网络流_Edmond-Karp算法、Dinic算法
转载:网络流基础篇——Edmond-Karp算法 BY纳米黑客
网络流的相关定义:
- 源点:有n个点,有m条有向边,有一个点很特殊,只出不进,叫做源点。
- 汇点:另一个点也很特殊,只进不出,叫做汇点。
- 容量和流量:每条有向边上有两个量,容量和流量,从i到j的容量通常用c[i,j]表示,流量则通常是f[i,j].
通常可以把这些边想象成道路,流量就是这条道路的车流量,容量就是道路可承受的最大的车流量。很显然的,流量<=容量。而对于每个不是源点和汇点的点来说,可以类比的想象成没有存储功能的货物的中转站,所有“进入”他们的流量和等于所有从他本身“出去”的流量。
- 最大流:把源点比作工厂的话,问题就是求从工厂最大可以发出多少货物,是不至于超过道路的容量限制,也就是,最大流。
求解思路:
首先,假如所有边上的流量都没有超过容量(不大于容量),那么就把这一组流量,或者说,这个流,称为一个可行流。
一个最简单的例子就是,零流,即所有的流量都是0的流。
- (1).我们就从这个零流开始考虑,假如有这么一条路,这条路从源点开始一直一段一段的连到了汇点,并且,这条路上的每一段都满足流量<容量,注意,是严格的<,而不是<=。
- (2).那么,我们一定能找到这条路上的每一段的(容量-流量)的值当中的最小值delta。我们把这条路上每一段的流量都加上这个delta,一定可以保证这个流依然是可行流,这是显然的。
- (3).这样我们就得到了一个更大的流,他的流量是之前的流量+delta,而这条路就叫做增广路。我们不断地从起点开始寻找增广路,每次都对其进行增广,直到源点和汇点不连通,也就是找不到增广路为止。
- (4).当找不到增广路的时候,当前的流量就是最大流,这个结论非常重要。
补充:
- (1).寻找增广路的时候我们可以简单的从源点开始做BFS,并不断修改这条路上的delta 量,直到找到源点或者找不到增广路。
- (2).在程序实现的时候,我们通常只是用一个c 数组来记录容量,而不记录流量,当流量+delta 的时候,我们可以通过容量-delta 来实现,以方便程序的实现。
相关问题:
为什么要增加反向边?
在做增广路时可能会阻塞后面的增广路,或者说,做增广路本来是有个顺序才能找完最大流的。
但我们是任意找的,为了修正,就每次将流量加在了反向弧上,让后面的流能够进行自我调整。
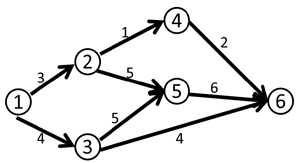
举例:
比如说下面这个网络流模型
我们第一次找到了1-2-3-4这条增广路,这条路上的delta值显然是1。
于是我们修改后得到了下面这个流。(图中的数字是容量)
这时候(1,2)和(3,4)边上的流量都等于容量了,我们再也找不到其他的增广路了,当前的流量是1。
但是,
这个答案明显不是最大流,因为我们可以同时走1-2-4和1-3-4,这样可以得到流量为2的流。
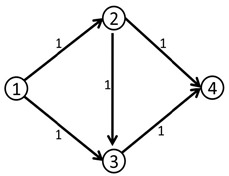
那么我们刚刚的算法问题在哪里呢?
问题就在于我们没有给程序一个“后悔”的机会,应该有一个不走(2-3-4)而改走(2-4)的机制。
那么如何解决这个问题呢?
我们利用一个叫做反向边的概念来解决这个问题。即每条边(i,j)都有一条反向边(j,i),反向边也同样有它的容量。
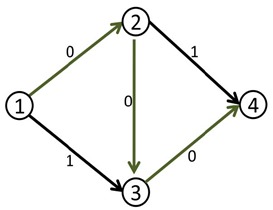
我们直接来看它是如何解决的:
在第一次找到增广路之后,在把路上每一段的容量减少delta的同时,也把每一段上的反方向的容量增加delta。
c[x,y]-=delta;c[y,x]+=delta;我们来看刚才的例子,在找到1-2-3-4这条增广路之后,把容量修改成如下:
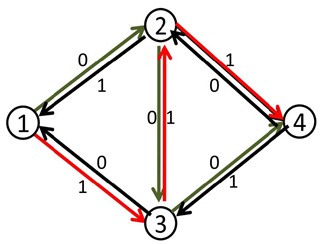
这时再找增广路的时候,就会找到1-3-2-4这条可增广量,即delta值为1的可增广路。将这条路增广之后,得到了最大流2。
那么,这么做为什么会是对的呢?
