Lucene.Net+盘古分词器(详细介绍)(转)
出处:http://www.cnblogs.com/magicchaiy/archive/2013/06/07/LuceneNet%E7%9B%98%E5%8F%A4%E5%88%86%E8%AF%8D%E5%99%A8%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90%E4%BB%8B%E7%BB%8D.html
1、Lucenne.Net简介
2、介绍盘古分词器
3、Lucene.Net实例分析
4、结束语(Demo下载)
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。开发人员可以基于Lucene.net实现全文检索的功能。
Lucene.net是Apache软件基金会赞助的开源项目,基于Apache License协议。
Lucene.net并不是一个爬行搜索引擎,也不会自动地索引内容。我们得先将要索引的文档中的文本抽取出来,然后再将其加到Lucene.net索引中。标准的步骤是先初始化一个Analyzer、打开一个IndexWriter、然后再将文档一个接一个地加进去。一旦完成这些步骤,索引就可以在关闭前得到优化,同时所做的改变也会生效。这个过程可能比开发者习惯的方式更加手工化一些,但却在数据的索引上给予你更多的灵活性。
(来自百度百科)
盘古分词是一个中英文分词组件。作者eaglet 曾经开发过KTDictSeg 中文分词组件,拥有大量用户。作者基于之前分词组件的开发经验,结合最新的开发技术重新编写了盘古分词组件。主要有以下功能:
1、中文未登陆词识别
2、词频优先
3、一元分词,多元分词
4、中文人名分词
5、繁体中文分词
6、英文分词
7、用户自定义规则(字典管理,动态加载字典,关键词高亮)
……
由于盘古分词器不是本章的重点内容,就简单带过了。有兴趣的朋友可以自己网上找找相关资料。文章末尾会提供一个盘古分词器的应用程序供下载
先上一下Demo的图把,看下最后运行效果:
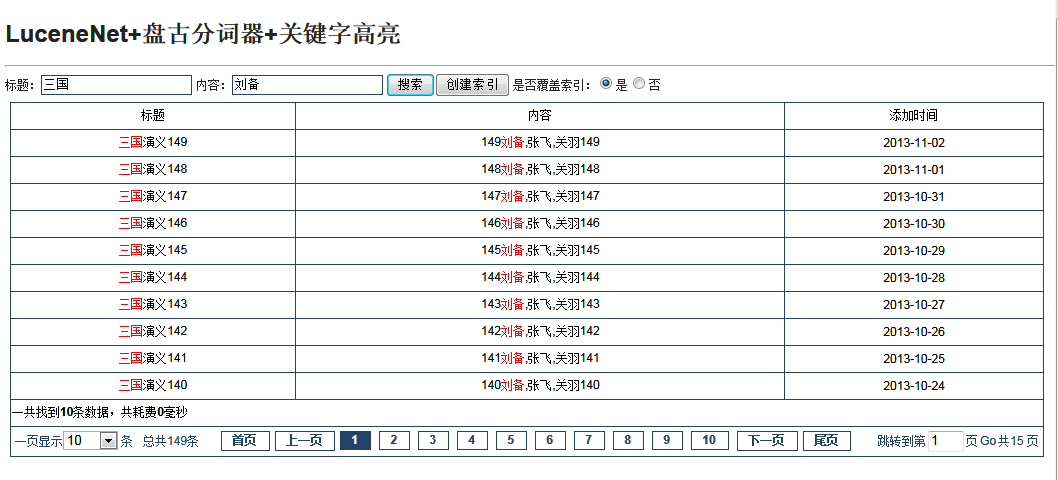
数据是临时随便创建的数据,表格和样式也是随便画的,不喜欢的朋友多包涵呐!
