Kafka消息时间戳(kafka message timestamp)
- 日志保存(log retention)策略:Kafka目前会定期删除过期日志(log.retention.hours,默认是7天)。判断的依据就是比较日志段文件(log segment file)的最新修改时间(last modification time)。倘若最近一次修改发生于7天前,那么就会视该日志段文件为过期日志,执行清除操作。但如果topic的某个分区曾经发生过分区副本的重分配(replica reassigment),那么就有可能会在一个新的broker上创建日志段文件,并把该文件的最新修改时间设置为最新时间,这样设定的清除策略就无法执行了,尽管该日志段中的数据其实已经满足可以被清除的条件了。
- 日志切分(log rolling)策略:与日志保存是一样的道理。当前日志段文件会根据规则对当前日志进行切分——即,创建一个新的日志段文件,并设置其为当前激活(active)日志段。其中有一条规则就是基于时间的(log.roll.hours,默认是7天),即当前日志段文件的最新一次修改发生于7天前的话,就创建一个新的日志段文件,并设置为active日志段。所以,它也有同样的问题,即最近修改时间不是固定的,一旦发生分区副本重分配,该值就会发生变更,导致日志无法执行切分。(注意:log.retention.hours及其家族与log.rolling.hours及其家族不会冲突的,因为Kafka不会清除当前激活日志段文件)
- 流式处理(Kafka streaming):流式处理中需要用到消息的时间戳
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test --partitions 1 --replication-factor 1 --config message.timestamp.type=LogAppendTime
record = new ProducerRecord<String, String>("my-topic", null, System.currentTimeMillis(), "key", "value");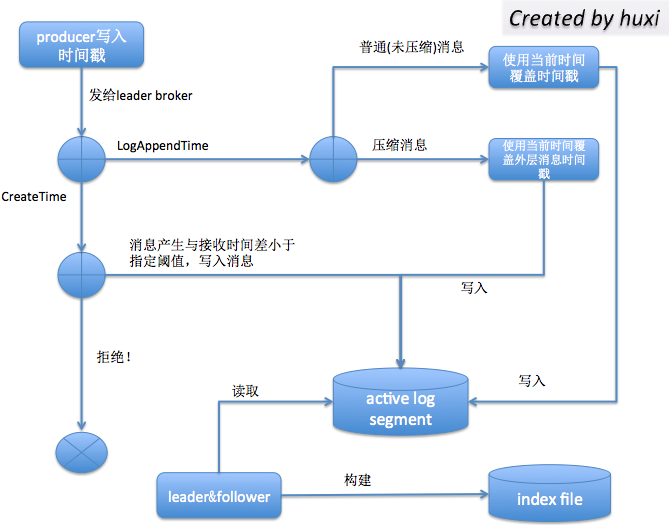
Kafka消息时间戳(kafka message timestamp)的更多相关文章
- Kafka 消息监控 - Kafka Eagle
1.概述 在开发工作当中,消费 Kafka 集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提下,我们可以使用 Kafka 提供的命令工具,配合 Zookeeper 客户端工具,可以很方便 ...
- spark streaming 接收kafka消息之三 -- kafka broker 如何处理 fetch 请求
首先看一下 KafkaServer 这个类的声明: Represents the lifecycle of a single Kafka broker. Handles all functionali ...
- 一文看懂Kafka消息格式的演变
摘要 对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化.随着Kafka的迅猛发展,其消息格式也在不断的升级改进,从0.8.x版本开始到现在的1.1.x版本,Kaf ...
- 转载来自朱小厮博客的 一文看懂Kafka消息格式的演变
转载来自朱小厮博客的 一文看懂Kafka消息格式的演变 ✎摘要 对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化.随着Kafka的迅猛发展,其消息格式也在 ...
- Kafka消息(存储)格式及索引组织方式
要深入学习Kafka,理解Kafka的存储机制是非常重要的.本文介绍Kafka存储消息的格式以及数据文件和索引组织方式,以便更好的理解Kafka是如何工作的. Kafka消息存储格式 Kafka为了保 ...
- 源码分析 Kafka 消息发送流程(文末附流程图)
温馨提示:本文基于 Kafka 2.2.1 版本.本文主要是以源码的手段一步一步探究消息发送流程,如果对源码不感兴趣,可以直接跳到文末查看消息发送流程图与消息发送本地缓存存储结构. 从上文 初识 Ka ...
- 源码分析 Kafka 消息发送流程
Futuresend(ProducerRecord<K, V> record) Futuresend(ProducerRecord<K, V> record, Callback ...
- Kafka消息的压缩机制
最近在做 AWS cost saving 的事情,对于 Kafka 消息集群,计划通过压缩消息来减少消息存储所占空间,从而达到减少 cost 的目的.本文将结合源码从 Kafka 支持的消息压缩类型. ...
- Kafka(3)--kafka消息的存储及Partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 [root@localhost ~]# ...
随机推荐
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(68)-微信公众平台开发- 资源环境准备
系列目录 前言: 本次将学习扩展企业微信公众号功能,微信公众号也是企业流量及品牌推广的主要途径,所谓工欲善其事必先利其器,调试微信必须把程序发布外网环境,导致调试速度太慢,太麻烦! 我们需要准备妥当才 ...
- 谈谈一些有趣的CSS题目(一)-- 左边竖条的实现方法
开本系列,讨论一些有趣的 CSS 题目,抛开实用性而言,一些题目为了拓宽一下解决问题的思路,此外,涉及一些容易忽视的 CSS 细节. 解题不考虑兼容性,题目天马行空,想到什么说什么,如果解题中有你感觉 ...
- CSS 3学习——box-sizing和背景
box-sizing 在CSS 2中设置元素的width和height仅仅是设置了元素内容区的宽和高,元素实际的尺寸是margin + border + padding + 内容区. CSS 3(截止 ...
- mysql 赋予用户权限
# 赋予权限MySQL> grant 权限参数 on 数据库名称.表名称 to 用户名@用户地址 identified by '用户密码'; # 立即生效权限MySQL> flush pr ...
- 一点公益商城开发系统模式Ring Buffer+
一个队列如果只生产不消费肯定不行的,那么如何及时消费Ring Buffer的数据呢?简单的方案就是当Ring Buffer"写满"的时候一次性将数据"消费"掉. ...
- D3.js学习(七)
上一节中我们学会了如何旋转x轴标签以及自定义标签内容,在这一节中,我们将接触动画(transition) 首先,我们要在页面上添加一个按钮,当我们点击这个按钮时,调用我们的动画.所以,我们还需要在原来 ...
- 升讯威ADO.NET增强组件(源码):送给喜欢原生ADO.NET的你
目前我们所接触到的许多项目开发,大多数都应用了 ORM 技术来实现与数据库的交互,ORM 虽然有诸多好处,但是在实际工作中,特别是在大型项目开发中,容易发现 ORM 存在一些缺点,在复杂场景下,反而容 ...
- [Intel Edison开发板] 01、Edison开发板性能简述
Integrated Wi-Fi certified in 68 countries, Bluetooth® 4.0 support, 1GB DDR and 4GB flash memory sim ...
- RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...