OpenNLP:驾驭文本,分词那些事
OpenNLP:驾驭文本,分词那些事
作者 白宁超
2016年3月27日19:55:03
摘要:字符串、字符数组以及其他文本表示的处理库构成大部分文本处理程序的基础。大部分语言都包括基本的处理库,这也是对文本处理或自然语言处理的前期必要工作。典型代表便是分词、词性标注、句子识别等等。本文所介绍的工具主要针对英文分词,对于英文分词工具很多,笔者经比较Apache OpenNLP效率和使用便捷度较好。另外其针对Java开发提供开源的API。开篇简介OpenNLP的情况,随后介绍6种常用模型,最后针对每种模型的使用和Java实现进行总结。部分笔者可能质疑那么中文分词怎么办?随后篇章会单独介绍中科院研究团队基于隐马尔可夫模型开发的中文分词工具NLPIR(ICTCLA)。内容经过多篇文档和书籍整理汇编,代码经运行无误。(本文原创,转载请标明出处:OpenNLP:驾驭文本,分词那些事)
目录
【文本挖掘(0)】快速了解什么是自然语言处理
【文本挖掘(1)】OpenNLP:驾驭文本,分词那些事
【文本挖掘(2)】【NLP】Tika 文本预处理:抽取各种格式文件内容
【文本挖掘(3)】自己动手搭建搜索工具
1 什么是OpenNLP,其具有哪些"内功"?
OpenNLP是为何物?
维基百科:Apache OpenNLP库是一个基于机器学习的自然语言文本处理的开发工具包,它支持自然语言处理中一些共有的任务,例如:标记化、句子分割、词性标注、固有实体提取(指在句子中辨认出专有名词,例如:人名)、浅层分析(句字分块)、语法分析及指代。这些任务通常都需要较为先进的文字处理服务功能。
官方文档:Apache的OpenNLP库是自然语言文本的处理基于机器学习的工具包。它支持最常见的NLP任务,如断词,句子切分,部分词性标注,命名实体提取,分块,解析和指代消解。这些任务通常需要建立更先进的文字处理服务。OpenNLP还包括最大熵和基于感知机器学习。该OpenNLP项目的目标是创造上述任务的成熟工具包。一个附加的目的是提供一种大量预建模型为各种语言,以及这些模型衍生自注释文本资源。
- 开发者: Apache Software Foundation
- 稳定版本: 1.5.2-incubating(2011年11月28日,5年前)
- 开发状态: Active
- 编程语言: Java
- 类型: 自然语言处理
- 网站: http://incubator.apache.org/opennlp/
使用:其支持Windows、linux等多个操作系统,本文主要介绍Windows下:
1 命令行界面(CLI):OpenNLP脚本使用JAVA_CMD和JAVA_HOME变量,以确定哪些命令用来执行Java虚拟机。OpenNLP脚本使用OPENNLP_HOME变量来确定OpenNLP的二进制分发的位置。建议这个变量指向当前OpenNLP版本和更新PATH变量的二进制分发版包括$OPENNLP_HOME/bin or %OPENNLP_HOME%\bin。这样的配置允许方便调用OpenNLP。下面的例子假设这个配置已经完成。使用如下:当工具被执行这种方式,模型是装载和工具正在等待来自标准输入的输入。此输入处理,并打印到标准输出。
$ opennlp ToolName lang-model-name.bin < input.txt > output.txt
2 Java在控制台:进行其API的调用,以下代码演示均采用此法。
- 在官网(点击下载):apache-opennlp-1.5.3工具包

- 解压文件:(如:savepath\apache-opennlp-1.5.3\lib)将lib下文件拷贝项目中

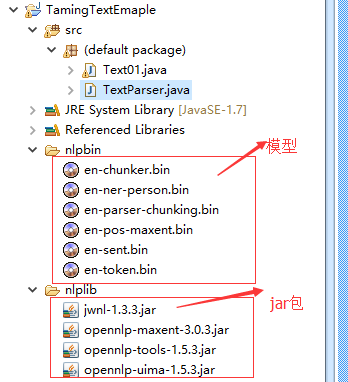
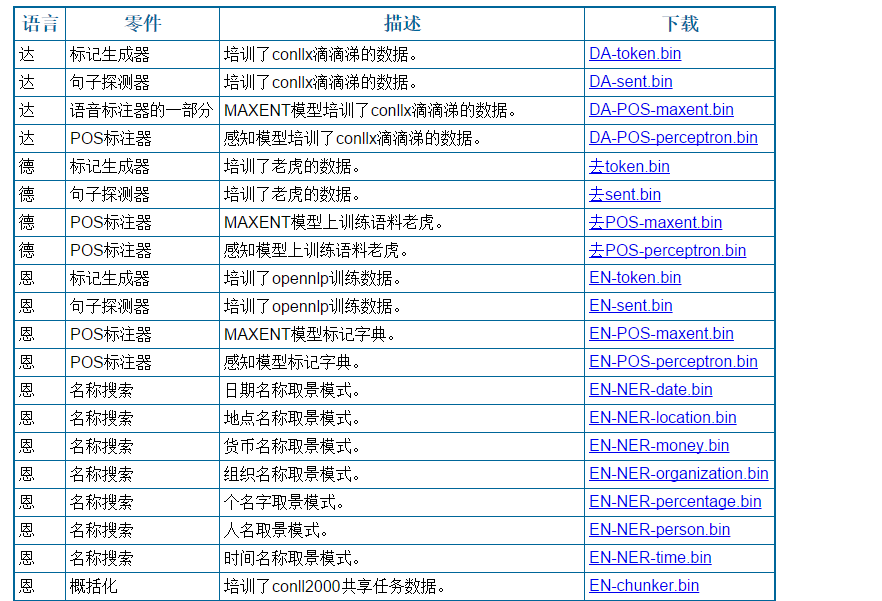
- 去官网模型页面下载bin文件,下载需要的模型,具体如下:
- 然后去创建java程序做相应处理,诸如:分词、词性标注等。
3 示例:至此完成java配置,然后相对 "The quick, red fox jumped over the lazy, brown dogs." 一条句子进行分词,常规方法采用空格分词代码如下:
//英文切词:空格或者换行符
public static void ENSplit(String str)
{
String[] result=str.split("\\s+");
for(String s:result){
System.out.println(s+" ");
}
System.out.println();
}
分词结果:

随着需求的改变,假如我想把标点也分开。实际这也是有意义的,可以通过标点确定句子的边界。下面OpenNLP将采用其方式完成,由此引入本文正题。
2 句子探测器
功能介绍:
句子检测器是用于检测句子边界。
句子探测器返回一个字符串数组。
API:句子探测器还提供了一个API来培养一个新的句子检测模型。三个基本步骤是必要的训练它:
- 应用程序必须打开一个示例数据流
- 调用SentenceDetectorME.train方法
- 保存SentenceModel到文件或直接使用它
代码实现:
/**
* 1.句子探测器:Sentence Detector
