python模块之正则
re模块
可以读懂你写的正则表达式
根据你写的表达式去执行任务
用re去操作正则
正则表达式
使用一些规则来检测一些字符串是否符合个人要求,从一段字符串中找到符合要求的内容。在线测试网站:http://tool.chinaz.com/regex/
元字符:用来表示范围
|
元字符 |
匹配内容 |
|
. |
匹配除换行符\n以外的任意字符 |
|
^ |
只匹配字符串的开始 |
|
$ |
只匹配字符串的结束 |
|
\w |
匹配字母或数字或下划线 |
|
\s |
匹配任意空白符 |
|
\d |
匹配数字 |
|
\n |
匹配一个换行符 |
|
\t |
匹配一个制表符 |
|
\W |
匹配非字母数字和下划线 |
|
\S |
匹配非空白符 |
|
\D |
匹配非数字 |
|
a|b |
匹配字符a或b |
|
() |
匹配括号内的表达式,也表示一个组 |
|
[ ] |
匹配字符组的字符 |
|
[^ ] |
匹配除了字符组中字符的所有字符 |
# 在字符组[ ]中,-表示范围,一般是根据字符对应的码值(字符在对应编码表中的编码的数值)来确定的,码值小的在前,码值大的在后。
# 在ascll编码表中, 0-9对应码值是48-57,a-z的码值是97-122,A-Z对应码值65-90
量词:
|
量词 |
用法说明 |
|
* |
重复零次或更多次 |
|
+ |
重复一次或更多次 |
|
? |
重复零次或一次,可匹配也可不匹配 |
|
{n} |
重复n次 |
|
{n,} |
重复n次或更多次 |
|
{n,m} |
重复n到m次 |
.*?的用法说明:
. 任意字符
* 取0至无限长度
? 非贪婪模式
.*?x 合在一起表示取尽量少的任意字符,知道一个x出现
其他使用说明:
* + ? { }:
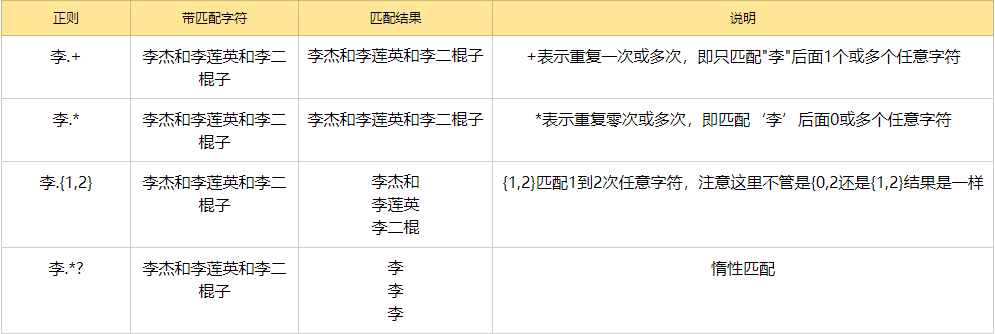
注: *,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
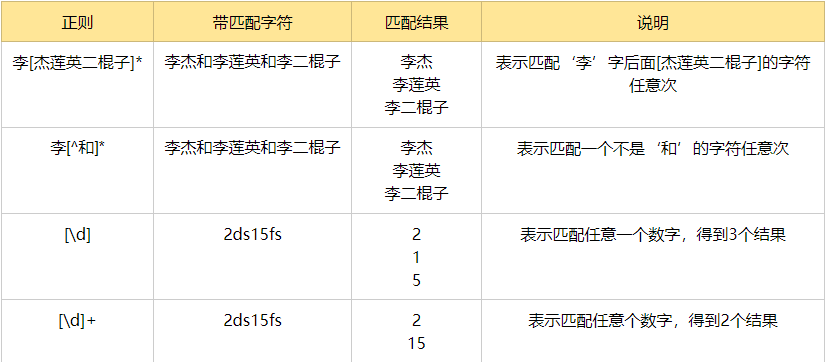
字符集[][^]:
分组 ()与 或 |[^]:
身份证号是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能是0
如果是18位,则前17位全部是数字,末尾可能是x
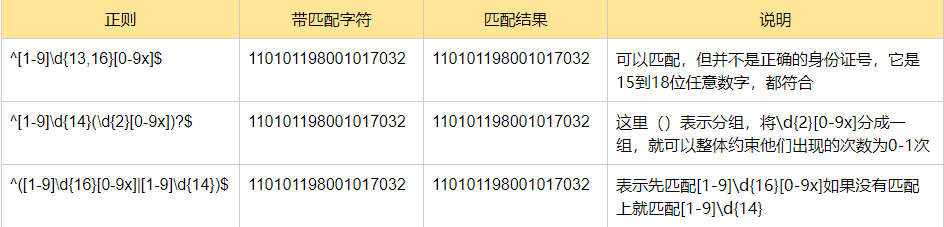
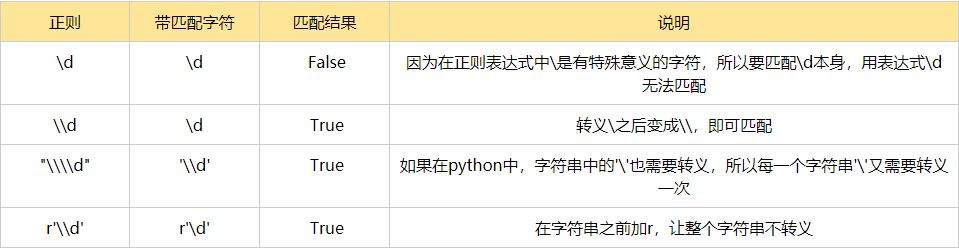
转义符 \:
在正则中,存在很多特殊意义的元字符,如\d,\s等,如果要在正则中匹配正常的‘\d’而不是‘数字’就需要对‘\d’进行转义,变成‘\\’
在py中,无论是正则表达式还是待匹配内容都是以字符串形式出现的,字符串中\也有特殊含义,本身也需要转义,这时候就要用到r‘\d’转换
贪婪匹配:
满足匹配时,匹配尽可能长的字符串

几个常用非贪婪匹配格式
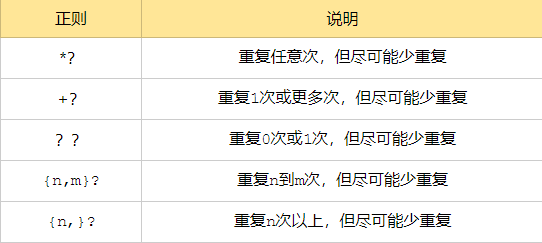
re模块下的常用方法
import re
ret = re.findall('a', 'eva egon yuan')
print(ret) # ['a', 'a'] ret = re.findall('\d+', 'dsaglhlkdfh1892494kashdgkjh127839')
print(ret) # ['1892494', '127839'] # findall接收两个参数 : 正则表达式 要匹配的字符串
# 一个列表数据类型的返回值:所有和这条正则匹配的结果 ret = re.search('a', 'eavegonyaun').group()
print(ret) # a # 函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象,该
# 对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,未调用group时
# 则返回None。 # search和findall的区别:
# 1.search找到一个就返回,findall是找所有
# 2.findall是直接返回一个结果的列表,search返回一个对象 ret = re.match('foo', 'fooid')
if ret:
print(ret.group())
'foo'
# 意味着在正则表达式中添加了一个^
# 同search,不过只从字符串的开始部分对模式进行匹配, ret = re.sub('\d', 'H', 'eva3egon4yuan4', 2)
print(ret) # evaHegonHyuan4
# 将前两个数字换成H ret = re.subn('\d', 'H', 'eva3egon4yuan4')
print(ret) # ('evaHegonHyuanH', 3)
