SQL语言笔记
字符串用单引号',判断用单等号=,两个单引号''转义为一个单引号'
创建与删除数据库
--创建数据库 create database School; --删除数据库 drop database School; --创建数据库的时候指定一些选项 create database School; on primary--配置主数据文件 ( name='School',--逻辑名称,数据库内部用的名字 filename='',--保存路径 size=5MB,--设置初始化大小 filegrowth=10MB或10%,--设置增长速度 maxsize=100MB--设置最大大小 ) log on--配置主日志文件 ( name='',--设置逻辑名称 filename='',--设置路径 size=3MB, filegrowth%, maxsize=20MB )
创建表
--每个项设置后面都加逗号 最后一项不加 --切换数据库 use School; --在School数据库中创建一个学生表 create table TblStudent ( --表中的定义在这对的小括号中 --开始创建列 --列名 数据类型 自动编号(从几开始,增长步长) 是否为空(不写默认允许,或者写null 不允许空写 not null) --tsid int identity(1,1) not null --设置名为tsid 类型为int 从1开始增长,每次增长1的主键列 tsid ,) primary key, )
插入数据
--查询表 select * from TblClass --insert向表插入数据(一次只能插一条) insert into TblClass(tclassName,tclassDesc) values('tclassName的值','tclassDesc的值') --TblClass后面的括号设置在哪些列插入数据,value后面的括号要与前面的一一对应.如果要给除自动编号的所有列插入数据,TblClass后面的括号可省 --插入同时返回指定列的数据:在value前加上output inserted.列名 --向自动编号列插入数据 --先把一个选项打开 倒数第二个是列名 set IDENTITY_INSERT tblclass on insert........ --最后记得把选项关掉 --听过一条语句插入多条数据 insert into TblClass(tclassName,tclassDesc) select '...','...' union select '...','...' union select '...','...' union select '...','...' --最后一项不用union --把一个表的书数据插入另一个表 insert into 被插表(列名,列名) select 列名,列名 from 数据来源表 --插入汉字记得在字符串前加入N
更新数据
update 表名 set 列名=值,列名2=值2 where 条件 and..or... --如果没有条件,所有数据都会更新
删除数据
--删除 delete from 表名 where 条件 --删除整表数!据!与drop不同,两种 --1,delete from 表名 --速度慢 --自动编号依然保留当前已经增长的位置 delete from 表名 --2,truncate table 表名 --速度快 --自动编号重置 truncate table 表名
修改表设置
--修该列 --删除指定列 alter table 表名 drop column 列名 --增加指定列 alter table 表名 add 列名(这里跟创建表一样) --修改指定列 alter table 表名 alter column 列名 --增加约束 --给指定列添加主键约束 alter table 表名 add constraint 约束名 primary key(列名) --给指定列添加非空约束 alter table 表名 alter column 列名 数据类型 not null --给指定列添加唯一约束 alter table 表名 add constrainy UQ开头的约束名 unique(列名) --给指定列添加默认约束 alter table 表名 add constraint 约束名 default(值) for 列名 --给指定列添加检查约束 alter table 表名 add constraint 约束名 check(表达式) --增加外键约束 alter table 表名 add constraint FK_约束名 foreign key(外键列名)references 主键表名(列名) --删除多个约束 alter table 表名 drop constraint 约束名,...,... --创建多个约束 alter table 表名 add constraint 约束名 unique(列名), constraint 约束名 check(表达式), constraint 约束名 foreign key(要引用列) references 被引用表(列) on delete cascade on update cascade --设置级联删除和更新
查询数据(select,top,distinct)
--数据检索,查询指定列的数据,不加where返回所有 select 列名,列名,... from 表名 where 条件 --用select显示东西,列名可省略,列名可以不''起来,除非名字有特殊符号 select 值 (空格或者as) 列名 --top获得前几条数据,选到的都是向上取整 select top (数字或数字 percent) * from 表名 order by 列名 (asc//升序,默认值 desc//降序) --Distinct去除查询出的重复数据,只要有一点不同(显示出来的列的内容不同)不算重复,比如自动增长的那列 select distinct 要显示的列 from 表名 ...
