【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器
之前介绍了那么多基本知识【Python爬虫】入门知识,(没看的先去看!!)大家也估计手痒了。想要实际做个小东西来看看,毕竟:
talk is cheap show me the code!
这个小工程的代码都在github上,感兴趣的自己去下载:
https://github.com/hk029/Pickup
制作爬虫的基本步骤
顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤。
一般来说,制作一个爬虫需要分以下几个步骤:
1. 分析需求(对,需求分析非常重要,不要告诉我你老师没教你)
2. 分析网页源代码,配合F12(没有F12那么乱的网页源代码,你想看死我?)
3. 编写正则表达式或者XPath表达式(就是前面说的那个神器)
4. 正式编写python爬虫代码
效果
运行:

恩,让我输入关键词,让我想想,输入什么好呢?好像有点暴露爱好了。

回车

好像开始下载了!好赞!,我看看下载的图片,哇瞬间我感觉我又补充了好多表情包….
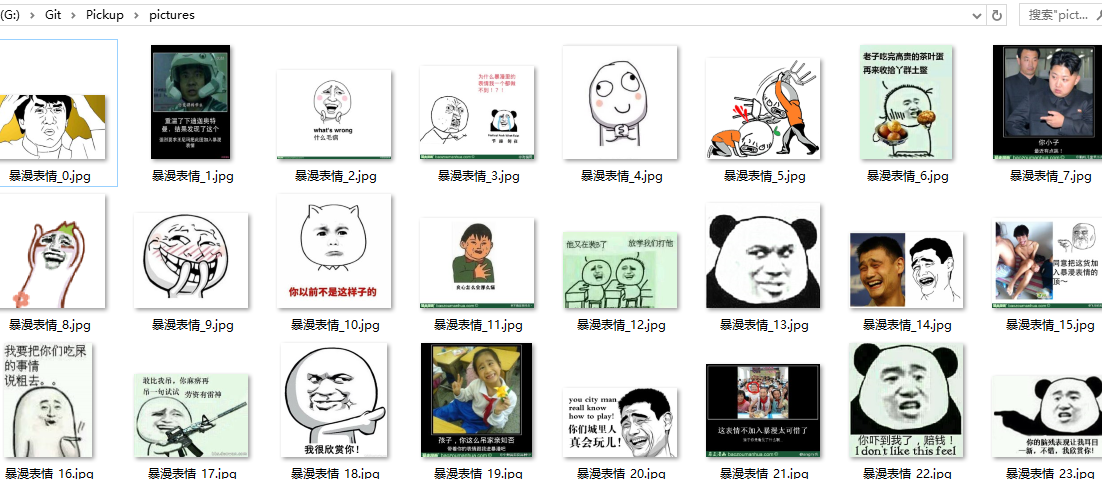
好了,差不多就是这么个东西。
需求分析
”我想要图片,我又不想上网搜“
”最好还能自动下载”
……
这就是需求,好了,我们开始分析需求,至少要实现两个功能,一是搜索图片,二是自动下载。
首先,搜索图片,最容易想到的就是爬百度图片的结果,好,那我们就上百度图片看看
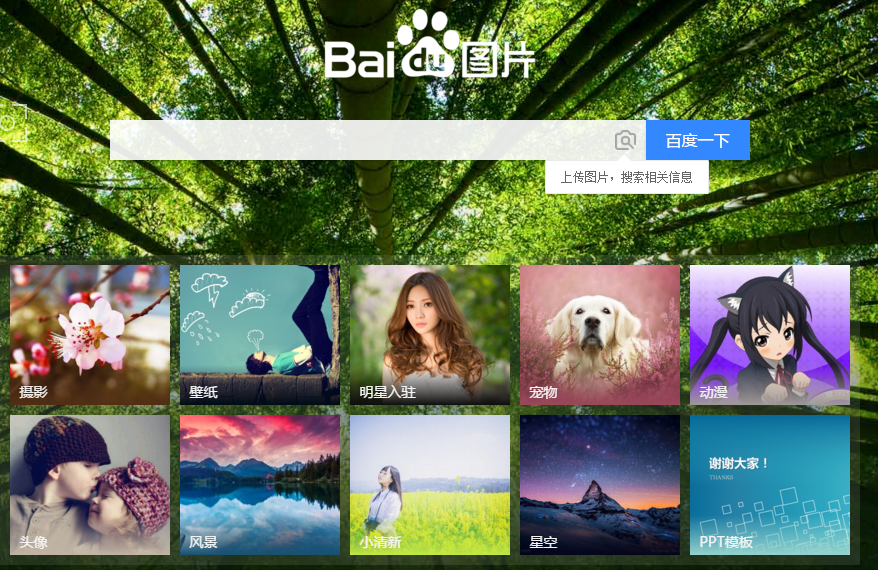
基本就是这样,还挺漂亮的。
我们试着搜一个东西,我打一个暴字,出来一系列搜索结果,这说明什么….
