ElasticSearch 安装中文分词器
1、安装中文分词器IK
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
在线下载安装: elasticsearch-plugin.bat install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip
先下载后安装:elasticsearch-plugin.bat install file:///D:\work\ElasticSearch\plugin\elasticsearch-analysis-ik-5.5.2.zip
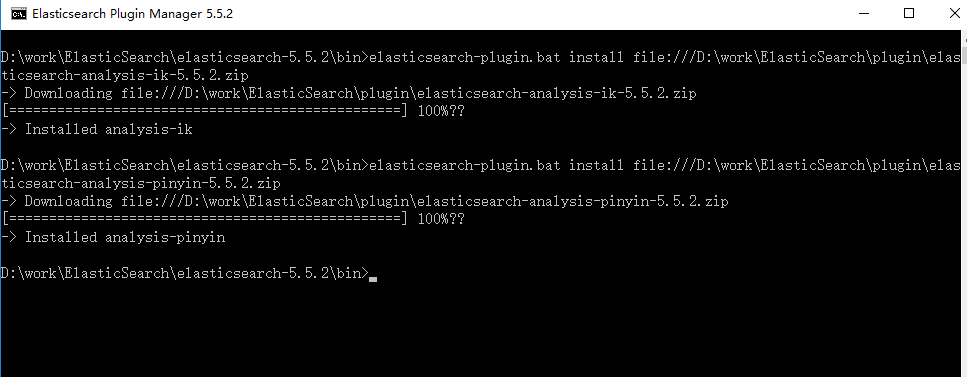

2、重启 elasticsearch
3、创建空索引
curl -XPUT http://127.0.0.1:9200/index_china

或
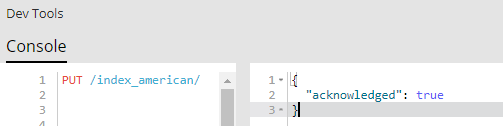
在kibana的Dev Tools中用 PUT /index_american/
4、创建映射
curl -XPOST http://127.0.0.1:9200/index_china/fulltext/_mapping -d "{\"properties\": {\"content\": {\"type\": \"text\",\"analyzer\": \"ik_max_word\",\"search_analyzer\": \"ik_max_word\"}}}"

或
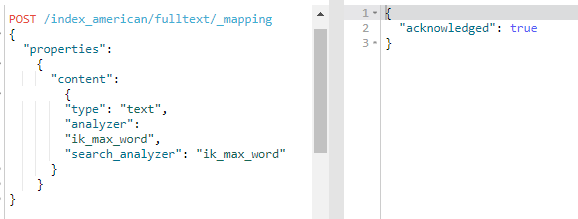
POST /index_american/fulltext/_mapping
{
"properties":
{
"content":
{
"type": "text",
"analyzer":
"ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
5、索引数据
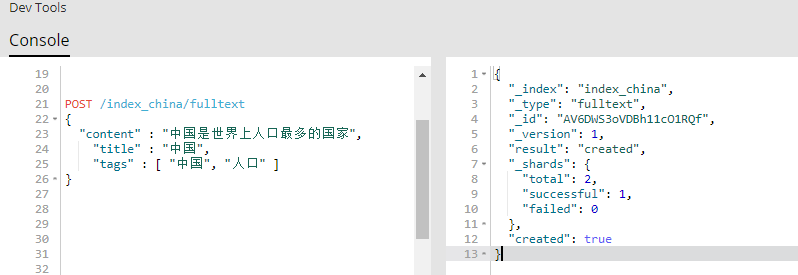
POST /index_china/fulltext
{
"content" : "中国是世界上人口最多的国家",
"title" : "中国",
"tags" : [ "中国", "人口" ]
}
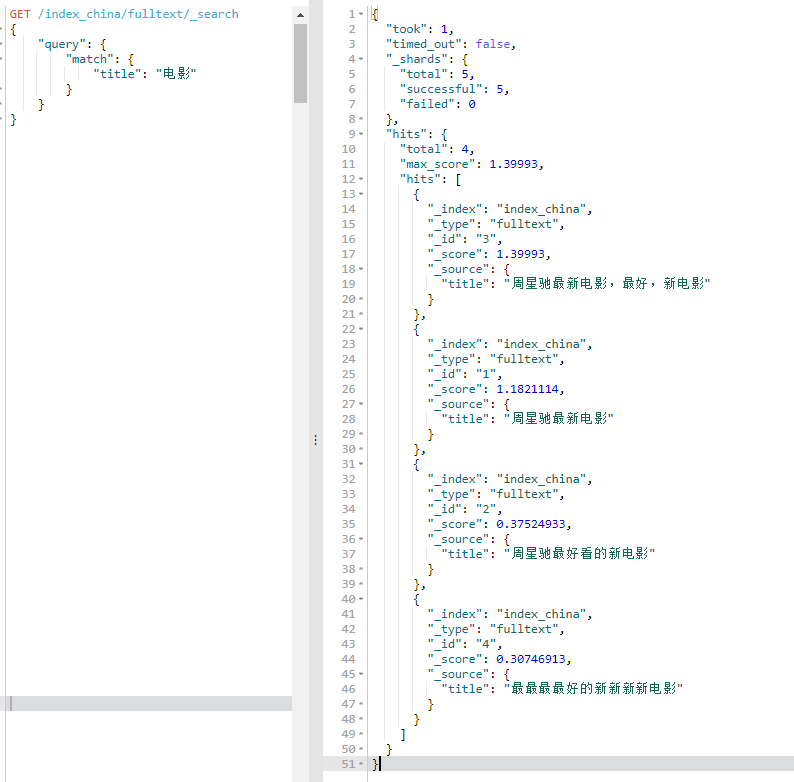
批量索引数据
POST /_bulk
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "周星驰最新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "周星驰最好看的新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "周星驰最新电影,最好,新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "最最最最好的新新新新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "I'm not happy about the foxes" }