联合查询(union,union all)
合并行叫做"联合"联合必须保证每行的数据数目与第一行一致,数据类型兼容列名为第一行的列名union all 在联合时不会去除重复数据,也不自动排序不能分别排序常用:底部总和例:select商品名称,销售总价格=(sum(销售数量*销售价格))fromMyOrdersgroupby商品名称union allselect'销售总价:',sum(销售数量*销售价格)fromMyOrders
连接查询(join....on...)
select*from TblClass jion tblstudent on TblClass.tClassId=TblStudent.tSClassId --查询出两个表符合TblClass.tClassId=TblStudent.tSClassId的数据行,并显示其所有数据
select*from TblClass jion tblstudent on TblClass.tClassId=TblStudent.tSClassId
select * from TestJoin1Emp emp inner join TestJoin2Dept dept on emp.EmpDeptid=dept.DeptId --两者等效 select * from TestJoin1Emp emp , TestJoin2Dept dept --假设emp与dept,行数分别是3,5.select * from 这两个表,实际会形成3*5=15行的临时表 --再在这个表中筛选,而这个表叫做笛卡尔表 where emp.EmpDeptid=dept.DeptId
create table groups ( gid ,) primary key not null, gname ), gparent int ) select * from groups ) ) ) ) ) --查询部门对应的上级部门 use Temp select deparment.gname as '部门名称',company.gname as '所属部门' from groups as deparment inner join groups as company on deparment.gparent=company.gid
------多表查询案例分析: -- dbo.Branch:结构表: 银行,开发商,政府房管局 --dbo.BuildingInfo: 建筑信息表。 天堂花园 1号楼。 --dbo.ProjectInfo:项目信息表。天堂花园1期。 --dbo.UserInfo:用户信息表 ---查询建筑信息表,顺便:建筑信息所属的项目名,项目所属的机构名字,项目创建人的名字 select B.*,P.ProjectName,BR.BranchName,u.UName as SubBy from dbo.BuildingInfo as B left join dbo.ProjectInfo as P on B.ProjectId=P.Id left join dbo.Branch as Br On P.BranchId=BR.Id left join dbo.UserInfo as U On P.SubBy=U.Id
模糊查询,通配符
--模糊查询,通配符,当使用通配符必须使用like,可以在like前面加no 表示除了匹配数据的数据 --%,表示匹配任意多个字符 --例子,查询以张开头的字符串 select * from 表名 where 列名 like N'张%' --查询包含%的字符串 select * from 表名 where 列名 like '%[%]%' -- _ ,表示一个任意字符 -- [ ],表示匹配一个字符,这个字符是[]访问内的通常是[0-9][a-z] -- ^ 非
排序(order by)
判断NULL值
分组(group by)
--例子,统计学生表中每个班的男生人数,且显示id select 班级id=tsclassId 男同学人数=count(*) from TblStudent where tsgender='男' group by (tsclassId,这就是group by包含的列,可以逗号添加多个列,意味着分组后在分组) --有时候要把一些信息放到group by后才能放到select,这时不一定担心,在group by 语句写过多会造成过多的分组, --例子如下 --列1 列2 列 3 --A aa 少壮不努力 --B bb 老大LOL --如果group 列1,列2 因为当列1为A,列2必须aa,列1B,列2必须bb时最终只会会分成两个组,所以有时候不用担心分组过多 --对得到的组进一步筛选(having) --例子:按笔记编号分组,筛选出班级人数大于10的班级 select tsclassId as 班级编号 count(*) as 人数 from TbStudent --如果这里有where,where这不能用聚合函数 group by tsclassId //having的内容只能是select选择的内容
select 列 into 新表 语法
子查询
select * from TblStudent as ts where exists//如果查到数据返回true ( select * from TblClass as tc where tc.tclassId=ts.tsclassId and (tc.tclassname='高一一班'or tc.tclassname='高二二班') )
分页(row_number())
* from Customers where CustomerId not in () CutomerID from Customers order by CustomerId asc) order by CustomerId asc
--每页7条,看第4页。 select * from ( select row_number() over(order by CustomerId asc) as Rn , * --over()子句把数据按CustomerId排序 --通过row_number()函数吧查到的数据添加一条编号列,列名为Rn --再通过编号得到想要的数据 from Customers ) )
over子句
select b.studentid,b.score ,b.courseName , (select count(*) from StudentScore where courseName=b.courseName group by courseName) as '参加该科目考试的额人数为' from StudentScore as b order by b.studentid,courseName --等效于 select studentid,score,courseName, count(*) over (partition by courseName) as'参加该科目考试的额人数为' from StudentScore order by studentid,courseName
视图
create view v_Areaasselect * from 表
alter view v_Areaasselect * from 表
drop view v_Area
select * fromv_Area
select * from v_Areaorder by....