随便找一个回车
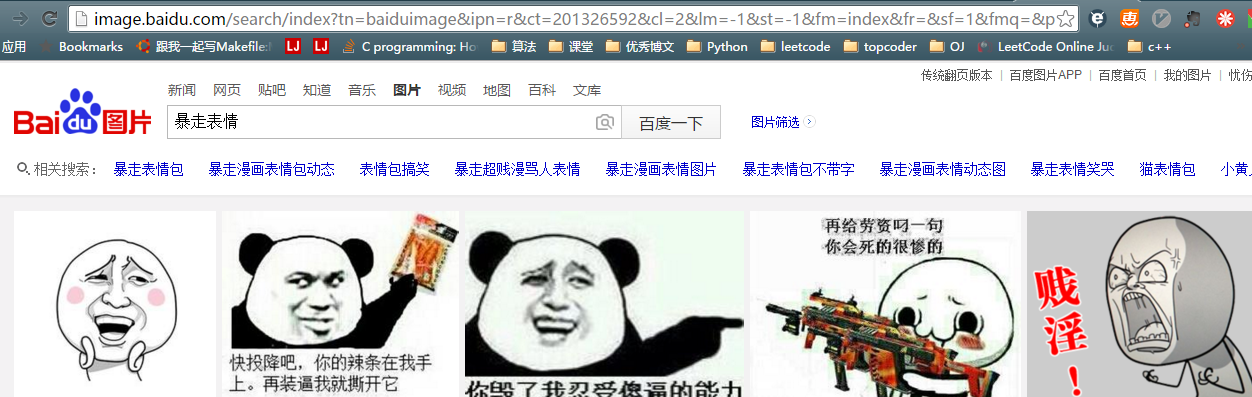
好了,我们已经看到了很多图片了,如果我们能把这里面的图片都爬下来就好了。我们看见网址里有关键词信息

我们试着在网址直接换下关键词,跳转了有没有!
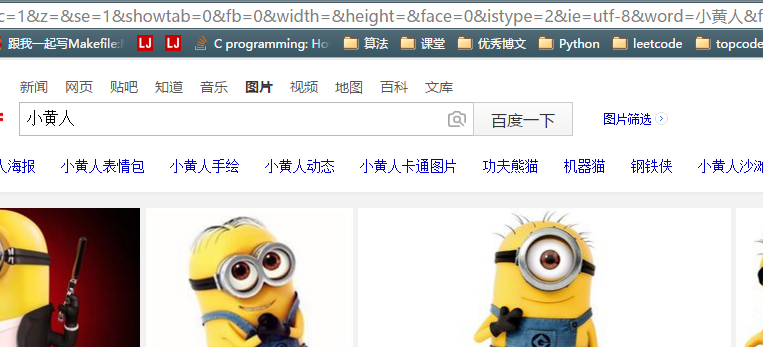
这样,可以通过这个网址查找特定的关键词的图片,所以理论上,我们可以不用打开网页就能搜索特定的图片了。下个问题就是如何实现自动下载,其实利用之前的知识,我们知道可以用request,获取图片的网址,然后把它爬下来,保存成.jpg就行了。
所以这个项目就应该可以完成了。
分析网页