接下来就一步一步来讲解整个编码过程(主要对一些核心的类和细节作为讲解过程),Let's GO
第一步:创建索引
1、由于索引是存放在硬盘里的,所以先定义一个索引的目录

1 /// <summary>
2 /// 索引存放目录
3 /// </summary>
4 protected string IndexDic
5 {
6 get
7 {
8 return Server.MapPath("/IndexDic");
9 }
10 }
2、创建索引器把要索引的内容写入到指定目录
|
1
|
IndexWriter writer = new IndexWriter(IndexDic, PanGuAnalyzer, isCreate, Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED); |
索引器的构造函数参数说明:
IndexDic是索引存放目录
PanGuAnalyzer是盘古解析器(由于默认的解析器解析能力不强,所以替换为这个)
IsCreate是索引创建方式(true:重新新建索引,false:从旧的索引执行追加)
Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED是文件长度是否限制
3、创建索引Document和往文档写入索引内容
1 private void AddIndex(IndexWriter writer, string title, string content,string date)
2 {
3 try
4 {
5 Document doc = new Document();
6 doc.Add(new Field("Title", title, Field.Store.YES, Field.Index.ANALYZED));//存储且索引
7 doc.Add(new Field("Content", content, Field.Store.YES, Field.Index.ANALYZED));//存储且索引
8 doc.Add(new Field("AddTime", date, Field.Store.YES, Field.Index.NOT_ANALYZED));//存储且索引
9 writer.AddDocument(doc);
10 }
11 catch (FileNotFoundException fnfe)
12 {
13 throw fnfe;
14 }
15 catch (Exception ex)
16 {
17 throw ex;
18 }
19 }
Document是索引文档,可以理解成数据库里的记录
Field是索引文档里的字段,可以直接理解成数据库里的字段
Field构造函数说明:
第一个是字段名称(实例里是Title,Content,AddTime)。
第二个是字段的存储方式(Field.Store.YES:进行存储,Filed.Store.No:不进行存储)有些字段值比较大,可以选择No不存储,对字段进行存储是为了检索的时候对某些字段进行提取。
第三个是是否索引(Field.Index.ANALYZED:索引, Field.Index.NOT_ANALYZED:非索引)
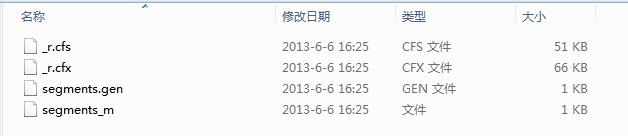
4、到此为止索引就创建完成了,应该可以看到索引目录会产生几个文件,如下图:
第二步:搜索索引
lucene的搜索相当强大,它提供了很多辅助查询类,每个类都继承自Query类,各自完成一种特殊的查询,你可以像搭积木一样将它们任意组合使用,完成一些复杂操 作;另外lucene还提供了Sort类对结果进行排序,提供了Filter类对查询条件进行限制。你或许会不自觉地拿它跟SQL语句进行比 较:“lucene能执行and、or、order by、where、like ‘%xx%’操作吗?”回答是:“当然没问题!”
1 private void SearchIndex()
2 {
3 Dictionary<string, string> dic = new Dictionary<string, string>();
4 BooleanQuery bQuery = new BooleanQuery();
5 string title = string.Empty;
6 string content = string.Empty;
7 if (Request.Form["title"] != null && Request.Form["title"].ToString()!="")
8 {
9 title =GetKeyWordsSplitBySpace( Request.Form["title"].ToString());
10 QueryParser parse = new QueryParser("Title", PanGuAnalyzer);
11 Query query = parse.Parse(title);
12 parse.SetDefaultOperator(QueryParser.Operator.AND);
13 bQuery.Add(query, BooleanClause.Occur.MUST);
14 dic.Add("title",Request.Form["title"].ToString());
15 txtTitle = Request.Form["title"].ToString();
16 }
17 if (Request.Form["content"] != null && Request.Form["content"].ToString() != "")
18 {
19 content = GetKeyWordsSplitBySpace(Request.Form["content"].ToString());
20 QueryParser parse = new QueryParser("Content", PanGuAnalyzer);
21 Query query = parse.Parse(content);
22 parse.SetDefaultOperator(QueryParser.Operator.AND);
23 bQuery.Add(query, BooleanClause.Occur.MUST);
24 dic.Add("content",Request.Form["content"].ToString());
25 txtContent = Request.Form["content"].ToString();
26 }
27 if (bQuery != null && bQuery.GetClauses().Length>0)
28 {
29 GetSearchResult(bQuery, dic);
30 }
31 }
这段代码创建了一个索引查询器,对title和content这两个字段进行查询。
1、介绍各种Query
TermQuery: 首先介绍最基本的查询,如果你想执行一个这样的查询:在content字段中查询包含‘刘备的document”,那么你可以用TermQuery:
1 Term t = new Term("content", "刘备");
2 Query query = new TermQuery(t);
BooleanQuery :如果你想这么查询:在content字段中包含”刘备“并且在title字段包含”三国“的document”,那么你可以建立两个TermQuery并把它们用BooleanQuery连接起来:
1 TermQuery termQuery1 = new TermQuery(new Term("content", "刘备"));
2 TermQuery termQuery2 = new TermQuery(new Term("title", "三国"));
3 BooleanQuery booleanQuery = new BooleanQuery();
4 booleanQuery.Add(termQuery1, BooleanClause.Occur.SHOULD);
5 booleanQuery.Add(termQuery2, BooleanClause.Occur.SHOULD);
