Ubuntu16.04 hadoop 伪分布式 的文件配置
首先需要完成java环境的配置,这里就省略了。
完成 hadoop 伪分布(pesudo distribution),只需配置下面 五 个文件即可:
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
这些配置文件都在解压后的hadoop目录中的 etc/hadoop 目录下,下面是它们的具体作用和配置:
1 hadoop-env.sh
这个用来配置 Java 环境的路径,在hadoop-env.sh中找到这一行:
export JAVA_HOME=
并将等号后面的内容替换成自己的java环境路径即可,如果不确定,执行sudo update-alternatives --config java 就能看到了,如果安装了多个java环境,可以从这儿选择某一个,每个条目的路径就是所需的java环境了, 比如我的执行结果是这样的:
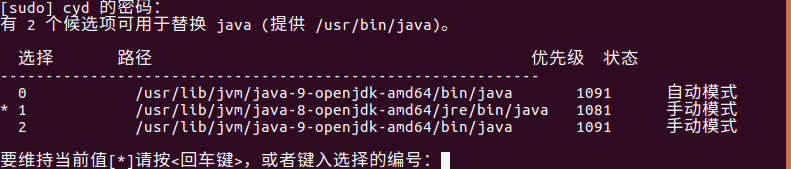
我目前用的是第二个条目的java环境,取bin之前的路径就是: /usr/lib/jvm/java-8-openjdk-amd64/jre
2 core-site.xml
指定HDFS的通信地址和缓存存储的路径:
在core-site.xml的 configure 中分别加入这些片段,如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_installs/tmp</value>
</property>
</configuration>
3 hdfs-site.xml
指定hdfs的副本数量,这里就假设是 1 个:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> </property>
</configuration>
4 yarn-site.xml
yarn 是hadoop的统一资源管理器:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
5 mapred-site.xml
mapred是一种计算模型, 这里就指定 它使用yarn 来管理资源
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这里要把原来的mapred-site.xml.template 改成 mapred-site.xml 再编辑.
6 参考博客:
https://www.cnblogs.com/gyouxu/p/4183417.html
Ubuntu16.04 hadoop 伪分布式 的文件配置的更多相关文章
- Ubuntu16.04下伪分布式环境搭建之hadoop、jdk、Hbase、phoenix的安装与配置
一.准备工作 安装包链接: https://pan.baidu.com/s/1i6oNmOd 密码: i6nc 环境准备 修改hostname: $ sudo vi /etc/hostname why ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop伪分布式环境搭建+Ubuntu:16.04+hadoop-2.6.0
Hello,大家好 !下面就让我带大家一起来搭建hadoop伪分布式的环境吧!不足的地方请大家多交流.谢谢大家的支持 准备环境: 1, ubuntu系统,(我在16.04测试通过.其他版本请自行测试, ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Linux下配置Hadoop伪分布式环境
1. 准备Linux环境 提示:我用的系统是CentOS 6.4. 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host- ...
- Ubuntu15.10下Hadoop2.6.0伪分布式环境安装配置及Hadoop Streaming的体验
Ubuntu用的是Ubuntu15.10Beta2版本,正式的版本好像要到这个月的22号才发布.参考的资料主要是http://www.powerxing.com/install-hadoop-clus ...
- Hadoop伪分布式模式搭建
title: Hadoop伪分布式模式搭建 Quitters never win and winners never quit. 运行环境: Ubuntu18.10-server版镜像:ubuntu- ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式平台搭建(centos 6.3)
最近要写一个数据量较大的程序,所以想搭建一个hbase平台试试.搭建hbase伪分布式平台,需要先搭建hadoop平台.本文主要介绍伪分布式平台搭建过程. 目录: 一.前言 二.环境搭建 三.命令测试 ...
随机推荐
- Tree--lecture08
1.二叉树 完全二叉树(complete binary tree):除了最下面一层都是满的,最下面一层也是优先排列在左边.这样的话父亲节点和孩子节点就在序号上面有关系: 父亲节点为n,那么子节点的编号 ...
- BIO,NIO,AIO的理解
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善. NIO: ...
- js 和C# ashx之间数组参数传递问题
js在进行ajax提交时,如果提交的参数是数组,js无法直接进行提交,及时提交上去,解析也是比较麻烦 ajax在提交数组时,需要设置参数: traditional: true, //参数作为数组传 ...
- 寻找jar包的好方法
好东西分享下: 下载jar包不用愁 http://maven.outofmemory.cn/
- 使用Quartz任务调用的时候报错Based on configured schedule, the given trigger will never fire.
org.quartz.SchedulerException: Based on configured schedule, the given trigger will never fire. 大概意思 ...
- Handler: Service中使用Toast
Handler 的使用在 android App 开发中用的颇多,它的作用也很大,使用 Handler 一般也会使用到多线程,相信大家对 Handler 不会陌生,在这里,重点说一下 android ...
- [LeetCode]9. Palindrome Number回文数
Determine whether an integer is a palindrome. An integer is a palindrome when it reads the same back ...
- 使用JAVA读写Properties属性文件
使用JAVA读写Properties属性文件 Properties属性文件在JAVA应用程序中是经常可以看得见的,也是特别重要的一类文件.它用来配置应用程序的一些信息,不过这些信息一般都是比较少的数 ...
- pandas:数据分析
一.介绍 pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. 1.主要功能 具备对其功能的数据结构DataFrame.Series 集成时间序列功能 提供丰富的数学运算和操 ...
- 从零开始的全栈工程师——html篇1.6
浮动与伪类选择器 一.浮动(float) 1.标准文档流 标准文档流是一种默认的状态 浏览器的排版是根据元素的特征(块和行级) 从上往下 从左往右排版 这就是标准文档流 2.浮动(float)floa ...