好了,我们开始做下一步,分析网页源代码。这里 我先切换回传统页面,为什么这样做,因为目前百度图片采用的是瀑布流模式,动态加载图片,处理起来很麻烦,传统的翻页界面就好很多了。

这里还一个技巧,就是:能爬手机版就不要爬电脑版,因为手机版的代码很清晰,很容易获取需要的内容。
好了,切换回传统版本了,还是有页码的看的舒服。
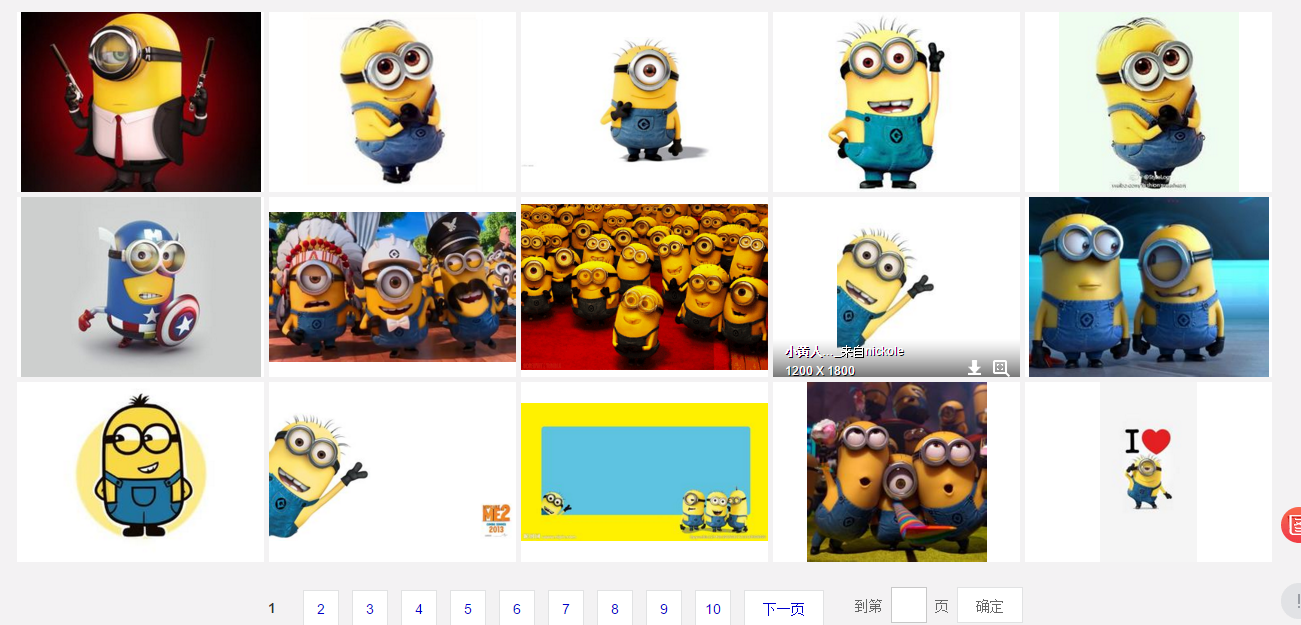
我们点击右键,查看源代码
这都是什么鬼,怎么可能看清!!

这个时候,就要用F12了,开发者工具!我们回到上一页面,按F12,出来下面这个工具栏,我们需要用的就是左上角那个东西,一个是鼠标跟随,一个是切换手机版本,都对我们很有用。我们这里用第一个

然后选择你想看源代码的地方,就可以发现,下面的代码区自动定位到了这个位置,是不是很NB!
