[IR] Index Construction
抛出问题
倒排索引的构建
Three steps to construct Inverted Index as following:

海量term排序
最难的step中:
- Token sequence.
- Sort by term.
- Dictionary & Postings
第2步中的最现实的问题是:假如100G的terms如何排序?
参考文档:http://home.ustc.edu.cn/~zhufengx/ir/pdf/solution.pdf【不错的课件内容】
External Sorting Algorithm (外排)
基于块的排序索引方法 BSBI(blocked sort-based indexing algorithm)

注释:
4. 文档集读取
5. 排序
6. 排序结果fi 存放到disk
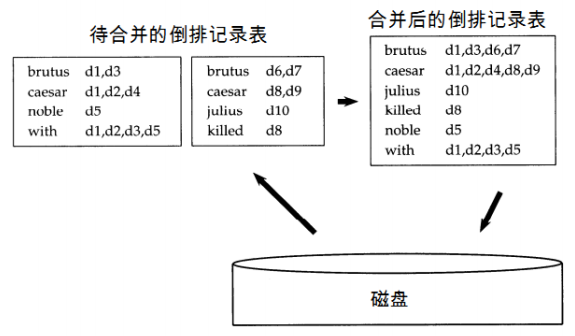
7. Merge 这些排序结果为一个整体的Inverted Index list. 使用小窗口一点点地放入min-heap,
堆顶端输出的是Inverted Index list的 dictionary部分,由小变大的顺序(因为fi 已排序)
注解:说白了就是“两个有序链表的合并”。
- 需要将词项映射成词项ID,必须事先知道词项的排序(知道整个词 典)。
- 所有的块共享一个全局的大词典。
- 如果在每块的处理中,不将词项映射成词项ID,而是直接对“词项-文 档ID”对进行排序,排序的代价将大大增加(整数的比较VS字符串的 比较)。
小缺陷
因为实际使用的是ID。并且一开始就整理出所有的词项 ID—文档 ID 并对它们进行排序的做法。
既然要排序,所以相对耗时。
内存式单遍扫描索引构建方法

注释:
拥有同一hash value的terms的排序设计:
Insert-at-back and move-to-front heuristic
每个块fi 建立新dict;
去除了高代价的sort最后一步依然是 MergeBlocks(.)
突出特点
用了词对索引的直接关联。还有1个比较大的特点是他不经过排序,直接按照先后顺序构建索引。
Term list采用了hash的方式去查找,故构建的过程中不需要排序。
动态索引 - Dynamic Indexing
同时保持着两个索引:一个是大的主索引,另外一个是用于存储新文档信息的辅助索引。
其中辅助索引保存在内存中,辅助索引用于对文档新增内容建立索引,用户在检索时对主索引和辅助索引一起检索,当辅助索引很大时候,将其与磁盘中的主索引进行合并;