* @deprecated Sentence detector is for detecting sentence boundaries. Given the following paragraph:
* Hi. How are you? This is Mike.
* 如:Hi. How are you? This is Mike.将返回如下:
* Hi. How are you?
* This is Mike.
* @throws IOException
* @throws InvalidFormatException
*/
public static void SentenceDetector(String str) throws InvalidFormatException, IOException
{
//always start with a model, a model is learned from training data
InputStream is = new FileInputStream("./nlpbin/en-sent.bin");
SentenceModel model = new SentenceModel(is);
SentenceDetectorME sdetector = new SentenceDetectorME(model); String sentences[] = sdetector.sentDetect(str); System.out.println(sentences[0]);
System.out.println(sentences[1]);
is.close();
System.out.println("---------------1------------");
}
运行结果:

3 标记生成器
功能介绍:该OpenNLP断词段输入字符序列为标记。常是这是由空格分隔的单词,但也有例外。例如,“isn't”被分割为“is”与“n't",因为它是AA简要格式”isn't“我们的句子分为以下标记:符号通常是词语,标点符号,数字等OpenNLP提供多种标记生成器的实现:
- 空白标记生成器 - 一个空白标记生成器,非空白序列被确定为符号
- 简单的标记生成器 - 一个字符类标记生成器,同样的字符类的序列标记
- 可学习标记生成器 - 一个最大熵标记生成器,检测基于概率模型符号边界
API:的断词可以被集成到由定义的API的应用程序。该WhitespaceTokenizer的共享实例可以从静态字段WhitespaceTokenizer.INSTANCE进行检索。该SimpleTokenizer的共享实例可以在从SimpleTokenizer.INSTANCE相同的方式进行检索。实例化TokenizerME(中可以学习标记生成器)符号模型必须先创建。
代码实现:
/**
* 2.标记生成器:Tokenizer
* @deprecated Tokens are usually words which are separated by space, but there are exceptions. For example, "isn't" gets split into "is" and "n't, since it is a a brief format of "is not". Our sentence is separated into the following tokens:
* @param str
*/
public static void Tokenize(String str) throws InvalidFormatException, IOException {
InputStream is = new FileInputStream("./nlpbin/en-token.bin");
TokenizerModel model = new TokenizerModel(is);
Tokenizer tokenizer = new TokenizerME(model);
String tokens[] = tokenizer.tokenize(str);
for (String a : tokens)
System.out.println(a);
is.close();
System.out.println("--------------2-------------");
}
运行结果:
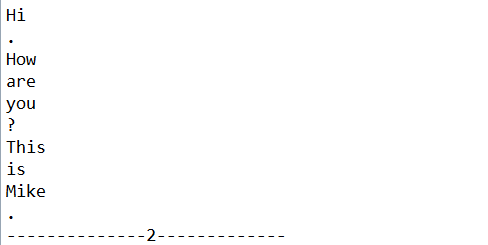
4 名称搜索
功能介绍:名称查找器可检测文本命名实体和数字。为了能够检测实体名称搜索需要的模型。该模型是依赖于语言和实体类型这是训练。所述OpenNLP项目提供了许多这些各种免费提供的语料库训练有素预训练名取景模式。他们可以在我们的模型下载页进行下载。要查找原始文本的文本必须分割成符号和句子的名字。详细描述中的一句话探测器和标记生成器教程中给出。其重要的,对于训练数据和输入的文本的标记化是相同的。根据不同的模型可以查找人名、地名等实体名。
API:从应用程序中训练名字发现者的建议使用培训API而不是命令行工具。三个基本步骤是必要的训练它:
- 应用程序必须打开一个示例数据流
- 调用NameFinderME.train方法
- 保存TokenNameFinderModel到文件或数据库
代码实现:
/**
* 3.名称搜索:Name Finder
