> model;
- Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
- model = SVM::create();
- model->setType(SVM::C_SVC);
- model->setKernel(SVM::LINEAR);
- model->setC();
- model->train(tdata);
- test_and_save_classifier(model, data, responses, ntrain_samples, );
- return true;
- }
- int main()
- {
- string data_filename = "E:/opencv/opencv/sources/samples/data/letter-recognition.data"; //字母数据
- cout << "svm分类:" << endl;
- build_svm_classifier(data_filename);
- cout << "贝叶斯分类:" << endl;
- build_nbayes_classifier(data_filename);
- cout << "K最近邻分类:" << endl;
- build_knearest_classifier(data_filename,);
- cout << "随机树分类:" << endl;
- build_rtrees_classifier(data_filename);
- //cout << "adaboost分类:" << endl;
- //build_boost_classifier(data_filename);
- //cout << "ANN(多层感知机)分类:" << endl;
- //build_mlp_classifier(data_filename);
- }
由于adaboost分类和 ann分类速度非常慢,因此我在main函数里把这两个分类注释掉了,大家有兴趣和时间可以测试一下。
结果:
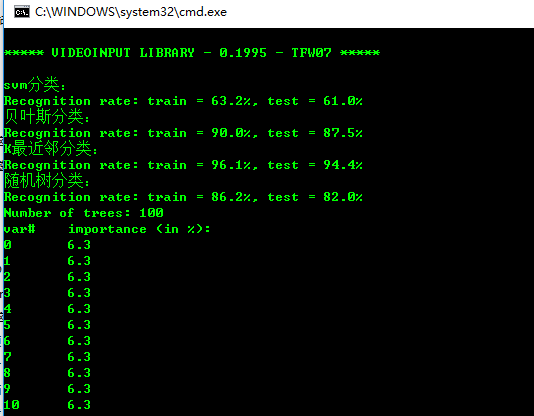
从结果显示来看,测试的四种分类算法中,KNN(最近邻)分类精度是最高的。所以说,对ocr进行识别,还是用knn最好。
在opencv3中的机器学习算法练习:对OCR进行分类的更多相关文章
- 在opencv3中的机器学习算法
在opencv3.0中,提供了一个ml.cpp的文件,这里面全是机器学习的算法,共提供了这么几种: 1.正态贝叶斯:normal Bayessian classifier 我已在另外一篇博文中介 ...
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- scikit-learn中的机器学习算法封装——kNN
接前面 https://www.cnblogs.com/Liuyt-61/p/11738399.html 回过头来看这张图,什么是机器学习?就是将训练数据集喂给机器学习算法,在上面kNN算法中就是将特 ...
- 在opencv3中实现机器学习之:利用逻辑斯谛回归(logistic regression)分类
logistic regression,注意这个单词logistic ,并不是逻辑(logic)的意思,音译过来应该是逻辑斯谛回归,或者直接叫logistic回归,并不是什么逻辑回归.大部分人都叫成逻 ...
- 在opencv3中实现机器学习之:利用svm(支持向量机)分类
svm分类算法在opencv3中有了很大的变动,取消了CvSVMParams这个类,因此在参数设定上会有些改变. opencv中的svm分类代码,来源于libsvm. #include "s ...
- 在opencv3中实现机器学习之:利用正态贝叶斯分类
opencv3.0版本中,实现正态贝叶斯分类器(Normal Bayes Classifier)分类实例 #include "stdafx.h" #include "op ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
随机推荐
- iOS网络检测Reachability 使用 Demo,可检测2、3、4G
你可以在Github下载这个Demo https://github.com/JanzTam/Reachability_Demo 首先,引入系统的Reachability类,不知道怎么引入的话,在Xco ...
- spring boot 1.4.1 with jsp file sample
<!--pom.xml--> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" ...
- 转载:sql关联查询
inner join(等值连接)只返回两个表中联结字段相等的行 left join(左联接)返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接)返回包括右表中的所有记录和 ...
- 系统在某些情况下会自动调节UIScrollView的contentInset
出现情景 如果一个控制器(ViewController)被导航控制器管理,并且该控制器的第一个子控件是UIScrollView,系统默认会调节UIScrollView的contentInset UIE ...
- struts2.3.24 + spring4.1.6 + hibernate4.3.11+ mysql5.5.25开发环境搭建及相关说明
一.目标 1.搭建传统的ssh开发环境,并成功运行(插入.查询) 2.了解c3p0连接池相关配置 3.了解验证hibernate的二级缓存,并验证 4.了解spring事物配置,并验证 5.了解spr ...
- 纪录JVM内存模型内容
声明:本内容是博主在牛客网上看到的网友发表的答案,因为感觉总结的比较好,所以摘抄过来供大家学习. 内容: 大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,He ...
- JMeter源码集成到Eclipse
由于JMeter纯Java开发,界面也是基于Swing或AWT搞出来的,所以想更深层次的去了解这款工具或对于想了解JMeter插件开发或二次开发的童鞋们来说,读读JMeter的源码估计是必不可少的,所 ...
- C# List与DataTable的相互转化
List与Data的转化比较简单,网上也很多.但是大多都有一个Bug:当实体类有可空类型的属性时,转化会出异常(DATASET不支持System.Nullable异常) 下面的方法可以避免出现这个问题 ...
- Java递归实现操作系统文件的复制、粘贴和删除功能
通过Java IO递归实现操作系统对文件的复制.粘贴和删除功能,剪切=复制+粘贴+删除 代码示例: import java.io.BufferedInputStream; import java.io ...
- 基于python的flask的应用实例注意事项
1.所有的html文件均保存在templates文件夹中 2.运行网页时python manage.py runserver