事实上,当我们第二次的增广路走3-2这条反向边的时候,就相当于把2-3这条正向边已经是用了的流量给“退”了回去,不走2-3这条路,而改走从2点出发的其他的路也就是2-4。
如果这里没有2-4怎么办?
这时假如没有2-4这条路的话,最终这条增广路也不会存在,因为他根本不能走到汇点
同时本来在3-4上的流量由1-3-4这条路来“接管”。而最终2-3这条路正向流量1,反向流量1,等于没有流。

附上自己写的Emonks_Karp:
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<queue>
using namespace std; const int INF=0xf777;
const int MAXN=; int n,m,ans;
int vis[MAXN],pre[MAXN];
int mp[MAXN][MAXN]; bool bfs(int s,int t)
{
memset(vis,,sizeof(vis));
memset(pre,,sizeof(pre));
vis[s]=;
queue<int> Q;
Q.push(s);
while(!Q.empty())
{
int q=Q.front();Q.pop();
if(q==t) return true;
for(int i=;i<=n;i++)
if(!vis[i]&&mp[q][i])
{
vis[i]=;
pre[i]=q;
Q.push(i);
}
}
return false;
} int Edmonds_Karp(int s,int t)
{
int ans=;
while(bfs(s,t))
{
int minn=INF;
for(int i=t;i!=s;i=pre[i])
minn=min(minn,mp[pre[i]][i]);
for(int i=t;i!=s;i=pre[i])
{
mp[pre[i]][i]-=minn;
mp[i][pre[i]]+=minn;
}
ans+=minn;
}
return ans;
} int main()
{
scanf("%d%d",&n,&m);
for(int i=;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
mp[x][y]=z;
}
printf("%d",Edmonds_Karp(,n));
return ;
}
Dinic算法:
ORZ SYCstudio
Dinic算法引入了一个叫做分层图的概念。具体就是对于每一个点,我们根据从源点开始的bfs序列,为每一个点分配一个深度,然后我们进行若干遍dfs寻找增广路,每一次由u推出v必须保证v的深度必须是u的深度+1。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<queue>
using namespace std; const int INF=0x7f7f7f7f;
const int MAXN=; struct Edge
{
int to,w,next;
}E[MAXN];
int node,head[MAXN],dis[MAXN];
int s,t;
int n,m,ans; void insert(int u,int v,int w)
{
E[++node]=(Edge){v,w,head[u]};
head[u]=node;
E[++node]=(Edge){u,,head[v]};
head[v]=node;
} bool bfs()
{
memset(dis,-,sizeof(dis));
queue<int> Q;
Q.push(s);
dis[s]=;
while(!Q.empty())
{
int q=Q.front();Q.pop();
for(int i=head[q];i;i=E[i].next)
if(E[i].w&&dis[E[i].to]==-)
{
Q.push(E[i].to);
dis[E[i].to]=dis[q]+;
}
}
return dis[t]!=-;
} int dfs(int x,int flow)
{
if(x==t) return flow;
for(int i=head[x];i;i=E[i].next)
if(E[i].w&&dis[E[i].to]==dis[x]+)
{
int minn=dfs(E[i].to,min(flow,E[i].w));
if(minn)
{
E[i].w-=minn;
E[i^].w+=minn;
return minn;
}
}
return ;
} void dinic()
{
while(bfs()) ans+=dfs(s,INF);
} int main()
{
scanf("%d%d%d%d",&n,&m,&s,&t);
for(int i=;i<=m;i++)
{
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
insert(u,v,w);
}
dinic();
printf("%d",ans);
return ;
}
网络流_Edmond-Karp算法、Dinic算法的更多相关文章
- 网络流之最大流Dinic算法模版
/* 网络流之最大流Dinic算法模版 */ #include <cstring> #include <cstdio> #include <queue> using ...
- 网络流(四)dinic算法
传送门: 网络流(一)基础知识篇 网络流(二)最大流的增广路算法 网络流(三)最大流最小割定理 网络流(四)dinic算法 网络流(五)有上下限的最大流 网络流(六)最小费用最大流问题 转自:http ...