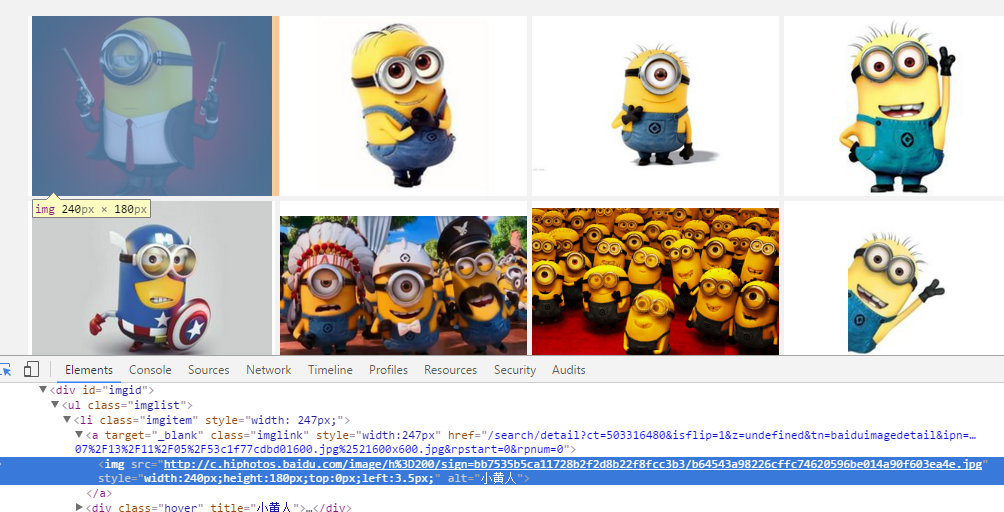
我们复制这个地址

然后到刚才的乱七八糟的源代码里搜索一下,发现它的位置了!(小样!我还找不到你!)但是这里我们又疑惑了,这个图片怎么有这么多地址,到底用哪个呢?我们可以看到有thumbURL,middleURL,hoverURL,objURL

通过分析可以知道,前面两个是缩小的版本,hover是鼠标移动过后显示的版本,objURL应该是我们需要的,不信可以打开这几个网址看看,发现obj那个最大最清晰。
好了,找到了图片位置,我们就开始分析它的代码。我看看是不是所有的objURL全是图片
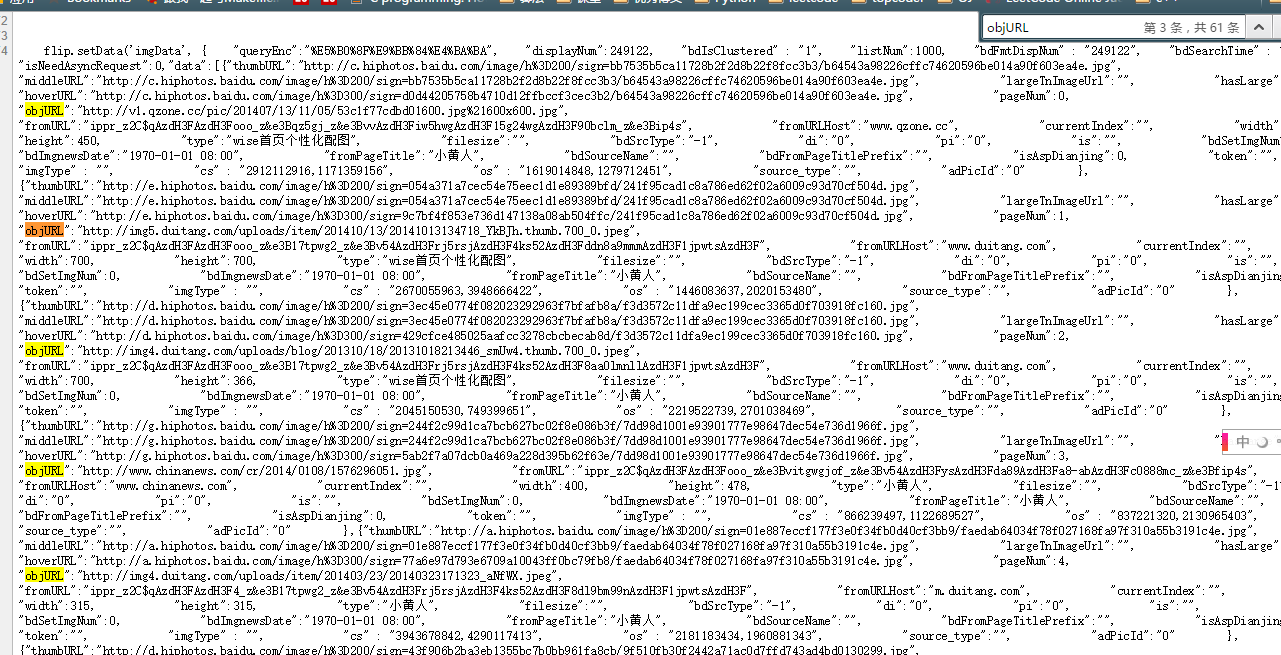
貌似都是以.jpg格式结尾的,那应该跑不了了,我们可以看到搜索出61条,说明应该有61个图片
编写正则表达式
通过前面的学习,写出如下的一条正则表达式不难把?