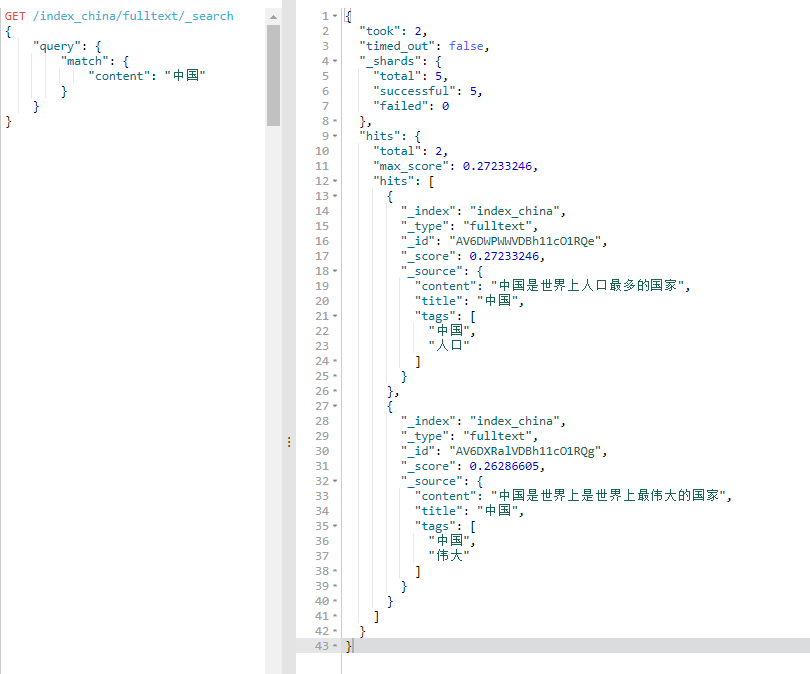
6、查询
GET /index_china/fulltext/_search
{
"query": {
"match": {
"content": "中国"
}
}
}
7、最大分词和最小分词
ik_smart,
ik_max_word
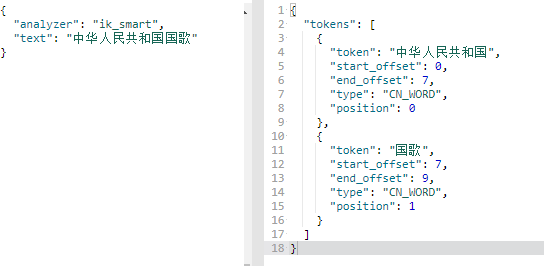

GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
#删除索引
DELETE /ott_test #创建索引 PUT /ott_test
{
"mappings": {
"ott_type" : {
"properties" : {
"title" : {
"type" : "text",
"index":true,
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"date" : {
"type" : "date"
},
"keyword" : {
"type" : "keyword"
},
"source" : {
"type" : "keyword"
},
"link" : {
"type" : "keyword"
}
}
}
}
} #索引数据
POST /ott_test/ott_type
{
"title":"微博新规惹争议:用户原创内容版权归属于微博?",
"link":"http://www.yidianzixun.com/article/0HHoxgVq",
"date":"2017-09-17",
"source":"虎嗅网",
"keyword":"内容"
} #分析
GET /ott_test/_analyze
{
"field": "title",
"text": "内容"
} #查询 GET /ott_test/ott_type/_search
{
"query": {
"match": {
"title": "内容"
}
}
} #只查询title和date两个字段的数据 GET /ott_test/ott_type/_search
{
"query": {"match_all": {}},
"_source": ["title","date"]
}
ElasticSearch 安装中文分词器的更多相关文章
- 如何给Elasticsearch安装中文分词器IK
安装Elasticsearch安装中文分词器IK的步骤: 1. 停止elasticsearch 2.2的服务 2. 在以下地址下载对应的elasticsearch-analysis-ik插件安装包(版 ...