注释:
Main Index在Disk; Auxiliary Index在Memory。
可以视为 Immediate Merge 与 No merge 的一个折中。
由于每个倒排记录在 log2(T/n)层 的每一层中都只处理一次,因此整个索引构建的时间是Θ(T*log2(T/n))。
引伸:
求Disk中最后留下的Index的数量。
We use |C| to denote the total size of the document collection, and M to denote the memory size.
Let's assume that: C = h*M
For i in [, log2h]
{
X = [h - (2i – )] mod [2i+1]
If X belong to (, 2i],
exist in column.
Else,
not exist.
}
The sum of existing X is the answer.
大数据量排序
数据多到内存装不下怎么办?
假设内存有100M容量
比如1G的数据,分10份,每份100M。先用快排让每一份各自排好序,然后写到文件中。这10份100M的 文件这个时候已经有序了。
这10份每份取9M,一共90M,使得他们合并。合并后的结果放到10M的缓存区中,满了就clear,IO到 文件中。
理解
有点小根对的意思,例如总是将最小的数字放入10M缓存中,放满后也就是top 10M小的elements,然后save to disk中。
End.
[IR] Index Construction的更多相关文章
- 本人AI知识体系导航 - AI menu
Relevant Readable Links Name Interesting topic Comment Edwin Chen 非参贝叶斯 徐亦达老板 Dirichlet Process 学习 ...
- [Code] 烧脑之算法模型
把博客的算法过一遍,我的天呐多得很,爱咋咋地! 未来可考虑下博弈算法. 基本的编程陷阱:[c++] 面试题之犄角旮旯 第壹章[有必要添加Python] 基本的算法思想:[Algorithm] 面试题之 ...
- [IR] Information Extraction
阶段性总结 Boolean retrieval 单词搜索 [Qword1 and Qword2] O(x+y) [Qword1 and Qword2]- 改进: Gallo ...
- coursera课程Text Retrieval and Search Engines之Week 2 Overview
Week 2 OverviewHelp Center Week 2 On this page: Instructional Activities Time Goals and Objectives K ...
- 人工智能头条(公开课笔记)+AI科技大本营——一拨微信公众号文章
不错的 Tutorial: 从零到一学习计算机视觉:朋友圈爆款背后的计算机视觉技术与应用 | 公开课笔记 分享人 | 叶聪(腾讯云 AI 和大数据中心高级研发工程师) 整 理 | Leo 出 ...
- [IR] Inverted Index & Boolean retrieval
教材:<信息检索导论> 倒排索引 How to build Inverted Index? 1. Token sequence. 2. Sort by terms. 3. Dictiona ...
- [IR] Time and Space Efficiencies Analysis of Full-Text Index Techniques
文章阅读:全文索引技术时空效率分析 LIU Xiao-ZhuPENG Zhi-Yong 根据全文索引实现技术的不同,将其分为三大类: 索引技术 (倒排文件.签名文件 .后缀树与后缀数组) 压缩与索引混 ...
- Theoretical comparison between the Gini Index and Information Gain criteria
Knowledge Discovery in Databases (KDD) is an active and important research area with the promise for ...
- 数据结构 - Codeforces Round #353 (Div. 2) D. Tree Construction
Tree Construction Problem's Link ------------------------------------------------------------------- ...
随机推荐
- 运行(WIN+R)中能使用的命令:ms-settings:,shell:,cpl,mmc...
ms-settings: --- DESC --- --- CMD --- Battery Saver ms-settings:batterysaver Battery Saver Settings ...
- pip 豆瓣镜像使用
pip install -i https://pypi.douban.com/simple/ flask 要用https的 https://pip.pypa.io/en/latest/user_gui ...
- Installing Oracle and ArcSDE on separate servers
http://help.arcgis.com/en/arcgisdesktop/10.0/help/index.html#//002n0000000q000000
- 【Android】Android 移动应用数据到SD
[Android]Android 移动应用数据到SD 在应用的menifest文件中指定就可以了,在 <manifest> 元素中包含android:installLocation 属性, ...
- json字符串转成 Map/List
package jsonToMap; import java.util.List; import java.util.Map; import java.util.Map.Entry; import n ...
- 闲聊Redshift与日本CG行业的近况
最近不少朋友跟我说Redshift如何如何,恰巧我目前工作的工作室花费了巨资购买了Redshift和Quadro M4000,妄图在艺术家工作站上做一个新的动画项目,把渲染时间控制在15分钟以下.结果 ...
- android设置背景半透明效果
1.Button或者ImageButton的背景透明或者半透明 半透明:<Button android:background="#e0000000"···> 透明:&l ...
- React直出实现与原理
前一篇文章我们介绍了虚拟DOM的实现与原理,这篇文章我们来讲讲React的直出. 比起MVVM,React比较容易实现直出,那么React的直出是如何实现,有什么值得我们学习的呢? 为什么MVVM不能 ...
- spring mvc jsp运行不起来的问题
spring mvc已经处理成让jsp运行,即: <bean class="org.springframework.web.servlet.view.InternalResourceV ...
- 精选29款非常实用的jQuery应用插件
今天我们来分享一些实用的jQuery应用插件,没有特别花哨,但都比较实用,jQuery菜单.jQuery图片都有涉及到,一起来看看. 1.jQuery+CSS3仿IOS无线局域网Wifi DEMO演示 ...