select a1.AreaId,a1.AreaName,a2.AreaName from TblArea as a1 inner join TblArea as a2 on a2.AreaId=a1.AreaPId --这个select用了两个AreaName,这样不能确定视图的列名,会报错
事务
' ' --模拟银行转账,如果第一条出错,第二条还是会执行 --所以这里需要用到事务
begin transaction --执行操作 ' --立刻验证一下这句话是否执行成功了。。 set @sumErrors=@sumErrors+@@error ' set @sumErrors=@sumErrors+@@error --验证是否执行成功 begin --表示没有出错 commit transaction --将事务提交 end else begin rollback --失败则回滚 end
存储过程
create procedure usp_Add1 @num1 int, @num2 int as begin print @num1+@num2 end --带默认值的存储过程 create procedure usp_Add2 , @num2 int as begin print @num1+@num2 end --带输出参数的存储过程 create procedure usp_Add3 @num1 int, @num2 int, @num3 int output as begin @num3=@num1+@num2 end
, --输出9 exec sp_helptext 'sp_databases' --看指定存储过程源码的 --输出11,usp_Add2如果给@num2赋值必须写@num2=...,否则会认为给@num1赋值 delcare @answer int--跟c#里面out参数差不多,声明与调用都要写output ,,@answer ouput
alter procedure usp_fenye @pageSize int,--每页的记录条数 @pageIndex int,--用户当前要查看第几页 @pageCount int output --输出参数,返回总共有几页 as begin select * from ( select *,Rn=row_number()over(order by tSid) from TblStudent ) as stu ) and @pageIndex* @pageSize --设置输出参数的值 declare @datacount int=(select count(*) from TblStudent) set @pageCount=ceiling(@datacount/(@pageSize*1.0)) --向较大的数取整 end
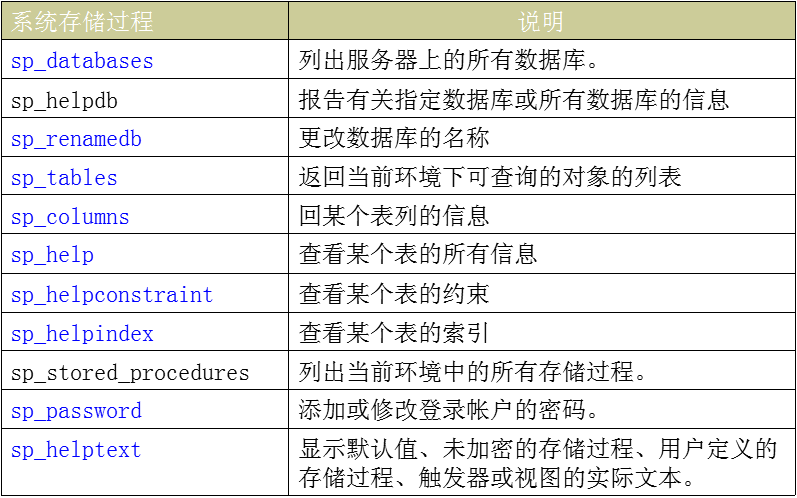
索引
--聚集索引创建 create clustered index 名字 on 表(列) --非聚集索引创建 create index 名字 on 表(列) --删除索引(略有不同) drop index 表名.索引名
inserted表与deleted表
触发器(像C#的事件)
--create trigger 触发器名 on 表名 create trigger tri_delete_TblPerson on TblPerson --for/after/instead of(for与after都表示after触发器) delete/insert/update,可以写多个触发器类型用逗号隔开 instead of delete,insert as begin --执行内容,会用到selected表或inserted表 end
游 标
--1.定义一个游标 * from Area --2.打开游标 open cur_Area --3.查询使用游标 fetch next from cur_Area begin fetch next from cur_Area end --4.关闭游标 close cur_Area --5。释放资源 deallocate cur_Area
SQL语句执行顺序
⑧Order By 列
下面内容为转载
sql的临时表使用小结
方法一:
create table TempTableName
或
select [字段1,字段2,...,] into TempTableName from table
方法二:
create table tempdb.MyTempTable(Tid int)
说明:
(1)、临时表其实是放在数据库tempdb里的一个用户表;
(2)、TempTableName必须带“#”,“#"可以是一个或者两个,以#(局部)或##(全局)开头的表,这种表在会话期间存在,会话结束则自动删除;
(3)、如果创建时不以#或##开头,而用tempdb.TempTable来命名它,则该表可在数据库重启前一直存在。
2、手动删除
drop table TempTableName
说明:
DROP TABLE 语句显式除去临时表,否则临时表将在退出其作用域时由系统自动除去:
(1)、当存储过程完成时,将自动除去在存储过程中创建的本地临时表。由创建表的存储过程执行的所有嵌套存储过程都可以引用此表。但调用创建此表的存储过程的进程无法引用此表;
(2)、所有其它本地临时表在当前会话结束时自动除去;
(3)、全局临时表在创建此表的会话结束且其它任务停止对其引用时自动除去。任务与表之间的关联只在单个Transact-SQL语句的生存周期内保持。换言之,当创建全局临时表的会话结束时,最后一条引用此表的Transact-SQL语句完成后,将自动除去此表。
3、示例代码
(1)创建

),Age )
select * from #tmpStudent
--创建局部临时表 另一种写法
select * into #tmpStudent from student
select * from #tmpStudent
第二种创建方法:
(2)删除
SQL语言笔记的更多相关文章
- Oracle学习笔记之四,SQL语言入门
1. SQL语言概述 1.1 SQL语言特点 集合性,SQL可以的高层的数据结构上进行工作,工作时不是单条地处理记录,而对数据进行成组的处理. 统一性,操作任务主要包括:查询数据:插入.修改和删除数据 ...
- 【MySQL笔记】SQL语言四大类语言
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL. 1. 数据查询语言DQL 数据查询语言DQL基本结构是由SELECT子句,FROM子句, ...
