Spark Streaming 交互 Kafka的两种方式
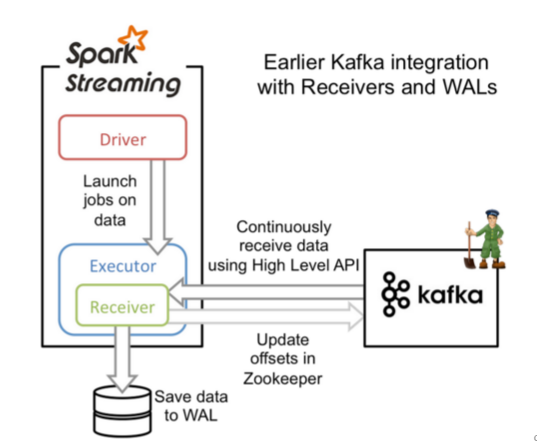
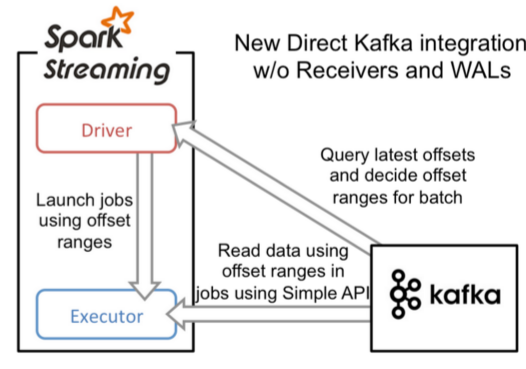
Spark Streaming 交互 Kafka的两种方式的更多相关文章
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
- sparkStreaming读取kafka的两种方式
概述 Spark Streaming 支持多种实时输入源数据的读取,其中包括Kafka.flume.socket流等等.除了Kafka以外的实时输入源,由于我们的业务场景没有涉及,在此将不会讨论.本篇 ...
- spark streaming集成kafka接收数据的方式
spark streaming是以batch的方式来消费,strom是准实时一条一条的消费.当然也可以使用trident和tick的方式来实现batch消费(官方叫做mini batch).效率嘛,有 ...
- spark-streaming-连接kafka的两种方式
推荐系统的在线部分往往使用spark-streaming实现,这是一个很重要的环节. 在线流程的实时数据一般是从kafka获取消息到spark streaming spark连接kafka两种方式在面 ...
- spark application提交应用的两种方式
bin/spark-submit --help ... ... --deploy-mode DEPLOY_MODE Whether to launch the driver program loc ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- spark streaming 接收kafka消息之一 -- 两种接收方式
源码分析的spark版本是1.6. 首先,先看一下 org.apache.spark.streaming.dstream.InputDStream 的 类说明: This is the abstrac ...
- Spark Streaming消费Kafka Direct方式数据零丢失实现
使用场景 Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(据说比较鸡肋,虽然可以 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
随机推荐
- 网站架构:消息队列 Java后端架构
2017-01-13 一.消息队列概述 消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构.是大型分布式系统不可缺少的中间 ...
- Hibernate课程 初探一对多映射3-4 双向多对一的测试
1 单向多对一和单向多对一的区别 比如部门和员工,一个部门下有很多员工,如果只查一个员工属于哪个部门,就用单向的,如果还要查一个部门下的所有员工,就用双向的. 2 双向多对一的配置 除了单向xml和双 ...
- iOS重用宏定义
iOS 多快好省的宏(转) 原文地址:http://my.oschina.net/yongbin45/blog/150149 // 字符串: #ifndef nilToEmpty #define ni ...
- Day3 Form表单
Day3 Form表单 一.form表单 :提交数据 表单在网页中主要负责数据采集功能,它用<form>标签定义. 用户输入的信息都要包含在form标签中,点击提交后,< ...
- ATL
Normal COM.cpp #include "resource.h" // 主符号 #include "ATLCOM_i.h" #include " ...
- Python开发环境Wing IDE之Search in Files工具详解
Search in Files工具是Wing IDE中最强大的搜索选项.它支持磁盘.项目,打开编辑器,或其它文件集的多文件批量搜索.它还可以使用通配符搜索,并可以做基于正则表达式的搜索/替换. 建议用 ...
- Web前端开发规范(二)
3.HTML代码规范 .html文件必须存放在项目工程约定的目录中. .html文件的命名:以模块 + 功能的结合方式来命名,比如:newsList.html. 文档类型声明:HTML4中使用< ...
- msql 综合练习
8.统计列印各科成绩,各分数段人数: 课程ID,课程名称,[100-85],[85-70],[70-60],[<60] 尽管表面看上去不那么容易,其实用 CASE 可以很容易地实现: SELE ...
- 【技巧】如何使用UltraEdit删掉某些行并且不留空行
例: 在S1这个文件中我想要把所有B6 96 FD 2E 49 96 2 D2的行删掉. 首先,查找这些序列,执行替换命令,替换为的内容不写. 点击“全部替换”之后,发现在原来的位置多了一行空行. 接 ...
- Python基础学习之变量赋值
1.赋值操作符 Python语言中,等号(=)是主要的赋值操作符: >>> aInt=-100 >>> aString='this is a string' > ...