* @deprecated By its name, name finder just finds names in the context. Check out the following example to see what name finder can do. It accepts an array of strings, and find the names inside.
* @param str
*/
public static void findName() throws IOException {
InputStream is = new FileInputStream("./nlpbin/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(is);
is.close();
NameFinderME nameFinder = new NameFinderME(model);
String[] sentence = new String[]{
"Mike",
"Tom",
"Smith",
"is",
"a",
"good",
"person"
};
Span nameSpans[] = nameFinder.find(sentence);
for(Span s: nameSpans)
System.out.println(s.toString());
System.out.println("--------------3-------------");
}
运行结果:

5 POS标注器
功能介绍:语音标记器的部分标记符号与基于符号本身和符号的上下文中它们的相应字类型。符号可能取决于符号和上下文使用多个POS标签。该OpenNLP POS标注器使用的概率模型来预测正确的POS标记出了标签组。为了限制可能的标记的符号标记字典可以使用这增加了捉人者的标记和运行时性能。
API:部分的词类打标签训练API支持一个新的POS模式的培训。三个基本步骤是必要的训练它:
- 应用程序必须打开一个示例数据流
- 调用POSTagger.train方法
- 保存POSModel到文件或数据库
代码实现1:
/**
* 4.POS标注器:POS Tagger
* @deprecated Hi._NNP How_WRB are_VBP you?_JJ This_DT is_VBZ Mike._NNP
* @param str
*/
public static void POSTag(String str) throws IOException {
POSModel model = new POSModelLoader().load(new File("./nlpbin/en-pos-maxent.bin"));
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");//显示加载时间
POSTaggerME tagger = new POSTaggerME(model);
ObjectStream<String> lineStream = new PlainTextByLineStream(new StringReader(str));
perfMon.start();
String line;
while ((line = lineStream.read()) != null) {
String whitespaceTokenizerLine[] = WhitespaceTokenizer.INSTANCE.tokenize(line);
String[] tags = tagger.tag(whitespaceTokenizerLine);
POSSample sample = new POSSample(whitespaceTokenizerLine, tags);
System.out.println(sample.toString());
perfMon.incrementCounter();
}
perfMon.stopAndPrintFinalResult();
System.out.println("--------------4-------------");
}
运行结果1:

代码实现2:
/**
* OpenNLP词性标注工具的例子:最大熵词性标注器pos-maxent
* JJ形容词、JJS形容词最高级、JJR形容词比较级
* RB副词、RBR副词最高级、RBS副词比较级
* DT限定词
* NN名称、NNS名称复试、NNP专有名词、NNPS专有名词复数:
* PRP:人称代词、PRP$:物主代词
* VB动词不定式、VBD过去式、VBN过去分词、VBZ现在人称第三人称单数、VBP现在非第三人称、VBG动名词或现在分词
*/
public static void POSMaxent(String str) throws InvalidFormatException, IOException
{
//给出词性模型所在的路径
File posModeFile=new File("./nlpbin/en-pos-maxent.bin");
FileInputStream posModeStream=new FileInputStream(posModeFile);
POSModel model=new POSModel(posModeStream);
//将句子切分成词