WildcardQuery :如果你想对某单词进行通配符查询,你可以用WildcardQuery,通配符包括’?’匹配一个任意字符和’*’匹配零个或多个任意字符,例如你搜索’三国*’,你可能找到’三国演义’或者’三国志’:
1 Query query = new WildcardQuery(new Term("content", "三国*"));
PhraseQuery :你可能对中日关系比较感兴趣,想查找‘中’和‘日’挨得比较近(5个字的距离内)的文章,超过这个距离的不予考虑,你可以:
1 PhraseQuery query = new PhraseQuery();
2 query.SetSlop(5);
3 query.Add(new Term("content ", "中"));
4 query.Add(new Term("content", "日"));
那么它可能搜到“中日合作……”、“中方和日方……”,但是搜不到“中国某高层领导说日本欠扁”。
PrefixQuery :如果你想搜以‘中’开头的词语,你可以用PrefixQuery:
1 PrefixQuery query = new PrefixQuery(new Term("content ", "中"));
FuzzyQuery :FuzzyQuery用来搜索相似的term,使用Levenshtein算法。假设你想搜索跟‘wuzza’相似的词语,你可以:
1 Query query = new FuzzyQuery(new Term("content", "wuzza"));
你可能得到‘fuzzy’和‘wuzzy’。
RangeQuery: 另一个常用的Query是RangeQuery,你也许想搜索时间域从20060101到20060130之间的document,你可以用RangeQuery:
1 RangeQuery query = new RangeQuery(new Term("time","20060101"), new Term("time","20060130"), true);
最后的true表示用闭合区间。
第三步:返回索引结果
上面介绍完各种查询的Query,接下来看看LuceneNet返回的数据集如何处理,如何显示高亮,上代码:
1 private void GetSearchResult(BooleanQuery bQuery,Dictionary<string,string> dicKeywords)
2 {
3 IndexSearcher search = new IndexSearcher(IndexDic,true);
4 Stopwatch stopwatch = Stopwatch.StartNew();
5 //SortField构造函数第三个字段true为降序,false为升序
6 Sort sort = new Sort(new SortField("AddTime", SortField.DOC, true));
7 TopDocs docs = search.Search(bQuery, (Filter)null, PageSize * PageIndex, sort);
8 stopwatch.Stop();
9 if (docs != null && docs.totalHits > 0)
10 {
11 lSearchTime = stopwatch.ElapsedMilliseconds;
12 txtPageFoot = GetPageFoot(PageIndex, PageSize, docs.totalHits, "sabrosus");
13 for (int i = 0; i < docs.totalHits; i++)
14 {
15 if (i >= (PageIndex - 1) * PageSize && i < PageIndex * PageSize)
16 {
17 Document doc = search.Doc(docs.scoreDocs[i].doc);
18 Article model = new Article()
19 {
20 Title = doc.Get("Title").ToString(),
21 Content = doc.Get("Content").ToString(),
22 AddTime = doc.Get("AddTime").ToString()
23 };
24 list.Add(SetHighlighter(dicKeywords, model));
25 }
26 }
27 }
28 }
最后这段代码相对比较简单,我就说下几个关键的类和高亮提示把。
1、关键类说明:
IndexSearcher:索引查询器,它的构造函数有两个参数,一个是索引文件路径,一个是是否只读(一般都设置为true就可以)。这个东西可以理解为SqlServer里面的查询分析器。
Sort:看字眼可知道是索引排序类。主要说一下第三个参数,第三个参数是排序方式(true为降序,false为升序)。
TopDocs:这个是查询后返回的文档,可以理解为Sqlserver的表,search.Search可以当做是在查询分析器里按了一次F5查询。
2、设置关键字高亮:
1 private Article SetHighlighter(Dictionary<string, string> dicKeywords, Article model)
2 {
3 SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"green\">", "</font>");
4 Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment());
5 highlighter.FragmentSize = 50;
6 string strTitle = string.Empty;
7 string strContent = string.Empty;
8 dicKeywords.TryGetValue("title", out strTitle);
9 dicKeywords.TryGetValue("content", out strContent);
10 if (!string.IsNullOrEmpty(strTitle))
11 {
12 model.Title = highlighter.GetBestFragment(strTitle, model.Title);
13 }
14 if (!string.IsNullOrEmpty(strContent))
15 {
16 model.Content = highlighter.GetBestFragment(strContent, model.Content);
17 }
18 return model;
19 }
这里用的也是盘古的高亮组件,设置高亮主要分两个步骤:
设置高亮的显示样式、设置高亮的查询关键字
SimpleHTMLFormatter:这个类是一个HTML的格式类,构造函数有两个,一个是开始标签,一个是结束标签。
Segment:添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment。
感谢大家的阅读,如果这篇文章能帮的上你,那是我的荣幸。如果文章哪里写的不好,还请多多指教。
参考文献:
http://www.cnblogs.com/jeffwongishandsome/archive/2011/01/02/1924107.html
http://space.itpub.net/12639172/viewspace-626546
Demo下载 (Demo是visual studio 2010编写的,打不开请下载vs2010或者自己更改为vs2008或其他版本)
Lucene.Net+盘古分词器(详细介绍)(转)的更多相关文章
- 【原创】Lucene.Net+盘古分词器(详细介绍)
本章阅读概要 1.Lucenne.Net简介 2.介绍盘古分词器 3.Lucene.Net实例分析 4.结束语(Demo下载) Lucene.Net简介 Lucene.net是Lucene的.net移 ...