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
编写爬虫代码
好了,正式开始编写爬虫代码了。这里我们就用了2个包,一个是正则,一个是requests包,之前也介绍过了,没看的回去看!
#-*- coding:utf-8 -*-
import re
import requests然后我们把刚才的网址粘过来,传入requests,然后把正则表达式写好
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1460997499750_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E5%B0%8F%E9%BB%84%E4%BA%BA'
html = requests.get(url).text
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
理论有很多图片,所以要循环,我们打印出结果来看看,然后用request获取网址,这里由于有些图片可能存在网址打不开的情况,加个5秒超时控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
i = 0
for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print '【错误】当前图片无法下载'
continue好了,再就是把网址保存下来,我们在事先在当前目录建立一个picture目录,把图片都放进去,命名的时候,用数字命名把
string = 'pictures\\'+str(i) + '.jpg'
fp = open(string,'wb')
fp.write(pic.content)
fp.close()
i += 1整个代码就是这样:
#-*- coding:utf-8 -*-
import re
import requests
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1460997499750_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E5%B0%8F%E9%BB%84%E4%BA%BA'
html = requests.get(url).text
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
i = 0
for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print '【错误】当前图片无法下载'
continue
string = 'pictures\\'+str(i) + '.jpg'
fp = open(string,'wb')
fp.write(pic.content)
fp.close()
i += 1我们运行一下,看效果(什么你说这是什么IDE感觉很炫!?赶紧去装Pycharm,Pycharm的配置和使用看这个文章!)!
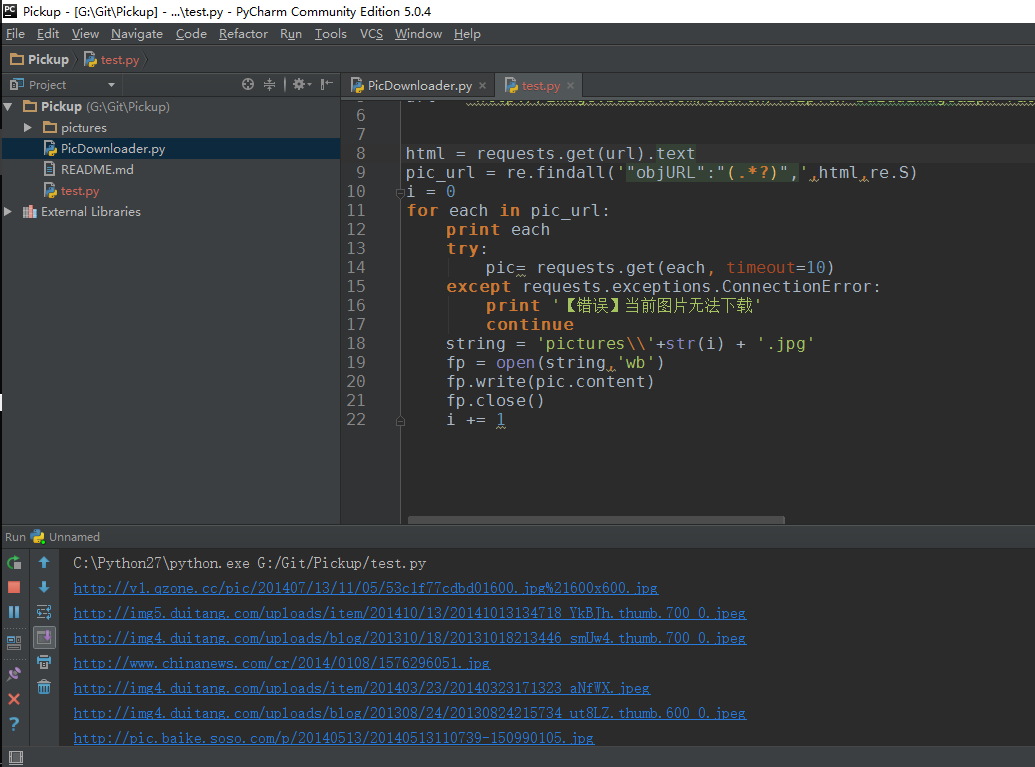
好了我们下载了58个图片,咦刚才不是应该是61个吗?