# #将数字替换成'H',返回元组(替换的结果,替换了多少次) ret = re.split("\d+", "eva3egon4yuan")
print(ret) # ['eva', 'egon', 'yuan']
ret = re.split("(\d+)", "eva162784673egon44yuan")
print(ret) # ['eva', '162784673', 'egon', '44', 'yuan']
# split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中,
# 如果将匹配的正则放到组内,就会将分隔符放到结果列表里 # 在多次执行同一条正则规则的时:
obj = re.compile('\d{3}')
ret1 = obj.search('abc123eeee')
ret2 = obj.findall('abc123eeee')
print(ret1.group()) # 123
print(ret2) # ['123']
# 如果匹配文件中的手机号,可以进行这样的一次编译,节省时间 # finditer适用于结果比较多的情况下,能够有效的节省内存
ret = re.finditer('\d', 'ds3sy4784a')
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) # 查看第一个结果
print(next(ret).group()) # 查看第二个结果
print([i.group() for i in ret]) # 查看剩余的左右结果
compile格式:
re.compile(pattern,flags=0)
pattern: 编译时用的表达式字符串。
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
| 标志 |
含义
|
|
re.S(DOTALL)
|
使.匹配包括换行在内的所有字符 |
|
re.I(IGNORECASE)
|
使匹配对大小写不敏感
|
|
re.L(LOCALE)
|
做本地化识别(locale-aware)匹配,法语等
 |
|
re.M(MULTILINE)
|
多行匹配,影响^和$
|
|
re.X(VERBOSE)
|
该标志通过给予更灵活的格式以便将正则表达式写得更易于理解
|
|
re.U
|
根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B
|
分组:
如果对一组正则表达式整体有一个量词约束,就将这一组表达是分成一个组
要想取消分组优先效果,在组内开始的时候加上?: 这个很关键的
# 当分组遇到re模块
import re
ret1 = re.findall('www.(baidu|oldboy).com', 'www.baidu.com')
ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.baidu.com')
print(ret1)
print(ret2)
# findall会优先显示组内匹配到的内容返回
# 如果想取消分组优先效果,在组内开始的时候加上?: # 分组的意义
# 1.对一组正则规则进行量词约束
# 2.从一整条正则规则匹配的结果中优先显示组内的内容
# "<h1>hello</h1>"
ret = re.findall('<\w+>(\w+)</\w+>', "<h1>hello</h1>")
print(ret) # ['hello'] # 分组命名 ?p固定语法,p大写
ret = re.search("<(?P<tag>\w+)>(?P<content>\w+)</(?P=tag)>", "<h1>hello</h1>")
print(ret.group()) # <h1>hello</h1>,search中没有分组优先的概念
print(ret.group('tag')) # h1
print(ret.group('content')) # hello # 如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
# 获取的匹配结果可以直接用group(序号)拿到对应的值
ret = re.search(r"<(\w+)>(\w+)</\1>", "<h1>hello</h1>")
print(ret.group()) # <h1>hello</h1>
print(ret.group(0)) # <h1>hello</h1>
print(ret.group(1)) # h1
print(ret.group(2)) # hello
分组进阶:
s = '2017-07-10 20:00'
p = re.compile(r'(((\d{4})-\d{2})-\d{2}) (\d{2}):(\d{2})')