- 学习笔记:oracle学习三:SQL语言基础之sql语言简介、用户模式
目录 1.sql语言简介 1.1 sql语言特点 1.2 sql语言分类 1.3 sql语言的编写规则 2.用户模式 2.1 模式与模式对象 2.2 实例模式scott 本系列是作为学习笔记,用于记录 ...
- PL/SQL语言的学习笔记
一.PL/SQL简介1.什么是PL/SQL程序?(PL/SQL是对SQL语言的一个扩展,从而形成的一个语言) 2.PL/SQL语言的特点(操作Orcale数据库效率最高的就是PL/SQL语言,而不是C ...
- atitit.java解析sql语言解析器解释器的实现
atitit.java解析sql语言解析器解释器的实现 1. 解析sql的本质:实现一个4gl dsl编程语言的编译器 1 2. 解析sql的主要的流程,词法分析,而后进行语法分析,语义分析,构建sq ...
- [SQL] SQL学习笔记之基础操作
1 SQL介绍 SQL 是用于访问和处理数据库的标准的计算机语言.关于SQL的具体介绍,我们通过回答如下三个问题来进行. SQL 是什么? SQL,指结构化查询语言,全称是 Structured Qu ...
- 2016 - 3 - 12 SQLite的学习之SQL语言入门
1.SQL语句的特点: 1.1 不区分大小写 1.2 每条语句以;结尾 2.SQL语句中常用关键字: select,insert,update,from,create,where,desc,order ...
- SQL 语言 - 数据库系统原理
SQL 发展历程 从 1970 年美国 IBM 研究中心的 E.F.Codd 发表论文到 1974 年 Boyce 和 Chamberlin 把 SQUARE 语言改为 SEQUEL 语言,到现在的 ...
- SQL语言
SQL语言的分类:DDL DML DQL DCL SQL中的操作无非就是(增删改查) DDL:Data Query Language,数据查询语言! 主要是用来定义和维护数据库的各种操作对象,比如库. ...
随机推荐
- (js有关图片加载问题)dom加载完和onload事件
引用旺旺的话...哈哈哈DOMContentLoaded事件表示页面的DOM结构绘制完成了,这时候外部资源(带src属性的)还没有加载完.而onload事件是等外部资源都加载完了就触发的.$.read ...
- centOS6.5x64简单的安装openfire
yum install java libldb.i686 mysql-server mysql-connector-java 创建数据库 create database openfire defaul ...
- centos安装与基本使用
1. 插入安装光盘 2. 进入试用 3. 在试用的桌面系统选择安装到硬盘 4. 选择安装语言 5. 选择基本存储或者专门的存储设备 6. - ...
- Cocos2d-x场景切换相关函数介绍
场景切换是通过导演类Director实现的,其中的相关函数如下: runWithScene(Scene* scene).该函数可以运行场景.只能在启动第一个场景时候调用该函数.如果已经有一个场景运行情 ...
- UI3_UIbarButtonItem
// // AppDelegate.m // UI3_UIbarButtonItem // // Created by zhangxueming on 15/7/6. // Copyright (c) ...
- MVC 构造
// // View.h // UI5_HomeWork // // Created by zhangxueming on 15/7/2. // Copyright (c) 2015年 zhangxu ...
- BeanDefinition的载入和解析
1.在完成对代表BeanDefinition的Resource定位的分析后,下面来了解整个BeanDefinition信息的载入过程. 2.对IoC容器来说,这个载入过程,相当于把定义的BeanDef ...
- JS获取非行间样式及兼容问题
获取非行间样式: <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- Netfilter深度解剖
在网络上发现这个Netfilter写的很好的系列文章,为了便于后期寻找,特此标注下博客地址,感谢大大神提供. ---------------------------分割线开始---- ...
- JS事件冒泡与捕获
1事件传播——冒泡与捕获 默认情况下,事件使用冒泡事件流,不使用捕获事件流.然而,在Firefox和Safari里,你可以显式的指定使用捕获事件流,方法是在注册事件时传入useCapture参数,将这 ...