- Lucene.Net+盘古分词器(详细介绍)
本章阅读概要1.Lucenne.Net简介2.介绍盘古分词器3.Lucene.Net实例分析4.结束语(Demo下载)Lucene.Net简介 Lucene.net是Lucene的.net移植版本,是 ...
- Lucene.Net3.0.3+盘古分词器学习使用
一.Lucene.Net介绍 Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索 ...
- Apache Lucene(全文检索引擎)—分词器
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- 【盘古分词】Lucene.Net 盘古分词 实现公众号智能自动回复
盘古分词是一个基于 .net framework 的中英文分词组件.主要功能 中文未登录词识别 盘古分词可以对一些不在字典中的未登录词自动识别 词频优先 盘古分词可以根据词频来解决分词的歧义问题 多元 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Net Core使用Lucene.Net和盘古分词器 实现全文检索
Lucene.net Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎, ...
- 使用Lucene.net+盘古分词实现搜索查询
这里我的的Demo的逻辑是这样的:首先我基本的数据是储存在Sql数据库中,然后我把我的必需的数据推送到MongoDB中,这样再去利用Lucene.net+盘古创建索引:其中为什么要这样把数据推送到Mo ...
随机推荐
- 前端开发框架Bootstrap和KnockoutJS
江湖中那场异常惨烈的厮杀,如今都快被人遗忘了.当年,所有的武林同道为了同一个敌人都拼尽了全力,为数不多的幸存者心灰意冷,隐姓埋名,远赴他乡,他们将唯一的希望寄托给时间.少年子弟江湖老,红颜少女的鬓边也 ...
- 关于rand()与srand()函数
rand函数功能为获取一个伪随机数(伪随机数的概念下面会有介绍). 一.函数名: rand(); 二.声明: int rand(); 三.所在头文件: stdlib.h 四.功能: 返回一个伪随机数. ...
- notepad++ 正则表达式
body { font-family: Bitstream Vera Sans Mono; font-size: 11pt; line-height: 1.5; } html, body { colo ...
- VBS中对Error的处理
VBScript语言提供了两个语句和一个对象来处理"运行时错误",如下所示: On Error Resume Next语句 On Error Goto 0语句 Err对象 简单介绍 ...
- python 获取文件夹大小
__author__ = 'bruce' import os from os.path import join,getsize def getdirsize(dir): size=0l for (ro ...
- localstorage,sessionstorage使用
今天看了一下HTML5,也算是简单的学习一下吧,HTML5 提供了两种在客户端存储数据的新方法:localstorage,sessionstorage. localStorage - 没有时间限制的数 ...
- Kernel Logestic Regression
一.把 soft margin svm 看做 L2 Regression 模型 先来一张图回顾一下之前都学了些什么: 之前我们是通过拉格朗日乘子法来进行soft Margin Svm的转化问题,现在换 ...
- WSGI
[WSGI] WSGI:Web Server Gateway Interface. WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求.我们来看一个最简单的Web版本的 ...
- Android permission
1. users-permission Users-permission is the permission that this app should acquire, so that the app ...
- 跨进程(同一app不同进程之间通信)——Android自动化测试学习历程
视频地址:http://study.163.com/course/courseLearn.htm?courseId=712011#/learn/video?lessonId=877122&co ...