POSTaggerME tagger=new POSTaggerME(model);
String[] words=SimpleTokenizer.INSTANCE.tokenize(str);
//将切好的词的句子传递给标注器
String[] result=tagger.tag(words);
for (int i=0; i<words.length;i++){
System.out.print(words[i]+"/"+result[i]+" ");
}
System.out.println();
}
运行结果2:
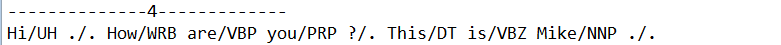
6 细节化
功能介绍:文本分块由除以单词句法相关部分,如名词基,动词基的文字,但没有指定其内部结构,也没有其在主句作用。
API:该概括化提供了一个API来培养新的概括化的模式。下面的示例代码演示了如何做到这一点:
代码实现:
/**
* 5.序列标注:Chunker
* @deprecated 通过使用标记生成器生成的tokens分为一个句子划分为一组块。What chunker does is to partition a sentence to a set of chunks by using the tokens generated by tokenizer.
* @param str
*/
public static void chunk(String str) throws IOException {
POSModel model = new POSModelLoader().load(new File("./nlpbin/en-pos-maxent.bin"));
//PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
POSTaggerME tagger = new POSTaggerME(model);
ObjectStream<String> lineStream = new PlainTextByLineStream(new StringReader(str));
//perfMon.start();
String line;
String whitespaceTokenizerLine[] = null;
String[] tags = null;
while ((line = lineStream.read()) != null) {
whitespaceTokenizerLine = WhitespaceTokenizer.INSTANCE.tokenize(line);
tags = tagger.tag(whitespaceTokenizerLine);
POSSample sample = new POSSample(whitespaceTokenizerLine, tags);
System.out.println(sample.toString());
//perfMon.incrementCounter();
}
//perfMon.stopAndPrintFinalResult(); // chunker
InputStream is = new FileInputStream("./nlpbin/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(is);
ChunkerME chunkerME = new ChunkerME(cModel);
String result[] = chunkerME.chunk(whitespaceTokenizerLine, tags);
for (String s : result)
System.out.println(s);
Span[] span = chunkerME.chunkAsSpans(whitespaceTokenizerLine, tags);
for (Span s : span)
System.out.println(s.toString());
System.out.println("--------------5-------------");
}
运行结果:

7 分析器
功能介绍:尝试解析器最简单的方法是在命令行工具。该工具仅用于演示和测试。请从我们网站上的英文分块解析器模型,并用以下命令启动解析工具。
代码实现:
/**
* 6.分析器: Parser
* @deprecated Given this sentence: "Programcreek is a very huge and useful website.", parser can return the following:
* (TOP (S (NP (NN Programcreek) ) (VP (VBZ is) (NP (DT a) (ADJP (RB very) (JJ huge) (CC and) (JJ useful) ) ) ) (. website.) ) )
* (TOP
* (S
* (NP
* (NN Programcreek)
* )
* (VP
* (VBZ is)
* (NP
* (DT a)
* (ADJP
* (RB very)
* (JJ huge)
* (CC and)
* (JJ userful)
* )
* )
* )
* (. website.)