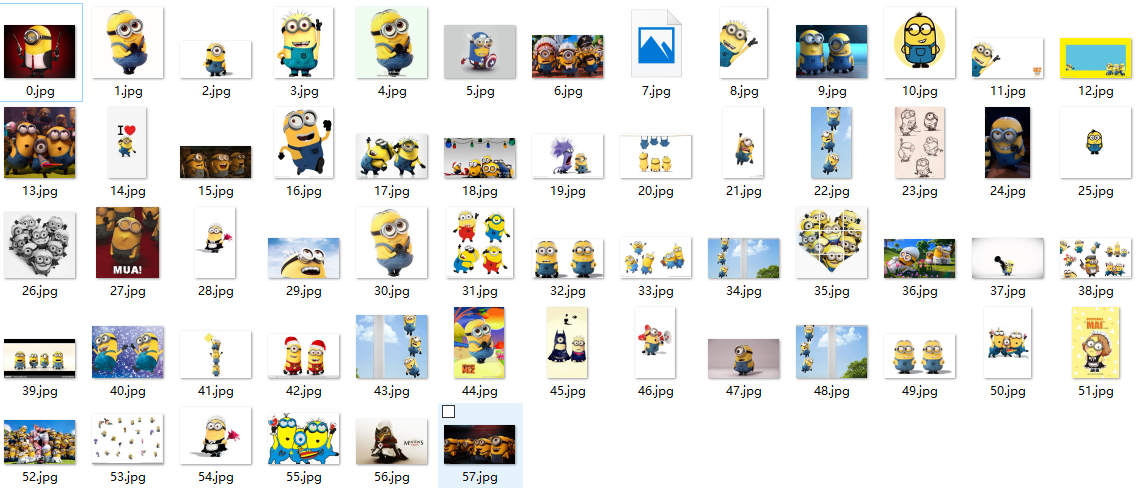
我们看,运行中出现了有一些图片下载不了
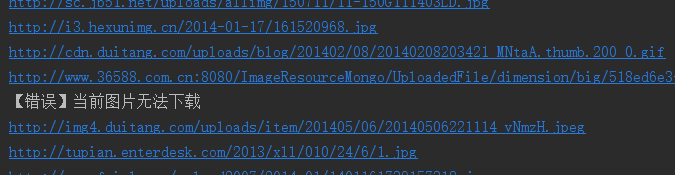
我们还看到有图片没显示出来,打开网址看,发现确实没了。
所以,百度有些图片它缓存到了自己的机器上,所以你还能看见,但是实际连接已经失效
好了,现在自动下载问题解决了,那根据关键词搜索图片呢?只要改url就行了,我这里把代码写下来了
word = raw_input("Input key word: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&ct=201326592&v=flip'
result = requests.get(url)好了,享受你第一个图片下载爬虫吧!!
【图文详解】python爬虫实战——5分钟做个图片自动下载器的更多相关文章
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- 【Python开发】【神经网络与深度学习】网络爬虫之图片自动下载器
python爬虫实战--图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识(没看的赶紧去看)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap show ...