- elasticsearch安装中文分词器插件smartcn
原文:http://blog.java1234.com/blog/articles/373.html elasticsearch安装中文分词器插件smartcn elasticsearch默认分词器比 ...
- ElasticSearch安装中文分词器IKAnalyzer
# ElasticSearch安装中文分词器IKAnalyzer 本篇主要讲解如何在ElasticSearch中安装中文分词器IKAnalyzer,拆分的每个词都是我们熟知的词语,从而建立词汇与文档 ...
- ElasticSearch安装中文分词器IK
1.安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可.IKAna ...
- elasticsearch安装中文分词器
1. 分词器的安装 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/rele ...
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
- Elasticsearch之中文分词器插件es-ik(博主推荐)
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch之分词器的工作流程 Elasticsearch之停用词 Elasticsearch之中文分词器 Elasti ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- Elasticsearch之中文分词器插件es-ik的自定义热更新词库
不多说,直接上干货! 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
随机推荐
- POJ 2318 TOYS | 二分+判断点在多边形内
题意: 给一个矩形的区域(左上角为(x1,y1) 右下角为(x2,y2)),给出n对(u,v)表示(u,y1) 和 (v,y2)构成线段将矩形切割 这样构成了n+1个多边形,再给出m个点,问每个多边形 ...
- 基于Windows Server 2008 R2的Failover Cluster
转载一下别人的文章吧,写的不错 基于Windows Server 2008 R2的Failover Cluster(故障转移群集)部署Sql Server 2008 AA(主主) 模式群集(第一部分) ...
- MyBatis的常见错误总结
把MyBatis的常见错误总结一下.. UserMapper: <mapper namespace="com.ydweb.data.dao.UserMapper"> & ...
- mininet命令
官方文档:http://mininet.org/walkthrough/ 翻译的官方文档:https://segmentfault.com/a/1190000000669218 ovs-ofctl相关 ...
- (2) python--pandas
import pandas as pd import numpy as np # 创建的Series几种方式 s1 = pd.Series(range(4)) s2 = pd.Series([0, 1 ...
- Javascript报错Converting circular structure to JSON 错误排解
在运行nodejs程序的时候报出以下的错误: 2017-11-20 17:44 +08:00: TypeError: Converting circular structure to JSON at ...
- 并发策略-CAS算法
对于并发控制而言,我们平时用的锁(synchronized,Lock)是一种悲观的策略.它总是假设每一次临界区操作会产生冲突,因此,必须对每次操作都小心翼翼.如果多个线程同时访问临界区资源,就宁可牺牲 ...
- Weblogic 监控工具汇总及简介
https://blog.csdn.net/hualusiyu/article/details/39608637
- AC日记——Array Queries codeforces 797e
797E - Array Queries 思路: 分段处理: 当k小于根号n时记忆化搜索: 否则暴力: 来,上代码: #include <cmath> #include <cstdi ...
- Python的程序结构[1] -> 方法/Method[3] -> 魔术方法 __getattr__ 与代理模式
__getattr__ 方法 __getattr__ 方法当对象调用内部属性(包括方法等)且未找到对应属性的时候会调用的特殊方法.利用这一特性,可是对函数实现一个代理模式. __getattr__方法 ...