re.findall(p,s)
# 输出:
# [('2017-07-10','2017-07','2017','20','00')] se = re.search(p,s)
print se.group()
print se.group(0)
print se.group(1)
print se.group(2)
print se.group(3)
print se.group(4)
print se.group(5) # 输出:
'''
'2017-07-10 20:00'
'2017-07-10 20:00'
'2017-07-10'
'2017-07'
'2017'
'20'
'00'
'''
关于split的优先级查询问题:
在匹配部分加上()之后所切出的结果是不同的,没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项
import re
ret = re.split('\d+','ds22glhfh124dgkjh1')
print(ret) # ['ds', 'glhfh', 'dgkjh', '']
# 这里最后一位有空格是由于它左边有东西而右边没有了,所以用空格替代了
ret = re.split('(\d+)','ds22glhfh124dgkjh1')
print(ret) # ['ds', '22', 'glhfh', '124', 'dgkjh', '1', '']
ret = re.split('(?:\d+)','ds22glhfh124dgkjh1')
print(ret) # ['ds', 'glhfh', 'dgkjh', '']
应用:
# 获取当中的字母
s ='abc @ 124,efg opAs4'
import re
a = ''.join(re.findall('[a-zA-Z]',s))
print(a)
b = re.sub('[^a-zA-Z]','', s)
print(b)
c = ''.join(re.split('[^a-zA-Z]',s))
print(c)
关于整数匹配问题,如匹配1-2*(60+(-40.35/5)-(-4*3))中的整数
import re
ret = re.findall(r'-?\d+\.\d*|(-?\d+)',a)
ret.remove('')
print(ret)
利用正则制作计算器:点击这里>>
利用正则爬去豆瓣网页
#!/usr/bin/env python # -*- coding:utf-8 -*-
# author: Learning time:2018/9/28 import time
import re
from urllib.request import urlopen def getPage(url):
response = urlopen(url) # 通过response=requests.get(url)获取也OK
return response.read().decode('utf-8') # 直接返回response.text def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s) # 正则匹配,然后通过生成器批量获取数据
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
} def main(num): # 入口函数
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
f = open("move_info7", "a", encoding="utf8") for obj in ret:
print(obj)
data = str(obj)
f.write(data + "\n") if __name__ == '__main__':
before=time.time()
count=0
for i in range(10):
main(count)
count+=25 # 每页25条数据,参考打开网址的url
after=time.time()
print("总共耗费时间:", after - before)
相关问题:
1.re的match和search区别?
re.match() 从第一个字符开始找, 如果第一个字符就不匹配就返回None, 不继续匹配. 用于判断字符串开头或整个字符串是否匹配,速度快.
re.search() 会整个字符串查找,直到找到一个匹配。

python模块之正则的更多相关文章
- Python模块(三)(正则,re,模块与包)
1. 正则表达式 匹配字符串 元字符 . 除了换行 \w 数字, 字母, 下划线 \d 数字 \s 空白符 \n 换行符 \t 制表符 \b 单词的边界 \W \D \S 非xxx [ ...