- 网络流(最大流-Dinic算法)
摘自https://www.cnblogs.com/SYCstudio/p/7260613.html 网络流定义 在图论中,网络流(Network flow)是指在一个每条边都有容量(Capacity ...
- 图论4——探索网络流的足迹:Dinic算法
1. 网络流:定义与简析 1.1 网络流是什么? 网络流是一种"类比水流的解决问题方法,与线性规划密切相关"(语出百度百科). 其实,在信息学竞赛中,简单的网络流并不需要太高深的数 ...
- 最大流EK算法/DINIC算法学习
之前一直觉得很难,没学过网络流,毕竟是基础知识现在重新来看. 定义一下网络流问题,就是在一幅有向图中,每条边有两个属性,一个是cap表示容量,一个是flow 表示流过的流量.我们要求解的问题就是从S点 ...
- 网络最大流算法—Dinic算法及优化
前置知识 网络最大流入门 前言 Dinic在信息学奥赛中是一种最常用的求网络最大流的算法. 它凭借着思路直观,代码难度小,性能优越等优势,深受广大oier青睐 思想 $Dinic$算法属于增广路算法. ...
- 网络流入门—用于最大流的Dinic算法
"网络流博大精深"-sideman语 一个基本的网络流问题 最早知道网络流的内容便是最大流问题,最大流问题很好理解: 解释一定要通俗! 如右图所示,有一个管道系统,节点{1,2,3 ...
- Dinic算法(研究总结,网络流)
Dinic算法(研究总结,网络流) 网络流是信息学竞赛中的常见类型,笔者刚学习了最大流Dinic算法,简单记录一下 网络流基本概念 什么是网络流 在一个有向图上选择一个源点,一个汇点,每一条边上都有一 ...
- Dinic算法详解及实现
预备知识: 残留网络:设有容量网络G(V,E)及其上的网络流f,G关于f的残留网络即为G(V',E'),其中G'的顶点集V'和G的顶点集V相同,即V'=V,对于G中任何一条弧<u,v>,如 ...
- 网络流入门--最大流算法Dicnic 算法
感谢WHD的大力支持 最早知道网络流的内容便是最大流问题,最大流问题很好理解: 解释一定要通俗! 如右图所示,有一个管道系统,节点{1,2,3,4},有向管道{A,B,C,D,E},即有向图一张. ...
随机推荐
- hdu2069(Coin Change)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2069 Coin Change Time Limit: 1000/1000 MS (Java/Other ...
- 双层列表 datagrid里属性
frozenColumns: [ [{ title: "姓名"}] ], columns: [ [{"title":"延时原因"}], [{ ...
- Postman安装步骤
Postman是一种网页调试与发送网页http请求的chrome插件. 我们可以用来很方便的模拟get或者post或者其他方式的请求来调试接口. 1.Postman_v4.1.3下载地址: http: ...
- AOP注解方式
Aop, aspect object programming 面向切面编程 功能: 让关注点代码与业务代码分离! 关注点, 重复代码就叫做关注点: 切面, 关注点形成的类,就叫切面(类)! 面向切 ...
- json java simple-json
http://code.google.com/p/json-simple/wiki/EncodingExamples#Example_1-1_-_Encode_a_JSON_object javac ...
- android 开发-spinner下拉框控件的实现
Android提供实现下拉框功能的非常实用的控件Spinner. spinner控件需要向xml资源文件中添加spinner标签,如下: <Spinner android:id="@+ ...
- HttpClient向后端的WebAPI工程发送HTTP的Post请求时,返回超过了最大请求长度的异常的解决方法
文章中的内容以及解决思路参考(转载)的 http://www.jb51.net/article/88698.htm 在WPF项目中通过HttpClient向后端的WebAPI工程发送HTTP的Post ...
- sublime 常用快捷键(转)
Sublime text 3是码农最喜欢的代码编辑器,每天和代码打交道,必先利其器,掌握基本的代码编辑器的快捷键,能让你打码更有效率.刚开始可能有些生疏,只要花一两个星期坚持使用并熟悉这些常用的快捷键 ...
- localstorage本地存储的应用
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Retrofit2与RxJava用法大全
Retrofit2是square公司出品的一个网络请求库,网上有很多相关的介绍.我很久以前都想去研究了,但一直都有各种事情耽搁,现在就让我们一起去捋一捋,这篇主要讲解Retrofit2与RxJava的 ...