* )
* )
* @param str
*/
public static void Parse() throws InvalidFormatException, IOException {
// http://sourceforge.net/apps/mediawiki/opennlp/index.php?title=Parser#Training_Tool
InputStream is = new FileInputStream("./nlpbin/en-parser-chunking.bin");
ParserModel model = new ParserModel(is);
Parser parser = ParserFactory.create(model);
String sentence = "Programcreek is a very huge and useful website.";
opennlp.tools.parser.Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (opennlp.tools.parser.Parse p : topParses)
p.show();
is.close();
}
运行结果:

8 参考文献
1 官方教程Apache OpenNLP Developer Documentation
5 驾驭文本第二章第二节
7 OpenNLP本文使用模型(bin文件)分享: 访问密码 1d65
相关文章
【文本处理】自然语言处理在现实生活中运用
【文本处理】多种贝叶斯模型构建及文本分类的实现
【文本处理】快速了解什么是自然语言处理
【文本处理】领域本体构建方法概述
OpenNLP:驾驭文本,分词那些事的更多相关文章
- NLPIR_Init文本分词-总是初始化失败,false,Init ICTCLAS failed!
前段时间用这个分词用的好好的,突然间就总是初始化失败了: 网上搜了很多,但是不是我想要的答案,最终去了官网看了下:官网链接 发现哇,版本更新了啊,下载页面链接 麻利的下载好了最新的文档,一看压缩包名字 ...
- NLP实现文本分词+在线词云实现工具
实现文本分词+在线词云实现工具 词云是NLP中比较简单而且效果较好的一种表达方式,说到可视化,R语言当仍不让,可见R语言︱文本挖掘——词云wordcloud2包 当然用代码写词云还是比较费劲的,网上也 ...
- seo与python大数据结合给文本分词并提取高频词
最近研究seo和python如何结合,参考网上的一些资料,写的这个程序. 目的:分析某个行业(例如:圆柱模板)用户最关心的一些词,根据需求去自动调整TDK,以及栏目,内容页的规划 使用方法: 1.下载 ...
- jieba文本分词,去除停用词,添加用户词
import jieba from collections import Counter from wordcloud import WordCloud import matplotlib.pyplo ...
- Hive基于UDF进行文本分词
本文大纲 UDF 简介 Hive作为一个sql查询引擎,自带了一些基本的函数,比如count(计数),sum(求和),有时候这些基本函数满足不了我们的需求,这时候就要写hive hdf(user de ...
- 【NLP】Tika 文本预处理:抽取各种格式文件内容
Tika常见格式文件抽取内容并做预处理 作者 白宁超 2016年3月30日18:57:08 摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理.首先我们要意识到预处理的重 ...
- R+openNLP︱openNLP的六大可实现功能及其在R语言中的应用
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- openNLP是NLP中比较好的开源工具,R语 ...
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- 文本向量化及词袋模型 - NLP学习(3-1)
分词(Tokenization) - NLP学习(1) N-grams模型.停顿词(stopwords)和标准化处理 - NLP学习(2) 之前我们都了解了如何对文本进行处理:(1)如用NLTK文 ...
随机推荐
- 07.LoT.UI 前后台通用框架分解系列之——轻巧的文本编辑器
LoT.UI汇总:http://www.cnblogs.com/dunitian/p/4822808.html#lotui 上次说的是强大的百度编辑器 http://www.cnblogs.com/d ...
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- java时间
Calendar.getInstance().getTime() 获取当前时间(包括星期和时区 CST China Standard Time): Fri Jan 06 21:03:36 CST 2 ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- java 字节流与字符流的区别
字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢?实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作 ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- 如何开启MySQL 5.7.12 的二进制日志
1. 打开/etc下的my.cnf文件 2. 编辑它,添加内容: log_bin=binary-log #二进制日志的文件名 server_id=1 #必须指定server_id,这是MySQL ...
- 洛谷P1547 Out of Hay
题目背景 奶牛爱干草 题目描述 Bessie 计划调查N (2 <= N <= 2,000)个农场的干草情况,它从1号农场出发.农场之间总共有M (1 <= M <= 10,0 ...
- MVP初探
什么是MVP MVP是一种UI的架构模式,是MVC的一种变体,适用于基于事件驱动的应用框架.MVP中的M和V分别对应了MVC中的Model和View,而P代替了Controller,而它更多地体现在了 ...
- 猫哥网络编程系列:详解 BAT 面试题
从产品上线前的接口开发和调试,到上线后的 bug 定位.性能优化,网络编程知识贯穿着一个互联网产品的整个生命周期.不论你是前后端的开发岗位,还是 SQA.运维等其他技术岗位,掌握网络编程知识均是岗位的 ...