- Python爬虫之足球小将动漫(图片)下载
尽管俄罗斯世界杯的热度已经褪去,但这届世界杯还是给全世界人民留下了无数难忘的回忆,不知你的回忆里有没有日本队的身影?本次世界杯中,日本队的表现让人眼前一亮,很难想象,就是这样一只队伍,二十几年还是 ...
- 【图文详解】scrapy安装与真的快速上手——爬取豆瓣9分榜单
写在开头 现在scrapy的安装教程都明显过时了,随便一搜都是要你安装一大堆的依赖,什么装python(如果别人连python都没装,为什么要学scrapy….)wisted, zope interf ...
- 最佳实战Docker持续集成图文详解
最佳实战Docker持续集成图文详解 这是一种真正的容器级的实现,这个带来的好处,不仅仅是效率的提升,更是一种变革:开发人员第一次真正为自己的代码负责——终于可以跳过运维和测试部门,自主维护运行环境( ...
- Python安装、配置图文详解(转载)
Python安装.配置图文详解 目录: 一. Python简介 二. 安装python 1. 在windows下安装 2. 在Linux下安装 三. 在windows下配置python集成开发环境(I ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 【和我一起学python吧】Python安装、配置图文详解
Python安装.配置图文详解 目录: 一. Python简介 二. 安装python 1. 在windows下安装 2. 在Linux下安装 三. 在windows下配置python集成开发环境( ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装爬虫框架Scrapy(离线方式和在线方式)(图文详解)
不多说,直接上干货! 参考博客 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解) 第一步:首先,提示升级下pip 第二步 ...
随机推荐
- IOS基础之 (十二) Block
一 定义 Block封装了一段代码,可以在任何时候执行. Block可以作为函数参数或者函数的返回值,而其本身又可以带输入参数或返回值. 二 使用 1. 定义函数指针,然后在实现. #import & ...
- BurpSuite之HTTP brute暴力破解
常规的对username/passwprd进行payload测试,我想大家应该没有什么问题,但对于Authorization: Basic dXNlcm5hbWU6cGFzc3dvcmQ=这样的问题, ...
- apache AddDefaultCharset
AddDefaultCharset 指令 说明 当应答内容是text/plain或text/html时,在HTTP应答头中加入的默认字符集 语法 AddDefaultCharset On|Off|ch ...
- B0BO TFS 安装指南(转载)
TFS2008安装过几次,每次都遇到点麻烦,结合网上的一些经验总结一下: Windows SharePoint Services 安装 Windows SharePoint Services你有两个选 ...
- CSS创建一个遮罩层
.layer{ width: 100%; position: absolute; left:; right:; top:; bottom:; -moz-opacity:; filter: alpha( ...
- 我所使用的一个通用的Makefile模板
话不多说,请看: 我的项目有的目录结构有: dirls/ ├── include │ └── apue.h ├── lib │ ├── error.c │ ├── error.o │ ...
- php利用淘宝IP库获取用户ip地理位置
我们查ip的时候都是利用ip138查询的,不过那个有时候是不准确的,还不如自己引用淘宝的ip库来查询,这样准确度还高一些.不多说了,介绍一下淘宝IP地址库的使用. 淘宝IP地址库 淘宝公布了他们的IP ...
- cocos进阶教程(3)Cocos2d-x多场景切换生命周期
在多个场景切换时候,场景的生命周期会更加复杂.这一节我们介绍一下场景切换生命周期. 多个场景切换时候分为几种情况: 情况1,使用pushScene函数从实现HelloWorld场景进入Setting场 ...
- Atlas安装及配置
==============linux下快捷键==================ctrl+insert 复制shift +insert 粘贴 输入文件名的前三个字母,按tab键自动补全文件名 在vi ...
- ADF成长记1--认识ADF
2014-07-08 近段时间由于公司项目需要,开始接触Oracle ADF.都说有事没事,上百度,但是对于IT技术而言,上百度还真是不一定好使,至于谷歌嘛,很不巧的进不去了.不过网上ADF的资料当真 ...