- python——re模块(正则表达)
python——re模块(正则表达) 两个比较不错的正则帖子: http://blog.csdn.net/riba2534/article/details/54288552 http://blog.c ...
- python 爬虫之 正则的一些小例子
什么是正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是 事先定义好的一些特定字符.及这些特定字符的组合,组成一个“规则字符”,这个“规则字符” 来表达对字符的一种过滤逻辑. 正则并不是pyth ...
- Python中的正则
regex_lst = [ ('字符组',), ('非打印字符',), ('特殊字符',), ('定位符',), ('限定符',), ('re模块',), ('分组命名',), ('或匹配',), ( ...
- Python 模块(二)
1 logging 模块 logging有两种的配置的方式,configure.logger 1.1 config方式 import logging ''' 日志的配置:config模式 只能选择在屏 ...
- re模块和正则
正则表达式:就是用来筛选字符串中特定内容的一串具有某种逻辑规则的字符组成.正则表达式不是Python独有的,而是一门独立的技术,它在所有的编程语言中都有使用,在Python中使用就必须依赖于re模块. ...
- 模块 re_正则
模块re_正则 讲正题之前我们先来看一个例子:https://reg.jd.com/reg/person?ReturnUrl=https%3A//www.jd.com/ 这是京东的注册页面,打开页面我 ...
- python—模块与包
模块: (一个.py文件就是一个模块module,模块就是一组功能的集合体,我们的程序可以导入模块来复用模块里的功能.) 模块分三种: 1.python标准库 2.第三方模块 3.应用程序自定义模块 ...
- Python模块Ⅱ
Python模块2 part3 模块的分类: 内置模块200种左右:python自带的模块,time os sys hashlib等 第三方模块6000种左右:需要pip install beauti ...
随机推荐
- list 增 删 改 查 及 公共方法
# 热身题目:增加名字,并且按q(不论大小写)退出程序 li = ['taibai','alex','wusir','egon','女神'] while 1: username = input('&g ...
- Django自定义过滤器
1.首先在在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag. 2.在app中创建templatetags模块(模块名只能是temp ...
- [转]jQuery.getJSON的缓存问题的解决办法
本文转自:http://mfan.iteye.com/blog/974132 今天做测试工作,发现了一个令我费解的问题,jquery的getJson方法在firefox上运行可以得到返回的结果,但是在 ...
- 《大巧不工 web前端设计修炼之道》学习笔记
前端设计如同一个人的着装与外表,站点的设计总是最先吸引人们的眼球.布局是否合理.风格是否简介.配色是否和谐,流程是否通畅,操作是否便捷,这些前端特效都影响着用户对站点的认可度.随着用户体验,可用性,可 ...
- linux下文件比对功能
很想对吧两个文本有什么不同,可linux下有没有那么方便的工具,怎么办?其实也很简单:diff命令,一行搞定. 新建a.txt文件
- kindeditor编辑区空格被隐藏,导致所见所得不一致的解决办法
1.修改kindereditor-all.js中的 var re = /(\s*)<(\/)?([\w\-:]+)((?:\s+|(?:\s+[\w\-:]+)|(?:\s+[\w\-:]+=[ ...
- 查看SQL Server中的锁表及解锁
有时候系统很慢,有可能是SQL Server数据库中某些表被锁定 --查看被锁表(需查多几次,有些临时锁很快会自动解锁): SELECT request_session_id AS spid, OBJ ...
- Geek to Live: Set up your personal Wikipedia
http://lifehacker.com/163707/geek-to-live--set-up-your-personal-wikipedia Filed to: Wikipedia Captur ...
- EF生成的表被更改后的错误
1.在Global.ascs设置 public class MvcApplication : System.Web.HttpApplication { protected void Applicati ...
- (生产)js-base64 - 转码
参考:https://github.com/dankogai/js-base64 安装 $ npm install --save js-base64 使用 var Base64 = require(' ...